《吃透 MQ 系列》之 Kafka 存儲選型的奧秘
大家好,我是武哥。這是《吃透 MQ 系列》之 Kafka 的第 3 篇,錯過前兩篇文章的,建議再溫習下:
從這篇文章開始,我將從微觀角度切入,深入分析 Kafka 的設計原理。本文要講的是 Kafka 最具代表性的:存儲設計。
談到 Kafka 的存儲設計,了解不多的同學,可能會有這樣的疑惑:為什么 Kafka 會采用 Logging(日志文件)這種很原始的方式來存儲消息,而沒考慮用數據庫或者 KV 來做存儲?
而對 Kafka 有所了解的同學,應該能快速說出一些 知識點:比如 Append Only、Linear Scans、磁盤順序寫、頁緩存、零拷貝、稀疏索引、二分查找等等。
我計劃寫兩篇文章,除了解釋清楚上面的疑惑,同時還會給出一個脈絡,幫助大家迅速切中 Kafka 存儲設計的要點,然后將上面這些零散的知識點串聯起來。
此外,也希望大家在了解了 Kafka 的存儲設計后,能對 Append Only Data Structures 這一經典的底層存儲原理認識更加深刻,因為它驅動了業界太多極具影響力的存儲系統走向成功,比如 HBase、Cassandra、RocksDB 等等。
1. Kafka 的存儲難點是什么?
為什么說存儲設計是 Kafka 的精華所在?之前這篇文章做過分析,Kafka 通過簡化消息模型,將自己退化成了一個海量消息的存儲系統。
既然 Kafka 在其他功能特性上做了減法,必然會在存儲上下功夫,做到其他 MQ 無法企及的性能表現。
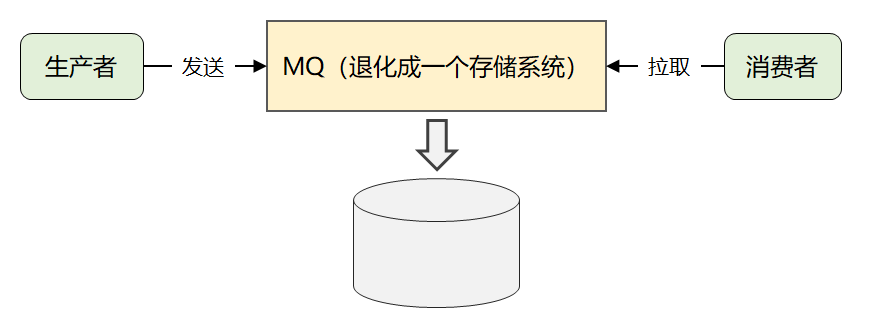
圖1:Kafka 的消息模型
但是在講解 Kafka 的存儲方案之前,我們有必要去嘗試分析下:為什么 Kafka 會采用 Logging(日志文件)的存儲方式?它的選型依據到底是什么?
這也是本系列希望做到的,思考力勝過記憶力,多問 why,而不是死記 what。
Kafka 的存儲選型邏輯,我認為跟我們開發業務需求的思路類似,到底用 MySQL、Redis 還是其他存儲方案?一定取決于具體的業務場景。
我們試著從以下兩個維度來分析下:
1、功能性需求:存的是什么數據?量級如何?需要存多久?CRUD 的場景都有哪些?
2、非功能性需求:性能和穩定性的要求是什么樣的?是否要考慮擴展性?
