無需額外數據,首次實現ImageNet 87.1% 精度,顏水成團隊開源VOLO
近十年來,計算機視覺識別任務一直由卷積神經網絡 (CNN) 主導。盡管最近流行的視覺 Transformer 在基于 self-attention 的模型中顯示出巨大的潛力,但是在沒有提供額外數據的情況下,比如在 ImageNet 上的分類任務,它們的性能仍然不如最新的 SOTA CNNs。目前,在無額外數據集時,ImageNet 上的最高性能依舊是由 Google DeepMind 提出的 NFNet (Normalizer-Free Network)所獲得。
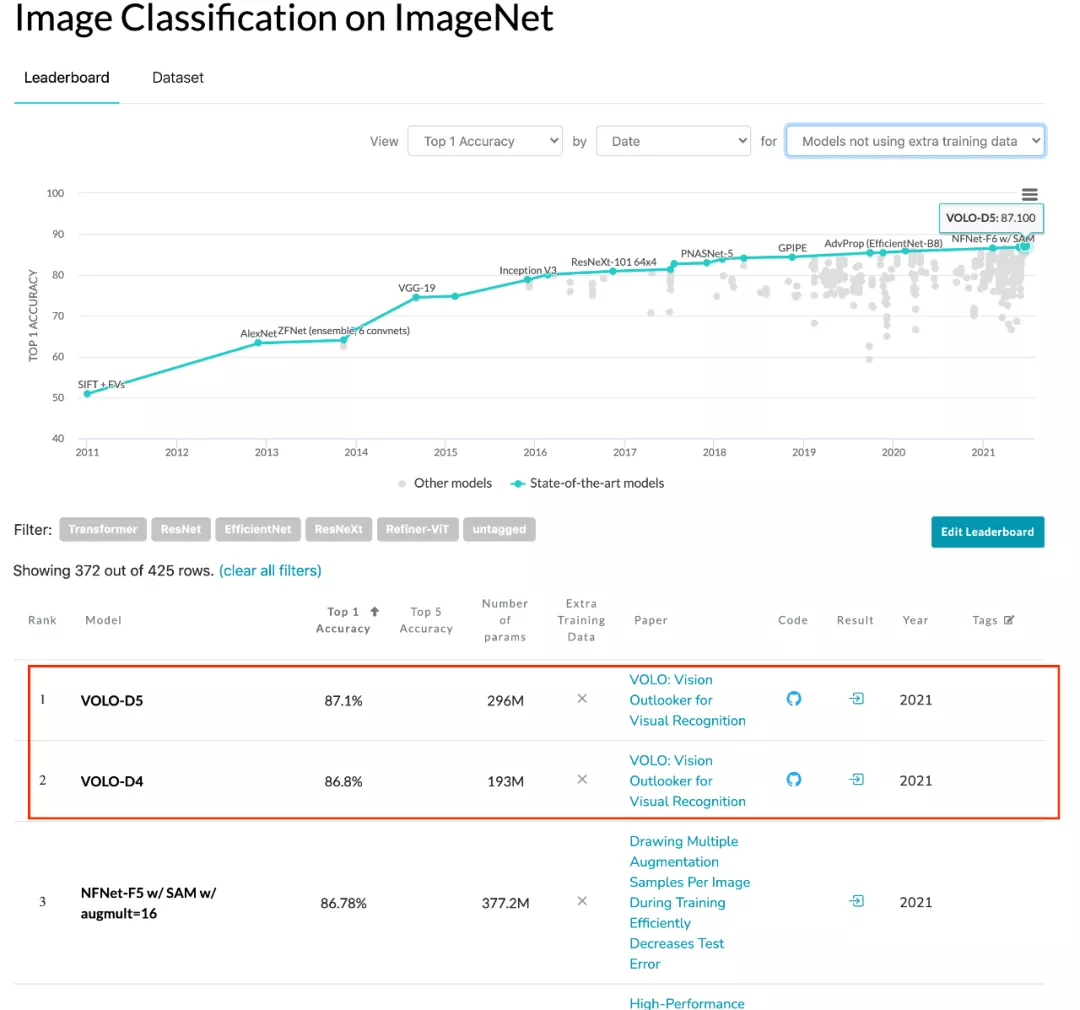
ImageNet 分類性能實時排行榜(無額外數據集),來源 https://paperswithcode.com/
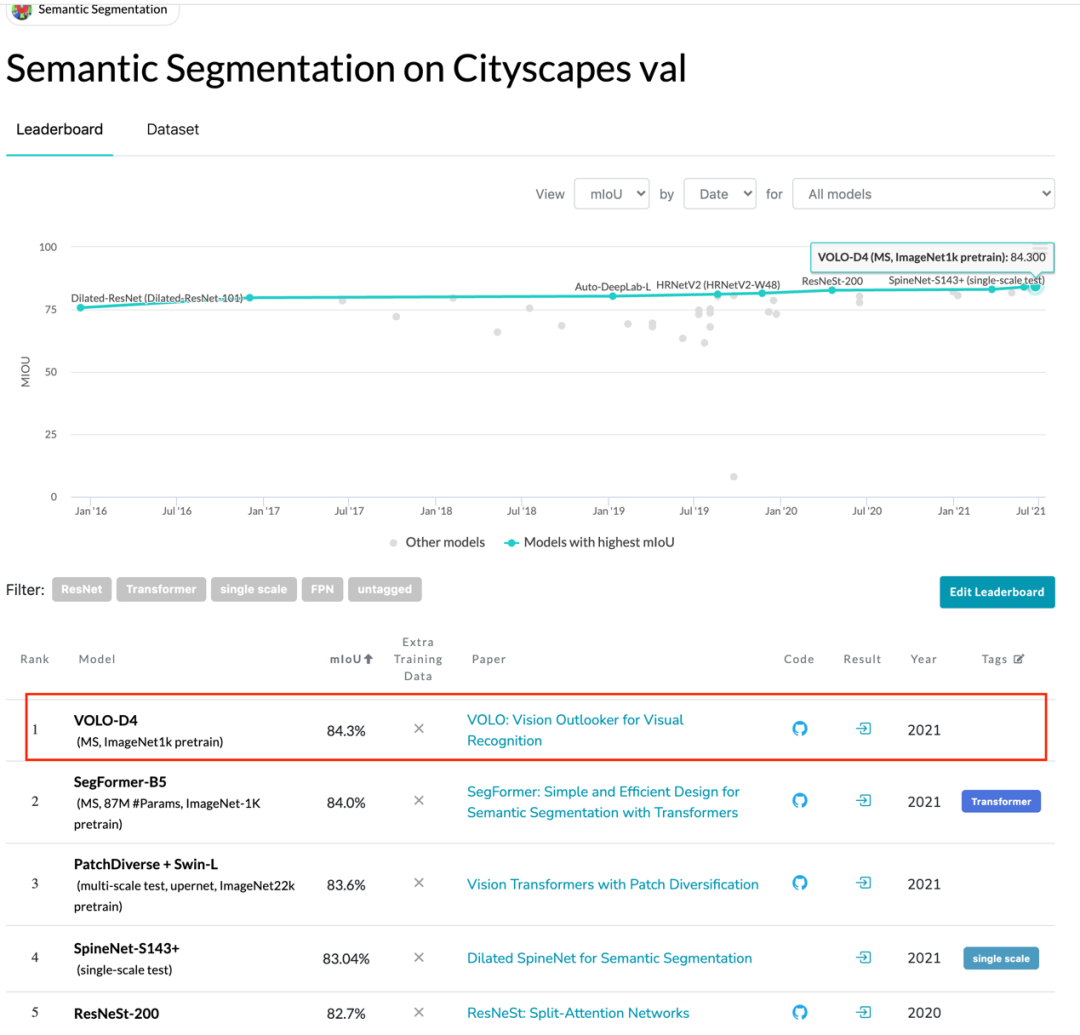
Cityscapes validation 實時排行榜,來源 https://paperswithcode.com/
