













用 Python 寫的文檔批量翻譯工具,效果竟然超越付費軟件?
一、需求描述
手上有大量外文文檔(本案例以5份為例,分別命名為 test1.docx test2.docx 以此類推),其中一份如下:

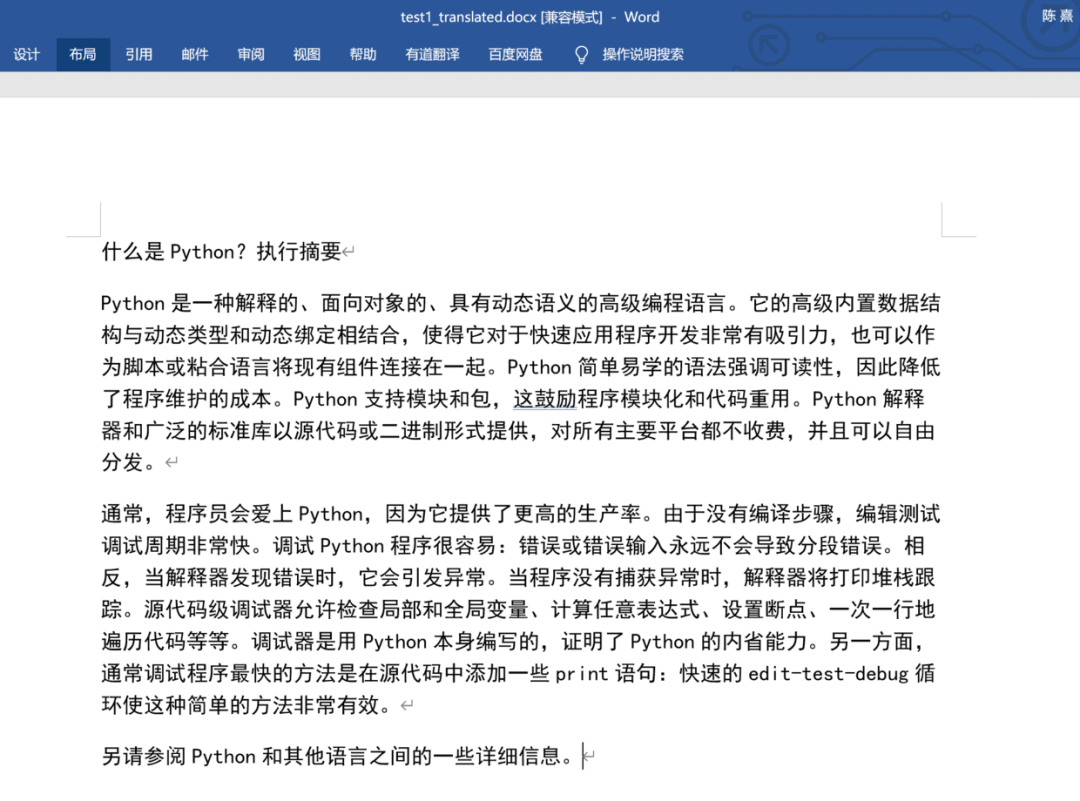
基本需求:「批量將這些文檔的內容全部翻譯成中文,并轉存到新的文件中」,效果如下:

高級需求:基本需求滿足的同時,要求 「保留原文檔的格式」,效果如下:

二、邏輯梳理
1. 翻譯 API
本需求的核心是翻譯,策略是利用網(wǎng)絡的翻譯 API,這里推薦百度翻譯開放平臺,不考慮并發(fā)數(shù)的話可以用標準版,免費使用不限字符量!
