













顏水成發(fā)了個“簡單到尷尬”的模型證明Transformer威力源自架構(gòu)
本文經(jīng)AI新媒體量子位(公眾號ID:QbitAI)授權(quán)轉(zhuǎn)載,轉(zhuǎn)載請聯(lián)系出處。
Transformer做視覺取得巨大成功,各大變體頻頻刷榜,其中誰是最強?
早期人們認為是其中的注意力機制貢獻最大,對注意力模塊做了很多改進。
后續(xù)研究又發(fā)現(xiàn)不用注意力換成Spatial MLP效果也很好,甚至使用傅立葉變換模塊也能保留97%的性能。
爭議之下,顏水成團隊的最新論文給出一個不同觀點:
其實這些具體模塊并不重要,Transformer的成功來自其整體架構(gòu)。

他們把Transformer中的注意力模塊替換成了簡單的空間池化算子,新模型命名為PoolFormer。
這里原文的說法很有意思,“簡單到讓人尷尬”……

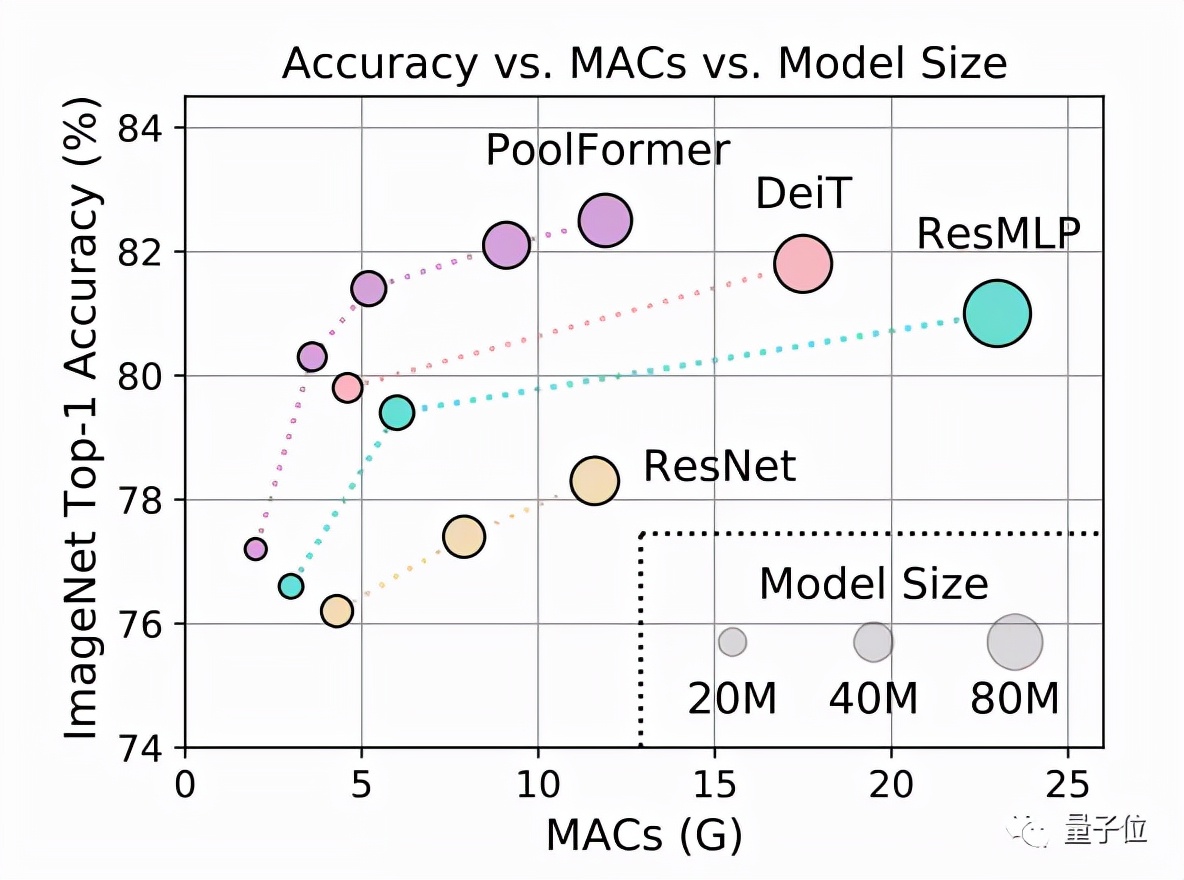
測試結(jié)果上,PoolFormer在ImageNet-1K上獲得了82.1%的top-1精度。
(PyTorch版代碼已隨論文一起發(fā)布在GitHub上,地址可在這篇推文末尾處獲取。)
同等參數(shù)規(guī)模下,簡單池化模型超過了一些經(jīng)過調(diào)優(yōu)的使用注意力(如DeiT)或MLP模塊(如ResMLP)的模型。
這個結(jié)果讓一些圍觀的CVer直接驚掉下巴:
太好奇了,模型簡單到什么樣才能令人尷尬?
