













如何基于MaxCompute快速打通數據倉庫和數據湖的湖倉一體實踐
本文主要分為四個部分:
一、湖倉融合的趨勢分析
二、阿里云湖倉一體
三、客戶案例分析
四、湖倉一體演示
一、 湖倉融合的趨勢分析

現在很多企業說不清楚現有大數據系統是數據湖還是數據倉庫,所以先帶著大家一起回顧一下。過去20年,整個大數據技術發展的過程,通過這樣一個剖析,希望能夠讓大家理解,數據湖和數據倉庫到底是一個什么樣的系統,它們是因為什么原因產生的,并且今天我們提的湖倉一體,它出現的一個背景是什么。縱觀整個計算機科學技術領域,對于數據處理的技術主要分為四個階段,數據庫階段、大數據技術探索階段、大數據技術發展階段、大數據普惠階段。
數據庫階段主要是在上個世紀70年代至90年代期間,這個階段主要是數據庫加單機的黃金時代。數據庫系統主要是面向操作,面向事務,面向在線業務系統的一個數據系統。其實在90年代左右,數據倉庫概念就已經出現了。數據倉庫面向的是歷史全量數據分析,探查,但因為當時的整體數據量并不大,所以用一些數據庫技術的擴展,能夠支持當時數據倉庫的需求。
2000年左右,隨著互聯網技術的爆發,我們迎來了大數據時代。在這個階段,我們用傳統數據庫的技術是很難滿足海量數據處理的需求。大家應該都知道,Google的三篇論文,分布式存儲、調度、計算,奠定了整個大數據技術的基礎。基本上在同一個時期,2006年出現了Hadoop的系統,阿里巴巴在2009年發展出了飛天系統,包括微軟等頭部公司都發展出了比較優秀的分布式系統。整個這個階段,整個大數據的技術,其實是把數據做起來,數據大起來再說。
2010年左右,進入了大數據的一個蓬勃發展階段,這個階段是之前我們希望大數據技術從能用轉變為好用。這個階段出現了一系列以SQL表達為主的一些引擎,包括Hadoop體系發展出來Hive、Flink、Presto等一系列引擎。這個時候,逐漸形成了以HDFS為統一的存儲,以ORC、Parquet 為開放的文件格式,上面有很多開放引擎為主的一個體系,這個體系像我們今天講的數據湖系統。這個階段,Hadoop的本質其實是一個數據湖系統。那數據湖的本質是什么?本質是統一的存儲,能夠存儲原始的數據,能夠支持多種計算范式,這就是數據湖的本質。
同一時期,阿里巴巴在飛天系統的基礎上發布了 MaxCompute ,Google 發布了Big Query,AWS 發布了Redshift。這幾個系統可以稱之為大數據時代下的云數據倉庫。那云數據倉庫系統跟上述Hadoop體系有什么區別呢?云數據倉庫并不對外暴露文件系統,暴露的是對數據的描述,用表的方式,用視圖的方式暴露出來。存儲引擎,計算引擎是被屏蔽在系統里面的,所以存儲引擎,計算引擎可以進行深度的優化,然而用戶是沒有辦法感知的。這個階段可以看出來,整個大數據技術已經開始細分,已經初步的形成了湖的形態和倉的形態。