百度翻譯開放平臺:http://api.fanyi.baidu.com/api/trans/product/index
在使用百度的通用翻譯 API 之前需要完成以下工作:
- 使用百度賬號登錄百度翻譯開放平臺(http://api.fanyi.baidu.com);
- 注冊成為開發(fā)者,獲得APPID;
- 進行開發(fā)者認證(如僅需標準版可跳過);
- 開通通用翻譯API服務:開通鏈接
- 參考技術文檔和Demo編寫代碼
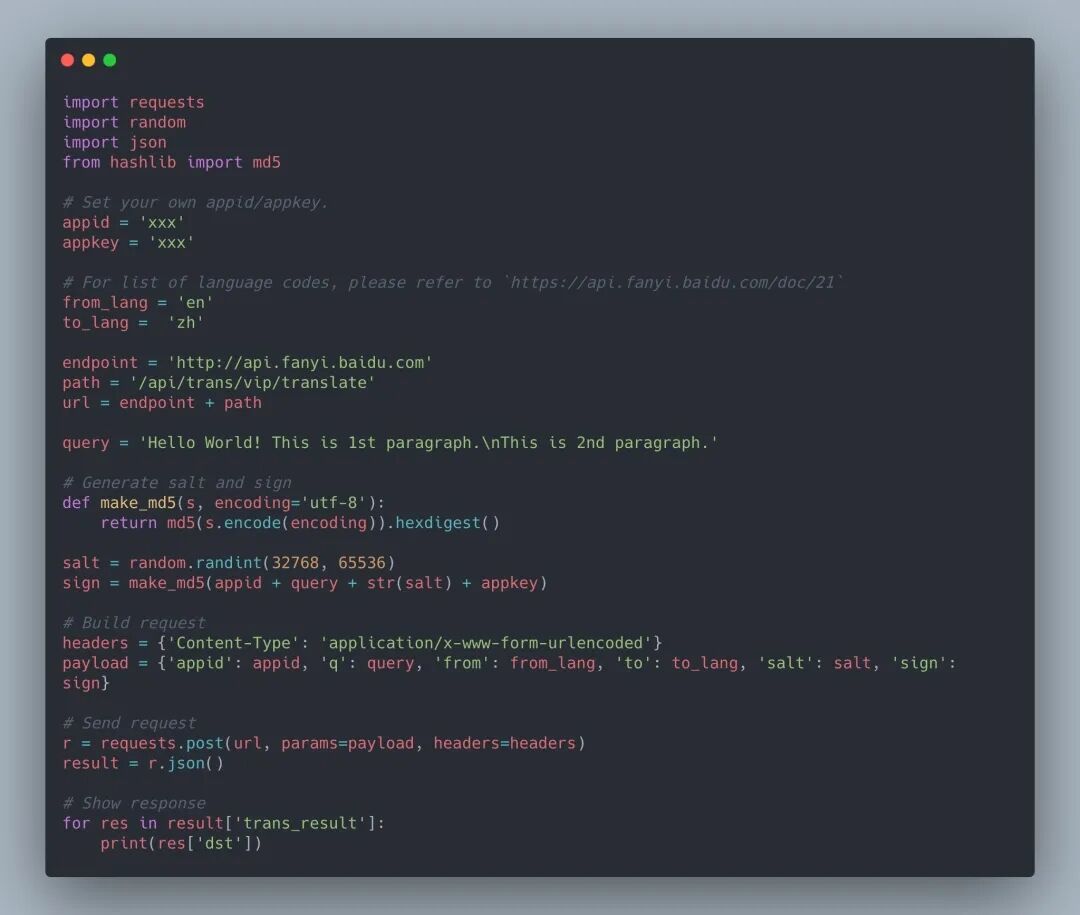
完成后在個人頁面在即可看到 ID 和密鑰,這個很重要!下面給出整理好的通用翻譯 API 的 demo,已經(jīng)對輸出做簡單修改,代碼拿走就能用!