再回到 Kafka 來看,它的功能性需求至少包括以下幾點:
1、存的數據主要是消息流:消息可以是最簡單的文本字符串,也可以是自定義的復雜格式。
但是對于 Broker 來說,它只需處理好消息的投遞即可,無需關注消息內容本身。
2、數據量級非常大:因為 Kafka 作為 Linkedin 的孵化項目誕生,用作實時日志流處理(運營活動中的埋點、運維監控指標等),按 Linkedin 當初的業務規模來看,每天要處理的消息量預計在千億級規模。
3、CRUD 場景足夠簡單:因為消息隊列最核心的功能就是數據管道,它僅提供轉儲能力,因此 CRUD 操作確實很簡單。
首先,消息等同于通知事件,都是追加寫入的,根本無需考慮 update。其次,對于 Consumer 端來說,Broker 提供按 offset(消費位移)或者 timestamp(時間戳)查詢消息的能力就行。再次,長時間未消費的消息(比如 7 天前的),Broker 做好定期刪除即可。
接著,我們再來看看非功能性需求:
1、性能要求:之前的文章交代過,Linkedin 最初嘗試過用 ActiveMQ 來解決數據傳輸問題,但是性能無法滿足要求,然后才決定自研 Kafka。ActiveMQ 的單機吞吐量大約是萬級 TPS,Kafka 顯然要比 ActiveMQ 的性能高一個量級才行。
2、穩定性要求:消息的持久化(確保機器重啟后歷史數據不丟失)、單臺 Broker 宕機后如何快速故障轉移繼續對外提供服務,這兩個能力也是 Kafka 必須要考慮的。
3、擴展性要求:Kafka 面對的是海量數據的存儲問題,必然要考慮存儲的擴展性。
再簡單總結下,Kafka 的存儲需求如下:
1、功能性需求:其實足夠簡單,追加寫、無需update、能根據消費位移和時間戳查詢消息、能定期刪除過期的消息。
2、非功能性需求:是難點所在,因為 Kafka 本身就是一個高并發系統,必然會遇到典型的高性能、高可用和高擴展這三方面的挑戰。
2. Kafka 的存儲選型分析
有了上面的需求梳理,我們繼續往下分析。
為什么 Kafka 最終會選用 logging(日志文件)來存儲消息呢?而不是用我們最常見的關系型數據庫或者 key-value 數據庫呢?
2.1 存儲領域的基礎知識
先普及幾點存儲領域的基礎知識,這是我們進一步分析的理論依據。
1、內存的存取速度快,但是容量小、價格昂貴,不適用于要長期保存的數據。
2、磁盤的存取速度相對較慢,但是廉價、而且可以持久化存儲。
3、一次磁盤 IO 的耗時主要取決于:尋道時間和盤片旋轉時間,提高磁盤 IO 性能最有效的方法就是:減少隨機 IO,增加順序 IO。
4、磁盤的 IO 速度其實不一定比內存慢,取決于我們如何使用它。
關于磁盤和內存的 IO 速度,有很多這方面的對比測試,結果表明:磁盤順序寫入速度可以達到幾百兆/s,而隨機寫入速度只有幾百KB/s,相差上千倍。此外,磁盤順序 IO 訪問甚至可以超過內存隨機 IO 的性能。
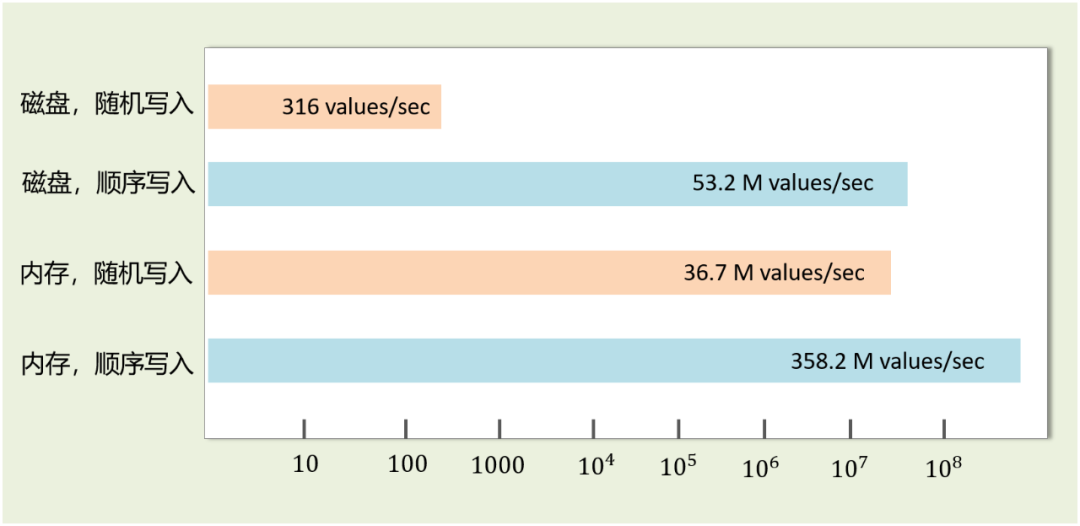