在一篇最近發表的論文中,來自新加坡 Sea 集團旗下、顏水成教授領導的 Sea AI Lab (SAIL) 團隊提出了一種新的深度學習網絡模型結構——Vision Outlooker (VOLO),用于高性能視覺識別任務。它是一個簡單且通用的結構,在不使用任何額外數據的情況下,實現了在 ImageNet 上圖像分類任務 87.1% 的精度目標;同時,實現了在分割數據集 CityScapes Validation 上 84.3% 的性能,創下 ImageNet-1K 分類任務和 CityScapes 分割任務的兩項新紀錄。
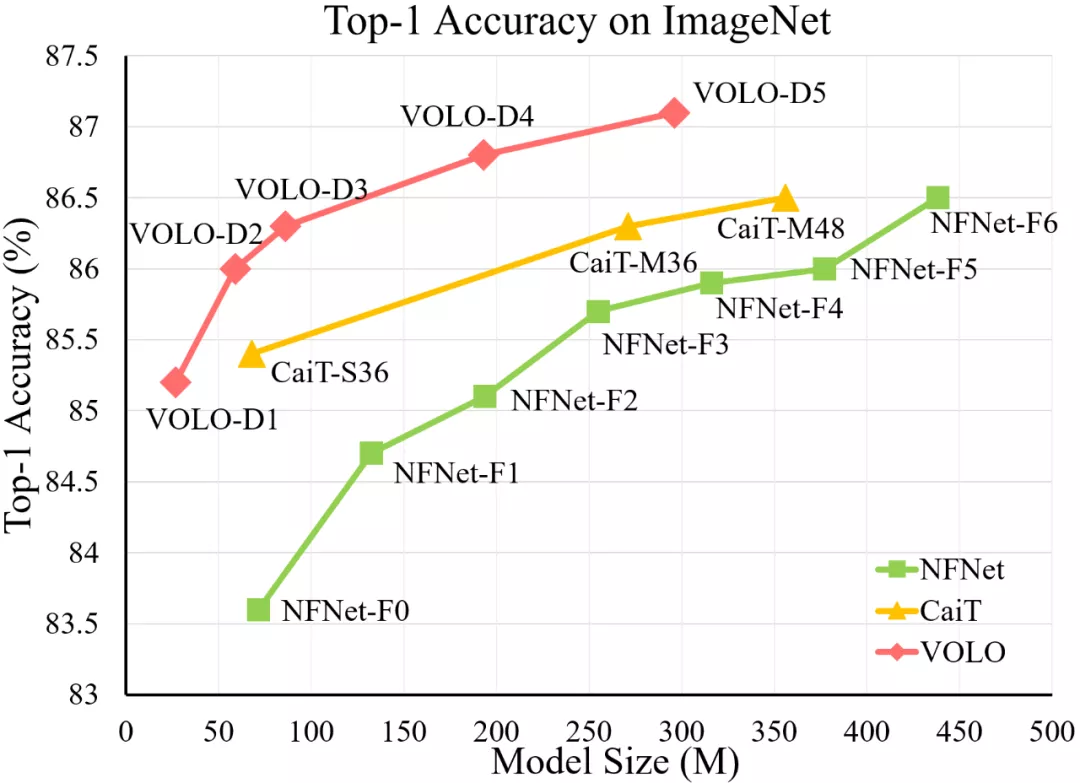
VOLO 模型與 SOTA CNN 模型(NFNet)和 Transformer 模型(CaiT)的 ImageNet top-1 準確率比較。在使用更少參數的情況下,VOLO-D5 優于 CaiT-M48 和 NFNet-F6,并首次在不使用額外訓練數據時達到了 87% 以上的 top-1 準確率。
顏水成教授認為,以 Transformer 為代表,「Graph Representation + Attentive Propagation」以其靈活性和普適性已展現出成為各領域統一框架的潛能,VOLO 算法表明了在視覺領域 Attention 機制也可以超越 CNN, 佐證了各領域走向模型統一的可行性。