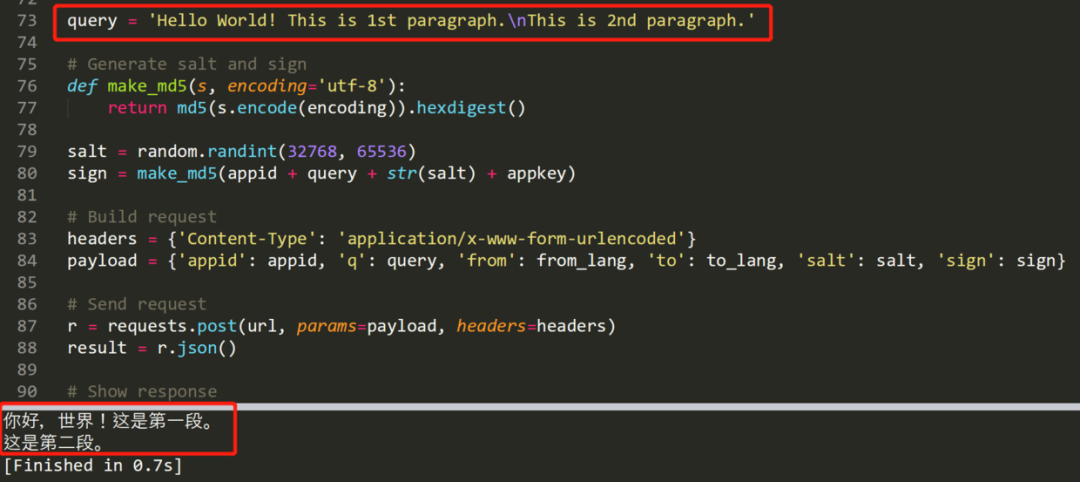
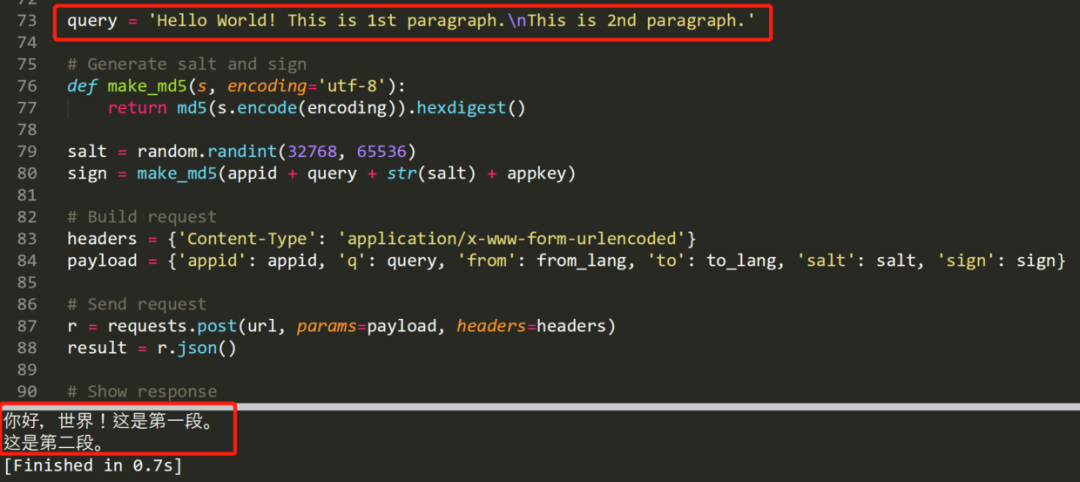
可以看到,測試內容準確的被翻譯出來,注意如果需要多次訪問 API,免費版有并發(fā)數(shù)和時間限制,可以用 time 模塊睡眠一秒。
2. 格式修改
高級需求的難點就是保留格式,簡單來說原文檔的頁面格式和段落格式是什么,翻譯后對應的部分就是什么。
基于上述的邏輯關系,只需要獲取原文檔的對應內容再賦值給新翻譯的文檔即可。(暫時只能滿足頁面設置和段落設置的統(tǒng)一,針對一段中特定詞語的格式修改,保證精確性需要基于自然語言處理NLP,本文暫不涉及)
2.1 頁面樣式
