













了解 HTTP/1.x 的 keep-alive 嗎?它與 HTTP/2 多路復用的區別是什么?
本文轉載自微信公眾號「三分鐘學前端」,作者sisterAn。轉載本文請聯系三分鐘學前端公眾號。
引言
本文分為以下三部分循序漸進走進 HTTP/1.x 的 keep-alive 與 HTTP/2 多路復用:
- HTTP/1.x keep-alive 是什么
- HTTP/2 多路復用
- HTTP/1.x keep-alive 與 HTTP/2 多路復用區別
下面正式開始吧
HTTP/1.x keep-alive 是什么
在一文走進 TCP 與 HTTP 中,我們介紹過,HTTP 協議是建立在 TCP 協議上的應用層協議, HTTP 協議最初是一個非常簡單的協議,通信方式也是采取簡答的請求-應答的模式,即:客戶端與服務器端的的每次請求都需要創建 TCP 連接,服務器響應后斷開 TCP 連接,再請求再創建斷開。
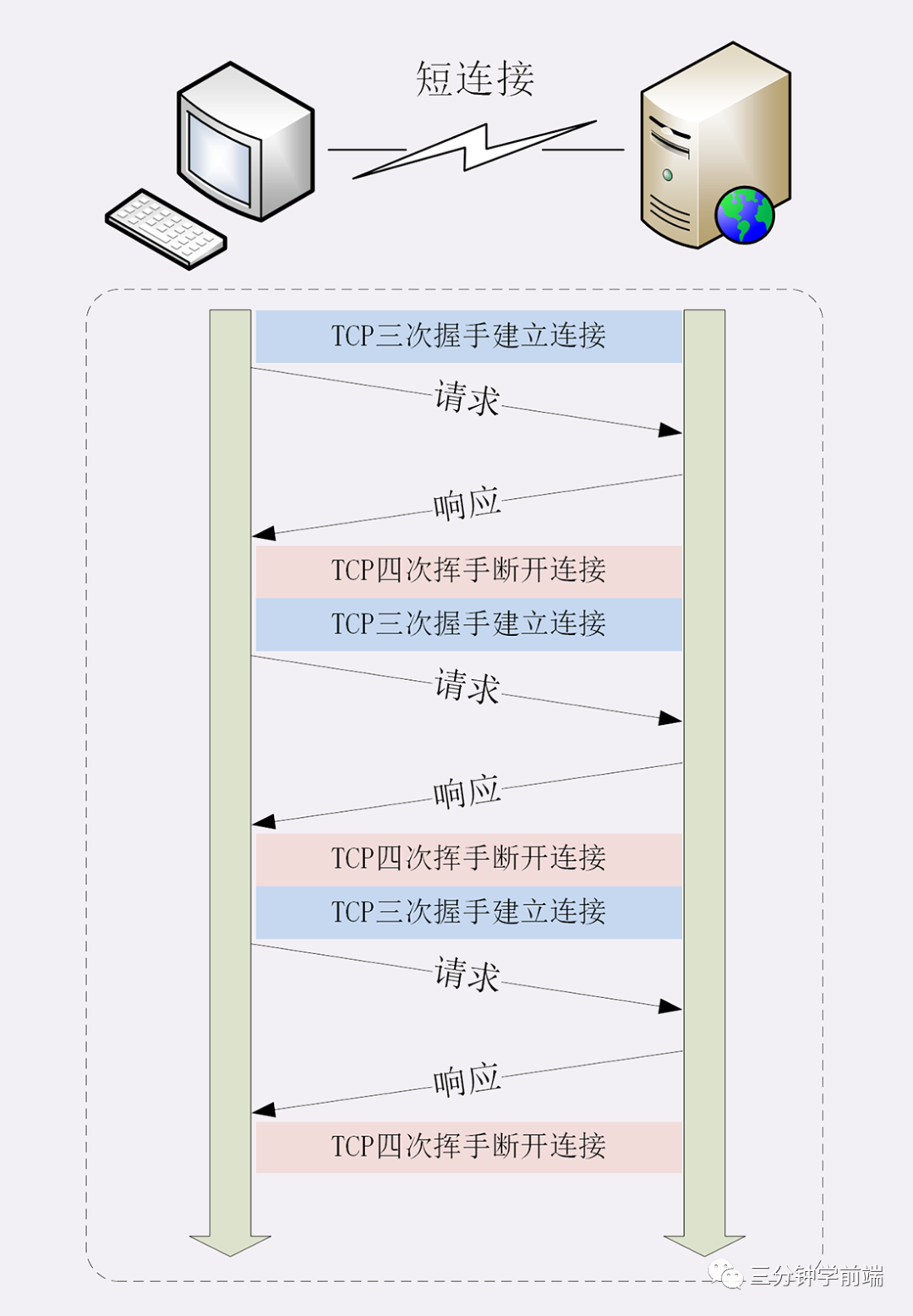
在 HTTP/0.9 與 早期 HTTP/1.0 中,默認的就是這種,但這種頻繁的創建、斷開連接無疑是極大的消耗性能
