打破“維度的詛咒”,機器學習降維方法好
本文經AI新媒體量子位(公眾號ID:QbitAI)授權轉載,轉載請聯系出處。
使用機器學習時,你是不是經常因為有太多無關特征而導致模型效果不佳而煩惱?
而其實,降維就是機器學習中能夠解決這種問題的一種好方法。
知名科技博主Ben Dickson 對此進行了探討,并在TechTalks上發表了博客《機器學習:什么是降維》,本文的編譯整理已受到Ben Dickson 本人授權。
他指出,機器學習算法因為能夠從具有許多特征的數據集中找出相關信息而大火,這些數據集往往包括了幾十行的表格或者數百萬像素的圖像。
云計算的突破可以幫助使用者運行大型的機器學習模型,而不用管后臺的計算能力。
但是,每增加一個新特征都會增加復雜性,增大使用機器學習算法的困難。
數據科學家通常使用降維,這是一套從機器學習模型中去除過多或者無關特征的技術。
降維可以降低機器學習的成本,有時還可以幫助用更簡單的模型來解決復雜的問題。
以下讓我們來看看是他的文章。
維度的詛咒
機器學習模型可以將特征映射到結果。
比如,假設你想創建一個模型,來預測一個月內的降雨量:
你有一個在不同月份從不同城市收集的各類信息的數據集,包括溫度、濕度、城市人口、交通、在城市舉辦的音樂會數量、風速、風向、氣壓、購買的汽車票數量和降雨量。
顯然,這些信息并不是都和降雨預測有關。
