Resource Queue 如何實現對 AnalyticDB PostgreSQL 的資源管理?
一 背景
AnalyticDB PostgreSQL版(簡稱ADB PG)是阿里云數據庫團隊基于PostgreSQL內核(簡稱PG)打造的一款云原生數據倉庫產品。在數據實時交互式分析、HTAP、ETL、BI報表生成等業務場景,ADB PG都有著獨特的技術優勢,在金融、物流、泛互聯網等行業都有廣泛的應用,是傳統數倉上云、去O去T、替換自建Greenplum的標桿云上數據倉庫產品。
數據倉庫產品是數據分析系統的重要組件之一,各類線上業務對數據倉庫產品的穩定性、可用性具有很高的要求。缺乏有效的資源管理機制會導致數據庫產品的穩定性下降,發生例如連接數打滿OS限制、內存不足、進程卡死等問題,從而影響產品的可用性。
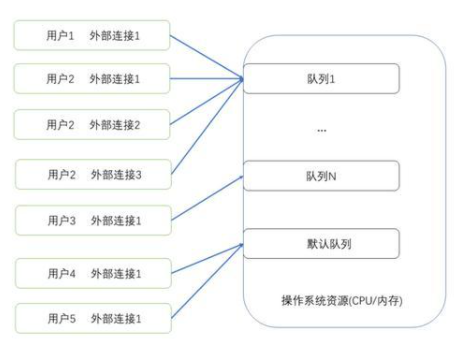
Resource Queue(資源隊列)是ADB PG的一種資源管理方式,能夠對數據庫的CPU、內存等資源進行限制,對多租戶資源限制、保障數據庫穩定運行具有一定的作用。顧名思義,Resource Queue以隊列形式對運行在數據庫集群上的SQL進行資源管理。對于每個用戶,他的所有連接只能歸屬于一個隊列。而對于每個隊列能夠管理多個用戶的連接。沒有顯示指定資源隊列的用戶,會歸屬于默認資源隊列管理。通過限制每個隊列的資源總量,我們可以達到限制某類業務或者某個用戶使用的資源總量的目的。
我們以ADB PG某在線交易平臺類客戶A為例,介紹Resource Queue的使用。客戶A基于ADB PG構建數據倉庫,日常運行三類業務:以交易數據入庫為代表的實時類業務;用于支撐決策分析的報表類業務;以及用于實時大屏展示的可視化類業務。我們根據三類業務的不同特點,按如下策略配置資源隊列。
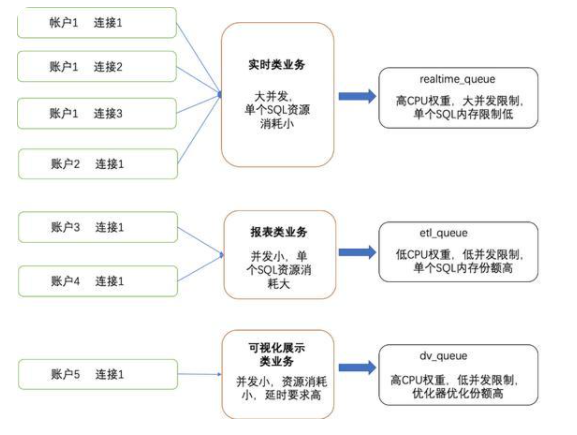
客戶A的實時類業務的典型代表是,交易數據經Kafka->Flink->ADB PG鏈路實時寫入ADB PG。這類業務的典型特點是,峰值并發比較大,單個SQL資源消耗小。在進行資源隊列限制前,業務高峰期經常發生突然提高的并發查詢打滿數據庫連接,造成高可用探活查詢執行失敗,引發實例不可用。對于這類業務我們將其關聯到一個高CPU權重、大并發限制(安全閾值內)、單個SQL內存份額低的隊列。既保證數據的快速入庫,又防止流量洪峰造成系統不穩定。
客戶A的另一類典型業務是報表類、ETL類業務,這類業務會在實時類業務的低峰期進行調度,生成報表以提供決策支持。這類業務涉及的數據量較大,消耗內存量和產生的臨時文件量大。對于這類業務,我們將其關聯到低CPU權重、低并發限制,但是內存份額高的隊列,在滿足業務需要的同時,控制內存使用上限;
除此之外,客戶還基于ADB PG數據倉庫支持數據的實時可視化展示,這類可視化方案往往具有非常穩定的并發,但是對查詢的延時具有一定的要求。對于這類業務,我們將其資源隊列設定為高CPU權重,低并發限制,以及寬泛的優化器查詢計劃消耗份額,最大程度為其生成良好的查詢計劃,以保證業務穩定。
接下來,本文會具體介紹Resource Queue的使用方式、狀態監控,以及它的實現機制。