PoolFormer
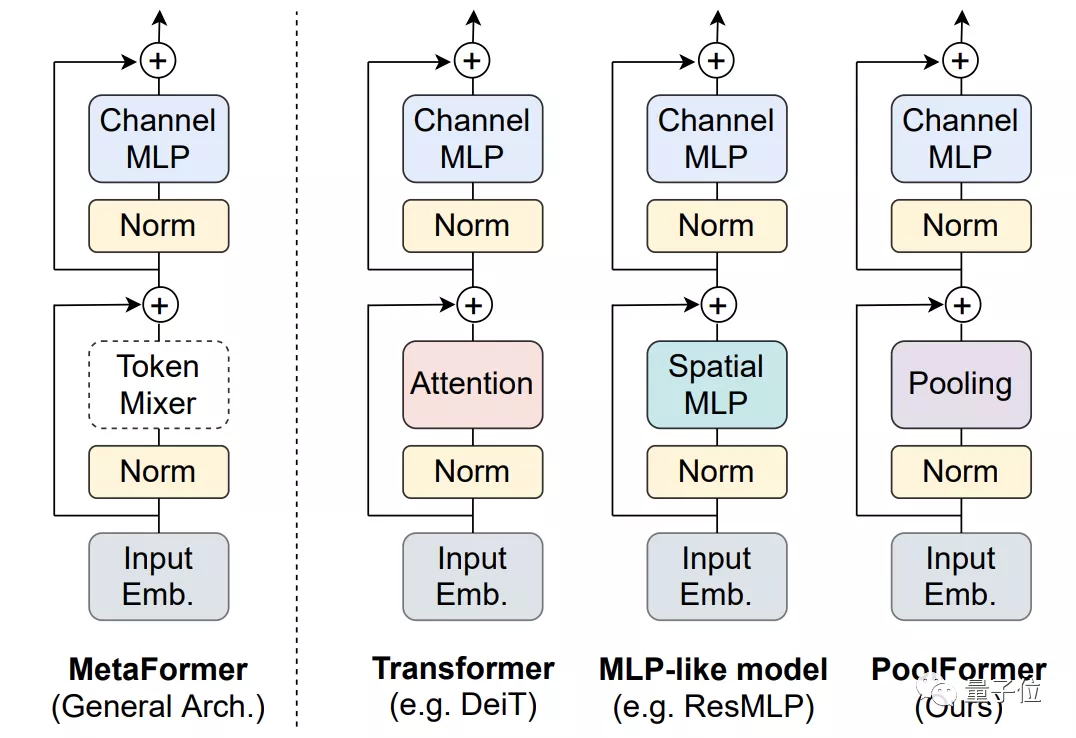
整體結(jié)構(gòu)與其他模型類似,PoolFormer只是把token mixer部分換了一下。
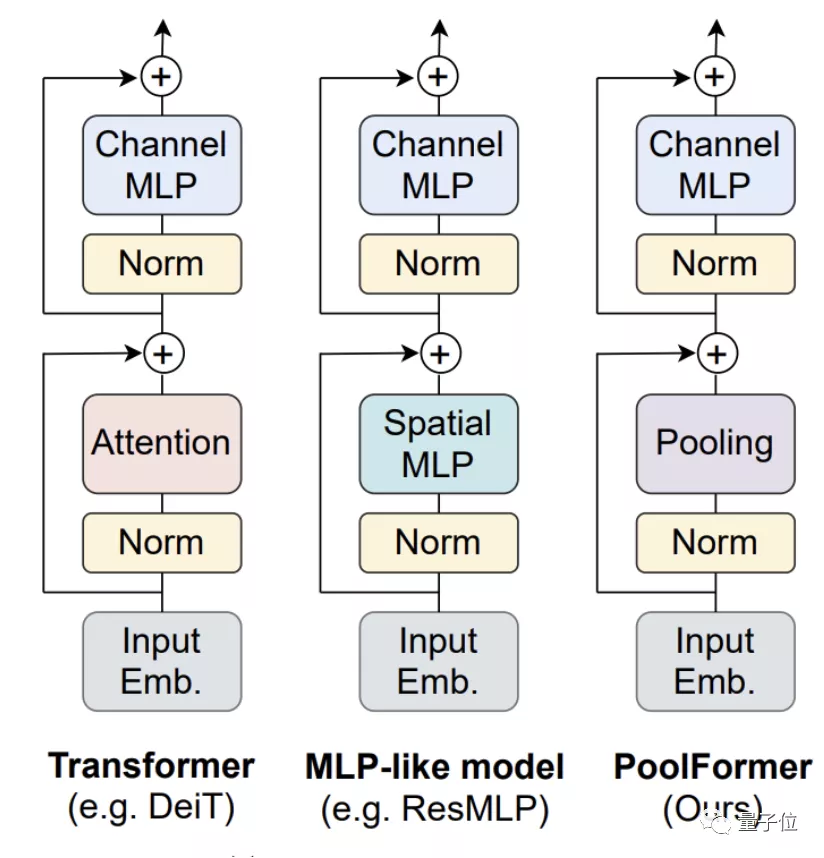
因為主要驗證視覺任務(wù),所以假設(shè)輸入數(shù)據(jù)的格式為通道優(yōu)先,池化算子描述如下:
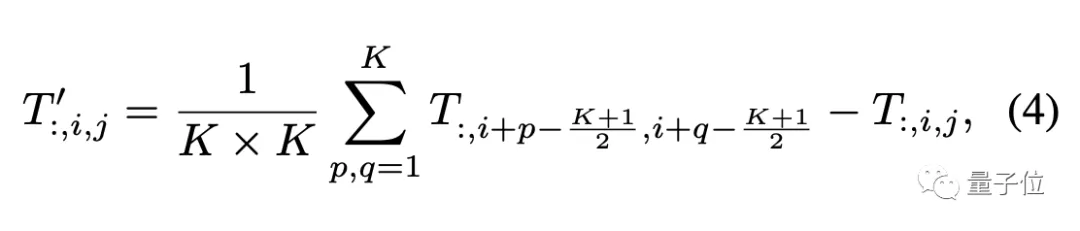
