字節(jié)MOMA-Force視力覺模仿學(xué)習(xí),機(jī)器人移動操作成功率提升近30%
我們正在目睹人工智能大廈的快速搭建,越來越多的算力奠定了大廈地基,大模型加快了大廈的建造速度,具身智能開始成為新的研究熱門 —— 大廈的功能性將會得到完備。
具備自主操作行為的移動操作機(jī)器人(mobile manipulators)無疑是具身智能(embodied AI)的一個絕佳代表:它集機(jī)器人的多模態(tài)自主感知、自主決策、軌跡生成、魯棒控制以及靈活本體于一身,為機(jī)器人以及具身智能領(lǐng)域的研究員、工程師提出了諸多令人興奮的挑戰(zhàn)點(diǎn)。比如:當(dāng)我們想要讓一臺機(jī)器 “人” 進(jìn)入家庭幫助我們做家務(wù),它如何結(jié)合各種傳感信息自主生成操作軌跡?如何在操作的過程中保證不損壞家具和自己?
針對移動操作機(jī)器人在真實(shí)場景操作過程中的自主性和安全性問題,Bytedance Research 團(tuán)隊提出了一種新的方法:MOMA-Force。該方法可幫助移動操作機(jī)器人自主、安全地完成多種存在接觸約束的操作任務(wù)(例如開洗衣機(jī)門、推拉抽屜)。
 該研究工作在模仿學(xué)習(xí)的背景下解決了真實(shí)物理世界移動操作任務(wù)中由不確定性和高維運(yùn)動學(xué)引起的挑戰(zhàn)性問題,提出了一種有效的視力覺模仿學(xué)習(xí)方法以解決復(fù)雜的接觸移動操作任務(wù)。在六個接觸約束的移動操作任務(wù)上進(jìn)行了系統(tǒng)的真實(shí)機(jī)器人實(shí)驗:在真實(shí)家庭環(huán)境中,MOMA-Force 在任務(wù)成功率方面明顯優(yōu)于基線方法(平均成功率 73.3%,而最佳基線方法僅實(shí)現(xiàn)了 45.0%)。此外,與沒有力學(xué)習(xí)的基線方法相比,平均絕對接觸力、力矩以及他們的平均方差均大幅減小,表明機(jī)器人與物體之間的接觸更安全、更穩(wěn)定。
該研究工作在模仿學(xué)習(xí)的背景下解決了真實(shí)物理世界移動操作任務(wù)中由不確定性和高維運(yùn)動學(xué)引起的挑戰(zhàn)性問題,提出了一種有效的視力覺模仿學(xué)習(xí)方法以解決復(fù)雜的接觸移動操作任務(wù)。在六個接觸約束的移動操作任務(wù)上進(jìn)行了系統(tǒng)的真實(shí)機(jī)器人實(shí)驗:在真實(shí)家庭環(huán)境中,MOMA-Force 在任務(wù)成功率方面明顯優(yōu)于基線方法(平均成功率 73.3%,而最佳基線方法僅實(shí)現(xiàn)了 45.0%)。此外,與沒有力學(xué)習(xí)的基線方法相比,平均絕對接觸力、力矩以及他們的平均方差均大幅減小,表明機(jī)器人與物體之間的接觸更安全、更穩(wěn)定。

