













再亂用緩存,CTO可就發飆了!
本文轉載自微信公眾號「小姐姐味道」,作者小姐姐養的狗02號 。轉載本文請聯系小姐姐味道公眾號。
今天總監很生氣,原因是強調了很多年的緩存同步方案,硬是有人不按常理出牌,挑戰權威。最終出了問題,這讓總監很沒面子。
"一群人拿著大老板的賬號在哪里瞎測,結果把數據搞出問題來了吧",總監牛鼻子里噴著氣,叉著腰說。自從老板的賬號有一次參與測試之后,就成了大家心照不宣的終極測試賬號。很多人用,硬生生把一個賬號的余額操作,給搞成了高并發的。
"老板的賬號不就是個測試賬號么...",下面有人小聲的嘀咕。
"現實中哪會有賬號有這樣的密集型操作的...",又有人小聲嘀咕,讓總監的臉色越來越沉。
"你們覺得我在開玩笑么?",總監紅著眼說,“我就曾經因為這樣的數據不一致問題,吃過一個一級故障。正好,今天就帶你們了解一下,為什么會有數據不一致的情況吧”。
我扶著眼鏡搖搖晃晃的做到臺下,心中暗笑,總監又要把Cache Aside Pattern給科普一遍了。
1. 為什么數據會不一致?
數據庫的瓶頸是大家有目共睹的,高并發的環境下,很容易I/O鎖死。當務之急,就是把常用的數據,給撈到速度更快的存儲里去。這個更快的存儲,就有可能是分布式的,比如Redis,也有可能是單機的,比如Caffeine。
但一旦加入緩存,就不得不面對一個蛋疼的問題:數據的一致性。
數據不一致的問題,人世間多了去了。進修過Java多線程的同學,肯定會對JMM的模型記憶猶新。一個數值,只要同時在兩個地方存儲,那就會產生問題。
但緩存系統和數據庫,比JMM更加的不可靠。因為分布式組件更加的脆弱,它隨時都可能發生問題。
2. Cache Aside Pattern
怎樣保證數據在DB和緩存中的一致性呢?現在一個比較好的最佳實踐方案,就是Cache Aside Pattern。
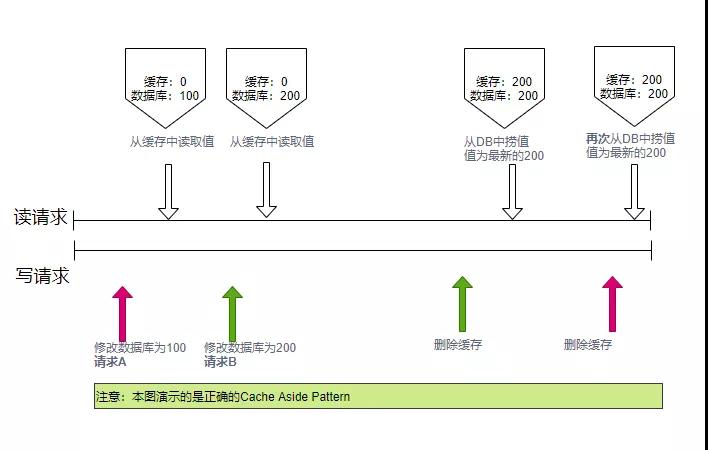
先來看一下數據的讀取過程,規則是:先讀cache,再讀db 。詳細步驟如下:
- 每次讀取數據,都從cache里讀
- 如果讀到了,則直接返回,稱作 cache hit
- 如果讀不到cache的數據,則從db里面撈一份,稱作cache miss
- 將讀取到的數據,塞入到緩存中,下次讀取的時候,就可以直接命中
再來看一下寫請求。規則是:先更新db,再刪除緩存 。詳細步驟如下:
- 將變更寫入到數據庫中
- 刪除緩存里對應的數據
說到這里,我看著有幾個人皺起了眉頭。我知道,肯定會有人不服氣,認為自己那一套是對的。比如,為什么是刪除緩存,不是更新緩存呢?效率會不會更低?為什么不先刪除緩存再更新數據庫?
好家伙,他們要向總監發問了。
3. 為什么是刪除緩存,而不是更新緩存?
這個比較好理解。當多個更新操作同時到來的時候,刪除動作,產生的結果是確定的;而更新操作,則可能會產生不同的結果。
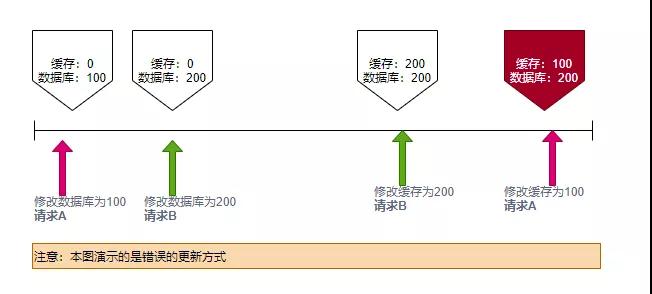
如圖。兩個請求A和B,請求B在請求A之后,數據是最新的。由于緩存的存在,如果在保存的時許發生稍許的偏差,就會造成A的緩存值覆蓋了B的值,那么數據庫中的記錄值,和緩存中的就產生了不一致,直到下一次數據變更。
而使用刪除的方式,由于緩存會miss,所以會每次都會從db中獲取最新的數據進行填充,與緩存操作的時機關系不大。
4. 為什么不先刪緩存,再更新數據庫?