TCP連接的新建成本很高,因為客戶端和服務器建立連接時需要“三次握手”,發送 3 個數據包,需要 1 個 RTT;關閉連接是“四次揮手”,4 個數據包需要 2 個 RTT,并且開始時發送速率較慢(slow start),隨著網頁加載的外部資源越來越多,這個問題就愈發突出了
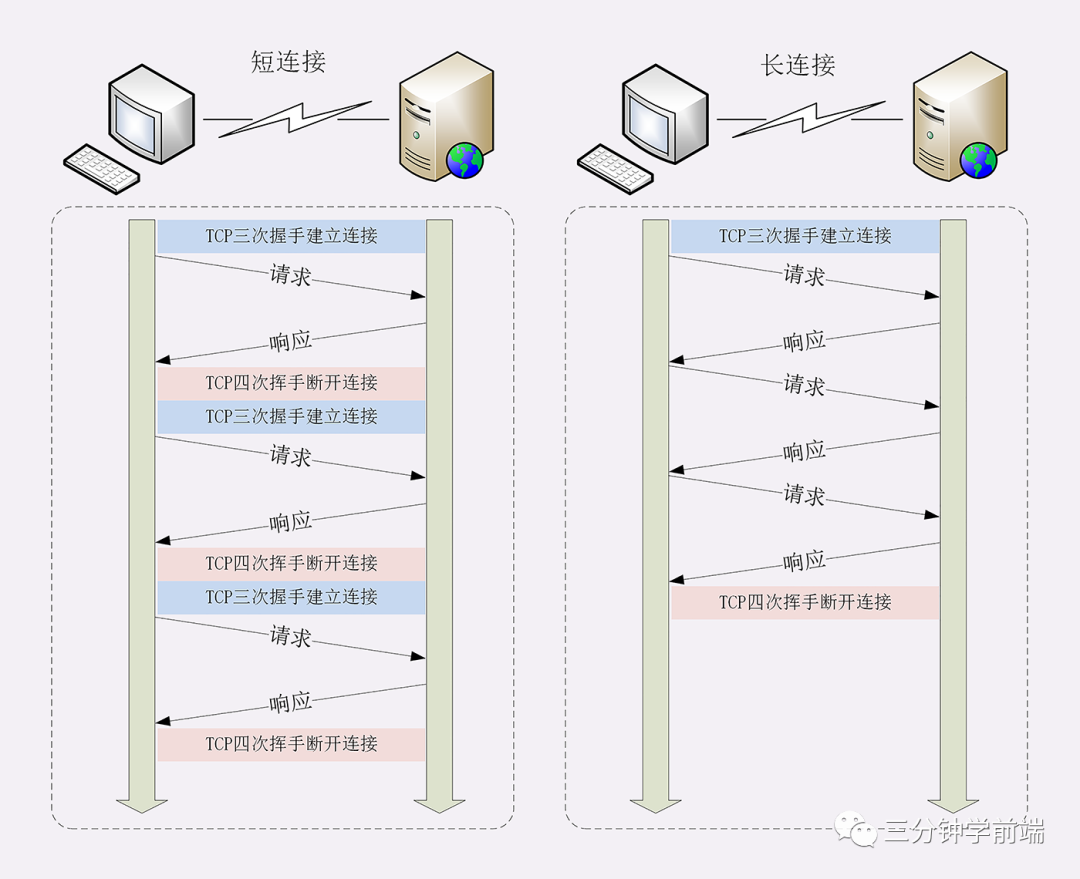
所以 HTTP/1.0 引入了 keep-alive 長連接,HTTP/1.0 中是默認關閉的,可以通過 Connection: keep-alive; 開啟 ,HTTP/1.1 默認是開啟的,無論加沒加 Connection: keep-alive;
所謂長連接,即在 HTTP 請求建立 TCP 連接時,請求結束,TCP 連接不斷開,繼續保持一段時間(timeout),在這段時間內,同一客戶端向服務器發送請求都會復用該 TCP 連接,并重置 timeout 時間計數器,在接下來 timeout 時間內還可以繼續復用 TCP 。這樣無疑省略了反復創建和銷毀 TCP 連接的損耗。
timeout 時間到了之后,TCP會立即斷開連接嗎?
若兩小時(timeout)沒有收到客戶的數據,服務器就發送一個探測報文段,以后則每隔 75 秒發送一次。若一連發送 10 個探測報文段后仍無客戶的響應,服務器就認為客戶端出了故障,接著就關閉這個連接。
——摘自謝希仁《計算機網絡》
HTTP/2 多路復用
為什么 HTTP/2 引入多路復用?
