Pravega Flink connector 的過去、現在和未來
摘要:本文整理自戴爾科技集團軟件工程師周煜敏在 Flink Forward Asia 2020 分享的議題《Pravega Flink Connector 的過去、現在和未來》,文章內容為:
- Pravega 以及 Pravega connector 簡介
- Pravega connector 的過去
- 回顧 Flink 1.11 高階特性心得分享
- 未來展望
一、Pravega 以及 Pravega connector 簡介

Pravega 項目的名字來源于梵語,意思是 good speed。項目起源于 2016 年,基于 Apache V2 協議在 Github 上開源,并且于 2020 年 11 月加入了 CNCF 的大家庭,成為了 CNCF 的 sandbox 項目。
Pravega 項目是為大規模數據流場景而設計的,彌補傳統消息隊列存儲短板的一個新的企業級存儲系統。它在保持對于流的無邊界、高性能的讀寫上,也增加了企業級的一些特性:例如彈性伸縮以及分層存儲,可以幫助企業用戶降低使用和維護的成本。同時我們也在存儲領域有著多年的技術沉淀,可以依托公司商用存儲產品為客戶提供持久化的存儲。
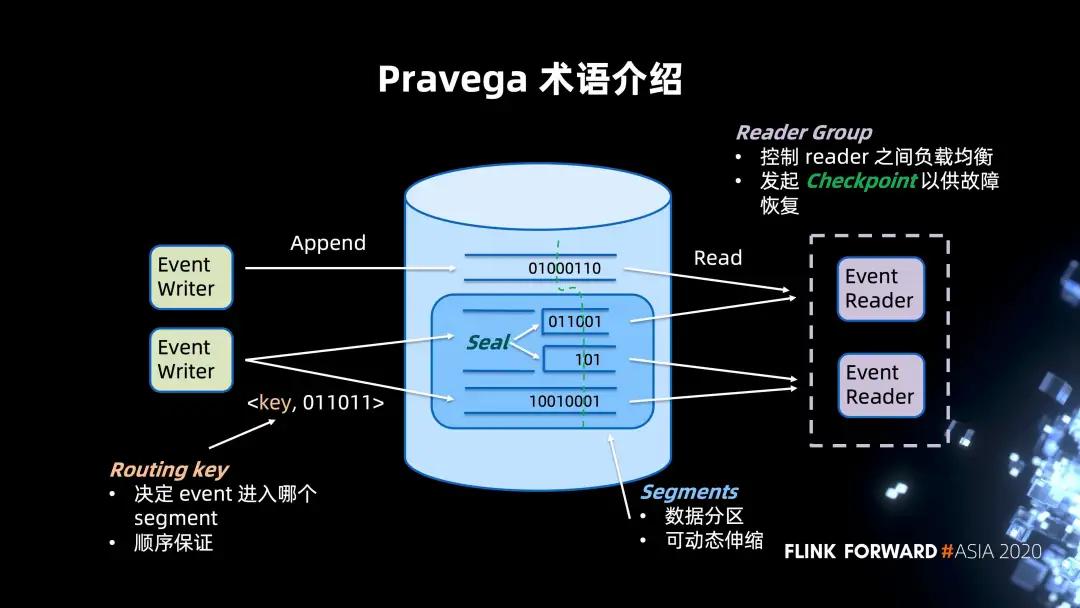
以上的架構圖描述的是 Pravega 典型的讀寫場景,借此進行 Pravega 術語介紹以幫助大家進一步了解系統架構。
- 中間部分是一個 Pravega 的集群 ,它整體是以 stream 抽象的系統。stream 可以認為是類比 Kafka 的 topic。同樣,Pravega 的 Segment 可以類比 Kafka 的 Partition,作為數據分區的概念,同時提供動態伸縮的功能。
Segment 存儲二進制數據數據流,并且根據數據流量的大小,發生 merge 或者 split 的操作,以釋放或者集中資源。此時 Segment 會進行 seal 操作禁止新數據寫入,然后由新建的 Segment 進行新數據的接收。
- 圖片左側是數據寫入的場景,支持 append only 的寫入。用戶可以對于每一個 event 指定 Routing key 來決定 Segment 的歸屬。這一點可以類比 Kafka Partitioner。單一的 Routing key 上的數據具有保序性,確保讀出的順序與寫入相同。
