MQ選型:一文詳解Kafka與RocketMQ區(qū)別
引言
在做MQ技術(shù)選型的時候,Kafka和RocketMQ是常用的兩個消息隊列中間件,今天就從架構(gòu)設(shè)計、性能分析、使用場景來比較一下兩者的區(qū)別,到底該使用哪個MQ?
Kafka最初由LinkedIn開發(fā),后來成為Apache的一個頂級項目,它設(shè)計之初就是為處理大規(guī)模數(shù)據(jù)而生,特別擅長于高吞吐量的場景。Kafka廣泛應(yīng)用于日志收集、流式處理、事件驅(qū)動架構(gòu)等多種場景,被許多知名企業(yè)采用,如Netflix、Uber和Twitter等。
RocketMQ原為阿里巴巴的內(nèi)部消息中間件,后來同樣成為了Apache的頂級項目。它在保證消息的高可靠性和順序性方面表現(xiàn)出色,非常適合金融行業(yè)等對數(shù)據(jù)一致性和可靠性要求極高的場景。除此之外,RocketMQ也支持多種消息傳遞模式,包括順序消息、延時消息和批量消息,能夠滿足復(fù)雜應(yīng)用場景的需求。
架構(gòu)設(shè)計
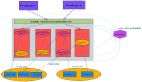
Kafka的基礎(chǔ)架構(gòu)
Apache Kafka 是一個分布式發(fā)布-訂閱消息系統(tǒng),設(shè)計之初的目標是處理大規(guī)模的數(shù)據(jù)流,并且以高吞吐量和低延遲為特點。Kafka 的架構(gòu)主要由以下幾個部分組成:
- Producer(生產(chǎn)者):生產(chǎn)者是發(fā)送消息到Broker集群。生產(chǎn)者將消息發(fā)送到指定的主題,Kafka根據(jù)配置的分區(qū)策略(如輪詢、按鍵哈希等)將消息分配到不同的分區(qū)。
- Consumer(消費者):消費者從Broker讀取消息。消費者可以獨立運行或分組在一起運行。分組中的消費者共享訂閱的主題,Kafka平衡各個消費者的負載,確保每個分區(qū)只被組內(nèi)的一個消費者讀取。
- Broker(消息代理服務(wù)器):Broker是Kafka集群中的一個服務(wù)器,負責(zé)存儲數(shù)據(jù)和處理對數(shù)據(jù)的讀寫請求。每個Broker可以存儲一個或多個主題的數(shù)據(jù)。一個Kafka集群可以包含多個Broker,以提高容量和提供容錯能力。
- Topic(主題): Topic是邏輯概念。生產(chǎn)者寫入消息到指定的Topic,消費者從Topic讀取消息。Topic在邏輯上被分割為一個或多個分區(qū),這允許數(shù)據(jù)在多個Broker之間進行負載均衡。
- Partition(分區(qū)): 分區(qū)是Topic的物理分段,每個分區(qū)是一個有序的、不可變的消息日志。分區(qū)可以分布在集群中的不同Broker上。每個分區(qū)都由一系列有序的、不斷增加的消息組成,每條消息都被分配一個順序的標識符稱為偏移量。
- ZooKeeper:Kafka使用ZooKeeper來維護集群狀態(tài)、配置信息和進行領(lǐng)導(dǎo)者選舉。
 圖片
圖片
RocketMQ的基礎(chǔ)架構(gòu)
RocketMQ主要由四個基本組件構(gòu)成:
- NameServer(命名服務(wù)器):NameServer是RocketMQ網(wǎng)絡(luò)中的注冊中心和路由中心,提供輕量級服務(wù)發(fā)現(xiàn)和路由功能。每個Broker啟動時都會在所有NameServer上注冊自己的路由信息,包括當(dāng)前Broker的IP地址、提供的Topic等信息。消費者和生產(chǎn)者通過查詢NameServer來獲取Topic的路由信息。
- Broker(消息代理服務(wù)器):Broker是消息處理的核心節(jié)點,負責(zé)存儲消息、驗證和服務(wù)消息傳輸。RocketMQ支持多個Broker配置,可以是同步或異步復(fù)制數(shù)據(jù)以確保高可用性。Broker處理大量的數(shù)據(jù)寫入操作,并支持消息的順序和并行處理。
- Producer(生產(chǎn)者):生產(chǎn)者負責(zé)發(fā)布消息到指定的Topic。RocketMQ支持多種消息發(fā)送模式,包括同步發(fā)送、異步發(fā)送和單向發(fā)送(不等待服務(wù)器響應(yīng))。
- Consumer(消費者):消費者從Broker訂閱消息并處理它們。RocketMQ支持集群消費和廣播消費兩種模式。在集群模式下,同一個Consumer Group中的不同Consumer實例平均分攤消息,而在廣播模式下,每個Consumer實例都會接收到所有的消息。
- Topic和Queue: Topic是消息的分類,每個Topic可以分為若干個Queue。RocketMQ通過增加Queue數(shù)量來水平擴展Topic的處理能力。
RocketMQ 支持多種消息模式,包括順序消息、定時/延時消息和批量消息等。此外,RocketMQ 提供了豐富的消息過濾功能,消費者可以根據(jù)Tag或者SQL92標準進行消息過濾,極大地增加了其靈活性和應(yīng)用場景。
 圖片
圖片
Kafka與RocketMQ在設(shè)計哲學(xué)和優(yōu)化點上有所不同。Kafka更注重于處理高吞吐量的數(shù)據(jù)流,而RocketMQ則提供了更為豐富的消息模式和高級功能,特別適合需要高可靠性和復(fù)雜消息處理場景的業(yè)務(wù)。
消息存儲機制
Kafka的日志存儲機制