- 論文地址:https://arxiv.org/pdf/2106.13112.pdf
- GitHub 地址:https://github.com/sail-sg/volo
方法概述
這項工作旨在縮小性能差距,并證明在無額外數據的情況下,基于注意力的模型優于 CNN。
具體來說,作者發現限制 self-attention 模型在圖像分類中的性能的主要因素是在將精細級特征編碼到 token 表征中的效率低下。
為了解決這個問題,作者提出了一種新穎的 outlook attention,并提出了一個簡單而通用的架構——Vision OutLOoker (VOLO)。
與專注于粗略全局依賴建模的 self-attention 不同,outlook attention 旨在將更精細的特征和上下文有效地編碼為 token,這些 token 對識別性能至關重要,但在很大程度上被自注意力所忽略。
Outlooker
VOLO 框架分為兩個階段,或者說由兩個大的 block 構成:
- 第一個階段由多層 outlooker 構成,旨在用于生成精細級別的數據表征;
- 第二個階段部署一系列 transformer 層來聚合全局信息。在每個階段的開始,使用 patch 嵌入模塊將輸入映射到相應大小的數據表示。
第一個 stage 由多層 outlooker 構成,outlooker 是本文提出的特殊的 attention 層,每一層 outlooker 由一層 outlook attention 層和 MLP 構成,如下所示為一層 outlooker 的實現方式。

其中,核心操作為 Outlook attention,如下圖所示:
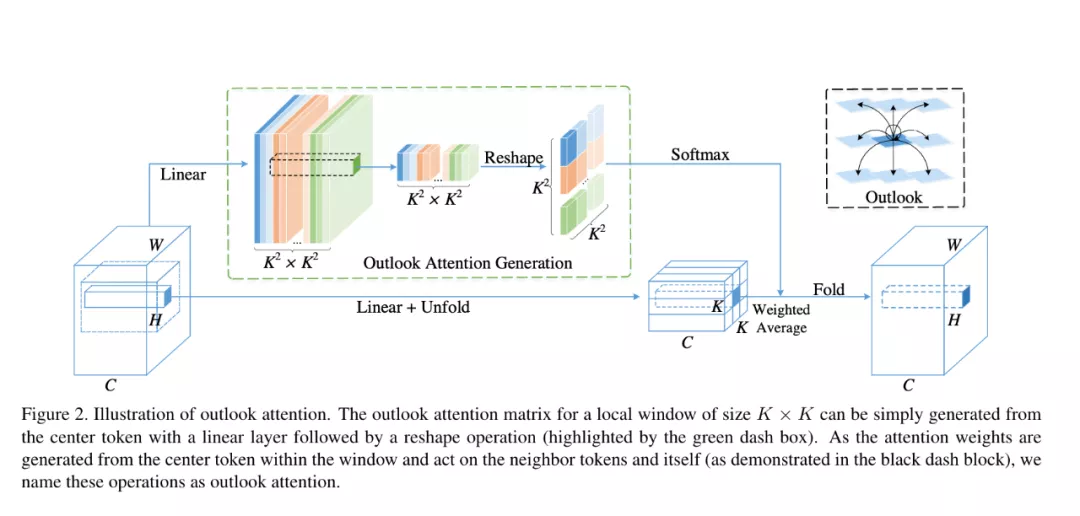
具體來說,outlook attention 的操作如下所示:

總體而言,outlook attention 具有如下優點:
- 較低的復雜度:相對于普通 self-attention 的時間復雜度是 O(H^2xW^2),而 outlook attention 只有 O(HW x k2 x k2)=O(HW x k4),而窗口大小 k 一般只有 3 或者 5,遠小于圖片尺寸 H 和 W。因此可用于具有更高分辨率的特征圖(例如,28x28 標記),這是提高 ViT 的有效方法;
- 更好建模局部細節:適用于下游視覺應用,如語義分割;
- Key and Query free: outlook attention 中無 Key 和 Query,attention map 可以直接由線性生成,去掉 MatMul(Query, Key),節省計算量;