這個問題是類似的。我們甚至都不需要并發寫的場景就能發現問題。
我們上面提到的緩存刪除動作,和數據庫的更新動作,明顯是不在一個事務里的。如果一個請求刪除了緩存,同時有另外一個請求到來,此時發現沒有相關的緩存項,就從數據庫里加載了一份到緩存系統。接下來,數據庫的更新操作也完成了,此時數據庫的內容和緩存里的內容,就產生了不一致。
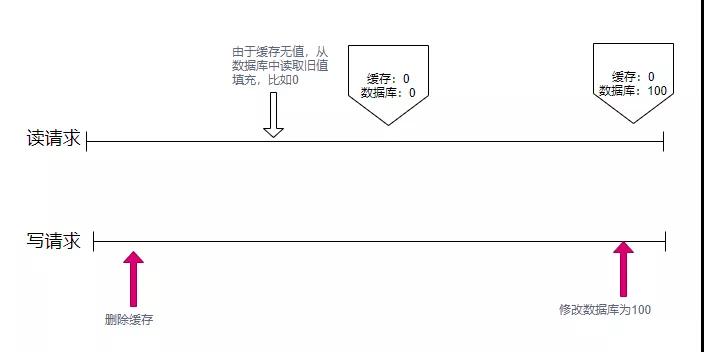
如上圖,寫請求首先刪除了緩存。結果在這個時候,有其他的讀請求,將數據庫的舊值,讀取到數據庫中,此時緩存中的數據是0。接下來更新了DB,將數據庫記錄改為了100。經過這么一哆嗦,數據庫和緩存中的數據,就產生了不一致。
大家都恍然大悟的點點頭,不少人露出了迷之微笑。
5. Spring中的緩存注解
使用 SpringBoot 可以很容易地對 Redis 進行操作,Java 的 Redis的客戶端,常用的有三個:jedis、redisson 和 lettuce,Spring 默認使用的是 lettuce。
很多人,喜歡使用Spring 抽象的緩存包 spring-cache。
它使用注解,采用 AOP的方式,對 Cache 層進行了抽象,可以在各種堆內緩存框架和分布式框架之間進行切換。這是它的 maven 坐標:
- <dependency>
- <groupId>org.springframework.boot</groupId>
- <artifactId>spring-boot-starter-cache</artifactId>
- </dependency>
使用 spring-cache 有三個步驟:
- 在啟動類上加入 @EnableCaching 注解;
- 使用 CacheManager 初始化要使用的緩存框架,使用 @CacheConfig 注解注入要使用的資源;
- 使用 @Cacheable 等注解對資源進行緩存。
而針對緩存操作的注解,有三個:
- @Cacheable 表示如果緩存系統里沒有這個數值,就將方法的返回值緩存起來;
- @CachePut 表示每次執行該方法,都把返回值緩存起來;
- @CacheEvict 表示執行方法的時候,清除某些緩存值。
那么問題來了,spring-cache中的@CacheEvict注解,到底是先刪緩存,還是后刪緩存呢?不弄明白這一點,真的是讓人夜不能寐。關鍵技術嘛,不僅要用的開心,也要用的放心。
緩存的移除,是在CacheAspectSupport中實現的,我們注意到下面的代碼。
- // Process any early evictions
- processCacheEvicts(contexts.get(CacheEvictOperation.class), true,
- CacheOperationExpressionEvaluator.NO_RESULT);
- ...
- // Process any late evictions
- processCacheEvicts(contexts.get(CacheEvictOperation.class), false, cacheValue);
它有一個前置的清除動作,還有后置的清除動作,是通過一個bool變量boolean beforeInvocation進行設置的。這個值從哪里來的呢?還是得看@CacheEvict注解。
- /**
- * Whether the eviction should occur before the method is invoked.
- * <p>Setting this attribute to {@code true}, causes the eviction to
- * occur irrespective of the method outcome (i.e., whether it threw an
- * exception or not).
- * <p>Defaults to {@code false}, meaning that the cache eviction operation
- * will occur <em>after</em> the advised method is invoked successfully (i.e.,
- * only if the invocation did not throw an exception).
- */
- boolean beforeInvocation() default false;
很好很好,它的默認值是false,證明刪除動作是滯后的,踐行的也是Cache Aside Pattern。
6. 還有其他模式?