現在我們所處的這個階段,也就是2015年左右,我們進入了大數據普惠階段。這個階段我們有觀察到兩個趨勢。第一個趨勢,大數據技術的發展除了追求規模,性能之外。更多的是看數據安全、數據治理、穩定性、低成本等企業級能力。我們也可以看出來,阿里巴巴 基于MaxCompute ,構建出了非常有阿里特色的數據中臺系統。開源體系,也發展出了Atlas和Ranger,主要圍繞血緣、治理、安全等開源項目。第二個趨勢,隨著AI、IOT、云原生技術的發展,對于非結構化數據處理的需求越來越強烈。使用云上對象存儲作為統一存儲的趨勢越來越明顯。Hadoop的體系也逐漸由HDFS為統一存儲,發展為云上像S3、OSS這樣的云存儲,做為統一存儲的數據湖體系。與此同時,出現了很多數據湖構建,像AWS Lake Formation以及阿里云發布的DLF這樣的產品。倉的這條線,也在為了適應這樣一個趨勢,我們也在跟數據湖做很密切的聯動,發展出了外表,通過外表的方式,可以對數據庫里面的數據進行聯邦計算。
縱觀整個20年的發展,隨著大數據技術的演進,其實是發展出來了倉跟湖的兩種體系。
我們可以用下圖這張表來對比一下數據湖跟數據倉庫到底有什么區別。

整體上來說,數據湖是一個寬進寬出,相對協同比較松耦合的系統。數據倉庫是一個嚴進嚴出,比較嚴格緊耦合的系統。數據湖是數據先進來,然后再開始用,所以是屬于事后建模。可以存儲結構化、半結構化、非結構化數據。數據湖是提供了一套標準的開放接口,來支持更多的引擎,像插拔式的插到這個體系里面,所以它是向所有的引擎開放。但是這里要注意了,正是因為它是插拔式的這種方式,計算跟存儲其實是獨立的兩套系統。它們彼此之間,其實是不能夠相互理解的,也沒有辦法做到深度的優化。這樣其實導致,引擎的優化只能做到適度有限優化。數據湖易于啟動,但是隨著數據規模的增長,一系列的治理管理的問題出現,后期是比較難以運維的。因為數據湖不做Schema的強一致的數據檢查,所以數據治理比較低,難管理使用。因為數據湖的數據是先進來再使用,所以它更適合解決未知的問題,比如探查類的分析,科學計算,數據挖掘等計算處理。
數據倉庫在對比維度里基本都是相反的狀態,數據倉庫是一個嚴格的系統,所以需要事前建模,數據經過轉化清洗進到倉里面,存儲類型變為結構化或者半結構化。因為數據倉庫是一個相對封閉的系統,是一個自閉環的系統,所以數據倉庫向特定引擎開放,但是恰恰因為數據倉庫是一個自閉環系統,它的計算引擎、存儲引擎、元數據之間是可以做到非常深度、垂直的優化,可以獲得一個非常好的性能。數據倉庫因為事前建模,數據才能進來,所以難啟動,相對來講啟動成本較高。但一旦數據進入數倉之后,整個數據的高質量,方便做治理,這個時候它的整體成本會降低,甚至達到一個免運維的狀態。數據倉庫的Schema會做強一致的檢查,所以數據質量很高,易于使用。所以數據倉庫的計算負載天然的適合做離線計算,交互式計算以及BI和可視化。
整體上來講,數據湖更偏靈活性,數據倉庫更偏企業級能力。那么這兩種特點對于企業到底意味著什么呢?我們用下面這張圖來表示。

橫軸是代表企業的業務規模,縱軸是代表企業搭建一套大數據系統所需要的成本。在企業初創的時候,整個業務規模還不大,數據從產生到消費的整個鏈路,是一個探索和創新的階段。在這個階段使用數據湖是非常容易啟動,成本也是比較低的。但是隨著業務的發展和壯大,參與的人員和部門越來越多,對于數據質量管理、權限控制、成本要求會越來越高。這個時候再使用數據湖,成本是指數級上升。所以這個時候適合用數據倉庫,可以做好成本控制、數據質量管理等。從上圖可以看出,對于一個企業來講,在不同的階段,數據湖和數據倉庫都發揮著各自關鍵的作用。那是否有一種技術或者架構能同時發揮出兩者的優勢呢?