- 靈活性:可以很容易地構成一個帶有 self-attention 的混合網絡。
作者也提供了 Outlook attention 實現的偽代碼,如下圖所示:

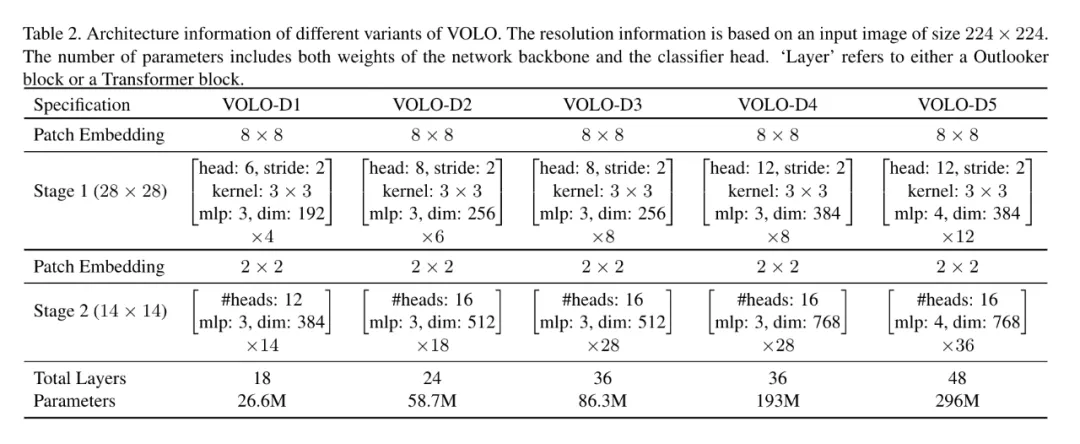
基于提出的 Outlooker 和傳統的 Transformer, 該工作提出了 VOLO 架構,同時包含五個大小變體,從小到大依次為 VOLO-D1 到 D5,架構示意如下圖所示:
實驗
研究者在 ImageNet 數據集上對 VOLO 進行了評估,在訓練階段沒有使用任何額外訓練數據,并將帶有 Token Labeling 的 LV-ViT-S 模型作為基線。他們在配有 8 塊英偉達 V100 或 A100 GPU 的單個節點機上訓練除 VOLO-D5 之外所有的 VOLO 模型,VOLO-D5 需要在雙節點機上訓練。
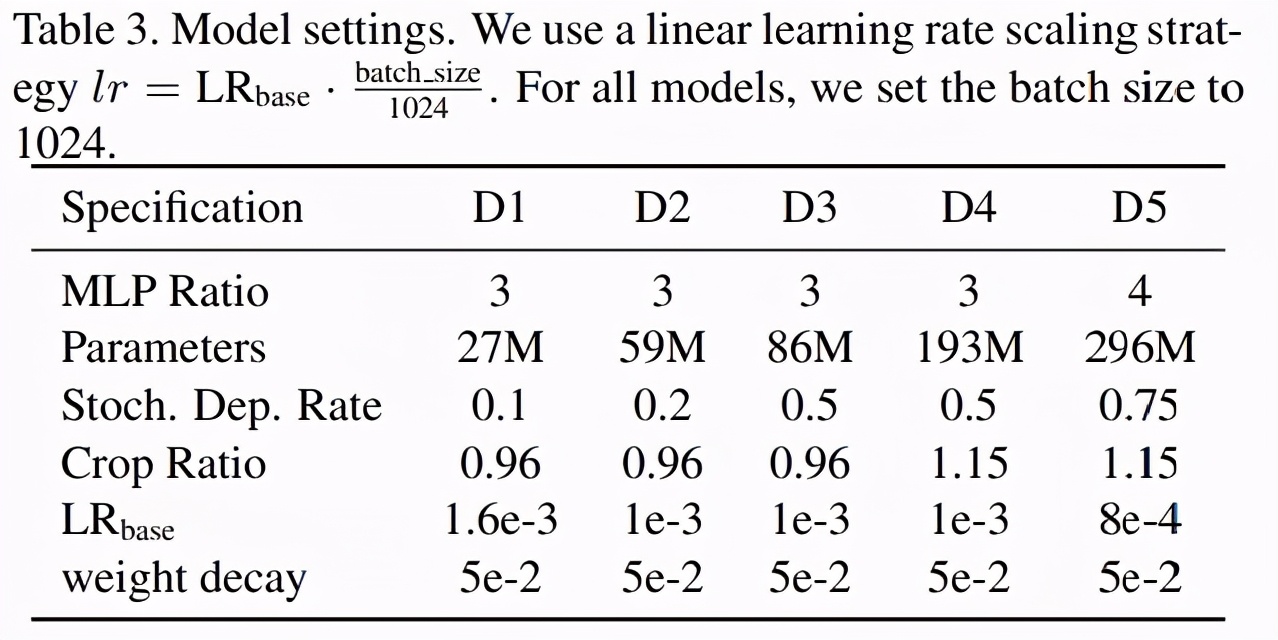
V0LO-D1 到 VOLO-D5 模型的設置如下表 3 所示:
主要結果
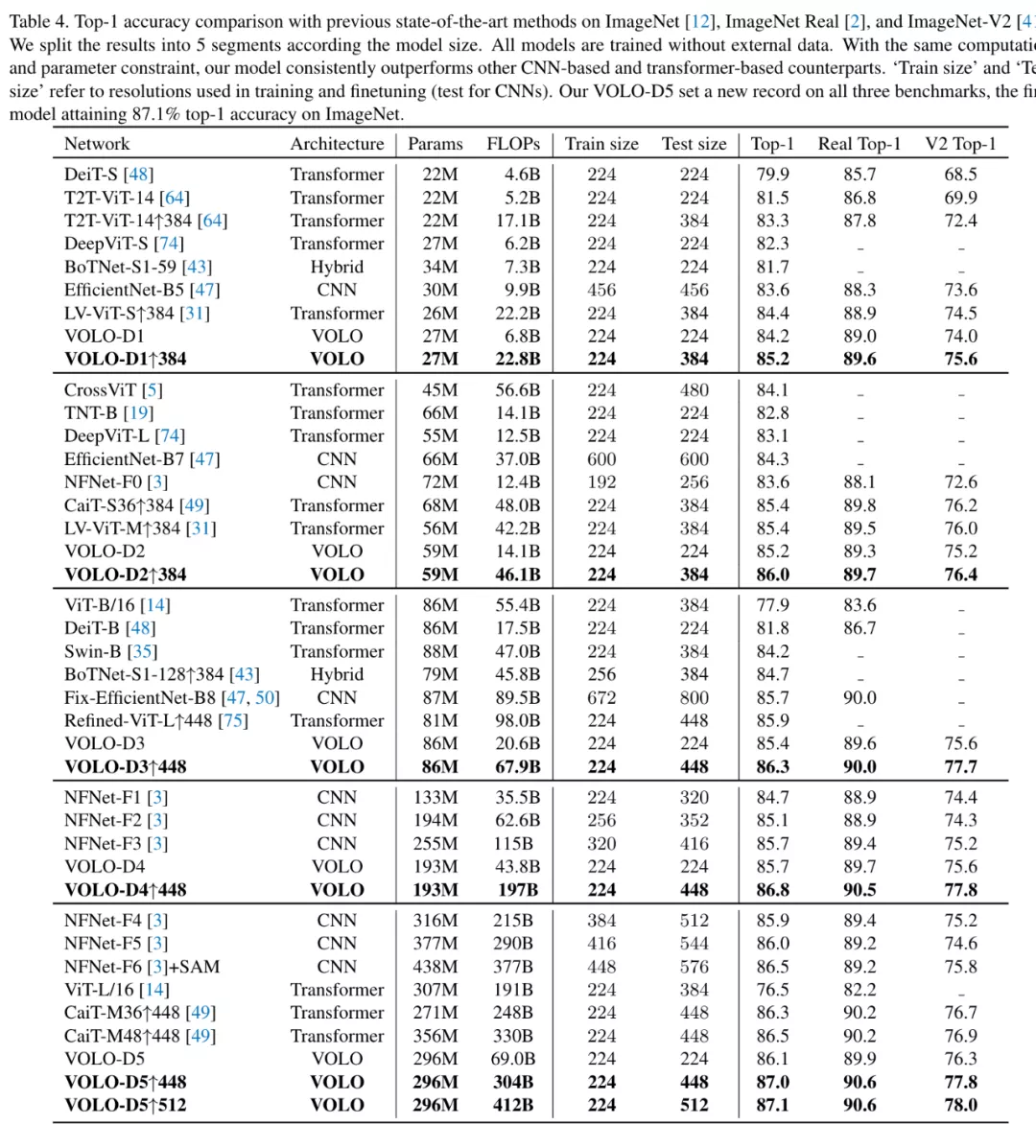