二 Resource Queue簡介
Resource Queue支持通過SQL配置,支持進行四種類型的資源限制:并發限制、CPU限制、內存限制和查詢計劃限制。用戶可以通過SQL在數據庫內定義多個資源隊列,并設置每個資源隊列的資源限制。在一個數據庫中,每個資源隊列可以關聯一個或多個數據庫用戶,而每個數據庫用戶只能歸屬于單個資源隊列。
另外,并不是所有提交到資源隊列的SQL都會受到隊列限制的限制,數據庫只會限制SELECT、SELECT INTO、CREATE TABLE AS SELECT、DECLARE CURSOR、INSERT、UPDATE 和DELETE這些類型SQL的資源利用。另外,在執行EXPLAIN ANALYZE命令期跑的SQL也會被資源隊列排除。
資源隊列支持的資源限制配置如下:
通過SQL語句定義一個新的資源隊列:
CREATE RESOURCE QUEUE etl WITH (ACTIVE_STATEMENTS=3, MEMORY_LIMIT='1GB', PRIORITY=LOW, MAX_COST=-1.0);
ACTIVE_STATEMENTS:
隊列中允許同時運行的查詢數,即隊列中允許并發查詢的最大并發值。數據庫允許超出ACTIVE_STATEMENTS數目、但是少于數據庫最大連接數MAX_CONNECTIONS數目的鏈接連接到數據庫,但是這部分SQL連接并不會立刻開始運行,而是排隊等待。
MAX_COST:
查詢計劃Cost限制。數據庫優化器會為每個查詢計算Cost,如果該Cost總量超過了資源隊列所設定的的MAX_COST的值,該查詢就會被拒絕。ADB PG的默認配置為0,即不受限制。
Memory Limit:
ADB PG可以通過設置statement_mem來決定每條SQL在每個Segment上使用的內存上限。Memory Limit既沒有默認值,也可以不指定。在MEMORY_LIMIT參數沒有被配置時,一個資源隊列中的一條SQL所允許的內存大小,由statement_mem參數決定:
如果一個資源隊列沒有設置MEMORY_LIMIT的話,每個資源所分配到的內存大小就是statement_mem的服務器配置參數,一個資源隊列的可用內存大小是根據statement_mem和ACTIVE_STATEMENTS的計算結果。當資源隊列有設置MEMORY_LIMIT時,單個SQL所使用的內存量會由隊列中的平均分配值(MEMORY_LIMIT/ACTIVE_STATEMENTS)和statement_mem中的最大值決定,具體計算方式可以參考后面實現章節。
資源隊列中可以并行執行的查詢數會受到該隊列的可用內存限制。舉個例子:對于隊列etl,設置STATEMENTS=3, MEMORY_LIMIT=2.1G;那么在沒有設置statement_mem的情況下,每個查詢默認使用內存700MB。
SQL1進入隊列,使用內存700MB,此時隊列剩余內存1.4G;
SQL2進入隊列,設置statement_mem為1.0GB,此時隊列剩余內存為0.4GB;
此時,隊列剩余內存無法滿足SQL3的內存使用需求(默認700GB),那么雖然隊列中并行查詢數沒有達到隊列限制,SQL3依然無法執行,需要排隊等待。