PyTorch風(fēng)格的偽代碼大概是這樣:

池化算子的復(fù)雜度比自注意力和Spatial MLP要小,與要處理的序列長度呈線性關(guān)系。
其中也沒有可學(xué)習(xí)的參數(shù),所以可以采用類似傳統(tǒng)CNN的分階段方法來充分發(fā)揮性能,這次的模型分了4個階段。
假設(shè)總共有L個PoolFormer塊,那么4個階段分配成L/6、L/6、L/2、L/6個。
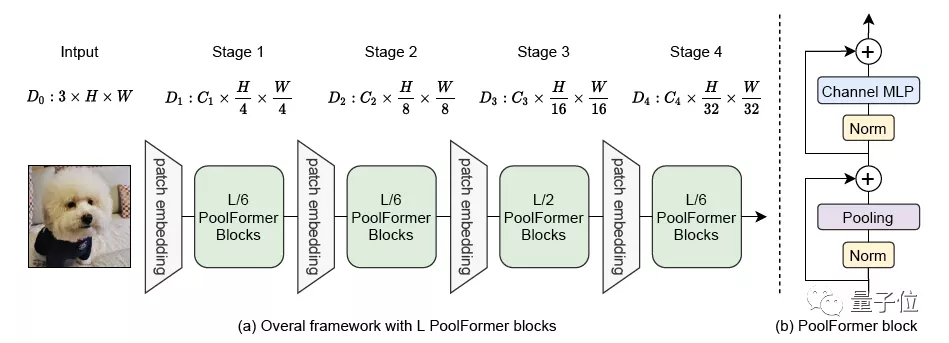