**日志文件: **Kafka 所有的消息以日志的形式存儲在磁盤上,并且每個Partition都是一個連續(xù)的日志文件。 **追加寫入: **Kafka采用追加寫入的方式存儲消息到日志文件中,新消息被添加到文件的末尾,這種方式對于磁盤I/O是非常高效的,因為它大部分是順序?qū)懭耄瑥亩鴺O大地提高了寫入速度。但是當(dāng)Partition數(shù)量過多時,順序?qū)懢妥兂闪穗S機寫,性能下降。索引文件:為了快速查找和讀取特定消息,Kafka為每個日志文件維護一個索引文件。索引文件存儲消息在日志文件中的偏移量和其對應(yīng)在文件中的物理位置,這樣可以在不讀取整個日志文件的情況下直接跳轉(zhuǎn)到特定的消息。
RocketMQ的存儲設(shè)計
RocketMQ的存儲系統(tǒng)主要由以下幾部分構(gòu)成:CommitLog
- 統(tǒng)一存儲: 所有Topic的消息都存儲在一個名為CommitLog的文件中,每個消息都有一個全局唯一的偏移量。這種設(shè)計簡化了消息存儲的管理,但也要求高效的索引機制來支持快速消息查找。
- 順序?qū)懭耄?與Kafka類似,RocketMQ的CommitLog也采用順序?qū)懭氲姆绞剑蕴岣邔懭胄屎蜏p少磁盤I/O操作。順序?qū)懭肽茱@著提高消息存儲的性能。
- 定期切割: RocketMQ定期切分CommitLog和消費隊列文件,新的消息寫入到新文件中。老舊文件在滿足一定條件后可以刪除或者歸檔,以釋放存儲空間。
- 刷盤策略: RocketMQ提供了同步刷盤和異步刷盤兩種策略,用戶可以根據(jù)業(yè)務(wù)需求和對性能的要求選擇合適的刷盤方式。
消費隊列(Consume Queue)
- 索引機制:為了快速檢索到CommitLog中的消息,RocketMQ為每個隊列(Queue)維護一個消費隊列(Consume Queue)。消費隊列存儲了消息在CommitLog中的偏移量、消息長度和消息標簽的哈希碼等信息。
- 輕量級設(shè)計:消費隊列相比于CommitLog要小很多,因為它僅僅存儲索引信息,這使得加載和查找效率更高。
索引文件(Index File)
- 可選的索引服務(wù):RocketMQ提供了一個獨立的索引服務(wù),用于快速檢索具有特定鍵(如ID、Key或是業(yè)務(wù)屬性)的消息。索引文件存儲了鍵到消息物理位置的映射。
- 快速查詢:索引文件加速了基于鍵的消息查詢操作,使得RocketMQ能在大數(shù)據(jù)量中快速定位消息。
文件回收與存儲清理RocketMQ通過定期清理舊的CommitLog文件和消費隊列文件來回收磁盤空間,這些操作基于消息的存儲時間和消費狀態(tài)。定期刪除:系統(tǒng)根據(jù)配置的文件保留策略(如時間間隔、文件大小)自動刪除舊文件。數(shù)據(jù)壓縮:在必要時,RocketMQ可以對存儲的數(shù)據(jù)進行壓縮,以節(jié)省存儲空間。
高可用設(shè)計
Kafka高可用
副本機制: Kafka通過副本(replicas)機制確保數(shù)據(jù)的安全性。每個Topic可以被配置為一個或多個分區(qū)(partitions),每個分區(qū)可以有一個或多個副本。副本分布在不同的Broker上,這樣即使一個或多個Broker發(fā)生故障,Topic的數(shù)據(jù)也不會丟失。
領(lǐng)導(dǎo)者和追隨者: 每個分區(qū)有一個領(lǐng)導(dǎo)者(leader)和多個追隨者(followers)。所有的讀寫請求都由領(lǐng)導(dǎo)者處理,而追隨者則從領(lǐng)導(dǎo)者那里復(fù)制數(shù)據(jù)。如果領(lǐng)導(dǎo)者發(fā)生故障,系統(tǒng)會從追隨者中選舉出新的領(lǐng)導(dǎo)者。
控制器(Controller): 控制器是一個特殊的Broker節(jié)點,負責(zé)維護領(lǐng)導(dǎo)者的選舉和副本狀態(tài)的管理。如果控制器出現(xiàn)故障,集群中的其他Broker將通過選舉產(chǎn)生新的控制器。
ZooKeeper協(xié)調(diào): Kafka使用ZooKeeper來管理集群元數(shù)據(jù)和進行Broker之間的協(xié)調(diào),包括領(lǐng)導(dǎo)者選舉和集群成員管理。
高水位標記(high watermark): Kafka為每個分區(qū)維護一個“高水位”(high watermark)標記,這是所有同步副本已確認寫入的最小偏移量。只有高于高水位的消息才被認為是“提交”的,消費者只能讀取到這些已提交的消息。這保證了即使在發(fā)生故障的情況下,消費者也不會讀取到可能因故障而回滾的消息。
RocketMQ高可用
主從架構(gòu): 在Broker級別,RocketMQ采用主從架構(gòu),其中主Broker負責(zé)處理讀寫請求,而從Broker則負責(zé)復(fù)制主Broker的數(shù)據(jù)。如果主Broker宕機,從Broker可以迅速升級為新的主Broker,接管消息服務(wù)。
NameServer的高可用: RocketMQ使用NameServer管理元數(shù)據(jù)和路由信息,NameServer采用了無狀態(tài)設(shè)計,之間互不備份,每個NameServer獨立提供服務(wù)。即使部分NameServer出現(xiàn)故障,其他NameServer仍能繼續(xù)提供服務(wù)。
同步復(fù)制與異步復(fù)制: RocketMQ支持同步和異步兩種數(shù)據(jù)復(fù)制方式。在同步復(fù)制模式下,生產(chǎn)者發(fā)送的消息必須被存儲在所有同步副本中Broker確認后才返回成功響應(yīng),確保了數(shù)據(jù)的強一致性。異步復(fù)制則強調(diào)高吞吐量,犧牲了一部分數(shù)據(jù)安全性。