我聽說,還有Read Through Pattern,Write Through Pattern,Write Behind Caching Pattern等其他常見的緩存同步模式,為什么不用這些呢? 有位同學的屁股一直在椅子上來回挪動,躍躍欲試,逮住機會,他終于發言了。
其實,這些方式使用的也非常廣泛,但由于對業務大多數是無感知的,所以很多人都忽略了。換句話說,這幾個模式,大多數是在一些中間件,或者比較底層的數據庫中實現的,寫業務代碼可能接觸不到這些東西。
比如,Read Through,其實就是讓你對讀操作感知不到緩存層的存在。通常情況下,你會手動實現緩存的載入,但Read Through可能就有代理層給你捎帶著做了。
再比如,Write Through,你不用再考慮數據庫和緩存是不是同步了,代理層都給你做了,你只管往里塞數據就行。
Read Through和Write Through是不沖突的,它們可以同時存在,這樣業務層的代碼里就沒有同步這個概念了。爽歪歪。
至于Write Behind Caching,意思就是先落地到緩存,然后有異步線程緩慢的將緩存中的數據落地到DB中。要用這個東西,你得評估一下你的數據是否可以丟失,以及你的緩存容量是否能夠經得起業務高峰的考驗。現在的操作系統、DB、甚至消息隊列如Kafaka等,都會在一定程度上踐行這個模式。
但它現在和我們的業務需求沒半點關系。
7. Cache Aside Pattern也有問題
總監上馬,一個頂倆,科普了這半天,所有的同學都心服口服。正在大家想要把掌聲送給總監的時候,一個不和諧的聲音傳來了。
我發現了一個天大的問題。 有同學說, 如果數據庫更新成功了,但緩存刪除失敗了,也會造成緩存不一致。
這個問題問的好啊,故障大多數就是由于這些極端情況造成的。這個時候就有意思了,我們要拼概率,畢竟沒有100%的安全套。 總監笑了。
方法一:將數據更新和緩存刪除動作,放在一個事務里,同進退。
方法二:緩存刪除動作失敗后,重試一定的次數。如果還是不行,大概率是緩存服務的故障,這時候要記錄日志,在緩存服務恢復正常的時候將這些key刪除掉
方法三:再多一步操作,先刪緩存,再更新數據,再刪緩存。這樣雖然操作多一些,但也更保險一些。
是不是沒有問題了? 總監環顧四周,看到大家都在點頭。No no no,依然還有數據不一致的情況。
所有人都一頭霧水。
上面那張看起來正確的圖,其實是錯誤的。為什么呢?因為數據在從數據庫讀到緩存中的操作,并不是原子性的。
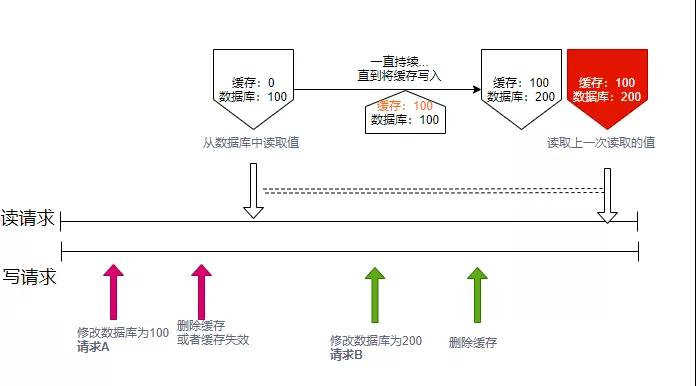
比如上圖,當緩存失效(或者被刪除)的時候,有一個讀請求正好到來。這個讀請求,拿到了舊的數據庫值,但它由于多方面的原因(比如網絡抽風),沒有立馬寫入到緩存中,而是發生了延遲。在它打算寫入到緩存的這段時間,發生了很多事情,有另外一個請求,將數據庫的值更新為200,并刪除了緩存。
直到第二個請求全部完成,第一個請求寫入緩存的操作,才真正落地。但其實,這時候數據庫和緩存的值,已經不是同步的了。
那么為什么大家在平常的設計中,幾乎把這個場景給忽略掉了呢?因為它發生的概率實在太低了。它要求在讀取數據的時候,有兩個或者多個并發寫操作(或者發生了數據失效),這在實際的應用場景中實在是太少了。而且,我們要注意虛線所持續的周期,是一個數據庫的更新操作,加上一個cache的刪除操作,這個操作一般情況下,也會比緩存的設置持續的時間長,所以進一步降低了概率。
所以,你們知道正確的操作方式了么? 總監問。
知道了!以后我們就用spring-cache的注解去完成工作,再也不在代碼中手寫一致性邏輯了。
很好很好,如果這么做的話,再發生問題,好像可以把鍋甩給spring團隊了呢。
作者簡介:小姐姐味道 (xjjdog),一個不允許程序員走彎路的公眾號。聚焦基礎架構和Linux。十年架構,日百億流量,與你探討高并發世界,給你不一樣的味道。我的個人微信xjjdog0,歡迎添加好友,進一步交流。
