下表 4 中,研究者將 VOLO 模型與 SOTA 模型進行了比較,所有的結果都基于純(pure)ImageNet-1k 數據集,沒有使用額外訓練數據。結果表明,VOLO 模型優于 CNN、Transformer 等以往 SOTA 模型。
具體來說,該工作在圖像分類和分割中驗證了所提方法有效性,下圖為 VOLO 在 ImageNet 上的實驗結果,可以看出,僅憑 27M 參數,VOLO-D1 就可以實現 85.2% 的準確率,遠超以往所有模型。同時 VOLO-D5 實現了 87.1% 的準確率,這也是當前在無額外數據集下 ImageNet 最好結果,比以往 SOTA 模型 NFNet-F6 有 0.5% 以上的提升。
Outlooker 的性能
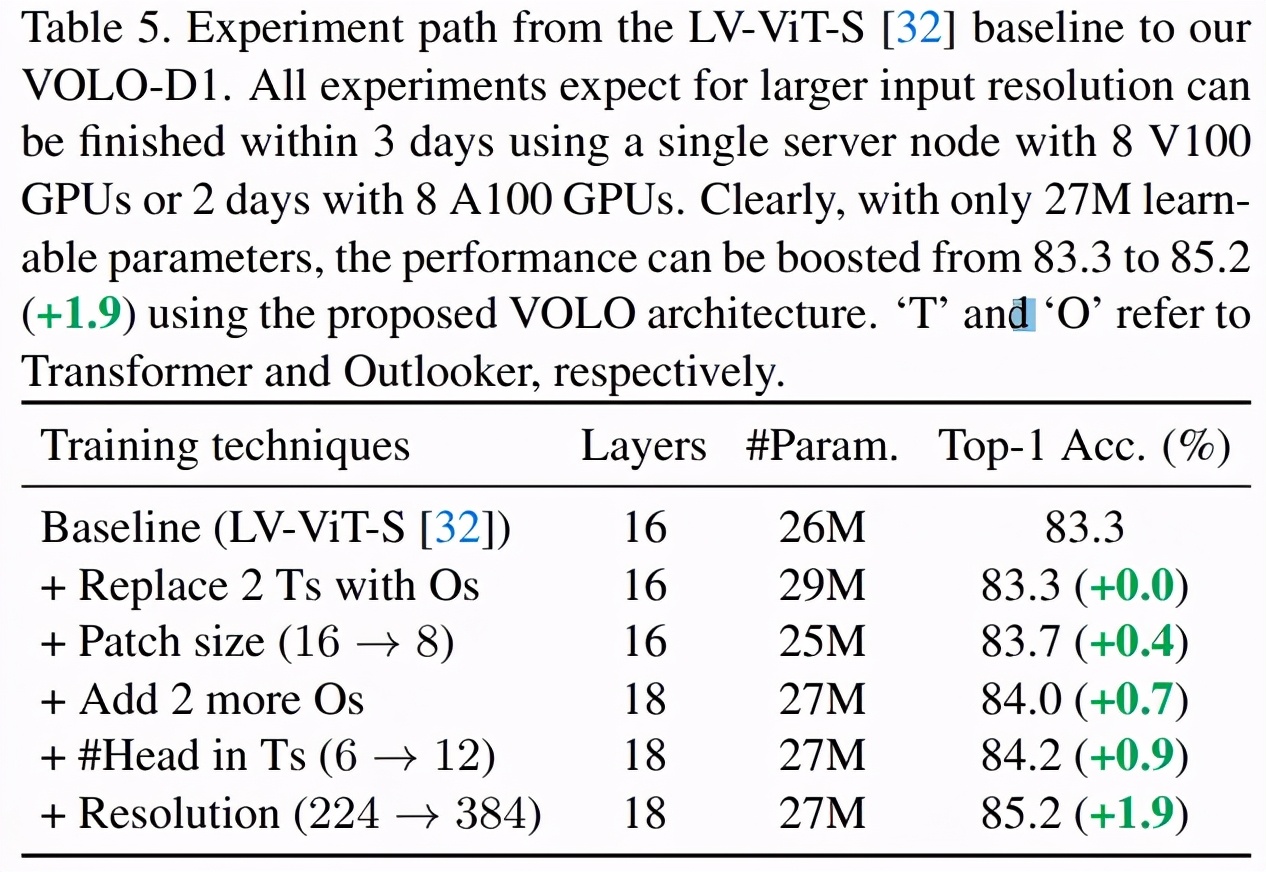
研究者展示了 Outlooker 在 VOLO 模型中的重要性,他們將最近的 SOTA 視覺 transformer 模型 LV-ViT-S 作為基線。LV-ViT-S 及 VOLO-D1 模型的實驗設置和相應結果如下表 5 所示:
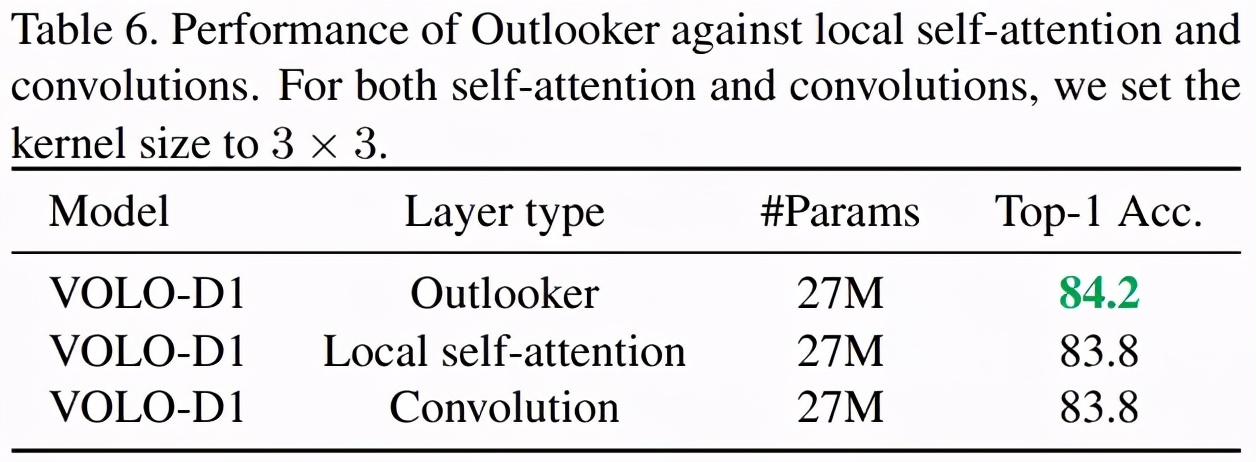