主要區(qū)別:
- 元數(shù)據(jù)管理:
Kafka強依賴Zookeeper進行集群管理和元數(shù)據(jù)存儲,而RocketMQ則依賴輕量級的NameServer進行路由信息管理,不涉及集群狀態(tài)管理。
- 數(shù)據(jù)復(fù)制與故障恢復(fù):
Kafka是基于分區(qū),側(cè)重于通過領(lǐng)導(dǎo)者和追隨者模式實現(xiàn)數(shù)據(jù)復(fù)制,依賴自動的領(lǐng)導(dǎo)者選舉來恢復(fù)服務(wù)。RocketMQ是基于Broker,提供了主從同步或異步復(fù)制,通常需要更多手動干預(yù)來切換Master。
- 架構(gòu)和擴展性:
Kafka的架構(gòu)設(shè)計為分布式系統(tǒng)帶來了強大的水平擴展性,適合處理大規(guī)模數(shù)據(jù)流。RocketMQ通過主從復(fù)制機制提供高可靠性,適用于交易等對數(shù)據(jù)一致性要求極高的場景。
消息可靠性保證
Kafka消息可靠性
- 復(fù)制(Replication)
Kafka通過在多個Broker中復(fù)制每個Topic的Partition來增加數(shù)據(jù)的可靠性和系統(tǒng)的容錯性。這意味著每個Partition都有一個Leader和多個Follower。所有的寫操作都通過Leader進行,而Follower從Leader同步數(shù)據(jù)。如果Leader失敗,一個Follower將被自動選舉為新的Leader,確保服務(wù)的連續(xù)性和數(shù)據(jù)的可用性。
- 確認機制(Acknowledgments)
生產(chǎn)者在發(fā)送消息時可以指定不同級別的確認機制來保證消息的可靠傳遞:
acks=0:生產(chǎn)者在寫入消息后不會等待任何服務(wù)器的確認,這種模式下消息可能會丟失,但延遲最低。 acks=1:生產(chǎn)者會等待Leader確認消息已被寫入本地日志后才考慮完成請求。這種模式下,如果在Follower復(fù)制之前Leader發(fā)生故障,消息可能會丟失。 acks=all 或 acks=-1:生產(chǎn)者會等待所有同步副本都確認消息已被接收,才認為消息發(fā)送成功。這提供了最高的數(shù)據(jù)可靠性保證。
- 事務(wù)支持
從0.11版本開始,Kafka引入了事務(wù)API,支持跨多個Partition的原子寫操作。這意味著生產(chǎn)者可以發(fā)送一批消息,這些消息要么全部成功寫入,要么全部失敗,從而防止了在處理復(fù)雜業(yè)務(wù)邏輯時出現(xiàn)部分更新的情況。
- 持久化
Kafka默認將所有消息持久化到磁盤,這不僅確保了數(shù)據(jù)在系統(tǒng)重啟后的可恢復(fù)性,還能保護數(shù)據(jù)不受系統(tǒng)故障的影響。Kafka通過順序?qū)懘疟P的方式優(yōu)化了I/O性能,即使是在高負載下也能保持高吞吐量。
- 高水位(High Watermark)
Kafka為每個Partition維護一個高水位標記,這表示所有同步副本都確認接收到的最小偏移量。消費者只能讀取到高水位之前的消息,這保證了消費者只看到已經(jīng)被所有同步副本確認的消息,增加了讀操作的一致性。
RocketMQ消息可靠性
- 復(fù)制
同步雙寫:在默認設(shè)置下,消息被同時寫入到主Broker(Master)和從Broker(Slave)。只有當(dāng)主從Broker都成功寫入消息后,生產(chǎn)者才會收到一個成功的響應(yīng)。這確保了即使主Broker發(fā)生故障,消息也不會丟失,因為它已經(jīng)存在于至少一個從Broker中。異步復(fù)制:除了同步雙寫,RocketMQ還支持異步復(fù)制模式,這在提高性能和吞吐量方面更為有效,尤其是在對延遲要求不是特別嚴格的場景下。
- 確認機制(Acknowledgments)
消息確認:RocketMQ 支持端到端的消息確認機制。生產(chǎn)者在發(fā)送消息后會等待Broker的確認,只有收到確認后才認為消息發(fā)送成功。重試機制:如果消息在傳輸過程中失敗(例如,因為網(wǎng)絡(luò)問題或Broker處理能力達到瓶頸),RocketMQ提供了自動重試機制。生產(chǎn)者可以配置消息的重試次數(shù)和重試間隔,以增加消息傳遞成功的概率。
- 事務(wù)消息
RocketMQ 支持事務(wù)消息,采用半消息機制(half message),允許生產(chǎn)者在發(fā)送消息的同時執(zhí)行本地事務(wù),然后根據(jù)本地事務(wù)執(zhí)行的結(jié)果來提交或回滾消息。
延遲消息
- Kafka不支持延遲消息
- RocketMQ提供了多個預(yù)定義級別的延遲消息。
可選級別有:
1s 5s 10s 30s 1m 2m 3m 4m 5m 6m 7m 8m 9m 10m 20m 30m 1h 2h
示例代碼:
import org.apache.rocketmq.client.producer.DefaultMQProducer;
import org.apache.rocketmq.common.message.Message;
public class DelayedMessageProducer {
public static void main(String[] args) throws Exception {
