













無需密集人工標簽,用于下游密集預測任務的自監督學習方法出爐
預訓練已被證實能夠大大提升下游任務的性能。傳統方法中經常利用大規模的帶圖像標注分類數據集(如 ImageNet)進行模型監督預訓練,近年來自監督學習方法的出現,讓預訓練任務不再需要昂貴的人工標簽。然而,絕大多數方法都是針對圖像分類進行設計和優化的。但圖像級別的預測和區域級別 / 像素級別存在預測差異,因此這些預訓練模型在下游的密集預測任務上的性能可能不是最佳的。
基于此,來自阿德萊德大學、同濟大學、字節跳動的研究者設計了一種簡單且有效的密集自監督學習方法,不需要昂貴的密集人工標簽,就能在下游密集預測任務上實現出色的性能。目前該論文已被 CVPR 2021 接收。
論文地址:
https://arxiv.org/pdf/2011.09157
代碼地址:
https://github.com/WXinlong/DenseCL
方法
該研究提出的新方法 DenseCL(Dense Contrastive Learning)通過考慮局部特征之間的對應關系,直接在輸入圖像的兩個視圖之間的像素(或區域)特征上優化成對的對比(不相似)損失來實現密集自監督學習。

兩種用于表征學習的對比學習范式的概念描述圖。
現有的自監督框架將同一張圖像的不同數據增強作為一對正樣本,利用剩余圖像的數據增強作為其負樣本,構建正負樣本對實現全局對比學習,這往往會忽略局部特征的聯系性與差異性。該研究提出的方法在此基礎上,將同一張圖像中最為相似的兩個像素(區域)特征作為一對正樣本,而將余下所有的像素(區域)特征作為其負樣本實現密集對比學習。
具體而言,該方法去掉了已有的自監督學習框架中的全局池化層,并將其全局映射層替換為密集映射層實現。在匹配策略的選擇上,研究者發現最大相似匹配和隨機相似匹配對最后的精度影響非常小。與基準方法 MoCo-v2[1] 相比,DenseCL 引入了可忽略的計算開銷(僅慢了不到 1%),但在遷移至下游密集任務(如目標檢測、語義分割)時,表現出了十分優異的性能。DenseCL 的總體損失函數如下:
模型性能
該研究進行消融實驗評估了匹配策略對下游任務的性能影響,結果如下表所示。
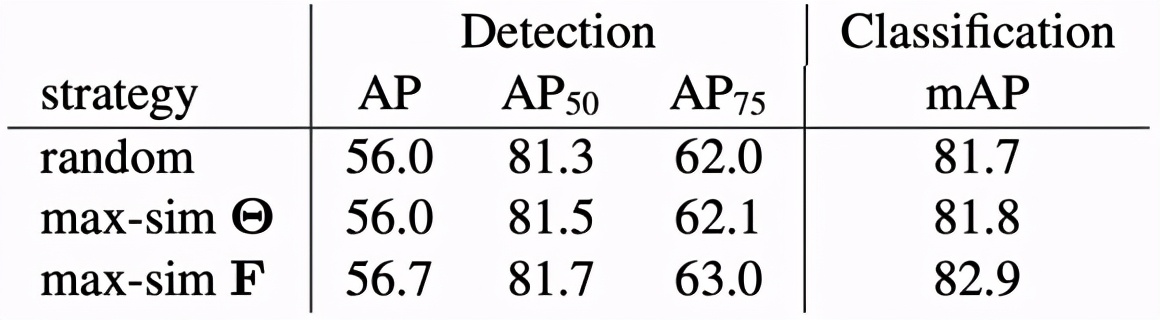
另一組消融實驗評估了預訓練區域數量對下游任務的性能影響,結果如下表所示。
