自動化神器!Python 批量讀取身份證信息寫入 Excel
今天分享一個實用技能,利用 Python 批量讀取身份證信息寫入 Excel。
讀取
以圖片形式的身份證為例,信息讀取我們使用百度文字識別OCR來實現,百度接口提供了免費額度,日常使用基本差不多夠了,下面來具體看一下如何使用百度文字識別。
SDK 安裝
百度云 SDK 提供了 Python、Java 等多種語言的支持,Python 版的 SDK 安裝很簡單,使用pip install baidu-aip即可,支持 Python 2.7+ & 3.x 版本。
創建應用
創建應用需要一個百度或百度云賬號,注冊登錄地址為:https://login.bce.baidu.com/?redirect=http%3A%2F%2Fcloud.baidu.com%2Fcampaign%2Fcampus-2018%2Findex.html,登錄后將鼠標移到登錄頭像位置,在彈出菜單中點擊用戶中心,如圖所示:
首次進入需選一下相應信息,如圖所示:
選完之后點保存即可。
接著將鼠標移到左側>符號位置,再選人工智能,點擊文字識別,如圖所示:
點擊之后會進到如下所示圖中:
現在,我們就可以點擊創建應用了,之后進到如下所示圖中:
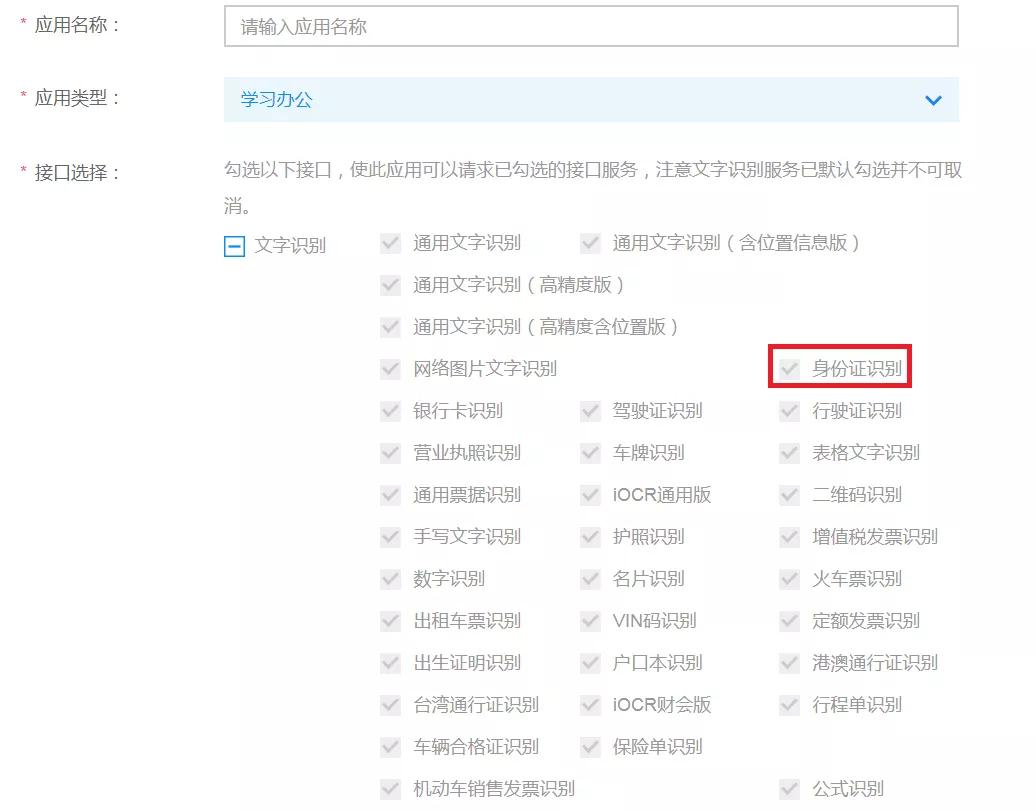
從上圖中我們可以看出百度文字識別OCR能夠識別的信息類別非常多,也就是說不只是身份證,如果你有其他信息識別的需求也是可以通過它來快速實現的。
這里我們填一下應用名稱和應用描述,填完之后點立即創建即可。
創建完成后返回應用列表,如下圖所示:
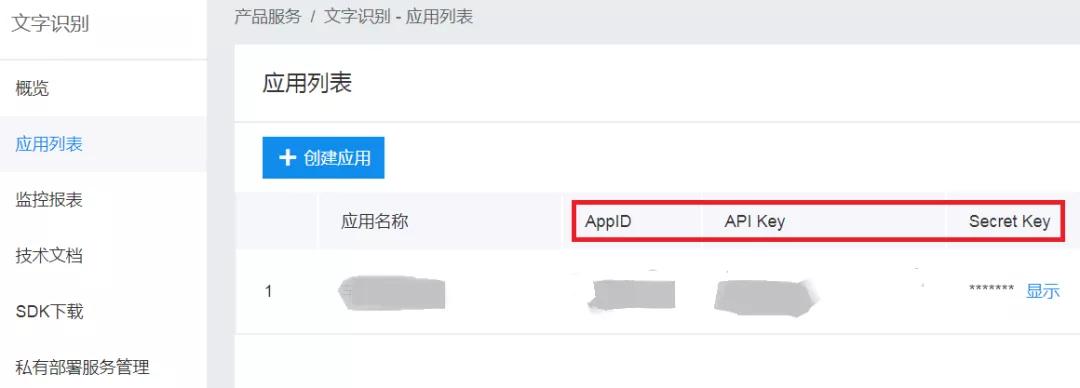
我們需要用到AppID&API Key&Secret Key這三個值,記錄一下。
代碼實現
代碼實現很簡單,幾行 Python 代碼即可搞定,如下所示:
- from aip import AipOcr
- APP_ID = '自己的APP_ID'
- API_KEY = '自己的API_KEY'
- SECRET_KEY = '自己的SECRET_KEY'
- # 創建客戶端對象
- client = AipOcr(APP_ID, API_KEY, SECRET_KEY)
- # 打開并讀取文件內容
- fp = open("idcard.jpg", "rb").read()
- # res = client.basicGeneral(fp) # 普通
- res = client.basicAccurate(fp) # 高精度