頁面樣式只要包括邊距、方向、高度、寬度等等,從原文檔中可以看到,采取的是窄邊距。但我們無需知道窄邊距四個方向應該如何設置,只需要在代碼中呈現(xiàn)新舊文檔的變量傳遞即可,具體如下:
2.2 段落樣式
段落樣式包括對齊、縮進、間距等等,原文檔中采取了段后縮進,標題是居中對齊。這些設置在變量傳遞中能夠很好完成。如果原文檔中沒有設置的變量值為 None。
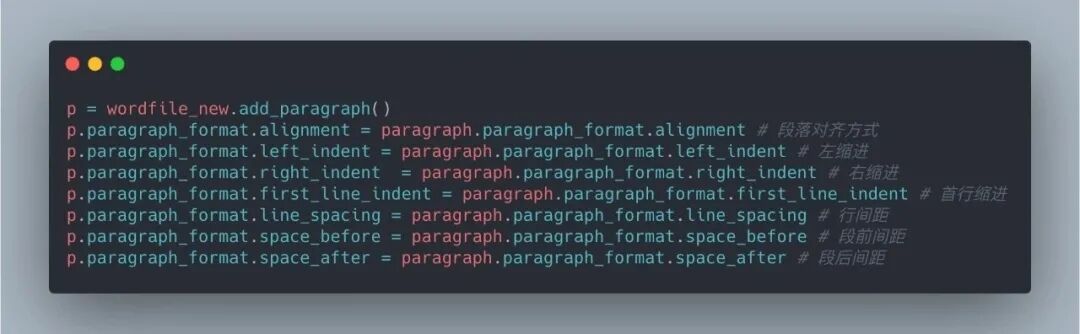
2.3 文字塊樣式修改
對于字號、加粗、斜體、顏色等樣式調整,采取的策略是建立空列表,遍歷原文檔每一段每一個文字塊,獲取相應屬性并放到各自的列表中,對同一段而言,其包含的文字塊屬性最多的選項賦值給翻譯后文檔的對應段落(如同一段全部或大部分的文字是加粗,則翻譯后對應段落所有文字塊均設置為加粗) 對NLP感興趣的讀者可自行嘗試如何高度還原英文文檔中某些特定詞語的樣式修改,并在翻譯后的文檔中體現(xiàn)出來。