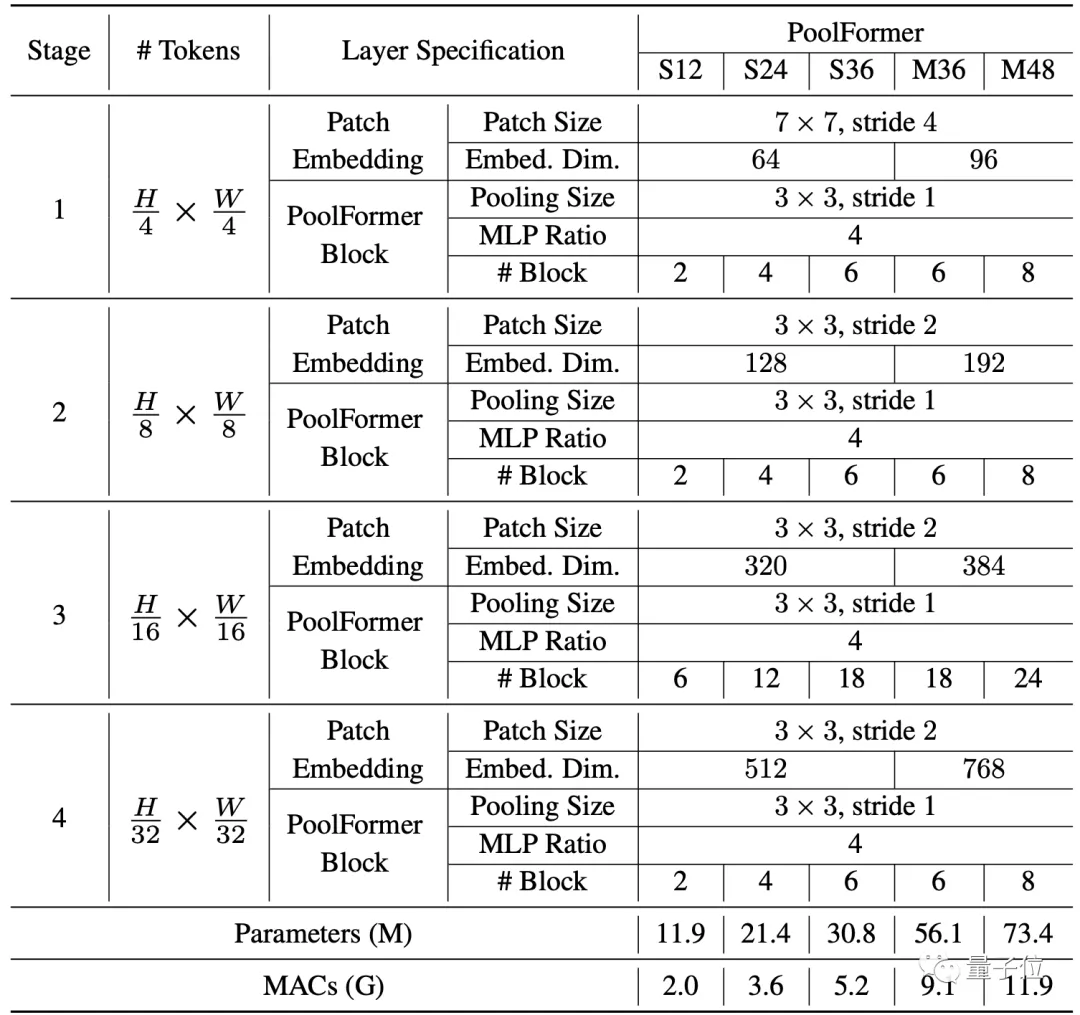
每個階段的具體參數(shù)如下:
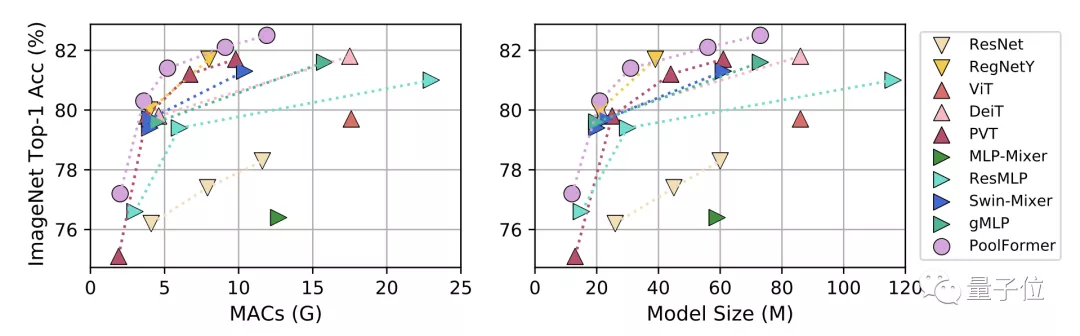
PoolFormer基本情況介紹完畢,下面開始與其他模型做性能對比。
首先是圖像分類任務(wù),對比模型分為三類:
- CNN模型ResNet和RegNetY
- 使用注意力模塊的ViT、DeiT和PVT
- 使用Spatial MLP的MLP-Mixer、ResMLP、Swin-Mixer和gMLP