從上述代碼中可以看出識別功能分為普通和高精度兩種模式,為了識別率更高,我們這里采用高精度模式。
以如下三張我在網上找的假身份證為例:

因為有多張身份證圖片,我們需要寫一個方法來進行遍歷,代碼實現如下:
- def findAllFile(base):
- for root, ds, fs in os.walk(base):
- for f in fs:
- yield base + f
通過識別功能獲取到的身份證原始信息格式如下:
- {'words_result': [{'words': '姓名韋小寶'}, {'words': '性別男民族漢'}, {'words': '出生1654年12月20日'}, {'words': '住址北京市東城區景山前街4號'}, {'words': '紫禁城敬事房'}, {'words': '公民身份證號碼11204416541220243X'}], 'log_id': 1411522933129289151, 'words_result_num': 6}
寫入
證件信息的寫入使用 Pandas 來實現。這里我們還需要先將獲取的原始證件信息進行預處理以便寫入 Excel 中,我們將證件的姓名...住址分別存放在數組中,處理代碼實現如下:
- for tex in res["words_result"]:
- row = tex["words"]
- if "姓名" in row:
- names.append(row[2:])
- elif "性別" in row:
- genders.append(row[2:3])
- nations.append(row[5:])
- elif "出生" in row:
- births.append(row[2:])
- elif "住址" in row:
- addr += row[2:]
- elif "公民身份證號碼" in row:
- ids.append(row[7:])
- else:
- addr += row
之后就可以很方便的將信息直接寫入到 Excel 中了,寫入代碼實現如下:
- df = pd.DataFrame({"姓名": names, "性別": genders, "民族": nations,
- "出生": births, "住址": address, "身份證號碼": ids})
- df.to_excel('idcards.xlsx', index=False)
看一下寫入效果:

到此,我們就實現了身份證信息的批量讀寫功能。