研究者還對 Outlooker 與局部自注意力(local self-attention)和空間卷積進行了比較,結果如下表 6 所示。結果表明,在訓練方法和架構相同的情況下,Outlooker 優于局部自注意力和空間卷積。
消融實驗
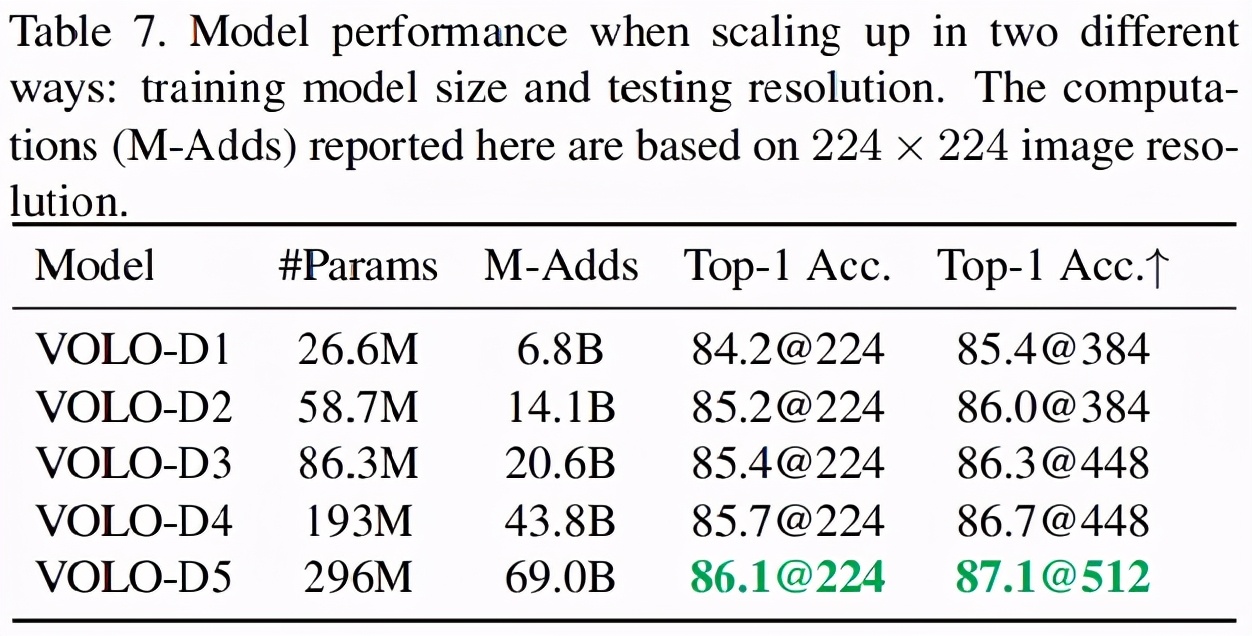
研究者將 VOLO-D1 模型擴展至 4 個不同的模型,即 VOLO-D2 到 VOLO-D5,具體的規格如上表 2 所示,相應的結果如下表 7 所示。結果表明,當增加訓練模型大小和測試分辨率時,VOLO 模型都可以實現性能提升。
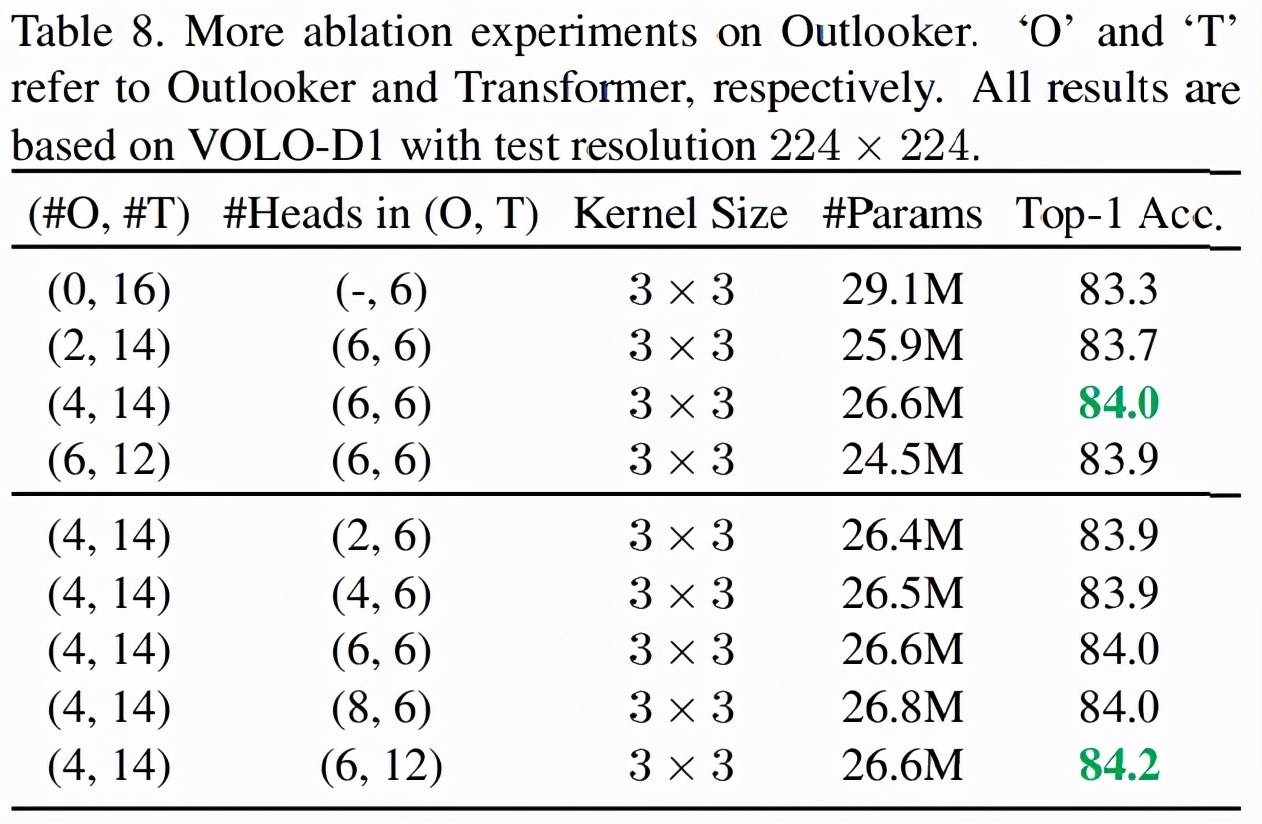
研究者還發現,VOLO 模型中 Outlooker 的數量對分類性能產生影響。下表 8 中,研究者在展示了不同數量的 Outlooker 在 VOLO 模型中的影響。
結果表明,在不使用 Outlooker 時,具有 16 個 transformer 的基線模型取得了 83.3% 的準確率。增加 Outlooker 的數量可以提升準確率,但使用 4 個 Outlooker 時即達到了性能飽和,之后增加再多的數量也無法帶來任何性能增益。
下游語義分割任務上的性能