有些特征可能和目標變量毫無關系。
比如,人口和購買的汽車票數量并不影響降雨量。
其他特征可能與目標變量相關,但與它沒有因果關系。
比如,戶外音樂會的數量可能與降雨量相關,但它不是一個很好的降雨預測器。
在其他情況下,比如碳排放,特征和目標變量之間可能有聯系,但效果可以忽略不計。
在這個例子中,哪些特征是有價值的,哪些是無用的,是顯而易見的。
在其他問題中,過度的特征可能不明顯,這就需要進一步的數據分析。
但是,為什么要費力地去除多余的維度呢?
因為當你有太多的特征時,你也會需要一個更復雜的模型,這就意味著你需要更多的訓練數據和更多的計算能力,才能把模型訓練到一個可接受的水平。
由于機器學習不了解因果關系,即使沒有因果關系,模型也會試圖將數據集中的任何特征映射到目標變量,這可能會導致模型錯誤。
另一方面,減少特征的數量會使機器學習模型更簡單,更有效,對數據的要求也更低。
很多特征造成的問題通常被稱為 “維度的詛咒”,而且它們并不限于表格數據。
考慮一個對圖像進行分類的機器學習模型。如果你的數據集由100×100像素的圖像組成,那么每個像素一個,這樣的問題空間有10,000個特征。然而,即使在圖像分類問題中,一些特征也是過度的,可以被刪除。
降維可以識別并刪除那些損害機器學習模型性能或對其準確性沒有貢獻的特征。
目前有幾種降維技術,每一種都有有用的適用范圍。