這是因為:
- HTTP/1.x 雖然引入了 keep-alive 長連接,但它每次請求必須等待上一次響應之后才能發起,
- 所以,在 HTTP/1.1 中提出了管道機制(默認不開啟),下一次的請求不需要等待上一個響應來之后再發送,但這要求服務端必須按照請求發送的順序返回響應,當順序請求多個文件時,其中一個請求因為某種原因被阻塞時,在后面排隊的所有請求也一并被阻塞,這就是隊頭阻塞 (Head-Of-Line Blocking)
- 人們采取了很多方法去解決,例如使用多個域名、引入雪碧圖、將小圖內聯等,但都沒有從根本上解決問題
HTTP/2 是怎么做的喃?
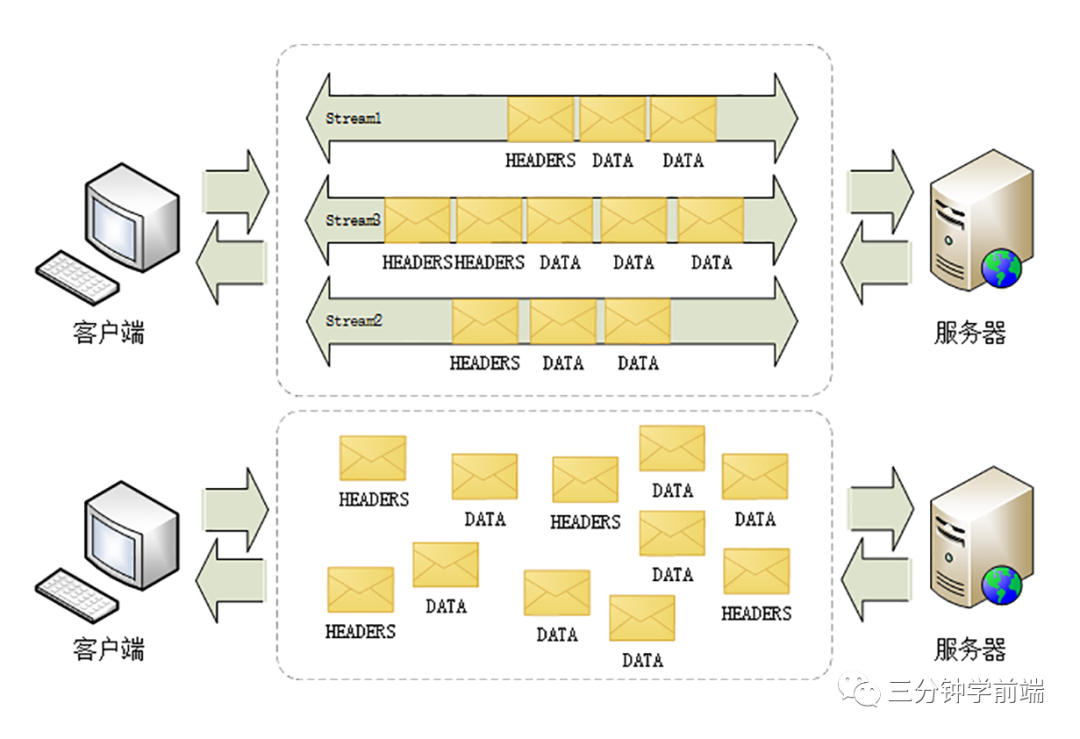
- 首先它引入了 幀(frame)和流(stream),因為 HTTP/1.x 是基于文本的,因為是文本,就導致了它必須是個整體,在傳輸是不可切割的,只能整體去傳
- 既然,HTTP/2 是基于二進制流的,它就可以把 HTTP 消息分解為獨立的幀,交錯發送,然后在另一端通過幀中的標識重新組裝,這就是多路復用
- 這就實現了在同一個TCP連接中,同一時刻可以發送多個請求和響應,且不用按照順序一一對應,即使某個請求任務耗時嚴重,也不會影響到其它連接的正常執行
HTTP/1.x keep-alive 與 HTTP/2 多路復用區別
總結一下,HTTP/1.x keep-alive 與 HTTP/2 多路復用區別:
- HTTP/1.x 是基于文本的,只能整體去傳;HTTP/2 是基于二進制流的,可以分解為獨立的幀,交錯發送
- HTTP/1.x keep-alive 必須按照請求發送的順序返回響應;HTTP/2 多路復用不按序響應
- HTTP/1.x keep-alive 為了解決隊頭阻塞,將同一個頁面的資源分散到不同域名下,開啟了多個 TCP 連接;HTTP/2 同域名下所有通信都在單個連接上完成
- HTTP/1.x keep-alive 單個 TCP 連接在同一時刻只能處理一個請求(兩個請求的生命周期不能重疊);HTTP/2 單個 TCP 同一時刻可以發送多個請求和響應
來自:https://github.com/Advanced-Frontend/Daily-Interview-Question

