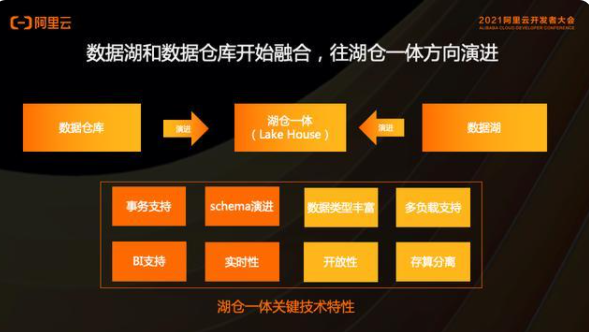
以阿里云對業界的觀察和本身大量的實踐,我們認為數據湖和數據倉庫正在發生融合。并且它們以各自的方式,向著湖倉一體的方向進行演進。從上圖中可以看出,數據倉庫到湖倉一體的演進方向,數據湖到湖倉一體的演進方向,兩者是相反的,相對的。那么在它們各自的演進上面需要做什么工作呢?
數據倉庫是一個嚴格的系統,所以數據倉庫更適合做事務支持,Schema強一致檢查和演進,天然支持BI,更容易做實時性。對于數據湖,優勢在于數據類型豐富,支持多種計算模式,有開放的文件系統,開放的文件格式,是存儲計算分離的架構。
所以數據倉庫到湖倉一體的演進,需要從本身擁有的特性發展出數據湖的特性。其實是要跟HDFS、OSS這樣的系統做好聯動,做好融合,所以數據倉庫的結構更偏左右結構。對于數據湖到湖倉一體的演進,是需要更多的站在HDFS、OSS基礎上面,來做出強倉的特性。所以數據湖的結構更像一個上下結構。那么,DeltaLake和Hudi其實就是在上下結構當中插了一層,做了一個湖上面的,能夠支持強倉的文件類型。
但不管是數據倉庫到湖倉一體,還是數據湖到湖倉一體,最終大家演進的這個方向都是一致的,都是湖倉一體。湖倉一體的特性是不變的,四種偏倉的特性,四種偏湖的特性。
二、阿里云湖倉一體
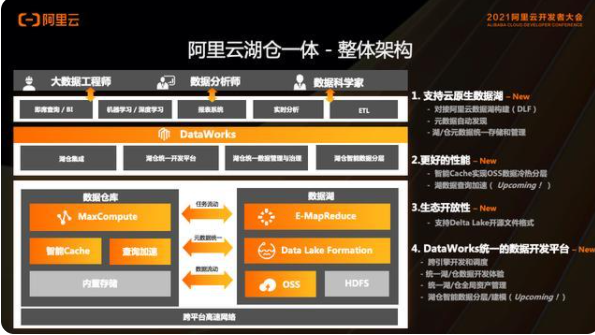
上圖為阿里云湖倉一體整體架構,從下往上看,底層是網絡層,中間層為湖倉引擎層,在往上是DataWorks 湖倉數據開發層,最上面是業務應用層。我們重點來講下引擎層,阿里云湖倉一體是左右結構,左邊是阿里云數據倉庫 MaxCompute,右邊是阿里云數據湖 EMR,中間是通過元數據的統一,通過開放格式兼容,以達到數據跟任務可以在數據倉庫和數據湖之間的任意流動。在2020年云棲大會上發布的是,對于Hadoop數據湖的支持。近期我們已經支持了OSS 數據湖的湖倉一體。
上圖右側是列出來一些我們近期發布的具體功能點。
1.支持云原生數據湖
MaxCompute 對接了阿里云數據湖構建產品DLF,可以做到元數據的自動發現,做到湖/倉元數據統一存儲和管理。
2.對于數據湖查詢更好的性能
近期阿里云正在灰度一個功能,智能Cache,此功能可以實現OSS到倉里面智能化的數據分層。MaxCompute 在2020年發布了查詢加速功能,未來一個版本我們會把查詢加速引擎也投射到數據湖上面,讓它能夠支持數據湖上面的查詢加速。
3.生態開放性
近期已支持Delta Lake開源文件格式。
4.DataWorks 統一的數據開發平臺
DataWorks支持多引擎,提供了湖倉一體開發體驗。

不管是從上下結構還是左右結構演進過來的湖倉一體,最終都應該是一個簡單易用的系統體系。阿里云湖倉一體有四大關鍵特性,這四大關鍵特性都是在圍繞怎么把數據湖跟數據倉庫做到更加易用。
快速接入