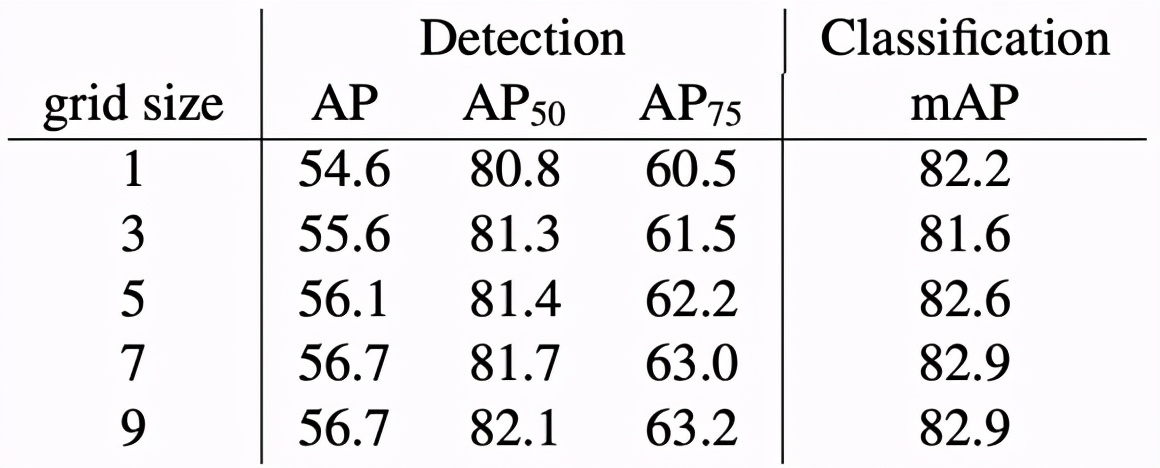
下圖展示了該方法遷移至下游密集任務的性能增益:
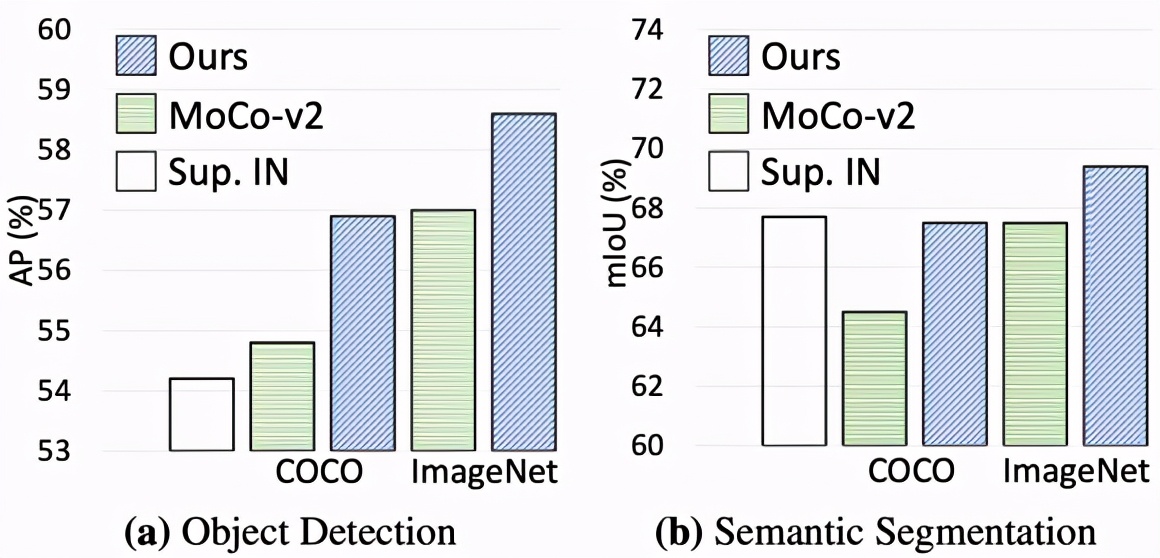
隨著訓練時間的延長,該研究進一步提供了與基線的直觀比較,表明 DenseCL 始終比 MoCo-v2 的性能高出至少 2%:
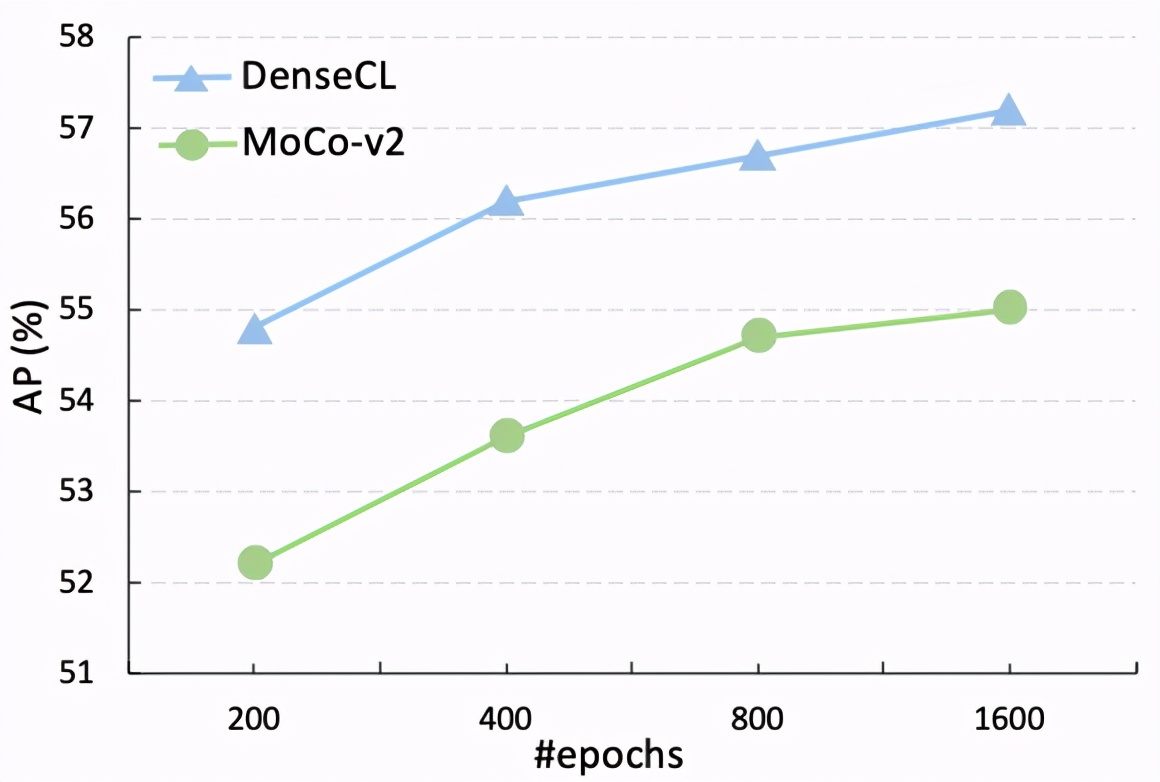
DenseCL 與 MoCo-v2 的預訓練時間消耗對比如下:
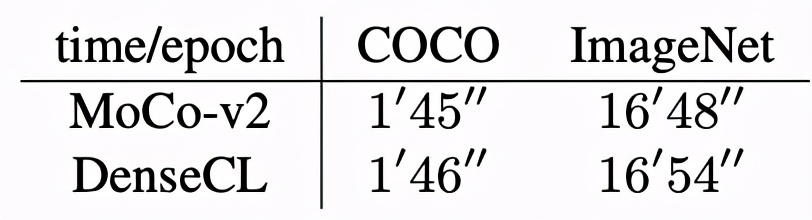
下圖對高相似度匹配進行了可視化,旨在描述局部語義特征間的對應關系:

如下圖所示,帶有隨機初始化的大多數匹配都是不正確的,從圖中可以看出隨著訓練時間的變化,對應關系發生了改變。

[1] Improved baselines with momentum contrastive learning. Chen, Xinlei and Fan, Haoqi and Girshick, Ross and He, Kaiming