- 圖片右側是數據讀取的場景,多個 reader 會有一個 Reader Group 進行管控。Reader Group 控制著 reader 之間的負載均衡的,來保證所有的 Segment 能在 reader 之間均勻分布。同時也提供 Checkpoint 機制形成一致的 stream 切分來保證數據的故障恢復。對于 "讀",我們支持批和流兩種語義。對于流的場景,我們支持尾讀;對于批的場景,我們會更多的考慮高并發來達到高吞吐。
二、Pravega Flink connector 的過去
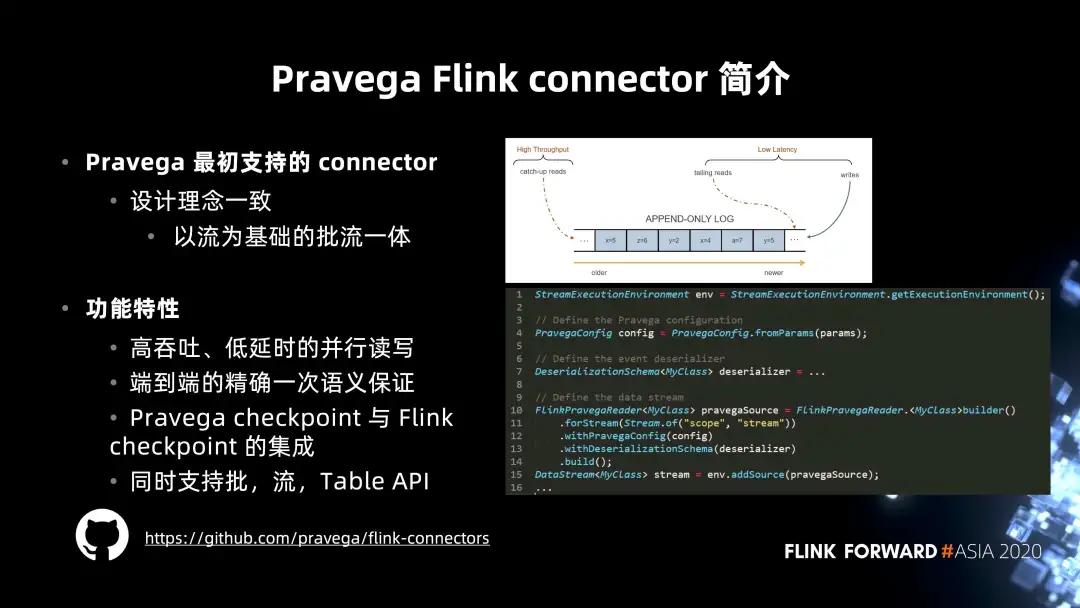
Pravega Flink connector 是 Pravega 最初支持的 connector,這也是因為 Pravega 與 Flink 的設計理念非常一致,都是以流為基礎的批流一體的系統,能夠組成存儲加計算的完整解決方案。
1. Pravega 發展歷程
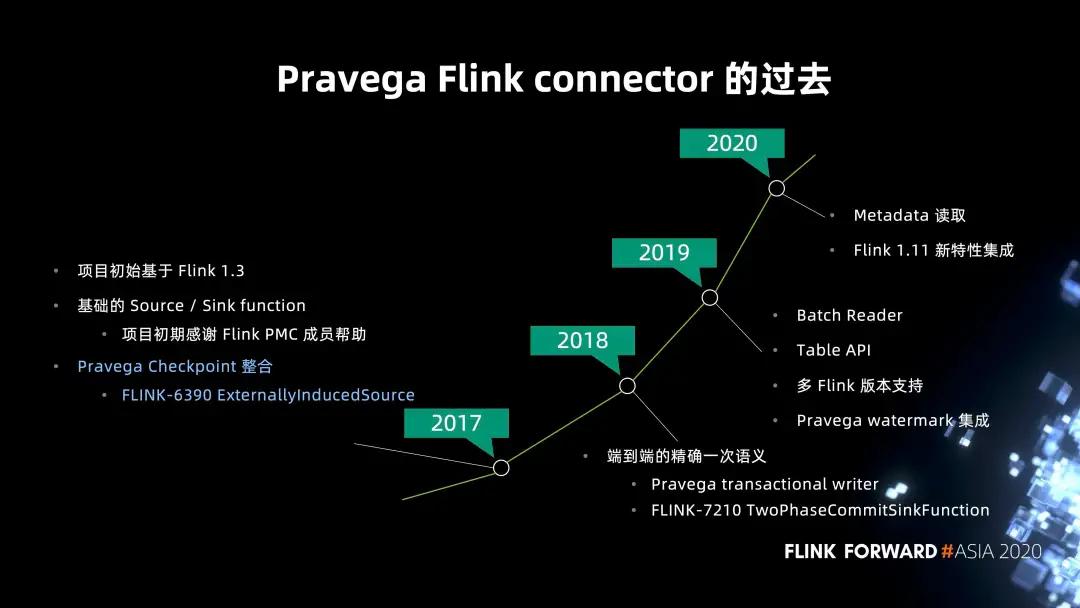
- connector 從 2017 年開始成為獨立的 Github 項目。2017 年,我們基于 Flink 1.3 版本進行開發,當時有包括 Stephan Ewen 在內的 Flink PMC 成員加入,合作構建了最基礎的 Source / Sink function,支持最基礎的讀寫,同時也包括 Pravega Checkpoint 的集成,這點會在后面進行介紹。
- 2018 年最重要的一個亮點功能就是端到端的精確一次性語義支持。當時團隊和 Flink 社區有非常多的討論,Pravega 首先支持了事務性寫客戶端的特性,社區在此基礎上合作,以 Sink function 為基礎,通過一套兩階段提交的語義實現了基于 checkpoint 的分布式事務功能。后來,Flink 也進一步抽象出了兩階段提交的 API,也就是為大家熟知的 TwoPhaseCommitSinkFunction 接口,并且也被 Kafka connector 采用。社區有博客來專門介紹這一接口,以及端到端的一次性語義。
- 2019 年更多的是 connector 對其它 API 的一些補完,包括對批的讀取以及 Table API 都有了支持。
- 2020 年的主要關注點是對 Flink 1.11 的集成,其中的重點是 FLIP-27 以及 FLIP-95 的新特性集成。