主要有兩個層次,一個是網絡層,一個是湖倉一體的開通層。MaxCompute 支持云上云下任何環境下Hadoop體系的打通,因為MaxCompute 自有的多租戶體系,如何跟特定的一個用戶環境打通,技術方面有很大的挑戰,我們研發了PrivateAccess網絡連通技術,來達到這個目標。第二個關于DataWorks白屏操作自助開通湖倉一體,未來我們會很快發布一個版本,用戶在控制臺里面就可以很快開通湖倉一體,目前還是需要用工單方式來提交開通。
2. 統一的數據/元數據
其中關鍵的技術是,有一個Database級別的元數據映射,就是我們可以把數據湖上面的Database映射成MaxCompute 里面的一個Project。數據湖上面的數據不需要移動,就可以讓 MaxCompute 像訪問操作普通Project一樣進行消費。同時做到數據湖和數據倉庫的數據/元數據做到實時同步,如果數據湖內的一張表數據或者Schema發生變化,可以及時的反應在 MaxCompute 數倉這一側。同時 MaxCompute 具備內置的存儲跟文件格式,我們也在持續的跟進開源生態內的文件格式,包含上文提到的Delta Lake。
3. 提供統一的開發體驗
數據湖和數據倉庫本身是兩套不同的系統,兩個系統有不同的數據庫模型的定義,對象模型的定義,我們在MaxCompute 這一側,把數據湖跟數據倉庫的對象模型進行了統一,再加上 MaxCompute 的SQL和Spark是高度兼容社區的,所以我們可以做到作業在兩套系統內,無縫遷移。
4. 自動數倉
這條線比較有意思,也是我們近期重點投入領域。我們去年做了一版Cache,主要是根據歷史數據做Cache,今年我又做了一版Cache,是能夠根據業務場景動態調整的策略智能化Cache,最終是要做到數據可以在數據湖跟數據倉庫中智能化的冷熱分層。我們的Cache本身需要存儲跟計算,要做到深度耦合,所以數倉做這層Cache,可以做到更加的極致。另外,我們還嘗試在數據湖的數據上進行打標跟識別,是從數據建模的角度來判定,哪些數據更適合放到倉里面,哪些數據更適合放到湖里面。比如一些結構化被反復訪問,比較高頻的表數據,更適合放到數據倉庫內。如果偏非結構化/半結構化低頻的數據,更適合放到數據湖內。最終的目的是為了在性能、成本以及業務效果上達到一個最佳的平衡。

阿里云湖倉一體適合哪些場景?概況起來有三大類。
1.Hadoop集群利舊上云
線下Hadoop上云需要很繁重的數據、任務搬遷,甚至要修改。這時就可以使用湖倉一體,讓線下Hadoop跟阿里云 MaxCompute 進行快速的打通,線下的作業不需要修改,不需要搬遷的情況下,可以直接運行到MaxCompute 的系統里面。
2.數據湖ETL/Ad-hoc加速
MaxCompute 作為SaaS模式云數據倉庫,具有高性能、低成本以及Serverless能力。通過湖倉一體,是可以把倉的能力投射到湖里面。
3.企業級跨平臺的統一大數據平臺