// 創(chuàng)建生產(chǎn)者,并指定生產(chǎn)者組名
DefaultMQProducer producer = new DefaultMQProducer("example_producer_group");
// 設(shè)置NameServer地址
producer.setNamesrvAddr("localhost:9876");
// 啟動生產(chǎn)者
producer.start();
// 創(chuàng)建消息實例,指定Topic、Tag和消息體
Message message = new Message("TopicTest", "TagA", "Hello RocketMQ, I will be sent after 30 seconds".getBytes());
// 設(shè)置延遲級別為4,即30秒
message.setDelayTimeLevel(4);
// 發(fā)送消息
producer.send(message);
// 關(guān)閉生產(chǎn)者
producer.shutdown();
}
}順序消息
- Kafka支持單分區(qū)有序
- RocketMQ 提供兩種類型的順序消息:
全局順序消息:全局順序消息確保消息全局嚴格按照發(fā)送順序被消費。實現(xiàn)方式是將所有消息路由到同一個隊列(Queue)中。
分區(qū)順序消息:分區(qū)順序消息確保同一分區(qū)內(nèi)的消息嚴格按照發(fā)送順序被消費。每個主題可以有多個隊列,每個隊列保證隊列內(nèi)消息的順序性。
消息過濾
- Kafka不支持在Broker層面進行消息過濾
- RocketMQ在Broker層面提供了兩種消息過濾機制,分別是標簽過濾和SQL表達式過濾。
1. 標簽過濾(Tag Filtering)這是RocketMQ最基本也是最常用的消息過濾方式。生產(chǎn)者在發(fā)送消息時可以指定一個標簽(Tag),消費者在訂閱消息時可以指定感興趣的標簽,Broker僅將符合標簽的消息推送給消費者。 發(fā)送消息時指定標簽:
Message msg = new Message("TopicTest", "TagA", "OrderID001", "Hello world".getBytes());消費者訂閱指定標簽:
consumer.subscribe("TopicTest", "TagA || TagB");2. SQL表達式過濾(SQL92 Filtering)RocketMQ 4.4.0 版本以上支持基于 SQL92 的表達式進行消息過濾,這提供了更為強大和靈活的消息選擇能力。生產(chǎn)者在發(fā)送消息時可以設(shè)置消息屬性,消費者可以通過 SQL92 表達式對這些屬性進行篩選。 發(fā)送消息時設(shè)置屬性:
Message msg = new Message("TopicTest", "TagA", "OrderID002", "Hello world".getBytes());
msg.putUserProperty("a", String.valueOf(10));消費者使用 SQL 表達式訂閱:
consumer.subscribe("TopicTest", MessageSelector.bySql("a > 5 AND b <> 'abc'"));對于使用SQL表達式過濾,RocketMQ需要配置Broker啟用此功能。在broker.conf中設(shè)置:
enablePropertyFilter=true消息重試
Kafka消息重試機制
Kafka支持生產(chǎn)者發(fā)送消息失敗的時候自動重試,不支持消費者消費消息失敗時重試。生產(chǎn)者重試配置:
- retries:
這個參數(shù)設(shè)置了生產(chǎn)者在發(fā)送消息時可以重試的次數(shù)。默認值通常是 0,表示不進行重試。如果設(shè)置為大于0的值,生產(chǎn)者將在發(fā)送失敗后嘗試重新發(fā)送消息指定的次數(shù)。
- retry.backoff.ms:
這個參數(shù)用來設(shè)置每次重試之間的時間間隔(以毫秒為單位)。這可以避免在出現(xiàn)暫時性問題時過于頻繁地重試,給系統(tǒng)帶來不必要的負擔(dān)。默認值通常是 100ms。
- max.in.flight.requests.per.connection:
此參數(shù)定義了生產(chǎn)者在收到服務(wù)器響應(yīng)之前可以發(fā)送的最大請求數(shù)。如果設(shè)置為1,這將保證消息是按照發(fā)送的順序?qū)懭敕?wù)器的,即使進行了重試。如果大于1,則在高吞吐量的情況下可以提高性能,但可能會導(dǎo)致重試后消息順序的改變。
生產(chǎn)者重試代碼示例:
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.clients.producer.RecordMetadata;
import java.util.Properties;
public class ProducerDemo {
public static void main(String[] args) {
Properties props = new Properties();
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer");
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer");