PRIORITY:
數據庫運行的SQL會按照其所在資源隊列的優先權設置來共享可用的CPU資源。當一個來自高優先權隊列的語句進入到活動運行語句分組中時,它可以得到可用CPU中較高的份額,同時也會降低具有較低優先權設置隊列中已經在運行的語句得到的份額。
查詢的相對尺寸或復雜度不影響CPU的分配。如果一個簡單的低代價的查詢與一個大型的復雜查詢同時運行,并且它們的優先權設置相同,它們將被分配同等份額的可用CPU資源。當一個新的查詢變成活動時,CPU份額將會被重新計算,但是優先權相等的查詢仍將得到等量的CPU。
例如,管理員創建三個資源隊列:streaming、etl、prod,并相應地配置為以下優先權:
streaming — 低優先權etl— 高優先權prod — 最大優先權
當數據庫中只有etl隊列中有查詢1和2同時運行時,它們有相等份額的CPU,因為它們的優先權設置相等:
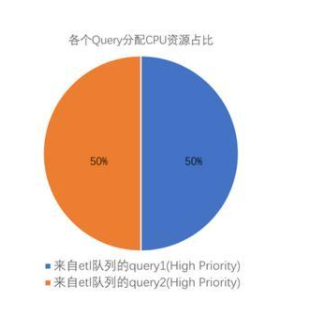
上圖中顯示的百分數都是近似值。高、低和中優先權隊列的CPU使用并不總是準確地用這些比例計算出來。
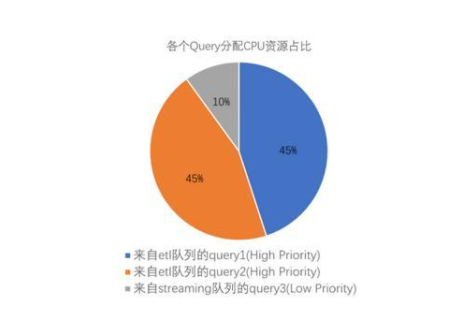
當一個streaming隊列中的查詢開始運行時,在etl隊列中兩個查詢依然保持相等的CPU份額,而低優先級的query3則會以較低CPU份額運行。
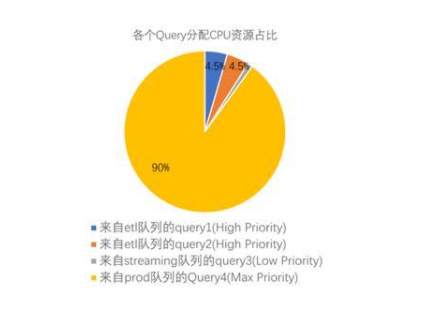
而當最高優先級隊列prod中有查詢進入隊列之后,其CPU使用會被調整以說明其最大優先權設置。它可能是一個非常簡單的查詢,但直到它完成前,它都將要求最大份額的CPU。而其他查詢的優先級則會被調整為較低的CPU份額。
三 Resource Queue使用
3.1 創建資源隊列
ADB PG允許用戶使用SQL創建資源隊列,并指定各類資源限制。使用CREATE RESOURCE QUEUE命令來創建新的資源隊列。
創建帶有并發限制的隊列
帶有ACTIVE_STATEMENTS設置的資源隊列會限制指派給該隊列的角色所執行的并發查詢數量。
CREATE RESOURCE QUEUE etl WITH (ACTIVE_STATEMENTS=3);
這意味著對于所有被分配到etl資源隊列的角色,在任意給定時刻只能有三個活動查詢被運行在這個系統上。如果這個隊列已經有三個查詢在運行并且一個角色在該隊列中提交第四個查詢,則第四個查詢只有等到一個槽被釋放出來后才能運行。
創建帶有內存限制的隊列
帶有MEMORY_LIMIT設置的資源隊列控制所有通過該隊列提交的查詢的總內存。在與ACTIVE_STATEMENTS聯合使用時,每個查詢被分配的默認內存量為:MEMORY_LIMIT /ACTIVE_STATEMENTS。
例如,要創建一個活動查詢限制為10且總內存限制為2000MB的資源隊列(每個查詢將在執行時被分配200MB的Segment主機內存):
CREATE RESOURCE QUEUE etl WITH (ACTIVE_STATEMENTS=10, MEMORY_LIMIT='2000MB');