2. Checkpoint 集成實現
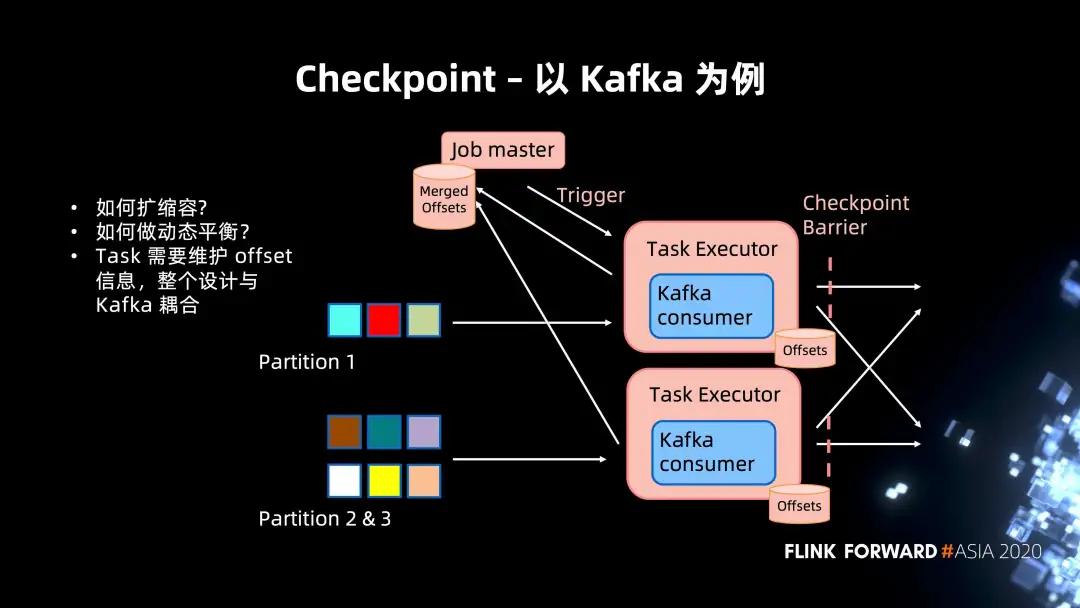
以 Kafka 為例,可以首先來看一下 Kafka 是如何做到 Flink Checkpoint 的集成的。
上圖所示是一個典型的 Kafka "讀" 的架構。基于 Chandy-Lamport 算法的 Flink checkpoint 實現,當 Job master Trigger 一個 Checkpoint 時,會往 Task Executor 發送 RPC 請求。其接收到之后會把自身狀態存儲中的 Kafka commit offset 合并回 Job Manager 形成一個 Checkpoint Metadata。
仔細思考后,其實可以發現其中的一些小問題:
- 擴縮容以及動態的平衡支持。當 Partition 進行調整的時候,或者說對 Pravega 而言,在 Partition 動態擴容和縮容的時候,如何進行 Merge 一致性的保證。
- 還有一點就是 Task 需要維護一個 offset 的信息,整個設計會與 Kafka 的內部抽象 offset 耦合。
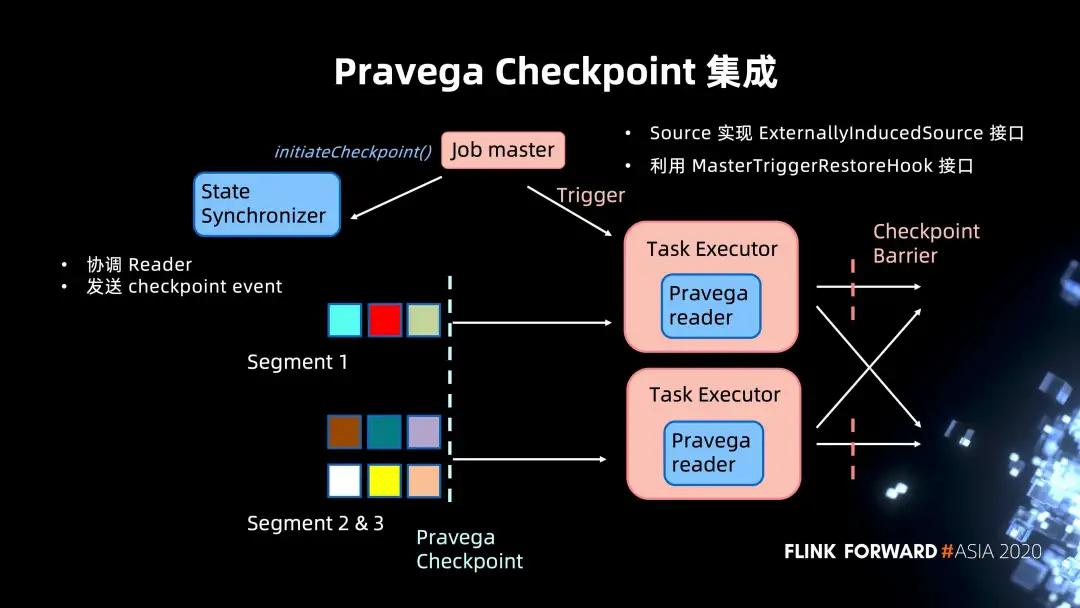
基于這些不足之處,Pravega 有自己內部設計的 Checkpoint 機制,我們來看一下它是怎么和 Flink 的 Checkpoint 進行集成的。
同樣讀取 Pravega Stream。開始 Checkpoint 這里就有不同,Job master 不再向 Task Executor 發送 RPC 請求,轉而以 ExternallyInducedSource 的接口,向 Pravega 發送一個 Checkpoint 的請求。
同時,Pravega 內部會利用 StateSynchronizer 組件來同步和協調所有的 reader,并且會在所有的 reader 之間,發送 Checkpoint 的 event。當 Task Executor 讀到 Checkpoint Event 之后,整個 Pravega 會標志著這個 Checkpoint 完成,然后返回的 Pravega Checkpoint 會存到 Job master state 當中,從而完成 Checkpoint。