props.put(ProducerConfig.RETRIES_CONFIG, 3); // 啟用重試,重試3次
props.put(ProducerConfig.RETRY_BACKOFF_MS_CONFIG, 300); // 設(shè)置重試的時間間隔為300ms
props.put(ProducerConfig.MAX_IN_FLIGHT_REQUESTS_PER_CONNECTION, 1); // 保持消息順序
KafkaProducer<String, String> producer = new KafkaProducer<>(props);
ProducerRecord<String, String> record = new ProducerRecord<>("test-topic", "key", "value");
producer.send(record, (RecordMetadata metadata, Exception exception) -> {
if (exception != null) {
exception.printStackTrace(); // 處理發(fā)送異常
} else {
System.out.println("Message sent successfully: " + metadata);
}
});
producer.close();
}
}注意事項
- 冪等性:從Kafka 0.11版本開始,支持冪等性生產(chǎn)者,通過配置enable.idempotence=true,可以保證即使進行重試,消息也不會在Kafka中重復(fù)。
- 錯誤處理:應(yīng)用程序應(yīng)適當(dāng)處理重試后仍然失敗的情況,比如記錄日志、發(fā)送告警等。
RocketMQ消息重試機制
RocketMQ 既支持生產(chǎn)者發(fā)送消息失敗的時候自動重試,也支持消費者消費消息失敗時重試。RocketMQ 生產(chǎn)者發(fā)送失敗重試機制:默認重試策略
- 重試次數(shù): RocketMQ 生產(chǎn)者默認會在消息發(fā)送失敗時自動重試,通常默認重試次數(shù)為 2 次(總共發(fā)送 3 次:首次發(fā)送加上兩次重試)。
- 重試間隔: 默認的重試間隔時間是 3000 毫秒(3 秒),即在初次發(fā)送失敗后,會在 3 秒后進行第一次重試。
可以根據(jù)實際需要配置生產(chǎn)者的重試次數(shù)和重試間隔。這通常在創(chuàng)建生產(chǎn)者實例時進行設(shè)置:
public static void main(String[] args) throws MQClientException {
// 創(chuàng)建消息生產(chǎn)者,指定生產(chǎn)者組名
DefaultMQProducer producer = new DefaultMQProducer("producerGroup");
// 設(shè)置 NameServer 地址
producer.setNamesrvAddr("localhost:9876");
// 設(shè)置重試次數(shù),默認2次,設(shè)置為5次
producer.setRetryTimesWhenSendFailed(5);
// 設(shè)置消息發(fā)送超時時間,超過這個時間未發(fā)送成功則不再重試,默認為3000ms
producer.setSendMsgTimeout(4000);
// 啟動生產(chǎn)者
producer.start();
// 創(chuàng)建消息
Message msg = new Message("TopicTest", "TagA", ("Hello RocketMQ ").getBytes(RemotingHelper.DEFAULT_CHARSET));
// 發(fā)送消息
try {
SendResult sendResult = producer.send(msg);
System.out.printf("%s%n", sendResult);
} catch (Exception e) {
e.printStackTrace();
}
// 關(guān)閉生產(chǎn)者
producer.shutdown();
}RocketMQ 消費者消費失敗重試機制:當(dāng)消費者從隊列中拉取到消息并且在處理過程中失敗(通常是業(yè)務(wù)邏輯拋出異常或者返回了錯誤狀態(tài)),RocketMQ 提供了自動的消息重試機制。這意味著消息不會被立即標記為“已消費”,而是會重新被放入隊列,稍后再次投遞給消費者。
- 重試延遲:
RocketMQ 為消費失敗的消息設(shè)置了一系列遞增的延遲時間等級,例如,首次重試可能延遲 10 秒,隨后 30 秒、1 分鐘、2 分鐘等。 默認情況下,RocketMQ 提供了 16 級延遲時間,最長可以延遲兩個小時。
- 重試次數(shù):
如果消息連續(xù)多次重試仍然失敗,當(dāng)重試次數(shù)達到上限后(默認是 16 次),消息將不再進入重試隊列。 這些“死信消息”會被轉(zhuǎn)移到一個特殊的死信隊列(DLQ,Dead-Letter Queue),開發(fā)者可以對這些消息進行特殊處理。非順序消息重試間隔如下:
第幾次重試 | 與上次重試的間隔時間 |
1 | 10秒 |
2 | 30秒 |
3 | 1分鐘 |
4 | 2分鐘 |
5 | 3分鐘 |
6 | 4分鐘 |
7 | 5分鐘 |
8 | 6分鐘 |
9 | 7分鐘 |
10 | 8分鐘 |
11 | 9分鐘 |
12 | 10分鐘 |
13 | 20分鐘 |
14 | 30分鐘 |
15 | 1小時 |