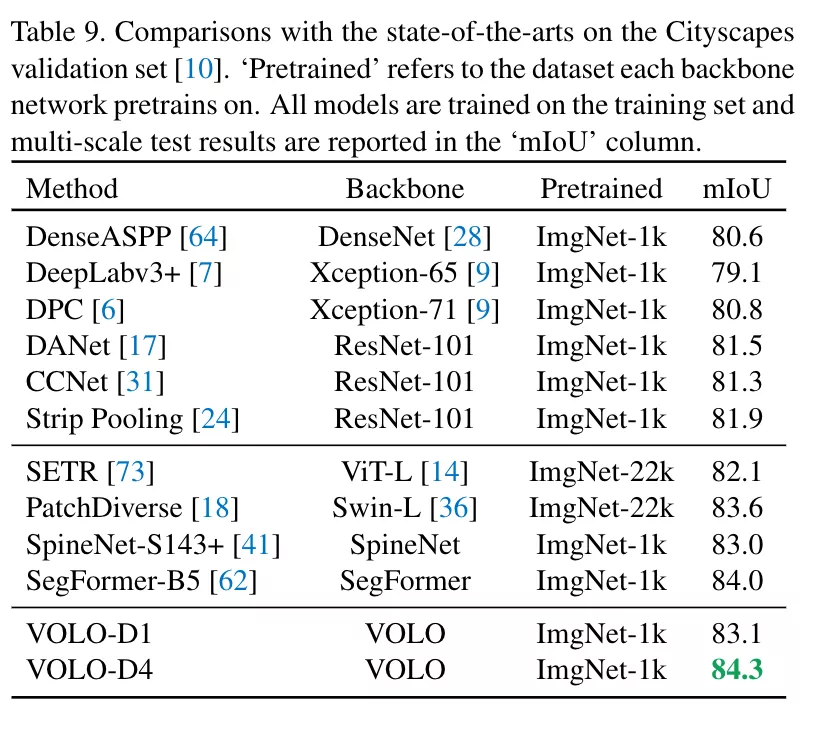
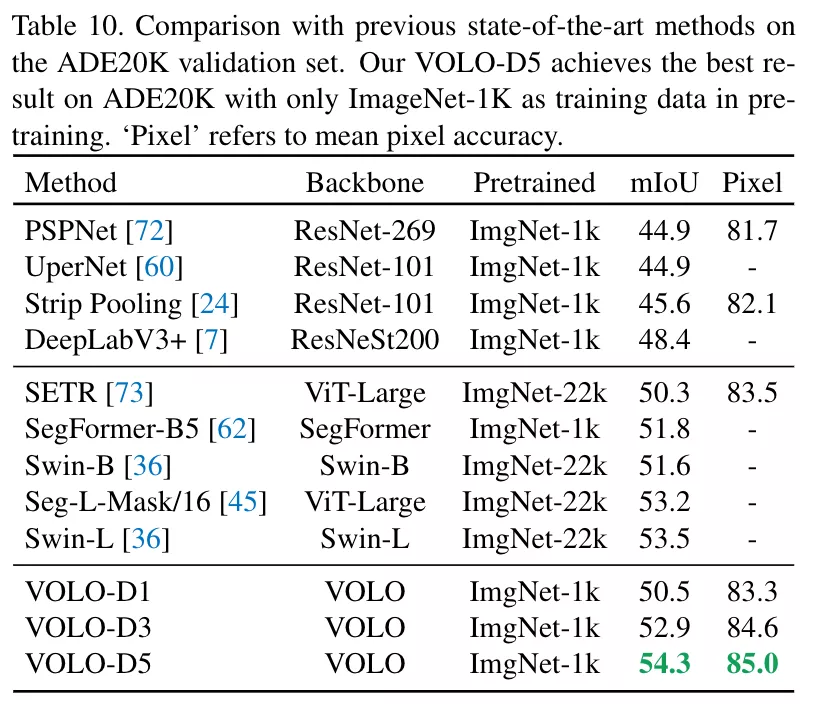
同時,該框架在下游任務上也取得了極大的提升,比如語義分割任務上,VOLO-d4 在 CityScapes 上實現 84.3 mIoU,在 ADE20k 上實現了 54.3 mIoU。
總體來說,實驗表明 VOLO 在 ImageNet-1K 分類上達到了 87.1% 的 top-1 準確率,在無額外數據集的情況下,首次在 ImageNet 上超過 87% 準確率的模型。
同時將該框架用于下游任務,比如語義分割 (Semantic Segmentation) 上,在 Cityscapes 和 ADE20k 上也實現了非常高的性能表現,VOLO-D5 模型在 Cityscapes 上實現 84.3% mIoU,目前位居 Cityscapes validation 首位。
工作總結
這個工作提出了一個全新的視覺模型,并取得了 SOTA 的效果。首次在無額外數據集下,讓 attention 主導的模型超越了 CNN 主導的模型精度。在證明了視覺 attention 的重要性的同時,為研究社區引入新的的模型框架和訓練策略。