在ImageNet-1K上,無論是按累計乘加操作數(shù)(MACs)還是按參數(shù)規(guī)模為標(biāo)準(zhǔn),PoolFormer性能都超過了同等規(guī)模的其他模型。
目標(biāo)檢測和實例分割任務(wù)上用了COCO數(shù)據(jù)集,兩項任務(wù)中PoolFormer都以更少的參數(shù)取得比ResNet更高的性能。
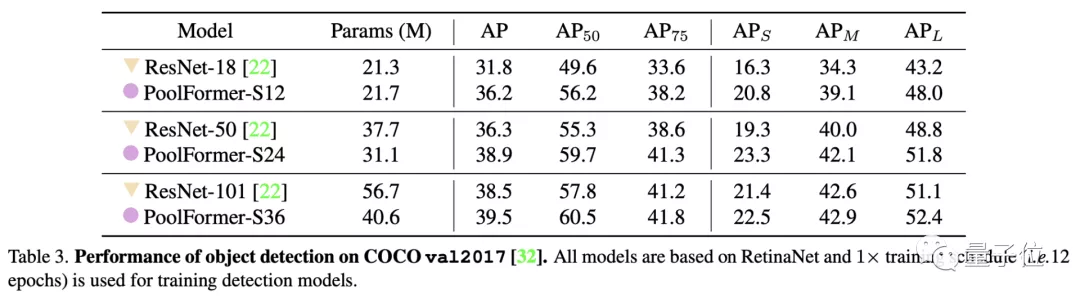
△目標(biāo)檢測
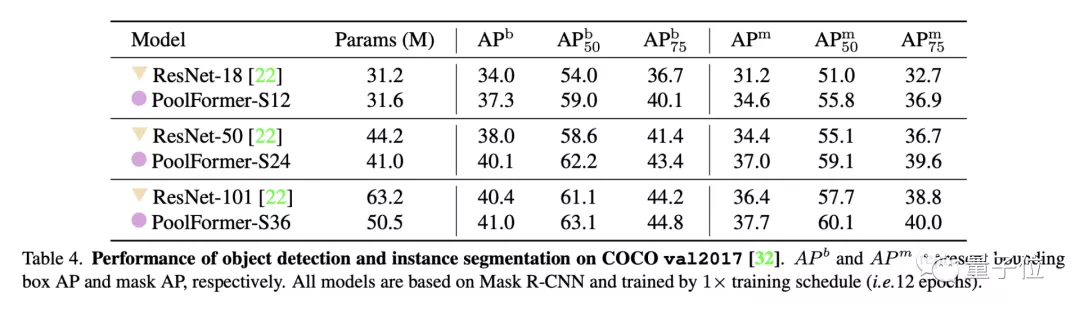