這樣的實現其實對于 Flink 來說是更干凈的,因為它沒有耦合外部系統的實現細節,整個 Checkpoint 的工作是交給 Pravega 來實現并完成的。
三、回顧 Flink 1.11 高階特性心得分享
Flink1.11 是 2020 年的一個重要發布版本,對 connector 而言其實也有非常多的挑戰,主要集中在兩個 FLIP 的實現:FLIP-27 以及 FLIP-95。對于這兩個全新功能,團隊也花了很多時間去集成,在過程中也遇到了一些問題和挑戰。下面我們來向大家分享一下我們是如何踩坑和填坑的。本文會以 FLIP-95 為例展開。
1. FLIP-95 集成

FLIP-95 是新的 Table API,其動機和 FLIP-27 類似,也是為了實現批流一體的接口,同時也能更好地支持 CDC 的集成。針對冗長的配置鍵,也提出了相應的 FLIP-122 來簡化配置鍵的設定。
- 1.1 Pravega 舊的 Table API

從上圖可以看到 Pravega 在 Flink 1.10 之前的一個 Table API,并且從圖中建表的 DDL 可以看到:
- 以 update mode 和 append 去進行區分批和流,而且批流的數據這樣的區分并不直觀。
- 配置件也非常的冗長和復雜,讀取的 Stream 需要通過 connector.reader.stream-info.0 這樣非常長的配置鍵來配置。
- 在代碼層面,和 DataStream API 也有非常多的耦合難以維護。
針對這些問題,我們也就有了非常大的動力去實現這樣一套新的 API,讓用戶更好的去使用表的抽象。整個框架如圖所示,借由整個新框架的幫助,所有的配置項通過 ConfigOption 接口定義,并且都集中在 PravegaOptions 類管理。

- 1.2 Pravega 全新 Table API
下圖是最新 Table API 建表的實現,和之前的相比有非常大的簡化,同時在功能上也有了不少優化,例如企業級安全選項的配置,多 stream 以及起始 streamcut 的指定功能。

2. Flink-18641 解決過程心得分享

接下來,我想在此分享 Flink 1.11 集成的一個小的心得,是關于一個 issue 解決過程的分享。Flink-18641 是我們在集成 1.11.0 版本時碰到的問題。升級的過程中,在單元測試中會報 CheckpointException。接下來是我們完整的 debug 過程。