另外gp_vmem_protect_limit參數會限制一個Segment上分配的內存總大小。該參數的優先級更高,如果這個參數超標,查詢可能會被取消。
設置優先級
為了控制一個資源隊列對可用CPU資源的消耗,用戶可以指派一個合適的優先級。
ALTER RESOURCE QUEUE etl WITH (PRIORITY=LOW);ALTER RESOURCE QUEUE etl WITH (PRIORITY=MAX);
3.2 指派角色(用戶)到資源隊列
一旦創建了一個資源隊列,用戶必須把角色(用戶)指派到它們合適的資源隊列。如果沒有顯式地把角色指派給資源隊列,它們將進入默認資源隊列pg_default。
使用ALTER ROLE或者CREATE ROLE命令來指派角色到資源隊列。例如:
ALTER ROLE name RESOURCE QUEUE queue_name;CREATE ROLE name WITH LOGIN RESOURCE QUEUE queue_name;
從資源隊列移除角色
所有用戶都必須被指派到資源隊列。如果沒有被顯式指派到一個特定隊列,用戶將會進入到默認的資源隊列pg_default。如果用戶想要從一個資源隊列移除一個角色并且把它們放在默認隊列中,可以將該角色的隊列指派改成none。例如:
ALTER ROLE role_name RESOURCE QUEUE none;
3.3 修改資源隊列
在資源隊列被創建后,用戶可以使用ALTER RESOURCE QUEUE命令更改隊列限制,或使用DROP RESOURCE QUEUE命令移除一個資源隊列。
修改資源隊列配置
ALTER RESOURCE QUEUE命令更改資源隊列的限制。要更改一個資源隊列的限制,可以為該隊列指定想要的新值。例如:
ALTER RESOURCE QUEUE etl WITH (ACTIVE_STATEMENTS=5);ALTER RESOURCE QUEUE etl WITH (PRIORITY=MAX);
刪除資源隊列
DROP RESOURCE QUEUE命令可以刪除資源隊列。要刪除一個資源隊列,該隊列不能有指派給它的角色,也不能有任何語句在其中等待。
DROP RESOURCE QUEUE etl;
四 Resource Queue狀態監控
4.1 查看隊列中的語句和資源隊列狀態
gp_toolkit.gp_resqueue_status視圖允許用戶查看一個負載管理資源隊列的狀態和活動。對于一個特定資源隊列,它展示有多少查詢在等待運行以及系統中當前有多少查詢是活動的。要查看系統中創建的資源隊列、它們的限制屬性和當前狀態:
SELECT * FROM gp_toolkit.gp_resqueue_status;

4.2 查看資源隊列統計信息
如果想要持續跟蹤資源隊列的統計信息和性能,用戶可以使用pg_stat_resqueues系統視圖來查看在資源隊列使用上收集的統計信息。
SELECT * FROM pg_stat_resqueues;
4.3 查看指派到資源隊列的角色
要查看指派給資源隊列的角色,執行下列在pg_roles和gp_toolkit.gp_resqueue_status系統目錄表上的查詢:
SELECT rolname, rsqname FROM pg_roles, gp_toolkit.gp_resqueue_status WHERE pg_roles.rolresqueue=gp_toolkit.gp_resqueue_status.queueid;
4.4 查看資源隊列的等待查詢
用戶可以看到所有資源隊列的所有當前活躍的以及在等待的查詢:
SELECT * FROM gp_toolkit.gp_locks_on_resqueue WHERE lorwaiting='true';
如果這個查詢不返回結果,那就意味著當前沒有語句在資源隊列中等待。
4.5 查看活動語句的優先權
查看當前正在被執行的語句并且提供優先權、會話ID和其他信息:
SELECT * FROM gp_toolkit.gp_resq_priority_statement;
4.6 重置活動語句的優先權
用戶可以使用函數gp_adjust_priority(session_id,statement_count,priority)調整當前正在被執行的語句的優先權。使用這個函數,用戶可以提升或者降低任意查詢的優先權。例如:
SELECT gp_adjust_priority(12, 10000, 'LOW');
在這個函數的參數中,session_id代表會話id, statement_count代表要調整的SQL在session中的序號,priority是待調整的優先級。可以通過gp_resq_priority_statement視圖查詢現有語句的上述信息。
select * from gp_toolkit.gp_resq_priority_statement;
五 Resource Queue實現
ADB PG數據庫是MPP架構,整體分為一個或多個Master,以及多個segment,數據在多個segment之間可以隨機、哈希、復制分布。在ADB PG中,Resource Queue的資源限制級別是語句級別,即在整條SQL執行的任何時刻,不管是否處于事務中,均會受到資源隊列的限制。
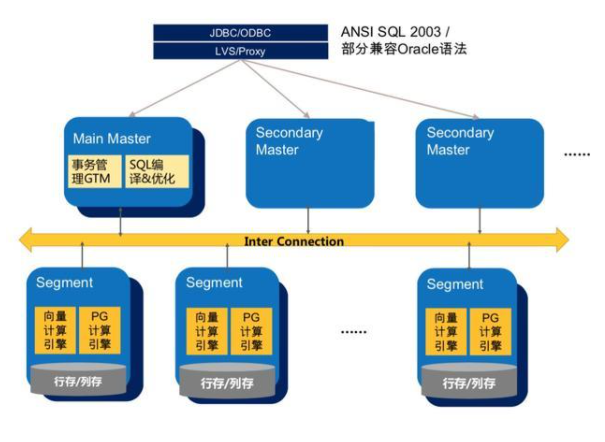
如上文所述,Resource Group支持對并發、CPU和內存等進行限制,本節會詳細介紹對這些資源進行限制的實現細節。
5.1 并發限制
ADBPG數據庫是多進程模型,分布式數據庫的每個節點會啟動多個子進程,各個子進程通過共享內存、共享信號量、共享消息隊列的方式實現進程間通信。
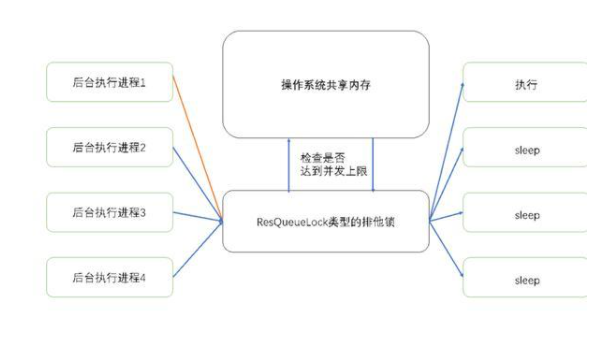
Resource Queue基于分布式鎖實現。在ADBPG中所有的SQL連接首先會到達Master節點,在經過解析、優化,到達執行器層面時,會首先嘗試獲取ResQueueLock類型的排他鎖。
在單個ADB PG節點中,同一時間只能有一個進程獲取到ResQueueLock類型的排他鎖,而每個進程只會包含單個線程。
如上文所述,Resource Group支持對并發、CPU和內存等進行限制,本節會詳細介紹對這些資源進行限制的實現細節。
5.1 并發限制
ADBPG數據庫是多進程模型,分布式數據庫的每個節點會啟動多個子進程,各個子進程通過共享內存、共享信號量、共享消息隊列的方式實現進程間通信。
