云集技術學社 | 主流大數據架構及適用場景
7月22日,深信服大數據負責人Letian在信服云《云集技術學社》系列直播課上進行了《主流大數據架構及適用場景》的分享,對典型大數據的分析場景進行了總結,歸納了大數據新架構及適用應用場景,從大數據開發的視角來分析大數據開發過程以及如何簡化開發。以下是他分享內容摘要,想要了解更多可以點擊http://sangfor.bizconf.cn/live/watch/technology/?id=m471p65m&time=1628846273488觀看直播回放。
看點一:大數據分析典型應用場景
對于大部分用戶來說,對大數據只有一個模糊的概念,不了解特別具象化的應用場景。數據分析是大數據的核心場景,依據對于分析效率和方式的不同,基本上可以分為批處理、交互式分析、實時分析、分析預測、智能決策等場景。
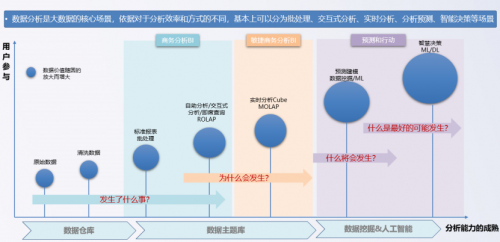
大數據分析的主要應用場景有五個
一是離線分析場景,應用于用戶需要貼合業務形成的報表中,常見的是對靜態數據的批處理。離線分析場景往往需要對于海量數據處理幾個小時甚至幾天才能得到貼合業務需求的結果報表。
二是交互式分析場景,應用于儀表盤或自助分析。它的特點是表與表之間的關聯關系不確定,分析維度不確定,查詢度量不確定,通過即席查詢滿足秒級~分鐘級的分析需求。
三是實時分析場景,通常應用在交易風險預警、實時反欺詐、交易特征分析中,它的特點是表與表之間的關聯關系確定,分析維度不確定,查詢度量不確定,通過數據立方(Cube)技術提前預設數據模型,滿足從既定的多層次多維度的亞秒~秒級的分析需求。
四是流處理場景,流處理是指對如傳感器信號、日志、時空軌跡、網購、交易等連續的、沒有邊界的、快速隨時間不斷變化的數據項(又稱“流式數據“)進行過濾、轉化、復雜邏輯等操作,主要應用在公安緝查布控、套牌車分析、互聯網實時推薦系統中。
五是綜合檢索,即從海量的結構化、半/非結構化數據中快速抓取到符合要求的信息。通常應用在站內搜索引擎、知識庫以及高并發精準查詢等通過關鍵字檢索快速獲得信息的使用場景中。
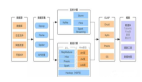
看點二:大數據新架構及適用場景
信息技術的發展催生了大數據新架構的不斷升級迭代與創新,在本次課程中,Letian介紹了不同類型的大數據新架構及適用場景。
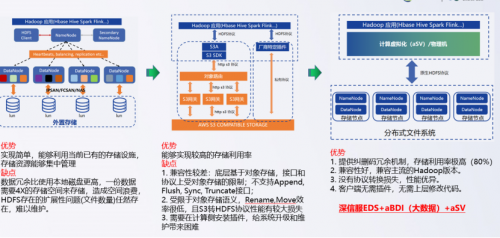
(1)存算分離
基于IO與CPU(含內存)的訴求可能出現不對等情況,人們意識到Hadoop發明之初強調存算融合,利用局部性讓計算跟著數據跑的局部性原理帶來的硬件節省,不如存儲和計算分別擴容帶來的節省硬件收益。對于企業而言,可以實現計算和存儲按需靈活擴容,降本增效。一般來說,數據量超過300TB,且大數據服務器總數量超過20臺時,用戶可以考慮采用存算分離架構。當分析時延要求極低且不具備緩存/RDMA能力時則不考慮采用存算分離架構。
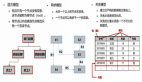
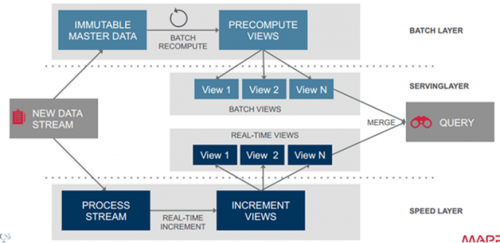
(2)Lambda架構
Lambda架構是一個實時大數據處理框架,通過Batch Layer和Speed Layer的分層設計來實現在一個系統內同時支持流處理和批處理。
Lambda(λ)架構的數據流采用基于不可變日志的分布式消息系統Kafka,數據進入Kafka后,一部分進行批處理,一部分進行流處理。批處理通常使用MR或Spark進行Batch View的預計算, Batch View自身結果數據的存儲采用HBase(查詢大量的歷史結果數據)。Speed Layer(流處理)增量數據的處理可選用Flink,Realtime View增量結果數據集為了滿足實時更新的效率,選用Redis。Lambda架構滿足了高容錯、低延時和可擴展等實時數據處理需求。