- 首先會自己去逐步斷點調試,通過查看 error 的報錯日志,分析相關的 Pravega 以及 Flink 的源碼,確定它是 Flink CheckpointCoordinator 相關的一些問題;
- 然后我們也查看了社區的一些提交記錄,發現 Flink 1.10 之后, CheckpointCoordinator 線程模型,由原來鎖控制的模型變成了 Mailbox 模型。這個模型導致了我們原來同步串型化執行的一些邏輯,錯誤的被并行化運行了,于是導致該錯誤;
- 進一步看了這一個改動的 pull request,也通過郵件和相關的一些 Committer 取得了聯系。最后在 dev 郵件列表上確認問題,并且開了這個 JIRA ticket。
我們也總結了以下一些注意事項給到在做開源社區的同胞們:
- 在郵件列表和 JIRA 中搜索是否有其他人已經提出了類似問題;
- 完整的描述問題,提供詳細的版本信息,報錯日志和重現步驟;
- 得到社區成員反饋之后,可以進一步會議溝通商討解決方案;
- 在非中文環境需要使用英語。
其實作為中國的開發人員,有除了像 mailing list 和 JIRA 之外。我們也有釘釘群以及視頻的方式可以聯系到非常多的 Committer。其實更多的就是一個交流的過程,做開源就是要和社區多交流,可以促進項目之間的共同成長。
四、未來展望
- 在未來比較大的工作就是 Pravega schema registry 集成。Pravega schema registry 提供了對 Pravega stream 的元數據的管理,包括數據 schema 以及序列化方式,并進行存儲。這個功能伴隨著 Pravega 0.8 版本發布了該項目的第一個開源版本。我們將在之后的 0.10 版本中基于這一項目實現 Pravega 的Catalog,使得 Flink table API 的使用更加簡單;
- 其次,我們也時刻關注 Flink 社區的新動向,對于社區的新版本、新功能也會積極集成,目前的計劃包括 FLIP-143 和 FLIP-129;
- 社區也在逐步完成基于 docker 容器的新的 Test Framework 的轉換,我們也在關注并進行集成。
最后也希望社區的小伙伴可以多多的關注 Pravega 項目,促進 Pravega connector 與 Flink 的共同發展。