Resource Queue基于分布式鎖實現。在ADBPG中所有的SQL連接首先會到達Master節點,在經過解析、優化,到達執行器層面時,會首先嘗試獲取ResQueueLock類型的排他鎖。
在單個ADB PG節點中,同一時間只能有一個進程獲取到ResQueueLock類型的排他鎖,而每個進程只會包含單個線程。
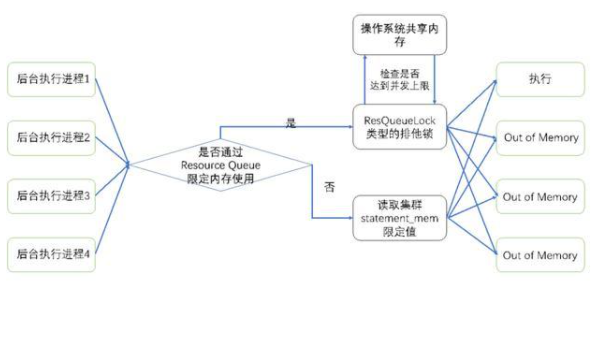
對于某個Resource Queue中的SQL,能夠使用的內存上限計算如下:
1)如果沒有設定resource queue的memory_limit值,那么直接取數據庫的statement_mem值;
2)如果設定了resource queue的memory limit值,則根據所設定的resource queue的memory_limit值,計算資源組能夠使用的內存總量;用總量除以resource queue設定的并發數,得到單條SQL所能利用的上限值。再將這個上限值與statement_mem取一個最大值,作為SQL最終使用的內存上限值。
5.3 CPU限制
Resource Queue的CPU限制是一個很有意思的實現。ADB PG專門為Resource Queue CPU限制的功能拉起了一個專門的進程:sweeper進程來監控各個后臺進程的CPU使用,以及調節各個后臺進程的CPU份額。
這個進程是一個與數據庫高度獨立的進程,它沒有加載一些緩存、資源類的東西,也無法開啟事務或者查系統表,它的活動就是不停的讀寫共享內存,計算各個進程的CPU使用,更改CPU分配份額。各個實際執行SQL的后臺進程(backend)會根據所計算的CPU份額去休眠一定的時間,從而調節各個SQL實際的CPU使用率。
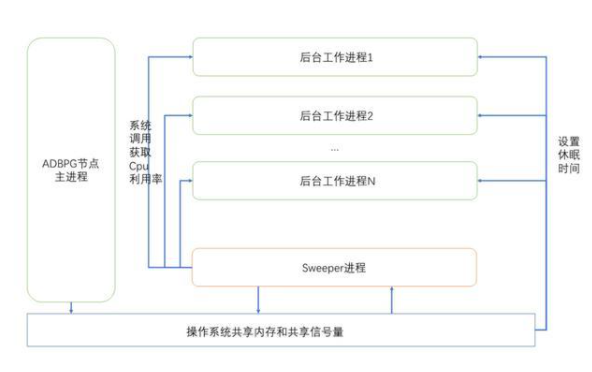
這個進程的主體流程如上,他的流程非常簡單,就是不斷地sweep和sleep。
各個實際執行SQL的backend進程在啟動時,會在共享內存中注冊一些狀態,并在執行過程中執行系統調用getrusage等,更新CPU使用狀態;sweeper進程會根據這些共享內存狀態,以及所設定的資源隊列CPU利用值,在共享內存中更新對應backend進程的CPU份額(targetCPU)。而在backend運行過程中,則會調用BackoffBackend,根據CPU份額來進行一段時間的休眠,從而調節整體的CPU利用率。
在運行過程中,分布式數據庫的每個計算節點都會有一個sweeper進程來調節每個節點的CPU調用,使資源隊列的CPU配置全局有效。
六 總結
資源管理對于數據庫集群的多租戶管理、資源細粒度分配具有很重要的價值。Resource Queue能夠對分布式數據庫進行整體的資源管理和控制,在多租戶隔離、保障數據庫整體平穩運行具有一定的價值。
除了Resource Queue的資源管理方式外,ADB PG還支持 Resource Group 的資源管理方式,能夠進行更精細的資源控制。Resource Group現已在專有云環境提供使用,后續會逐步在公有云提供能力。后續我們會介紹Resource Group的基本使用和最佳實踐。