企業可以基于湖倉一體的技術,將現有的一個或多個Hadoop甚至OSS湖上的數據,跟 MaxCompute 數倉進行一個打通,最后構建一整套統一的數據開發,統一的管理、治理、調度的數據開發平臺。對上層業務提供的是,統一的、透明的中臺能力。
三、客戶案例分析
案例1、MaxCompute 數倉跟Hadoop數據湖的數倉一體案例業務介紹:
主要做社交媒體領域里的推薦 / 排序、文本 / 圖像分類、反垃圾 / 反作弊等。在開源 Hadoop數據湖的基礎上,借助阿里巴巴MaxCompute和PAI,解決了超大規模下的特征工程、模型訓練等性能問題,形成了MaxCompute 和Hadoop數據湖共存的格局。
痛點:
數據同步安排專人專項負責,工作量巨大;
訓練數據體量大,導致耗時多,無法滿足實時訓練要求;
新寫 SQL 數據處理 query,無法復用 Hive SQL 原有 query。
價值:
通過湖倉一體,無須進行數據搬遷和作業遷移,原有生產作業無縫靈活調度MaxCompute 集群和 EMR 集群中,且性能有提升;
封裝構建AI計算中臺,極大提升該團隊的業務支撐能力。
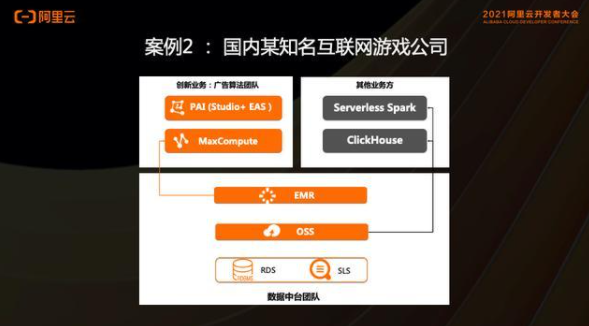
案例2、MaxCompute 數倉跟OSS數據湖的湖倉一體案例業務介紹:
客戶廣告算法團隊是湖倉一體主要客戶,主要應用是機器學習DW + MC + PAI + EAS 在線模型服務 。
痛點:
算法團隊想更集中在業務和算法上,需要自服務程度高、一站式的機器學習平臺;
Hadoop 集群是多團隊共用,使用集群管控較嚴,無法短時間支撐大workload 的創新業務。
價值:
通過湖倉一體將新業務平臺與原有數據平臺打通,PAI on MaxCompute + DataWorks 為客戶創新業務提供敏捷、一站式機器學習模型開發、訓練、模型發布,大規模計算能力、EAS 模型發布流程;
起到好的示范作用,并快速復制到其他業務線,高效的支撐了該客戶業務的快速增長。
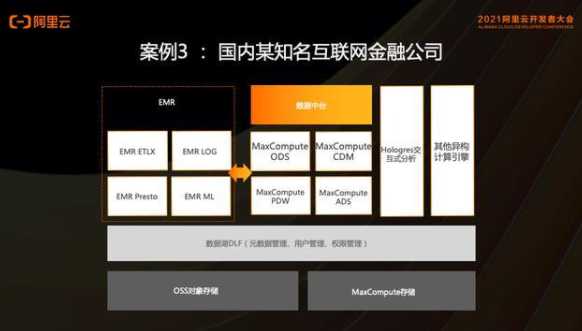
案例3、MaxCompute數倉跟OSS數據湖的湖倉一體案例業務介紹:
豐富的大數據平臺建設經驗,持續進行平臺的迭代升級以滿足業務不斷發展的需求。從國外某廠商遷移到阿里云后,積極建設和改造數據湖架構。
痛點:
第一代數據湖是 EMR + OSS,公司引入的數據中臺的執行引擎和存儲是Maxcompute,兩套異構的執行引擎帶來存儲冗余、元數據不統一、權限不統一、湖倉計算不能自由流動。
價值:
將 EMR 的元數據統一到DLF,底層使用 OSS 作統一存儲,并通過湖倉一體打通EMR數據湖和MaxCompute數倉兩套體系,讓數據和計算在湖和倉之間自由流動;
實現湖倉數據分層存儲。數據中臺對數據湖數據進行維度建模的中間表存儲在MaxCompute上,建模的結果表放在數據湖里供EMR或其他引擎消費。





























