聊一下關于去重計數的多種實現方式
作者:卡門的兒子
這是一個關于 pandas 從基礎到進階的練習題系列,來源于 github 上的 guipsamora/pandas_exercises 。這個項目從基礎到進階,可以檢驗你有多么了解 pandas。
本文轉載自微信公眾號「數據大宇宙」,作者卡門的兒子。轉載本文請聯系數據大宇宙公眾號。
這是一個關于 pandas 從基礎到進階的練習題系列,來源于 github 上的 guipsamora/pandas_exercises 。這個項目從基礎到進階,可以檢驗你有多么了解 pandas。
我會挑選一些題目,并且提供比原題庫更多的解決方法以及更詳盡的解析。
如下數據:
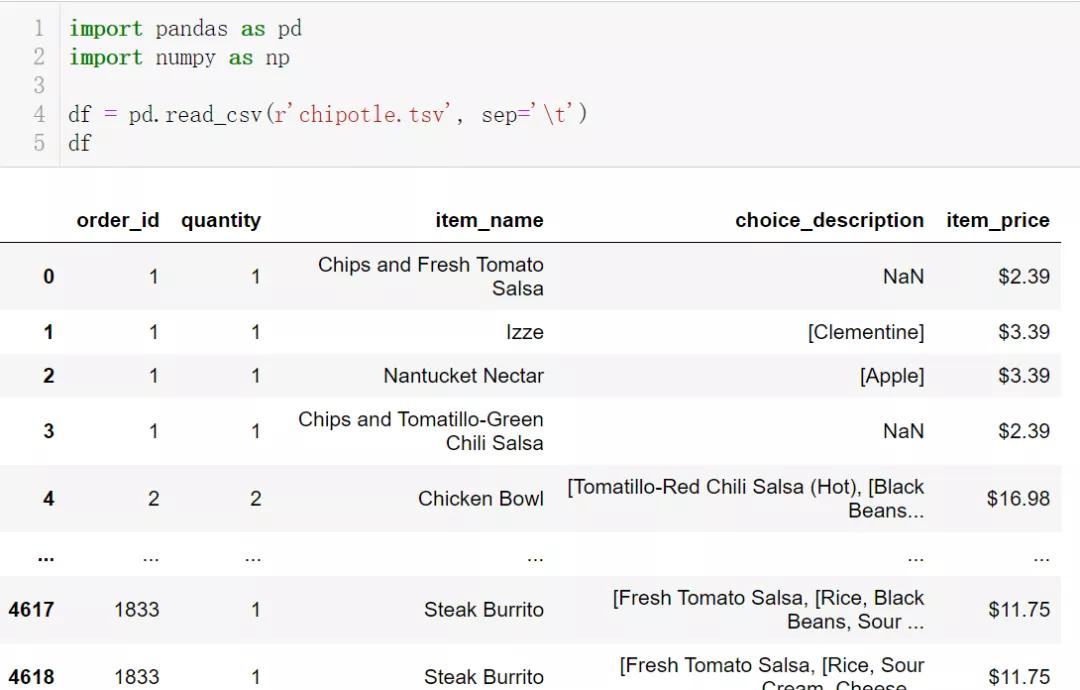
數據描述:
- 此數據是訂單明細表。一個訂單會包含很多明細項,表中每個樣本(每一行)表示一個明細項
- order_id 列存在重復
- quantity 是明細項數量
需求:數據中共有多少個訂單?
下面是答案了
方式1
因為 order_id 列是存在重復的,那么一種比較直觀的方式就是去重+計數:
- len(df.order_id.drop_duplicates())
- 1834
- Series.drop_duplicates() 返回的仍然是一個 Series
- len 函數可以計算 Series 值數量
但是你可能不知道的是,這個方式是不準確的!
方式2
之所以說上一種方式是不準確,是因為沒有考慮到空值的問題。
len 函數不會忽略空值(nan) ,因此如果列中有空值,那么就比正確結果數量多。
正確的做法是:
- len(df.order_id.drop_duplicates().dropna())
- 使用 Series.dropna() 方法可以去掉 nan 值
提示:
即使列中有多個 nan ,經過去重后只會保留一個 nan 值
方式3
實際上,pandas 本身有提供一個忽略 nan 的計數方法:
- df.order_id.drop_duplicates().count()
點評:
這種方式個人認為最合適
方式4
pandas 為列(Series)提供了一個快速匯總計數方法:
- df.order_id.value_counts()

- Series.value_counts() 相當于 根據 order id 分組,統計數量。并且排除 nan
這相當于實現了去重,因此:
- df.order_id.value_counts().count()
點評:
- 這是原項目的解法,不太直觀,不推薦使用
- 我本人經常把 value_counts 方法中s的位置搞錯
不過我自制了一個方法查詢器,這樣子不至于記錯方法:
責任編輯:武曉燕
來源:
數據大宇宙