特征選擇
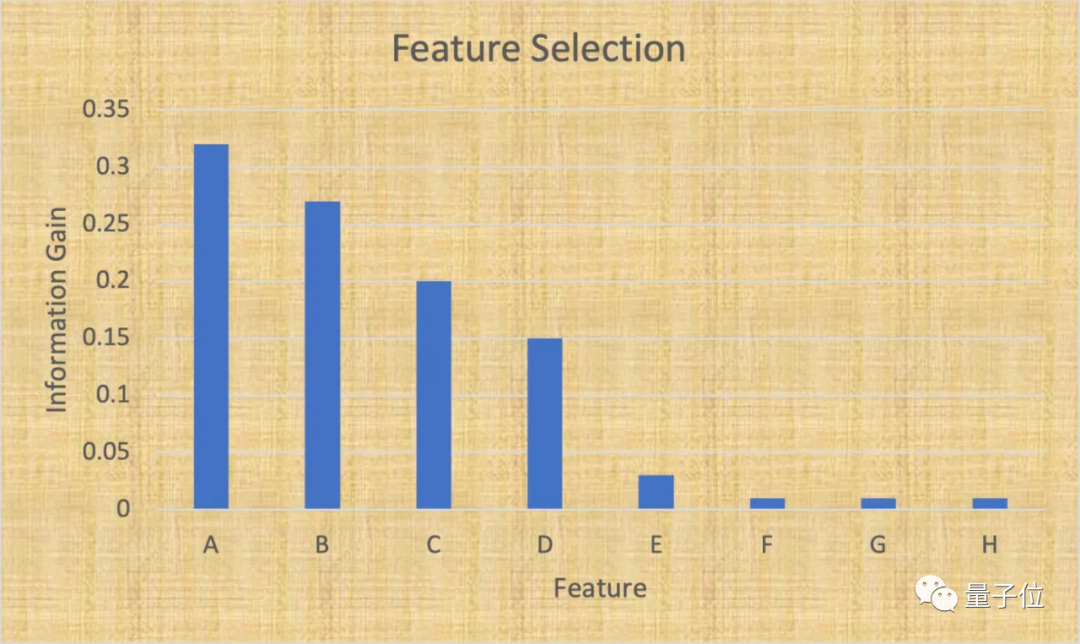
一個基本且有效的降維方法是“特征選擇”,就是識別和選擇與目標變量最相關的特征子集。
當處理表格數據時,特征選擇非常有效,因為其中的每一列都代表了一種特定的信息。
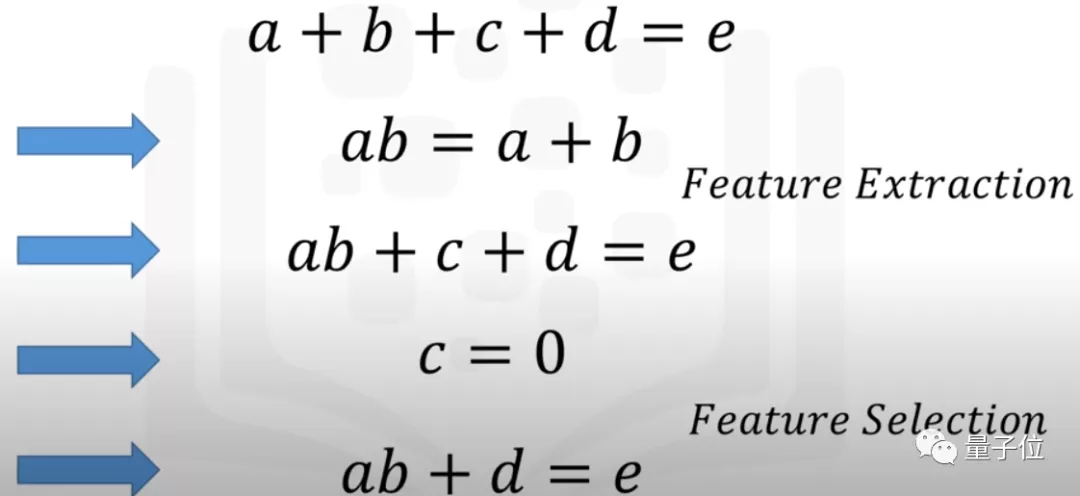
在進行特征選擇時,數據科學家要做兩件事:
保留與目標變量高度相關的特征,和對數據集的方差貢獻最大的特征。
Python的Scikit-learn庫開發了很多功能,能夠分析、可視化和選擇正確的特征,來實現機器學習模型。
比如,數據科學家可以使用散點圖和熱圖來可視化不同特征的協方差。
如果兩個特征高度相關,那么它們將對目標變量產生類似的影響,因此,可以刪除其中一個,而不會對模型造成負面影響。
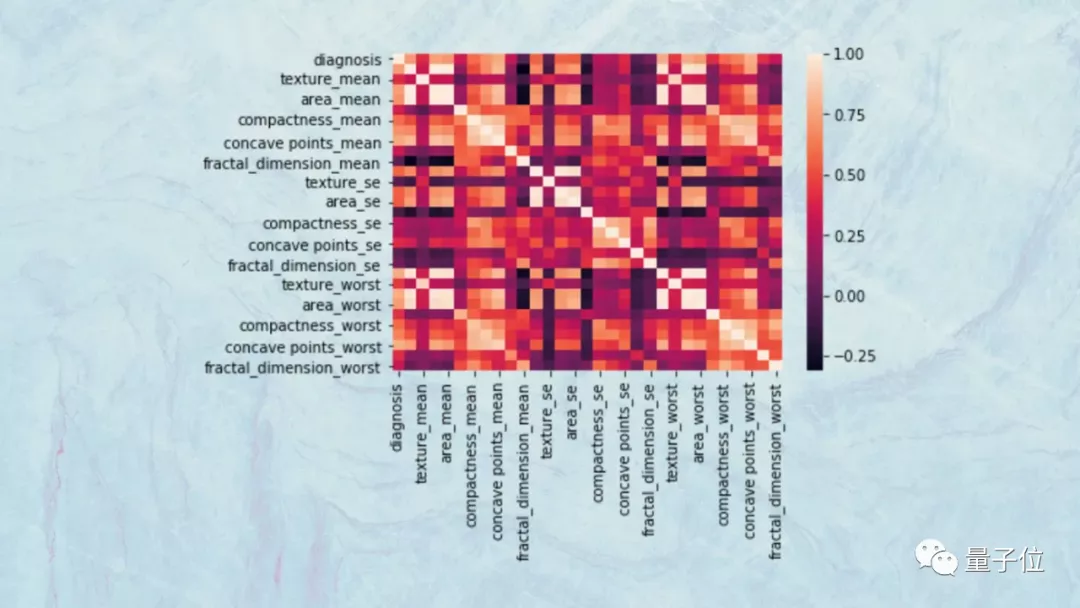
這些工具還可以幫助可視化特征和分析目標變量之間的關聯性,從而幫助去除不影響目標變量的變量。
比如,你可能會發現,在你的數據集的25個特征中,有7個對目標變量的影響占到了95%。
所以能夠刪除18個特征,使機器學習模型變得更簡單,而不會對模型的準確性產生太大影響。
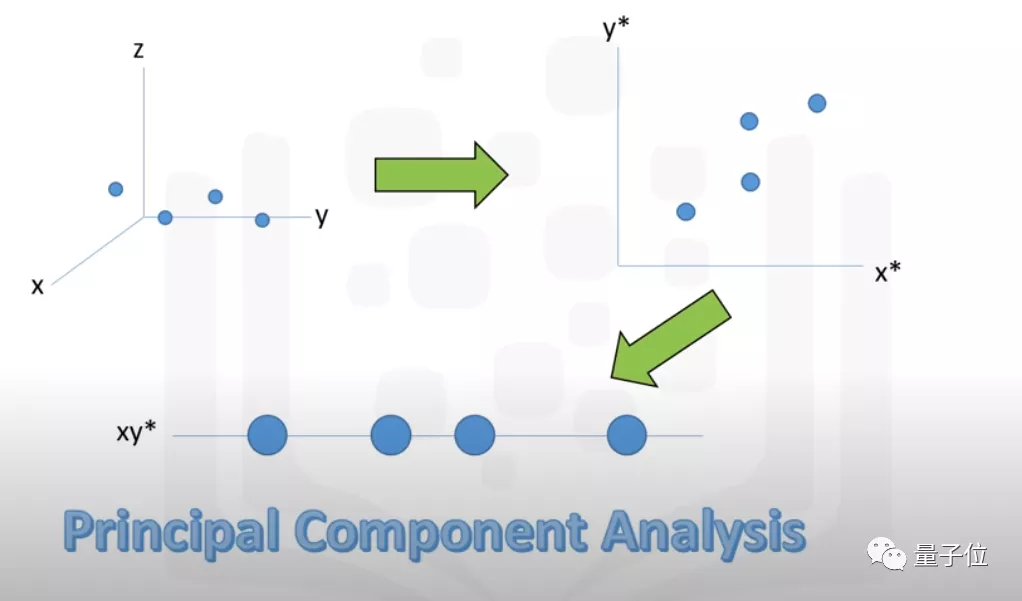