- 項目主頁:https://visual-force-imitation.github.io/
- 論文地址:https://arxiv.org/abs/2308.03624
方法
訓(xùn)練神經(jīng)網(wǎng)絡(luò)能夠以端到端的方式生成動作,但由于動作精度和對噪聲響應(yīng)的低魯棒性,導(dǎo)致難以應(yīng)用于真實(shí)物理世界。另一方面,基于經(jīng)典控制的方法可以增強(qiáng)系統(tǒng)的魯棒性,但需要進(jìn)行大量繁瑣的參數(shù)調(diào)校。為了解決這些挑戰(zhàn),MOMA-Force 融合了用于視覺感知的表示學(xué)習(xí)(Representation Learning)、復(fù)雜運(yùn)動軌跡生成的模仿學(xué)習(xí)(Imitation Learning)以及阻抗全身控制(Admittance Whole Body Control),以實(shí)現(xiàn)系統(tǒng)的魯棒性和可控性。
MOMA-Force 的流程原理可以簡單描述為:
- 專家示教數(shù)據(jù)中的 RGB 觀測圖像通過視覺編碼器(visual encoder)轉(zhuǎn)換為表示向量 Ze。當(dāng)機(jī)器人在實(shí)時運(yùn)行過程中,末端操作器的 RGB 觀測圖像通過相同的視覺編碼器轉(zhuǎn)換為表示向量 Zt。
- 通過從專家數(shù)據(jù) Ze 中檢索匹配出與當(dāng)前實(shí)際觀測表示 Zt 最相似的表示索引 i,并抽取出索引 i 對應(yīng)的專家運(yùn)動行為(機(jī)器人末端位置姿態(tài))、夾爪開閉行為、力和力矩來作為當(dāng)前時刻機(jī)器人的局部行為目標(biāo)。
- 通過感知末端操作器當(dāng)前所受到的接觸力的大小、目標(biāo)力的大小以及目標(biāo)末端位姿,通過導(dǎo)納全身控制(Admittance Whole Body Control)生成機(jī)械臂關(guān)節(jié)和底盤輪速控制信號驅(qū)動機(jī)器人平穩(wěn)、安全地跟蹤目標(biāo)軌跡點(diǎn)完成任務(wù)。
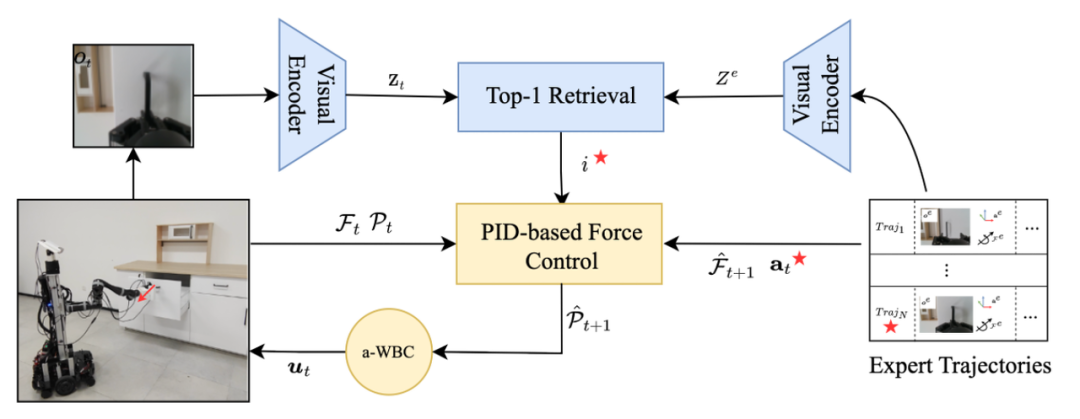
方法可以從兩個部分進(jìn)行拆解:
1. 目標(biāo)行為的預(yù)測:實(shí)時視覺觀測 -> 下個時刻機(jī)器人的狀態(tài)預(yù)測
機(jī)器人的目標(biāo)行為預(yù)測模塊建立在最前沿的模仿學(xué)習(xí)方法上。它由兩個階段組成:離線的 RGB 視覺觀測編碼和在線編碼運(yùn)算。
- 在離線階段,MOMA-Force 利用預(yù)訓(xùn)練的視覺編碼器(ibot)將專家軌跡中每幀的 RGB 觀測圖像投影到深度嵌入中。該嵌入即 RGB 視覺觀測的緊湊表示。
- 在在線階段,MOMA-Force 利用同樣的視覺編碼器將每個時間點(diǎn) t 所捕獲的 RGB 觀測圖像也進(jìn)行了編碼,并通過計算與專家數(shù)據(jù)編碼的相似度找出最相似的那一幀觀測,這幀觀測所對應(yīng)的機(jī)器人在三維空間中末端位姿、夾爪的狀態(tài)、六維力傳感數(shù)據(jù)、任務(wù)完成狀態(tài)等被匹配成為機(jī)器人當(dāng)前的目標(biāo)行為。
2. 導(dǎo)納全身控制:實(shí)時力覺觀測 -> 機(jī)械臂和底盤電機(jī)輸出
由于機(jī)器人定位的精準(zhǔn)度限制和目標(biāo)行為預(yù)測的瑕疵,導(dǎo)納全身控制用于為機(jī)器人系統(tǒng)形成基于力傳感的閉環(huán)。在帶有接觸約束的任務(wù)中,小的姿態(tài)誤差可能會導(dǎo)致大的接觸力以及扭矩,甚至造成不可逆的機(jī)械損傷。因此,通過阻抗控制去彌補(bǔ)目標(biāo)行為預(yù)測的不準(zhǔn)確能夠賦予移動操作機(jī)器人更加柔順、安全的行為。
具體而言,MOMA-Force 通過導(dǎo)納控制對預(yù)測出來的專家軌跡目標(biāo)點(diǎn)位姿進(jìn)行微調(diào),微調(diào)之后的軌跡點(diǎn)通過基于最優(yōu)控制的 QP 算法生成控制移動操作機(jī)器人整體構(gòu)型空間(機(jī)械臂的 7 個關(guān)節(jié)和底盤輪子)的速度指令。
真機(jī)實(shí)驗
實(shí)踐出真知,有關(guān) MOMA-Force 的能力邊界需要一系列嚴(yán)格且科學(xué)的實(shí)驗評測方式去進(jìn)行驗證。實(shí)驗的設(shè)計緊密圍繞機(jī)器人移動操作性能和機(jī)器人操作安全性兩個方面展開,同時也對比了不同的預(yù)訓(xùn)練視覺編碼器的效果。
Q:實(shí)驗如何展開?
A:作者在六個帶有接觸約束的任務(wù)上進(jìn)行了實(shí)驗:例如拉抽屜、旋轉(zhuǎn)水管、開洗衣機(jī)門、拉開柜門等。幾乎所有的任務(wù)都要求機(jī)器人在操作過程中移動底盤并且保持與物體持續(xù)的合理的接觸力。
作者為每個任務(wù)收集了 30 個專家演示:具體地說,對于每個時間點(diǎn)都記錄了機(jī)器人末端相機(jī)的 RGB 觀測圖像、末端位姿、夾爪動作。所有操作任務(wù)都可以分為三個階段:接近、抓取和接觸操作。如果在任務(wù)執(zhí)行過程中出現(xiàn)以下任一一種情況都會結(jié)束操作:1)完成任務(wù);2)超時;3)力大于 40N 或過去 1 秒鐘的平均力大于 30N。如果至少完成了一個任務(wù)軌跡長度的 80%,則認(rèn)為這次實(shí)驗成功。每種方法每個任務(wù)進(jìn)行了 10 次實(shí)驗。