△實例分割
最后是ADE20K語義分割任務(wù),PoolFormer的表現(xiàn)也超過了ResNet、ResNeXt和PVT。
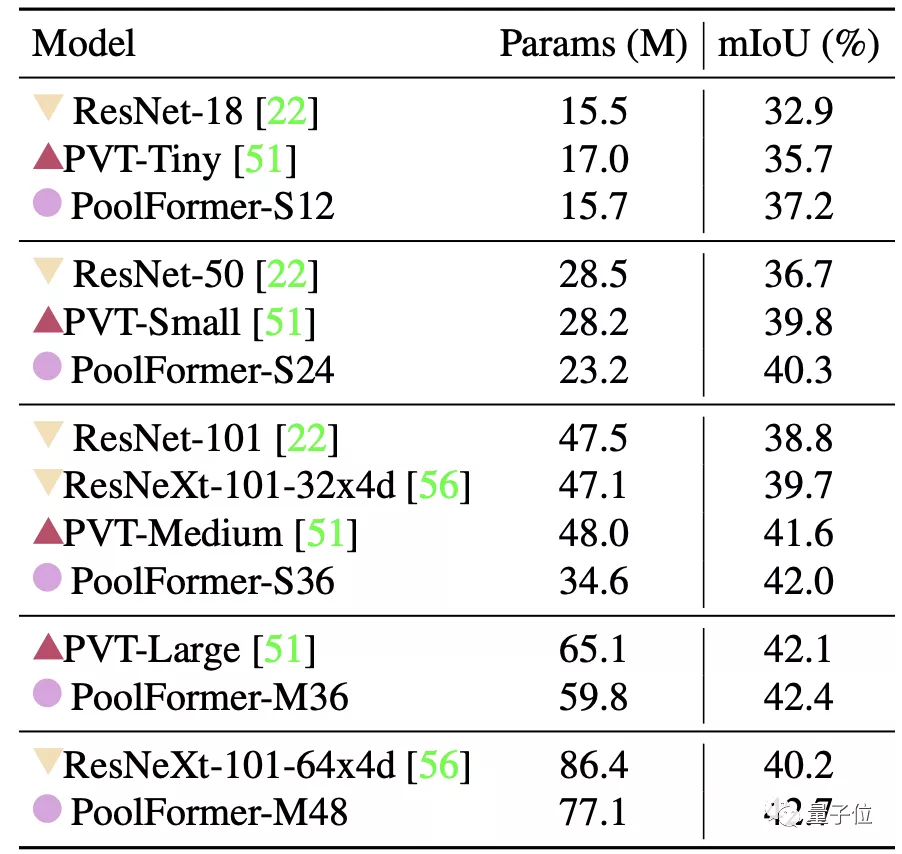
消融實驗
上面可以看出,幾大視覺任務(wù)上PoolFormer都取得了有競爭力的成績。
不過這還不足以支撐這篇論文開頭提出的那個觀點。
到底是整體架構(gòu)重要?還是說PoolFormer中的池化模塊剛好是一種簡單卻有效的Token Mixer?