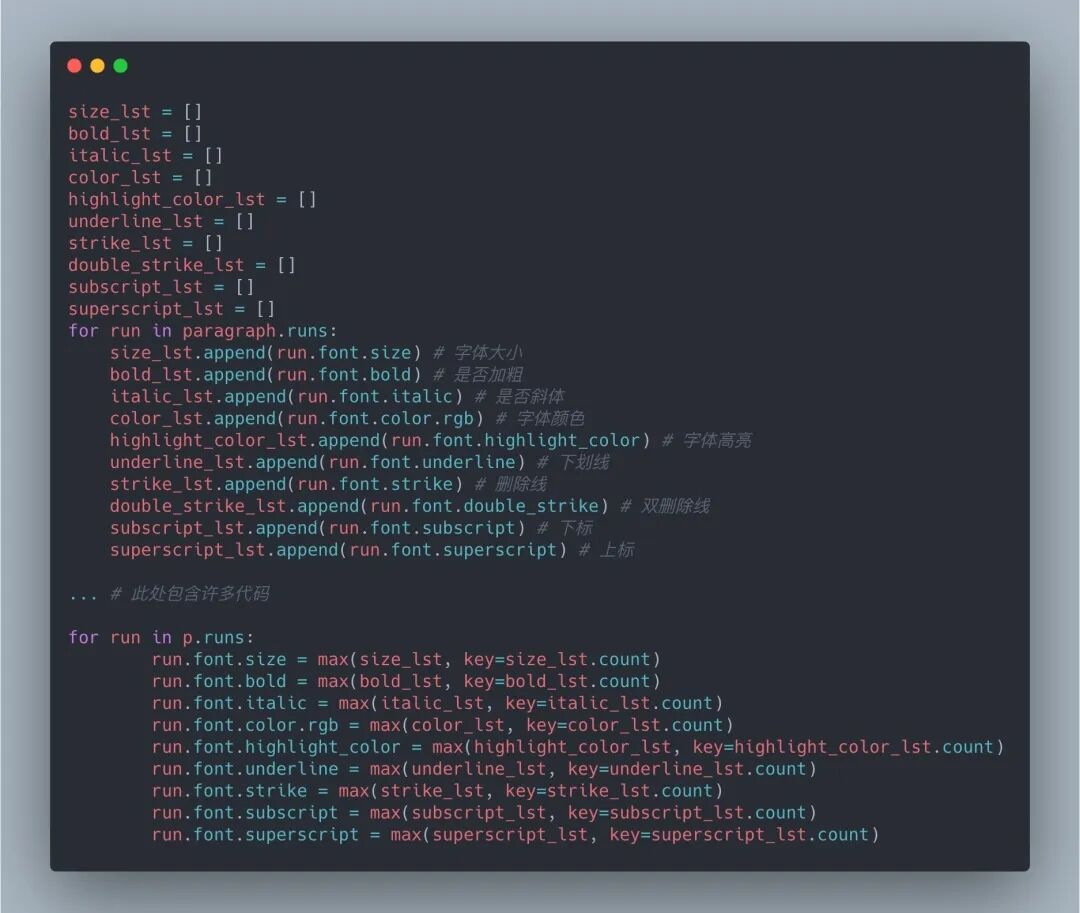
上面的代碼不包含對字體的設置,因為沒必要把英文的字體傳遞給中文文檔。對中文字體的設置之前的文章有提到過,比較復雜,直接見代碼:
- from docx.oxml.ns import qn
- run.font.name = '微軟雅黑'
- r = run._element.rPr.rFonts
- r.set(qn('w:eastAsia'), '微軟雅黑')
3. 整體實現(xiàn)步驟
現(xiàn)在每個部分操作均以完成,考慮到本例中有多個文檔均需要翻譯,故全部邏輯如下:
- 利用 glob 模塊批處理框架可獲取某個文件的絕對路徑
- 由 python-docx 完成 Word 文件實例化后對段落進行解析