Q:增加了力覺的模仿學(xué)習(xí)方法是否能夠?qū)崒?shí)在在地提升任務(wù)成功率?
A:MOMA-Force 方法在跟其它基線方法的對比中實(shí)現(xiàn)了最佳的平均成功率。與單任務(wù)行為克隆 BC(Behavior Cloning)方法相比,MOMA-Force 將任務(wù)成功率從 20% 提升到了 73.3%。有力覺的 MOMA-Force 對比無力覺的 MOMA-Force 成功率是 73.3% 比 45%。

以下視頻素材對比展示了 MOMA-Force 以及其它對照基線方法在真機(jī)上的表現(xiàn)效果:
行為克隆(BC):任務(wù)成功率較低

MOMA-Force 無力覺 :由于接觸力過大導(dǎo)致操作中斷

MOMA-Force

Q:從直覺上如何理解力覺模仿會帶來對任務(wù)成功率的提升?
A:當(dāng)機(jī)器人在執(zhí)行一些任務(wù)時,通過預(yù)訓(xùn)練模型預(yù)測的機(jī)器人未來狀態(tài)總是不完全準(zhǔn)確的,加上機(jī)器人在移動過程中底盤定位誤差,機(jī)器人動力學(xué)導(dǎo)致的狀態(tài)誤差等等都會使得末端夾爪的位置不準(zhǔn)確,進(jìn)而使得末端與操作物體(比如門把手)接觸時存在較大的應(yīng)力。由于機(jī)器人夾爪和物體是硬接觸的,一點(diǎn)微小的位置姿態(tài)誤差都會造成很大的接觸應(yīng)力,這樣的接觸應(yīng)力超過一定閾值后可能會對機(jī)器人造成不可逆的機(jī)械損傷,這樣就判定這種情況為失敗。只有加入了力覺模仿學(xué)習(xí)的方案才能夠使得機(jī)器人調(diào)整姿態(tài)釋放掉末端的接觸應(yīng)力,也就大大避免了在操作過程中因為應(yīng)力過大而失敗的情況。
Q:MOMA-Force 相比 BC 以及沒有力覺模仿的方案,力傳感的數(shù)據(jù)是怎樣的呢?
A:實(shí)驗對比了 MOMA-Force 和其它幾個基線方法。對于所有的方法,作者計算了在六個任務(wù)中所有成功的實(shí)驗的平均絕對接觸力、力矩和平均力、力矩方差,然后對任務(wù)進(jìn)行平均(如圖)。較小的力、力矩方差表示執(zhí)行任務(wù)過程中更穩(wěn)定的接觸。MOMA-Force(紅色柱子)在 x、y 和 z 軸上的平均絕對接觸力和力矩都是最小的,且方差也是最小的。

Q:不同的預(yù)訓(xùn)練視覺編碼器在真實(shí)機(jī)器人數(shù)據(jù)上表現(xiàn)的對比如何?
A:實(shí)驗通過對比各種 SOTA 的預(yù)訓(xùn)練模型作為視覺編碼器在 5 倍交叉驗證的測試集上的均方誤差(MSE)來比較不同的視覺預(yù)訓(xùn)練編碼器的有效性,表格 II 展示了結(jié)果。MVP(Masked Visual Pretraining)是基于 masked auto-encoder 通過互聯(lián)網(wǎng)視頻數(shù)據(jù)進(jìn)行的預(yù)訓(xùn)練的。CLIP 旨在通過對比學(xué)習(xí)(contrastive learning)將圖像表示與文本對齊。同樣由字節(jié)跳動提出的 iBOT 通過在線標(biāo)記器(online tokenizer)在 masked auto-encoder 和對比學(xué)習(xí)之間取得了良好的平衡。由于 iBOT 以自蒸餾的方式進(jìn)行掩膜圖像建模,并通過對圖像使用在線 tokenizer 進(jìn)行 BERT 式預(yù)訓(xùn)練,讓 CV 模型獲得了通用廣泛的特征表達(dá)能力。表格 II 顯示 iBOT 的特征表示能力十分有效,在實(shí)驗任務(wù)中取得了最佳的表現(xiàn)性能。