投影技術
有時,你沒辦法刪除個別特征,但這并不意味著不能簡化機器學習模型。
投影技術 就是一個好辦法,也被稱為 “特征提取” ,可以通過將幾個特征壓縮到一個低維空間來簡化模型。
用于表示投影技術的一個常見示例是 “瑞士卷”。
這是一組圍繞三維焦點旋轉的數據點,這個數據集有三個特征。每個點(目標變量)的值是根據它沿卷曲路徑到瑞士卷中心的距離來測量的。在下面的圖片中,紅點更靠近中心,黃點沿著滾動方向更遠。
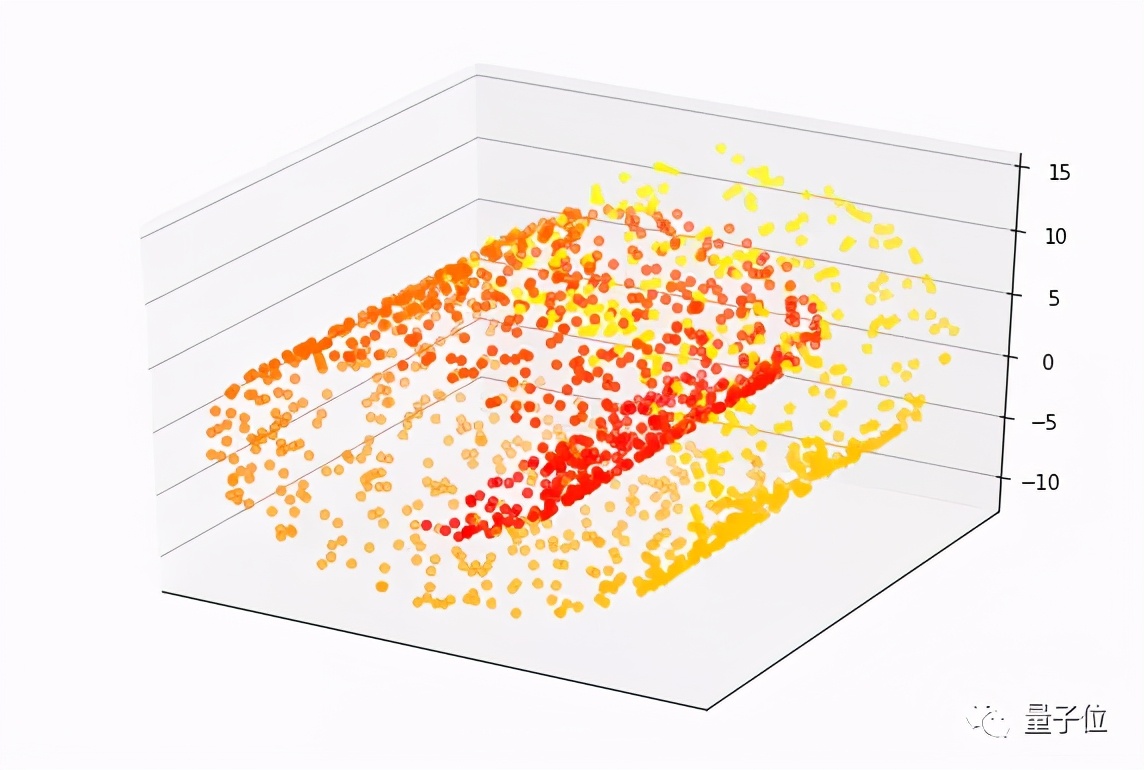
創建一個機器學習模型,將瑞士卷點的特征映射到它們的值非常難,需要一個具有許多參數的復雜模型。但是,引入降維技術,這些點可以被投射到一個較低維度的空間,可以用一個簡單的機器學習模型來學習。
有各種投影技術。在上面的例子中,我們使用了 “局部線性嵌入(LLE)”的方法,這種算法可以降低問題空間的維度,同時保留了分離數據點數值的關鍵元素。當我們的數據用LLE處理時,結果看起來就像下面的圖片,這就像一個展開的瑞士卷。
你可以看到,每種顏色的點都保持在一起。因此,這個問題仍然可以簡化為一個單一的特征,并用最簡單的機器學習算法(線性回歸)建模。
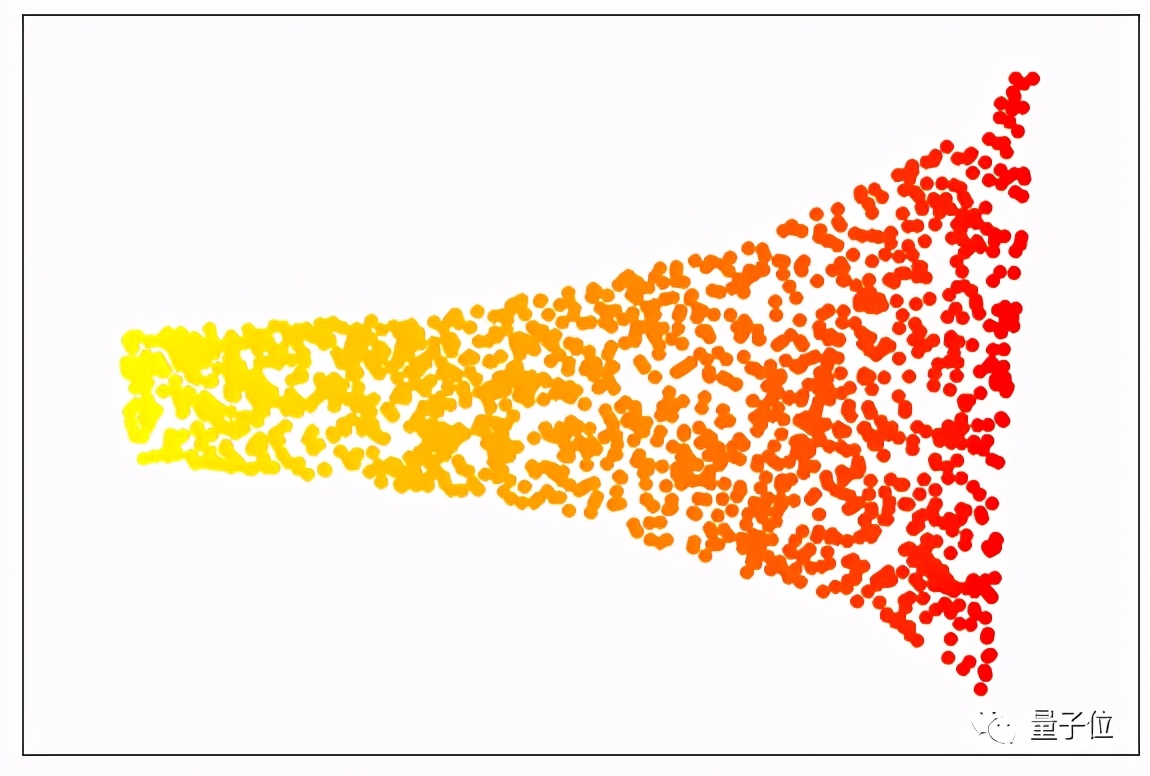