- 解析出的段落文本交給百度通用翻譯 API,解析返回的 Json 格式結果(上面的修改 demo 中已經(jīng)完成了這一步)并重新寫入新的文件
- 同個文件全部解析、翻譯并寫入新文件后保存文件
三、代碼實現(xiàn)
導入需要的模塊,除翻譯 demo 中需要的庫外還需要 glob 庫批量獲取文件、python-docx 讀取文件、time 模塊控制訪問并發(fā)。為什么要 os 模塊見下文:
- import requests
- import random
- import json
- from hashlib import md5
- import time
- from docx import Document
- import glob
- import os
對原 demo 的部分內容進行保留,涉及到 query 參數(shù)的代碼需要移動到后面的循環(huán)中。保留的部分:
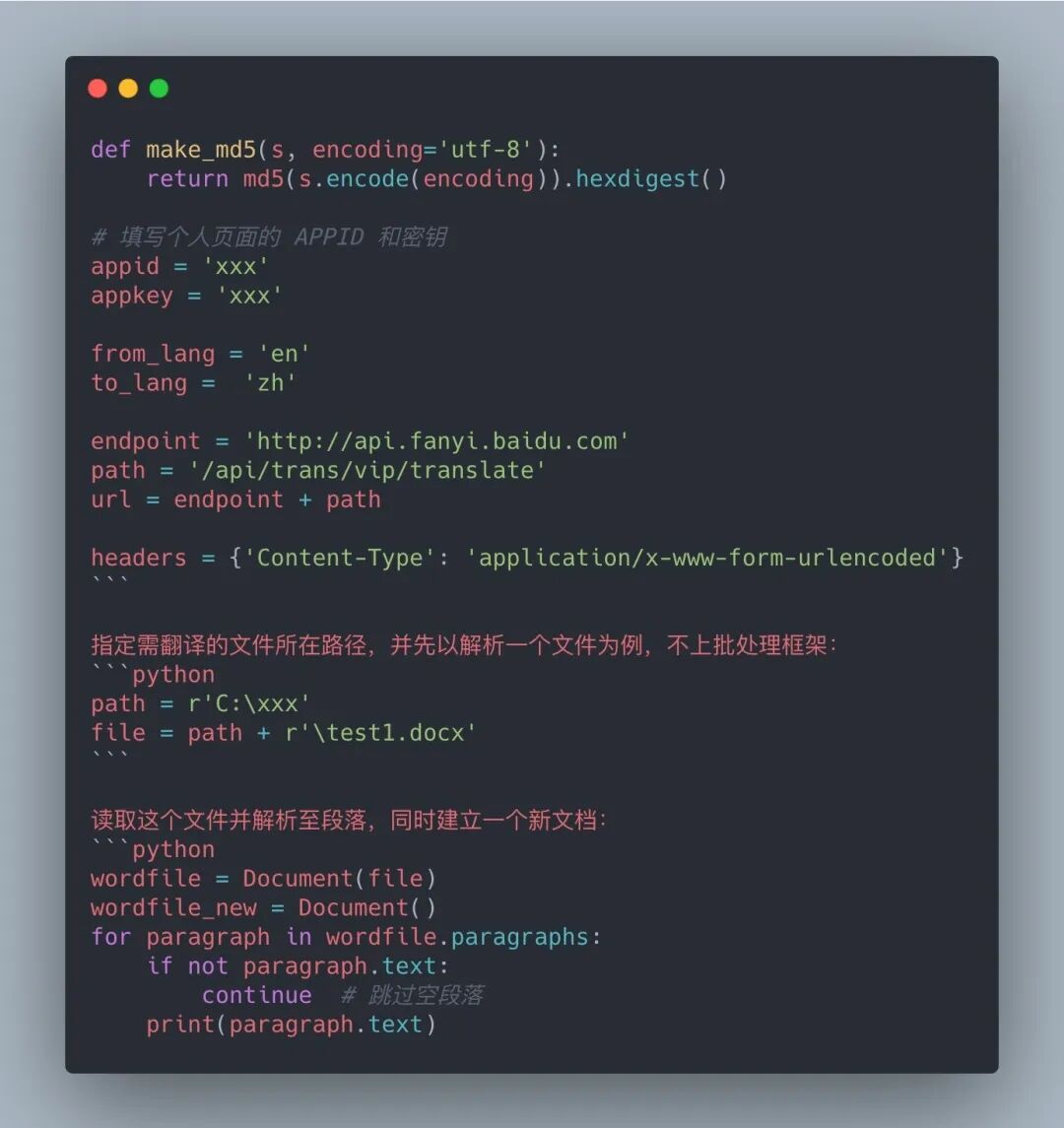
效果如下:

獲取到段落文本后,可以將段落文本賦值給 query 參數(shù),調用 API demo 的后續(xù)代碼。輸出結果的同時用 add_paragraph 將結果寫入新文檔:
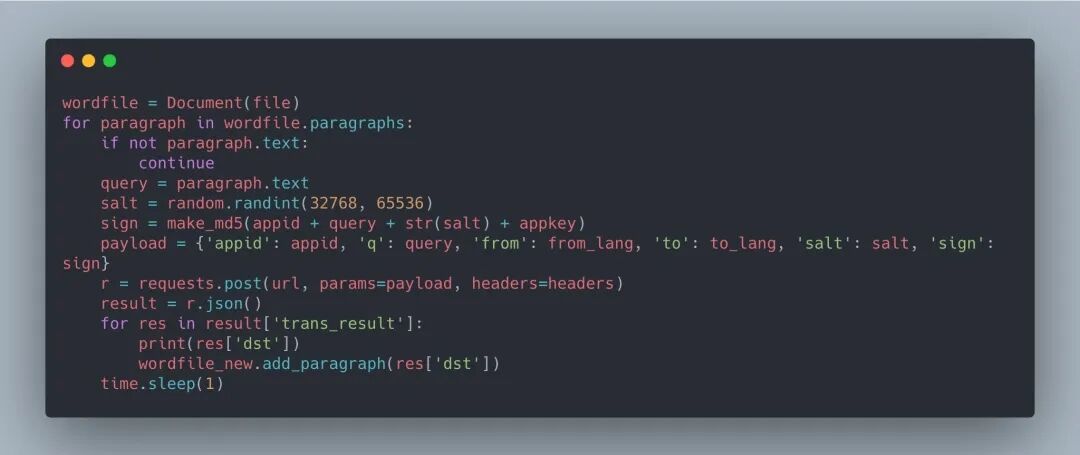
最后保存成新文件,期望命名為 原文件名_translated 的形式,可用 os.path.basename 方法獲取并經(jīng)字符串拼接達到目的:
- wordfile_new.save(path + r'\\' + os.path.basename(file)[:-5] + '_translated.docx')