16 | 2小時 |
消費者重試代碼示例:
public class ConsumerDemo {
public static void main(String[] args) throws MQClientException {
DefaultMQPushConsumer consumer = new DefaultMQPushConsumer("consumer_group");
consumer.setNamesrvAddr("localhost:9876");
consumer.subscribe("TopicTest", "*");
consumer.registerMessageListener(new MessageListenerConcurrently() {
@Override
public ConsumeConcurrentlyStatus consumeMessage(List<MessageExt> msgs, ConsumeConcurrentlyContext context) {
try {
for (MessageExt msg : msgs) {
String body = new String(msg.getBody(), "UTF-8");
System.out.println("Receive message: " + body);
// 業(yè)務(wù)邏輯處理
}
return ConsumeConcurrentlyStatus.CONSUME_SUCCESS;
} catch (Exception e) {
e.printStackTrace();
// 告訴MQ這條消息處理失敗,需要稍后重新消費
return ConsumeConcurrentlyStatus.RECONSUME_LATER;
}
}
});
consumer.start();
System.out.println("Consumer Started.");
}
}消息回溯
消息回溯指的是消費者重新消費已經(jīng)消費過的消息。這個功能對于處理消費失敗、消息處理錯誤或者需要重新處理數(shù)據(jù)的場景非常有用。 Kafka和RocketMQ都支持以下兩種消息回溯:
- 基于偏移量回溯:
消費者可以直接指定隊列的偏移量來回溯消息。這種方式需要消費者知道具體的偏移量。
- 基于時間戳回溯:
消費者根據(jù)時間戳來重置消費進度。這種方式適用于希望從某一特定時間點重新開始消費消息的場景。
事務(wù)消息
Kafka事務(wù)消息
Kafka 0.11 版本開始支持事務(wù)消息,允許生產(chǎn)者在單個或多個分區(qū)中原子地寫入消息。通過事務(wù)消息,生產(chǎn)者可以確保消息要么全被發(fā)送,要么全不發(fā)送,從而避免了在失敗時消息部分發(fā)送的問題。
Kafka 事務(wù)消息的關(guān)鍵概念
- 事務(wù)ID:每個事務(wù)生產(chǎn)者都被分配一個唯一的事務(wù)ID。這個ID用來標識生產(chǎn)者的事務(wù)狀態(tài),并保證即使在發(fā)生故障后,也能恢復(fù)并繼續(xù)處理事務(wù)。
- 事務(wù)協(xié)調(diào)器:Kafka集群中的每個事務(wù)生產(chǎn)者都有一個事務(wù)協(xié)調(diào)器(Transaction Coordinator)與之對應(yīng)。協(xié)調(diào)器負責(zé)管理所有與其事務(wù)ID相關(guān)的事務(wù)狀態(tài)。
- 生產(chǎn)者冪等性:事務(wù)生產(chǎn)者在 Kafka 中自動啟用冪等性。冪等性保證了即使生產(chǎn)者發(fā)送相同消息多次,消息也只會被寫入一次。
如何使用 Kafka 事務(wù)消息
- 配置事務(wù)生產(chǎn)者:啟用事務(wù)需要在生產(chǎn)者配置中設(shè)置 transactional.id 和開啟冪等性。
- 初始化事務(wù):通過調(diào)用 initTransactions() 方法初始化事務(wù)環(huán)境。
- 開始事務(wù):通過調(diào)用 beginTransaction() 開始一個新的事務(wù)。
- 發(fā)送消息:在事務(wù)中正常發(fā)送消息。
- 提交或中止事務(wù):根據(jù)業(yè)務(wù)邏輯處理結(jié)果,調(diào)用 commitTransaction() 或 abortTransaction() 來提交或中止事務(wù)。
示例代碼
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.common.serialization.StringSerializer;
import java.util.Properties;
public class KafkaTransactionalProducerExample {
public static void main(String[] args) {
Properties props = new Properties();
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
props.put(ProducerConfig.TRANSACTIONAL_ID_CONFIG, "prod-1"); // 指定事務(wù)ID
props.put(ProducerConfig.ENABLE_IDEMPOTENCE_CONFIG, "true"); // 啟用冪等性
KafkaProducer<String, String> producer = new KafkaProducer<>(props);