團隊的驗證方法是把池化模塊直接替換成恒等映射(Identity Mapping)。
結(jié)果令人驚訝,替換后在ImageNet-1K上也保留了74.3%的Top-1精度。
在此基礎(chǔ)上無論是改變池化核尺寸、歸一化方法、激活函數(shù)影響都不大。
最重要的是,在4個階段中把注意力和空間全連接層等機制混合起來用性能影響也不大。
其中特別觀察到,前兩階段用池化后兩階段用注意力這種組合表現(xiàn)突出。
這樣的配置下稍微增加一下規(guī)模精度就可達到81%,作為對比的ResMLP-B24模型達到相同性能需要7倍的參數(shù)規(guī)模和8.5倍的累計乘加操作。
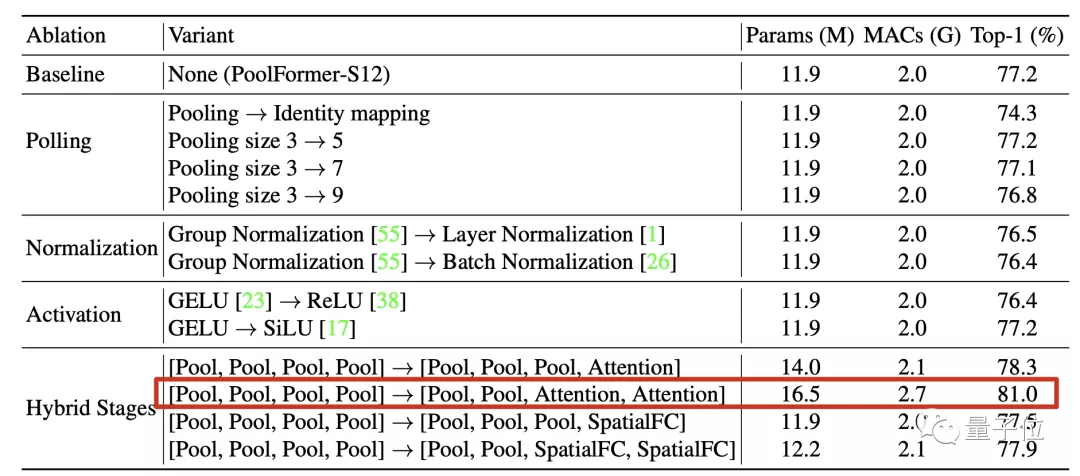
最終,消融實驗結(jié)果說明Transformer中具體到token mixer這個部分,具體用了哪種方法并不關(guān)鍵。
不增加模型規(guī)模的情況下,網(wǎng)絡(luò)的整體結(jié)構(gòu)才是對性能提升最重要的。
這樣的整體結(jié)構(gòu)被團隊提煉出來,命名為MetaFormer。
NLP上還會成立嗎?
這項研究由顏水成領(lǐng)導(dǎo)的Sea AI Lab和來自新加坡國立大學(xué)的成員共同完成。
△顏水成
論文的最后,團隊表示下一步研究方向是在更多場景下繼續(xù)驗證,如自監(jiān)督學(xué)習(xí)和遷移學(xué)習(xí)。
除了視覺任務(wù),也要看看在NLP任務(wù)上結(jié)論是否也成立。
另外發(fā)這篇論文還有一個目的:
呼吁大家把研究的重點放在優(yōu)化模型的基礎(chǔ)結(jié)構(gòu),而不是在具體模塊上花太多精力去打磨。

論文地址:
https://arxiv.org/abs/2111.11418
GitHub倉庫:
https://github.com/sail-sg/poolformer



