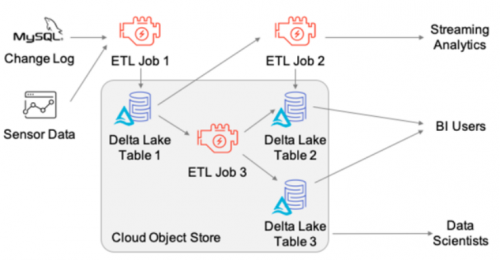
(3)批流融合
除了Lambda(λ)架構這種批流分離的架構外,批流融合也是十分流行的架構。批流融合支持ACID的upsert、delete、insert等可以實現流處理和批處理一體,確保統一的原始視圖(ODS),數據直接進入大數據數倉,計算口徑統一。批流融合不再采用消息隊列,其作用可以被流引擎部分替換,可以內部自動合并小文件,對上屏蔽小文件的處理復雜性,還可以讓用戶查詢給定時間點的快照或回滾錯誤更新到之前正確的數據。
(4)實時數倉
據Gartner統計實時數據規模在未來三年內會達到25%,數據規模高速增長帶來了強勁的數據分析需求,由此實時數倉應運而生,它可以進行內存級、細粒度的實時預計算。將cube的構建分為內存部分和磁盤部分,磁盤部分對應于傳統的預計算,內存部分對應于實時場景。在實時預計算系統中,用戶預先設置好需要在線分析的統計方法(度量及指標)。對實時產生的數據,實時數倉以極細的時間粒度(segment)進行計算和匯總;實時數倉收到用戶查詢請求(query)時,如果計算結果處于內存中(realtime-node)中,則直接從內存中獲取結果。實時數倉廣泛應用于用戶畫像分析、點擊流分析、網絡流量分析等場景中。
(5)數據湖
企業在持續發展,企業的數據也不斷堆積,在數據存儲層面上,“含金量”最高的數據已經存在數據庫和數倉里,支撐著企業的運轉。但是,企業希望把生產經營中的所有相關數據,歷史的、實時的,在線的、離線的,內部的、外部的,結構化的、非結構化的,都能完整保存下來,方便未來“沙中淘金”。因此,數據湖誕生,它由數據存儲架構、數據管理工具、數據探索和開發工具三要素構建。
(6)湖倉一體方案
數據湖起步成本很低,但隨著數據體量增大,TCO成本會加速飆升,數倉則恰恰相反,前期建設要小心地處理數據,開支很大。一個后期成本高,一個前期成本高,對于既想修湖、又想建倉的用戶來說,既然都是拿數據為業務服務,數據湖和數倉作為兩大“數據集散地”,能不能彼此整合一下?于是數倉一體方案出現,讓一套架構里面具備數據湖靈活性,兼有數據倉庫的成長性。
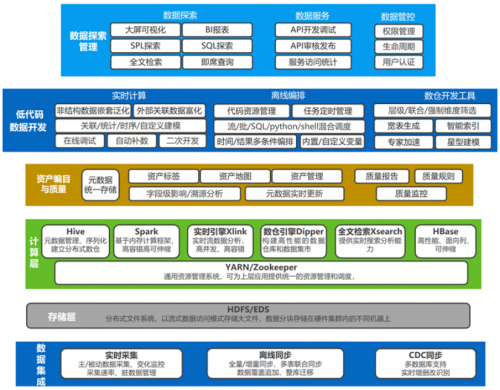
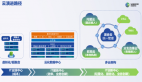
看點三:如何簡化大數據的開發
大數據的開發過程受工具及開發流程的影響,開發團隊的使用門檻高,上手難度大。對于項目交付而言,一是大數據分析的定制需求多,需要專業團隊才能交付;二是實施階段問題多,全階段都需要研發投入;三是項目成本中大數據占比高,驗證階段壓力大。這三重問題使得項目交付的成本高。其次,大數據復雜的架構就意味著技術棧復雜,尋找復合型人才難度大,人力成本高。由此可見,大數據的開發亟需降本增效,那么如何簡化大數據的開發,提高研發人員的開發效率呢? Letian給出了如下建議:
一、通過外部工具將可視化展示內遷應用到大數據上。可視化是大數據分析的最后環節,針對離線分析場景可以通過配置SQL/SPL 編寫圖/表的代碼,或者選擇預置的圖或表模板實現從立方體到交叉表(中國式復雜報表)的展示。針對交互式分析場景可以通過敏捷BI(Tableau、Kibana-Lens)進行拖拽實時自動地生成圖或表實現交互式分析可視化展示。
二、通過數倉開發工具簡化流程。數倉開發是大數據開發的主要場景,針對數倉開發可以通過工具或者可視化平臺減少需要反復的過程。在數據進行清洗后,數倉可以進入可視化平臺開發免除繁瑣的代碼編寫,在原始數據中加載數據可以有可視化操作,通過拖拽構建數倉模型,從中提取指標并設置加速機制自動進行預計算,設置上線定時周期腳本讓模型在固定時間關聯、運行、驗證。
三、流計算開發工具。在流處理場景中,可以通過可視化工具進行輔助開發。通過可視化開發畫布,進行數據來源配置、觸發條件配置和數據目的配置,省去流計算中的代碼編寫。
四、調度開發工具。大數據的開發需要不同代碼的編寫,各個代碼之間可以通過可視化調度開發工具實現管理、調度和依賴關系的處置。