// 1. 初始化事務(wù)
producer.initTransactions();
try {
// 2. 開啟事務(wù)
producer.beginTransaction();
for (int i = 0; i < 100; i++) {
// 3. 同時發(fā)送到多個分區(qū)
producer.send(new ProducerRecord<>("your-topic", Integer.toString(i), "test message - " + i));
}
// 4. 提交事務(wù)
producer.commitTransaction();
} catch (Exception e) {
// 5. 中止事務(wù)
producer.abortTransaction();
} finally {
producer.close();
}
}
}注意事項
- 事務(wù)超時:事務(wù)生產(chǎn)者必須在配置的事務(wù)超時時間內(nèi)完成事務(wù),否則 Kafka 會認為事務(wù)失敗并自動中止它。
- 單一生產(chǎn)者規(guī)則:事務(wù)ID 應(yīng)唯一對應(yīng)單一生產(chǎn)者實例,以避免并發(fā)沖突和潛在的數(shù)據(jù)不一致問題。
- 事務(wù)與消費者:確保消費者正確處理事務(wù)消息,例如使用 read_committed 配置來只消費已提交的消息。
RocketMQ 事務(wù)消息
RocketMQ采用半消息機制,實現(xiàn)了事務(wù)消息,就是把本地事務(wù)和生產(chǎn)者發(fā)送消息放在一個事務(wù)中。RocketMQ 事務(wù)消息工作原理
- 半消息(Half Message): 事務(wù)消息首先被發(fā)送為“半消息”,這意味著消息被Broker接收但對消費者不可見。
- 執(zhí)行本地事務(wù): 一旦半消息被成功發(fā)送,生產(chǎn)者客戶端將執(zhí)行本地事務(wù)邏輯(如數(shù)據(jù)庫操作)。
- 提交或回滾: 根據(jù)本地事務(wù)執(zhí)行的結(jié)果,生產(chǎn)者決定是提交還是回滾事務(wù)消息:
如果本地事務(wù)成功,生產(chǎn)者發(fā)送提交消息指令給Broker,使得半消息對消費者可見。
如果本地事務(wù)失敗,生產(chǎn)者發(fā)送回滾消息指令給Broker,Broker將刪除半消息。
- 消息狀態(tài)回查: 如果Broker沒有收到最終的提交或回滾指令(可能由于生產(chǎn)者崩潰等原因),Broker將向生產(chǎn)者查詢該半消息對應(yīng)的本地事務(wù)狀態(tài)。
示例代碼
import org.apache.rocketmq.client.producer.TransactionMQProducer;
import org.apache.rocketmq.client.producer.TransactionSendResult;
import org.apache.rocketmq.client.producer.LocalTransactionState;
import org.apache.rocketmq.client.producer.TransactionListener;
import org.apache.rocketmq.common.message.Message;
public class TransactionProducer {
public static void main(String[] args) throws MQClientException {
// 創(chuàng)建事務(wù)生產(chǎn)者,指定生產(chǎn)者組名
TransactionMQProducer producer = new TransactionMQProducer("producer_group");
producer.setNamesrvAddr("localhost:9876");
// 設(shè)置事務(wù)監(jiān)聽器
producer.setTransactionListener(new TransactionListener() {
@Override
public LocalTransactionState executeLocalTransaction(Message msg, Object arg) {
// 執(zhí)行本地事務(wù)邏輯
// 返回事務(wù)狀態(tài)
return LocalTransactionState.COMMIT_MESSAGE;
}
@Override
public LocalTransactionState checkLocalTransaction(MessageExt msg) {
// 提供事務(wù)狀態(tài)的檢查邏輯
return LocalTransactionState.COMMIT_MESSAGE;
}
});
producer.start();
// 創(chuàng)建消息
Message msg = new Message("TopicTest", "TagA", "Key", "Transaction Message".getBytes());
// 發(fā)送事務(wù)消息
TransactionSendResult sendResult = producer.sendMessageInTransaction(msg, null);
System.out.printf("%s%n", sendResult);