圖2:磁盤和內存的 IO 速度對比
再看數據存儲領域,有兩個 “極端” 發展方向:
1、加快讀:通過索引( B+ 樹、二份查找樹等方式),提高查詢速度,但是寫入數據時要維護索引,因此會降低寫入效率。
2、加快寫:純日志型,數據以 append 追加的方式順序寫入,不加索引,使得寫入速度非常高(理論上可接近磁盤的寫入速度),但是缺乏索引支持,因此查詢性能低。
基于這兩個極端,又衍生出來了 3 類最具代表性的底層索引結構:
1、哈希索引:通過哈希函數將 key 映射成數據的存儲地址,適用于等值查詢等簡單場景,對于比較查詢、范圍查詢等復雜場景無能為力。
2、B/B+ Tree 索引:最常見的索引類型,重點考慮的是讀性能,它是很多傳統關系型數據庫,比如 MySQL、Oracle 的底層結構。
3、 LSM Tree 索引:數據以 Append 方式追加寫入日志文件,優化了寫但是又沒顯著降低讀性能,眾多 NoSQL 存儲系統比如 BigTable,HBase,Cassandra,RocksDB 的底層結構。
2.2 Kafka 的存儲選型考慮
有了上面這些理論基礎,我們繼續回到 Kafka 的存儲需求上進行思考。
Kafka 所處業務場景的特點是:
1、寫入操作:并發非常高,百萬級 TPS,但都是順序寫入,無需考慮更新
2、查詢操作:需求簡單,能按照 offset 或者 timestamp 查詢消息即可
如果單純滿足 Kafka 百萬級 TPS 的寫入操作需求,采用 Append 追加寫日志文件的方式顯然是最理想的,前面講過磁盤順序寫的性能完全是可以滿足要求的。
剩下的就是如何解決高效查詢的問題。如果采用 B Tree 類的索引結構來實現,每次數據寫入時都需要維護索引(屬于隨機 IO 操作),而且還會引來“頁分裂”等比較耗時的操作。而這些代價對于僅需要實現簡單查詢要求的 Kafka 來說,顯得非常重。所以,B Tree 類的索引并不適用于 Kafka。
相反,哈希索引看起來卻非常合適。為了加快讀操作,如果只需要在內存中維護一個「從 offset 到日志文件偏移量」的映射關系即可,每次根據 offset 查找消息時,從哈希表中得到偏移量,再去讀文件即可。(根據 timestamp 查消息也可以采用同樣的思路)
但是哈希索引常駐內存,顯然沒法處理數據量很大的情況,Kafka 每秒可能會有高達幾百萬的消息寫入,一定會將內存撐爆。
可我們發現消息的 offset 完全可以設計成有序的(實際上是一個單調遞增 long 類型的字段),這樣消息在日志文件中本身就是有序存放的了,我們便沒必要為每個消息建 hash 索引了,完全可以將消息劃分成若干個 block,只索引每個 block 第一條消息的 offset 即可,先根據大小關系找到 block,然后在 block 中順序搜索,這便是 Kafka “稀疏索引” 的來源。

圖3:Kafka 的稀疏索引示意圖
最終我們發現:Append 追加寫日志 + 稀疏的哈希索引,形成了 Kafka 最終的存儲方案。而這不就是 LSM Tree 的設計思想嗎?