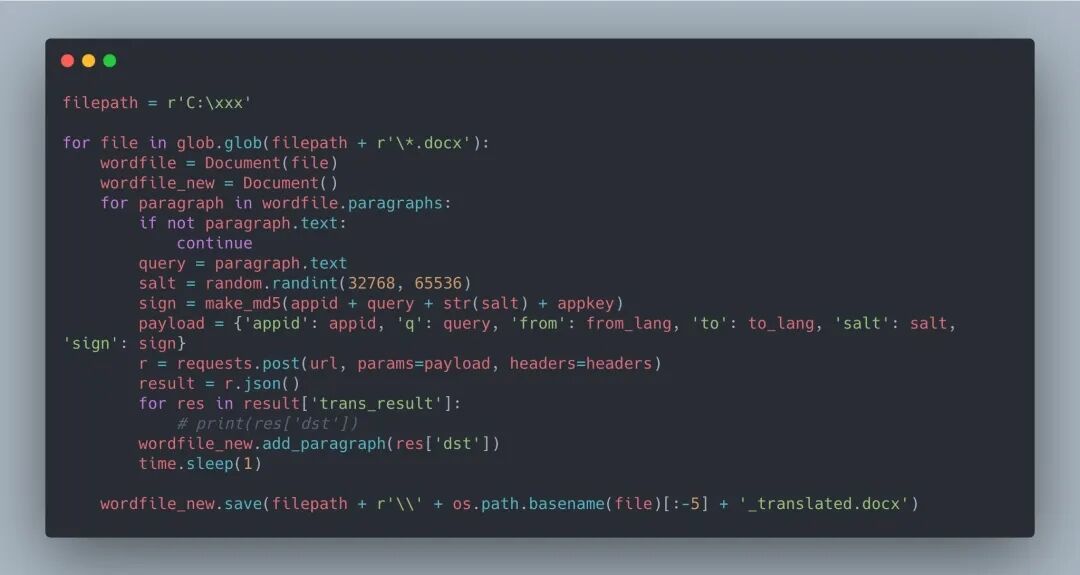
單個文件操作完成后將讀取和創(chuàng)建文件的代碼塊放到批處理框架內:
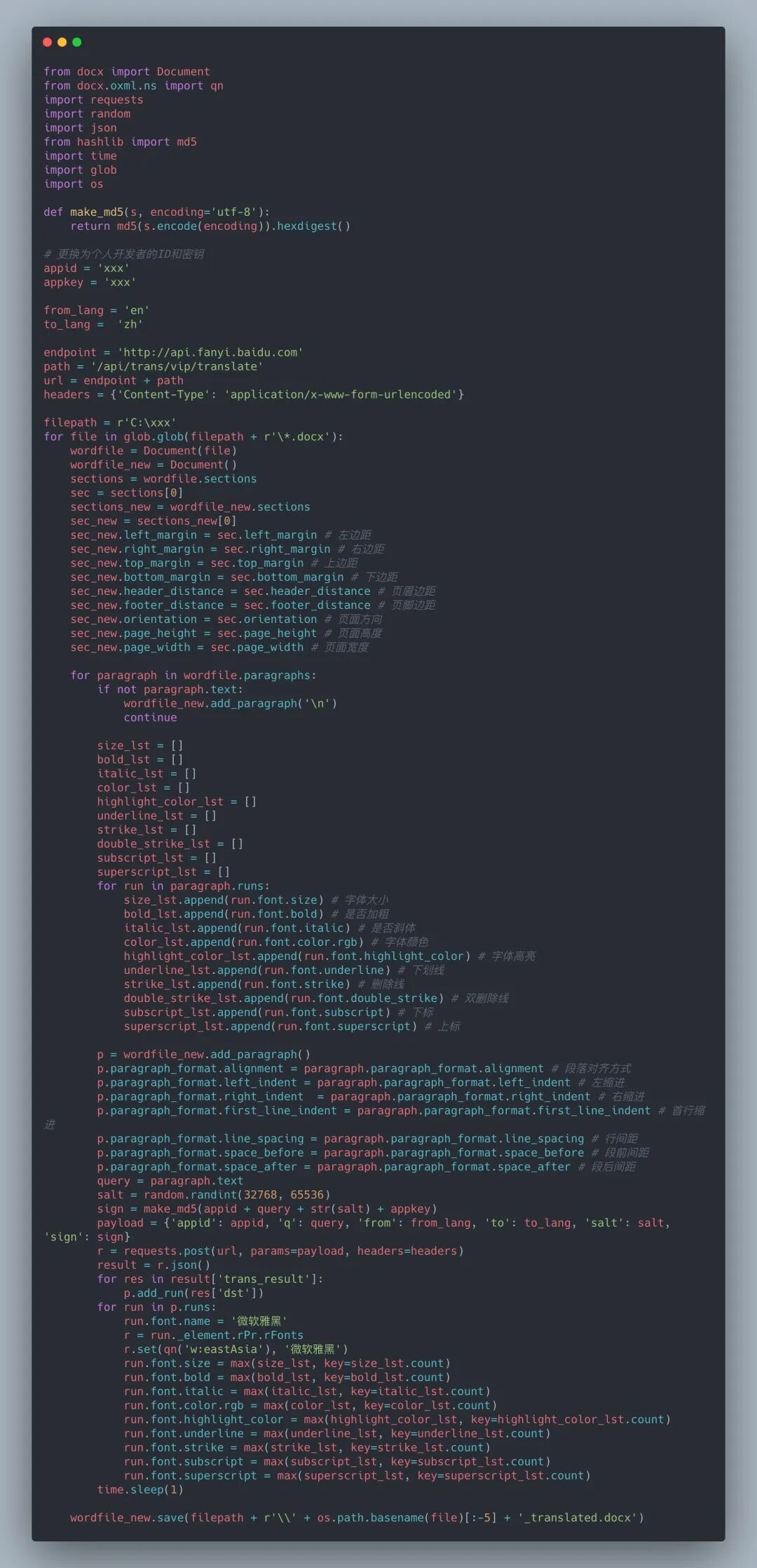
完成了上面的內容后,基本需求就完成了。根據(jù)我們梳理的對樣式的修改知識,再把樣式調整的代碼加進來就行了,最終完整代碼如下:
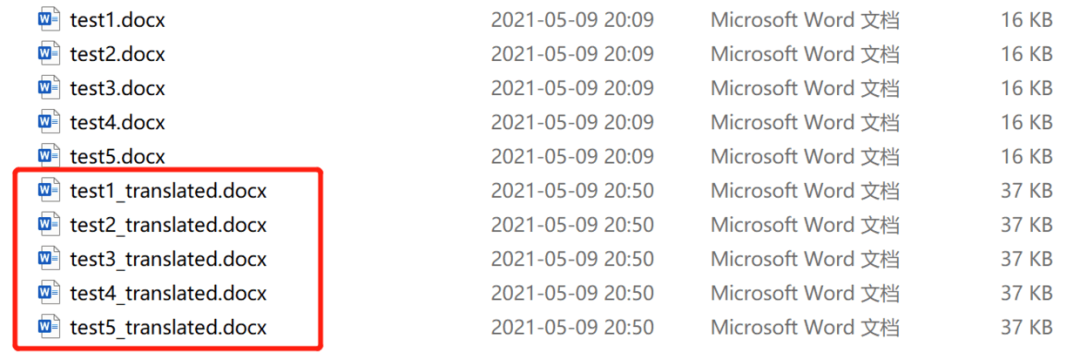
代碼運行完畢后得到五個新的翻譯后文件:
翻譯效果如下,可以看到英文被翻譯成中文,并且樣式大部分保留!

至此,所有文檔都被成功翻譯,當然這是機器翻譯的,具體應用時還需要對關鍵部分進一步人工調整,不過整體來說還是一次成功的Python辦公自動化嘗試!
