雖然這個例子是假設性的,但如果你把特征投射到一個較低維度的空間,經常會面臨一些可以簡化的問題。
比如, “主成分分析”(PCA) 是一種流行的降維算法,在簡化機器學習問題方面有許多有用的應用。
在優秀的《用Python進行機器學習(Hands-on Machine Learning with Python)》一書中,數據科學家Aurelien Geron展示了如何使用PCA將MNIST數據集從784個特征(28×28像素)減少到150個特征,同時保留了95%的方差。
這種降維水平對人工神經網絡的訓練和運行成本的影響特別大。

關于投影技術,有幾個注意事項需要考慮:
一旦你開發了投影技術,就必須先將新數據點轉換到低維空間,然后再通過機器學習模型運行它們。但如果這個預處理步驟的成本太大,最后模型的收益太小的話,可能不太值。
第二個問題是,轉換后的數據點可能不能直接代表其原始特征,如果將它們再轉換回原始空間可能很麻煩,某些情況下也不太可行,因此這可能會很難解釋模型的推論。
機器學習工具箱中的降維
簡單總結一下。
過多的特征會降低機器學習模型的效率,但刪除過多的特征也不太好。
數據科學家可以用降維作為一個工具箱,生成好的機器學習模型,但和其他工具一樣,使用降維的時候也有許多問題,有許多地方都需要小心。
作者簡介
知名科技博主、軟件工程師Ben Dickson,TechTalks的創始人。