也許會有人會反駁 Kafka 的方案跟 LSM Tree 不一樣,并沒有用到樹型索引以及 Memtable 這一層。但我個人認為,從「設計思想」從這個角度來看,完全可以將 Kafka 視為 LSM Tree 的極端應用。
此外,關于 Append Only Data Structures 和 LSM Tree,推薦 Ben Stopford (Kafka 母公司的一位技術專家) 于 2017 年 QCon 上做的一個視頻分享,演講非常精彩,值得一看。

https://www.infoq.com/presentations/lsm-append-data-structures/
3. Kafka 的存儲設計
了解了 Kafka 存儲選型的來龍去脈后,最后我們再看下它具體的存儲結構。
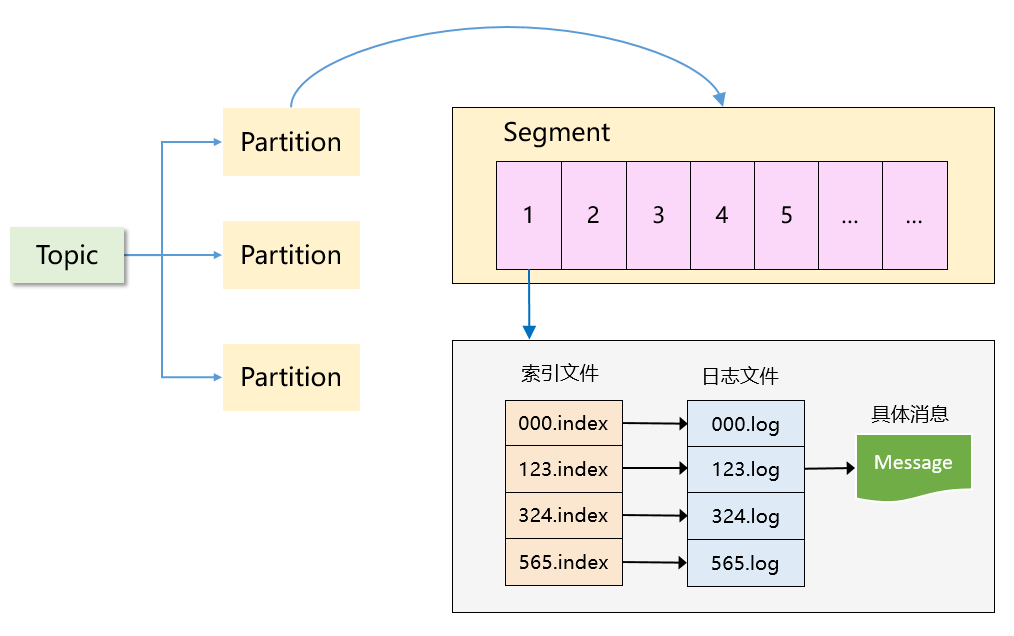
圖4:Kafka 的存儲結構
可以看到,Kafka 是一個「分區 + 分段 + 索引」的三層結構:
1、每個 Topic 被分成多個 Partition,Partition 從物理上可以理解成一個文件夾。
之前的文章解釋過:Partition 主要是為了解決 Kafka 存儲上的水平擴展問題,如果一個 Topic 的所有消息都只存在一個 Broker,這個 Broker 必然會成為瓶頸。因此,將 Topic 內的數據分成多個 Partition,然后分布到整個集群是很自然的設計方式。
2、每個 Partition 又被分成了多個 Segment,Segment 從物理上可以理解成一個「數據文件 + 索引文件」,這兩者是一一對應的。
一定有讀者會有疑問:有了 Partition 之后,為什么還需要 Segment?
如果不引入 Segment,一個 Partition 只對應一個文件,那這個文件會一直增大,勢必造成單個 Partition 文件過大,查找和維護不方便。
此外,在做歷史消息刪除時,必然需要將文件前面的內容刪除,不符合 Kafka 順序寫的思路。而在引入 Segment 后,則只需將舊的 Segment 文件刪除即可,保證了每個 Segment 的順序寫。
4. 寫在最后
本文從需求分析、到選型對比、再到具體的存儲方案,一步步撥開了 Kafka 選用 logging(日志文件)這一存儲方案的奧秘。
也是希望大家能去主動思考 Kafka 在存儲選型時的難點,把它當做一個系統設計題去思考,而不僅僅記住它用了日志存儲。
另外一個觀點:越底層越通用,你每次多往下研究深一點,會發現這些知識在很多優秀的開源系統里都是相通的。
下篇文章我將結合 Kafka 的源碼,分析它在存儲數據時的各個性能優化手段,我們下期見!
本文轉載自微信公眾號「武哥漫談IT」,可以通過以下二維碼關注。轉載本文請聯系武哥漫談IT公眾號。