producer.shutdown();
}
}集群擴展
Kafka 集群擴展
- 統(tǒng)一的 Broker 角色:
Kafka 的 Broker 同時負責(zé)消息存儲、處理和路由信息的管理。每個 Broker 都可以處理客戶端的請求,存儲消息數(shù)據(jù),以及處理其他 Broker 的數(shù)據(jù)復(fù)制請求。
- 復(fù)制機制:
Kafka 采用分區(qū)和副本的方式進行數(shù)據(jù)復(fù)制。每個主題被分為多個分區(qū),每個分區(qū)可以有一個或多個副本,復(fù)制策略可以配置為同步或異步。
- 擴展性:
擴展 Kafka 集群主要是通過增加更多的 Broker 來完成。新的 Broker 加入后,可以通過重新平衡分區(qū)來分散數(shù)據(jù)和請求負載。
- 依賴于 Zookeeper:
Kafka 使用 Zookeeper 進行集群管理和協(xié)調(diào),雖然最新版本的 Kafka 正在嘗試去除對 Zookeeper 的依賴。
RocketMQ 集群擴展
- 角色區(qū)分:
RocketMQ 明確區(qū)分了 Broker 和 NameServer 的角色。Broker 負責(zé)消息存儲和傳輸,而 NameServer 提供路由信息和服務(wù)發(fā)現(xiàn)功能,不參與消息傳遞。
- 主從同步:
RocketMQ 支持主從同步,其中 Master Broker 處理讀寫請求,Slave Broker 主要用于數(shù)據(jù)同步和故障恢復(fù)。
- 擴展方式:
擴展 RocketMQ 集群通常涉及添加更多的 Broker(Master/Slave)和可能的 NameServer。這種方式有助于提升集群的容錯能力和數(shù)據(jù)的可用性。
- 靈活的部署:
可以靈活地部署多個 NameServer 來提高服務(wù)的可用性,但 NameServer 之間不進行數(shù)據(jù)同步。
核心區(qū)別
- 依賴服務(wù):RocketMQ 使用 NameServer 作為獨立的路由和服務(wù)發(fā)現(xiàn)層,而 Kafka 使用 Zookeeper 作為協(xié)調(diào)服務(wù)。
- 數(shù)據(jù)同步:RocketMQ 的主從架構(gòu)與 Kafka 的分區(qū)副本策略提供了不同的數(shù)據(jù)同步和故障恢復(fù)機制。
- 擴展操作:RocketMQ 在擴展時可能需要同時增加 Broker 和 NameServer,而 Kafka 的擴展更多關(guān)注于增加 Broker 和分區(qū)重新平衡。
使用場景
RocketMQ 使用場景
- 事務(wù)消息:
RocketMQ 提供原生支持的事務(wù)消息特別適合需要處理復(fù)雜業(yè)務(wù)邏輯的場景,如電子商務(wù)中的訂單系統(tǒng),可以在處理業(yè)務(wù)邏輯失敗時進行消息回滾。
- 順序消息:
RocketMQ 支持嚴格的順序消息,非常適合需要消息嚴格順序消費的場景,如金融行業(yè)的交易和支付系統(tǒng)。
- 廣播消息:
RocketMQ 支持廣播消息發(fā)送,適用于發(fā)送如廣告信息、系統(tǒng)通知等到多個接收者的場景。
- 定時、延遲消息:
RocketMQ 支持定時或延遲消息傳遞,適合需要在指定時間執(zhí)行任務(wù)的應(yīng)用,例如定時推送、預(yù)約提醒等。
- 可靠性和可用性較高的應(yīng)用:
RocketMQ 的設(shè)計注重高可用性和服務(wù)的穩(wěn)定性,適合銀行、股票交易和電信運營商等對消息丟失敏感度極高的行業(yè)。
Kafka 使用場景
- 日志聚合:
Kafka 常用于日志數(shù)據(jù)的收集和聚合,適用于需要高吞吐量處理日志文件的場景,如中大型網(wǎng)站的用戶活動跟蹤、應(yīng)用日志集中管理等。
- 流式處理:
Kafka 與流處理框架(如 Apache Flink、Apache Storm 和 Kafka Streams)結(jié)合,提供實時數(shù)據(jù)流處理能力,適合實時分析和監(jiān)控系統(tǒng)。
- 事件驅(qū)動架構(gòu):
Kafka 支持高吞吐的事件發(fā)布和訂閱,適用于構(gòu)建微服務(wù)架構(gòu)中的事件驅(qū)動系統(tǒng),可以作為各個服務(wù)之間解耦的通信中間件。
- 數(shù)據(jù)湖或數(shù)據(jù)倉庫的數(shù)據(jù)集成:
Kafka 可以作為數(shù)據(jù)管道,將數(shù)據(jù)從多個源頭實時傳輸?shù)酱髷?shù)據(jù)平臺(如 Hadoop 或 Spark),支持大數(shù)據(jù)分析和數(shù)據(jù)挖掘。
- 分布式系統(tǒng)的冗余備份:
Kafka 的數(shù)據(jù)復(fù)制特性適用于需要在多個地理位置進行冗余備份的系統(tǒng),以提高數(shù)據(jù)的可靠性和系統(tǒng)的災(zāi)難恢復(fù)能力。
區(qū)別
選擇 RocketMQ 或 Kafka 主要取決于具體的業(yè)務(wù)需求、系統(tǒng)要求以及團隊的技術(shù)棧偏好。如果需要處理具有復(fù)雜業(yè)務(wù)邏輯的事務(wù)性消息,或需要精確控制消息順序和定時發(fā)送的功能,RocketMQ 可能是更合適的選擇。 而如果應(yīng)用場景更側(cè)重于高吞吐量的數(shù)據(jù)處理,如日志收集、實時數(shù)據(jù)流處理或事件驅(qū)動的微服務(wù)架構(gòu),Kafka 則可能是更優(yōu)的選擇。