一文詳解SRE之SLI/SLO設定
1.什么是SLI/SLO
SLI,全名Service Level Indicator,是服務等級指標的簡稱,它是衡定系統穩定性的指標。
SLO,全名Sevice Level Objective,是服務等級目標的簡稱,也就是我們設定的穩定性目標。
簡單一句話:SLI 就是我們要監控的指標,SLO 就是這個指標對應的目標。
如何選擇SLI
在系統中,常見的指標有很多種,比如:
- 系統層面:CPU使用率、內存使用率、磁盤使用率等
- 應用服務器層面:端口存活狀態、JVM的狀態等
- 應用運行層面:狀態碼、時延、QPS、TPS以及連接數等
- PASS層面:mysql、redis、kafka、mq和分布式文件儲存等組件的QPS、TPS、時延等。
這么多指標,應該如何選擇呢?只要遵從兩個原則就可以:
- 選擇能夠標識一個主體是否穩定的指標,如果不是這個主體本身的指標,或者不能標識主體穩定性的,就要排除在外。
- 優先選擇與用戶體驗強相關或用戶可以明顯感知的指標。
我們可以直接套用 Google 的方法:VALET。VALET 是 5 個單詞的首字母,分別是 Volume、Availability、Latency、Error 和 Ticket。這 5 個單詞就是我們選擇 SLI 指標的 5 個維度。
Volume 容量(流量)
就是常說的QPS,TPS等。下圖是性能測試的拐點模型。
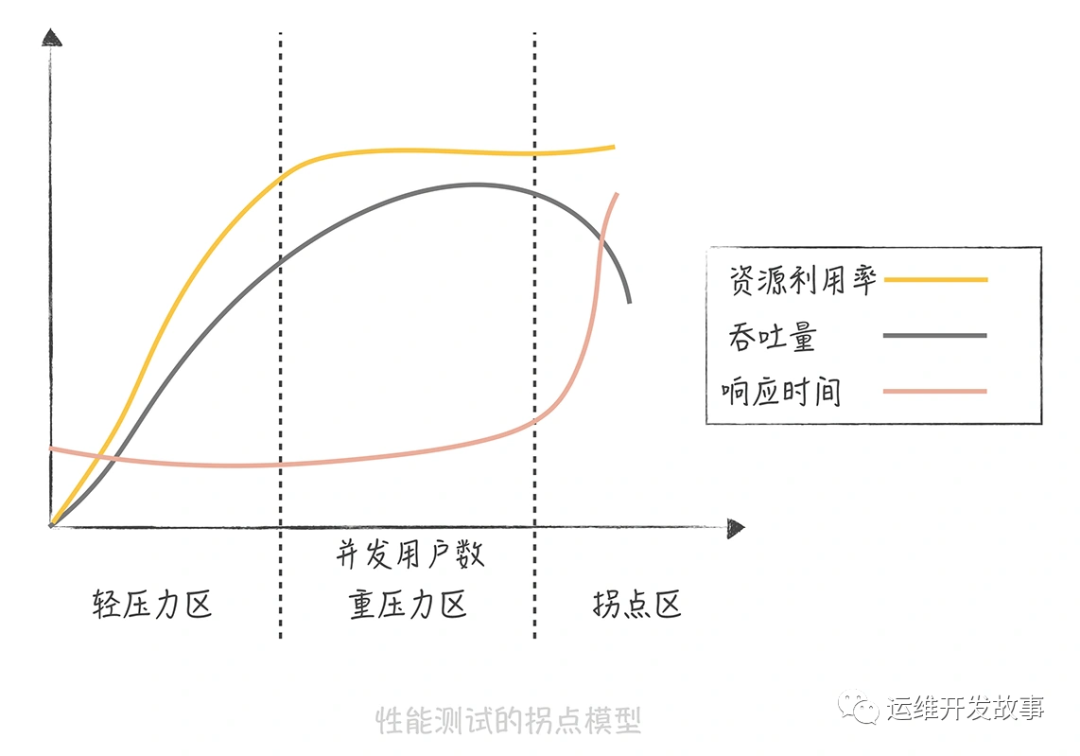
從圖中你可以發現,并發用戶數處于輕壓力區時,響應時間平穩,吞吐量和并發用戶數線性相關。而當并發用戶數處于重壓力區時,系統資源利用率到達極限,吞吐量開始有下降的趨勢,響應時間也會略有上升。這個時候,再對系統增加壓力,系統就進入拐點區,處于超負荷狀態,吞吐量下降,響應時間大幅度上升。 所以我們在評估系統性能時通常需要做壓力測試,目的就是找到系統的“拐點”,從而知道系統的承載能力,也便于找到系統的瓶頸,持續優化系統性能。
Availability 可用性
可用性是一個抽象的概念,你需要知道要如何來度量它,與之相關的概念是:MTBF 和 MTTR。
- MTBF(Mean Time Between Failure)是平均故障間隔的意思,代表兩次故障的間隔時間,也就是系統正常運轉的平均時間。這個時間越長,系統穩定性越高。
- MTTR(Mean Time To Repair)表示故障的平均恢復時間,也可以理解為平均故障時間。這個值越小,故障對于用戶的影響越小。
- 可用性與 MTBF 和 MTTR 的值息息相關,我們可以用下面的公式表示它們之間的關系:
- Availability = MTBF / (MTBF + MTTR)
Latency 延遲
是說響應是否足夠快,這是一個會直接影響用戶訪問體驗的指標。但是這個還對系統資源有影響。這里區分成功請求和失敗請求很重要。
- 復雜的高并發系統通常會有很多的系統模塊組成,同時也會依賴很多的組件和服務,比如說緩存組件,隊列服務等等。它們之間的調用最怕的就是延遲而非失敗,因為HTTP 500錯誤通常是瞬時的,可以通過重試的方式解決。
- 調用某一個模塊或者服務發生比較大的延遲,調用方就會阻塞在這次調用上,它已經占用的資源得不到釋放。當存在大量這種阻塞請求時,調用方就會因為用盡資源而掛掉。如果把HTTP 500回復的延遲也計算在內,可能會產生誤導性的結果。因此,監控錯誤恢復的延遲是很重要的。
Error 錯誤
錯誤率有多少?這里除了 5xx 之外,我們還可以把 4xx 列進來,因為前面我們的服務可用性不錯,但是從業務和體驗角度,4xx 太多,用戶也是不能接受的。有時候還有隱式的失敗。比如http 200恢復中包含了錯誤內容,或者策略導致的失敗。比如我們要求超過一秒的請求就返回失敗,這樣超過一秒的請求都是失敗請求。當協議內部的錯誤碼不能表達全部的失敗情況時,可以利用其它信息,如內部協議,來跟蹤一部分特定故障情況。
Ticket 故障單
是否需要人工介入?如果一項工作或任務需要人工介入,那說明一定是低效或有問題的。舉一個我們常見的場景,數據任務跑失敗了,但是無法自動恢復,這時就要人工介入恢復;或者超時了,也需要人工介入,來中斷任務、重啟拉起來跑等等。
Tickets 的 SLO 可以想象成它的中文含義:門票。一個周期內,門票數量是固定的,比如每月 20 張,每次人工介入,就消耗一張,如果消耗完了,還需要人工介入,那就是不達標了。好,VALET 我們就講完了,怎么選 SLI 指標,你是不是一下子就清楚了。可以說,這是一個我們可以直接復用的工具。
SLO 方式計算
我們可以將多個SLO的百分數相乘,得到最后的SLO值。
- SLO1:99.95% 狀態碼成功率
- SLO2:90% Latency <= 80ms
- SLO3:99% Latency <= 200ms
- 直接用公式表示:
- Availability = SLO1 & SLO2 & SLO3
2.案例:
本案例源自《SRE工作手冊》英文版第三章,講述的是家得寶(THD)公司在SRE轉型中如何使用VALET來定義SLO:家得寶又創建一個 VALET 應用程序,以存儲和報告 SLO 數據。由于 SLO 可以最好地用作趨勢工具,因此該服務每天、每周和每月對 SLO 進行跟蹤。請注意,我 SLO 是一種趨勢分析工具,可用于錯誤預算,但未直接連接到監控系統。相反,家得寶仍舊有各種不同的監控平臺,每個監控平臺都有自己的報警。這些監控系統每天匯總其 SLO ,并發布到 VALET 服務以進行趨勢分析。這種設置的缺點是,監控系統中設置的警報閾值未與 SLO 集成在一起。但是,可以根據需要靈活地更改監控系統。TPS 報告是第一個與 VALET 服務集成的系統,到目前為止,家得寶的 VALET 與其各種本地應用程序平臺(在 VALET 中注冊的服務的一半以上)集成。
VALET 儀表板
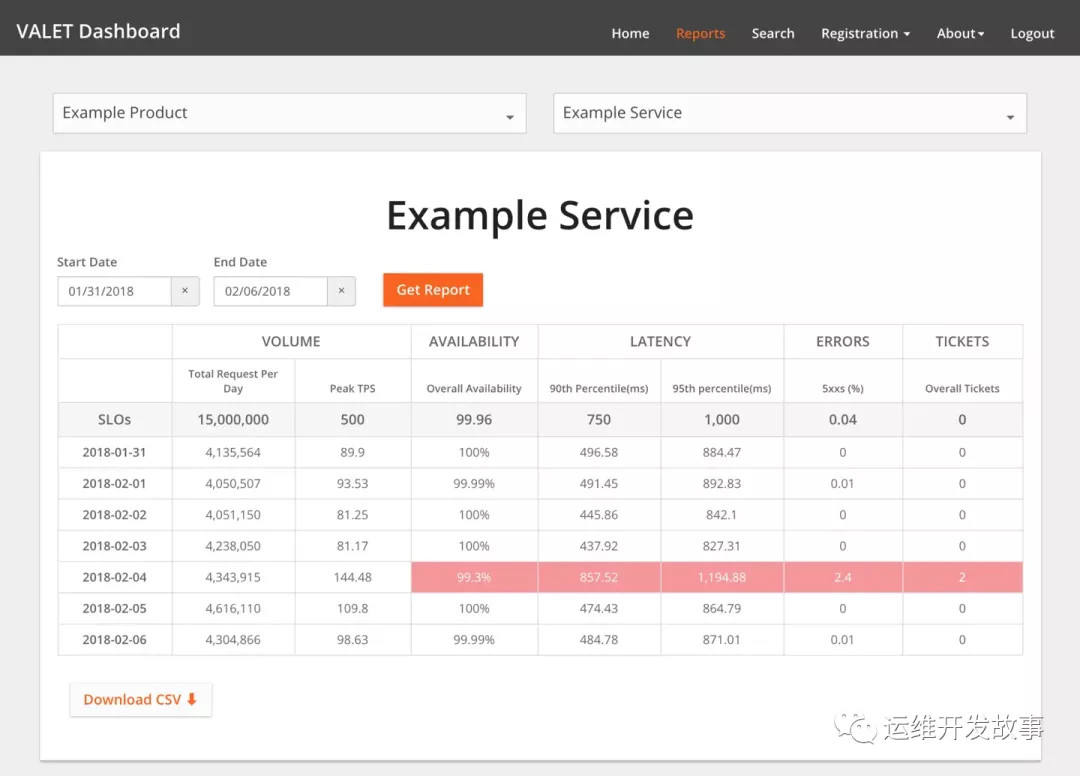
VALET 儀表板如上圖所示,用于可視化和報告此數據,并且相對簡單。它允許用戶:
- 注冊新服務。這通常意味著將服務分配給一個或多個URL,這些URL可能已經收集了VALET數據。
- 為五個 VALET 類別中的任何一個設定 SLO 目標。
- 在每個 VALET 類別下添加新的指標類型。例如,一項服務可以跟蹤 P99 的延遲,而另一項服務可以跟蹤 P90 (或兩者)的延遲。后端處理系統可以跟蹤每天的交易量(一天創建的購買訂單),而客戶服務前端可以跟蹤每秒的高峰交易。
VALET 儀表板使用戶可以立即報告許多服務的 SLO ,并以多種方式對數據進行切片和切塊。例如,一個團隊可以查看過去一周不滿足 SLO 的所有服務的統計信息。尋求查看服務性能的團隊可以查看所有服務及其所依賴服務的延遲。VALET 儀表板將數據存儲在簡單的Cloud SQL數據庫中,開發人員使用流行的 BI 工具來構建報告。這些報告成為開發人員采取新的最佳實踐的基礎:定期對其服務進行 SLO 審核(通常是每周或每月)。基于這些審查,開發人員可以創建操作項以將服務返回到其 SLO ,或者可以決定需要調整不切實際的 SLO。
將VALET應用于批處理應用
當圍繞 SLO 開發可靠的報告時,家得寶還發現,只要對 VALET 稍作調整,就可以用在批處理應用程序上,如下所示:
- 容量:處理的記錄量
- 可用性:在一定時間內完成工作的頻率(以百分比為單位)
- 延遲:作業運行所需的時間
- 錯誤:無法處理的記錄
- 故障單:操作員必須手動修復數據并重新處理作業的次數
3.總結:
根據上面的 SLI 和 SLO 設定標準示例,內容很直觀,需要你認真研上面的內容。請你嘗試按照上面的格式,制定一個自己所負責系統的 SLO。
本文轉載自微信公眾號「運維開發故事」,可以通過以下二維碼關注。轉載本文請聯系運維開發故事公眾號。