













技術Leader教你看源碼的本質
前面我說過技術 leader 的幾個特質, 今天還想跟大家分享下,作為技術 leader ,還要懂得研究和引入技術,引入的 前提一定是要 Hold 住。怎么才叫 hold 住呢?就是能精通使用它,能夠深入了解它的架構、原理,能夠剖析它的核心源代碼。
以研究 Nacos 為例,這次我分享下研究技術的方法,授之以漁,希望大家有所收獲,當然也歡迎留言共同討論更好的技巧。
01 官方文檔,搭建demo使用
很多人喜歡買書看,看別人的博客,其實都是吃剩飯,別人也是看了官方文檔寫的。一名合格的技術人員, 盡量從源頭看,看官方的文檔,原汁原味的,耐心點一點點看。
Nacos 的官方文檔,怎么看這個過程我就不講了,基本上就是按目錄過一遍,然后根據官方例子搭建起來,知道它的基本功能使用。
重點看看里面的架構設計、模型概念。
02 了解功能設計主線,確定研究主線,高維度抽象功能模型
看完官方文檔,基本會用后,要確定深入研究的主線。 Nacos 不僅僅包含了服務管理功能,還包含了配置管理,元數據管理。看到這里其實也能明白為什么 Nacos 未來會成為注冊中心的趨勢,因為它同時包含了微服務的兩個套件:注冊中心、配置中心,用了它能少部署一個配置中心。下圖來自官方文檔:

圖片來源: nac os 官方文檔
這篇文章我們研究的主線是注冊中心,所以只研究它如何實現注冊中心的。 這個時候,我們要高維度看,注冊中心需要哪些功能?這些功能,是任何注冊中心都需要實現的功能,要把這些掌握清楚。顯然,注冊中心通用的功能模型包含:
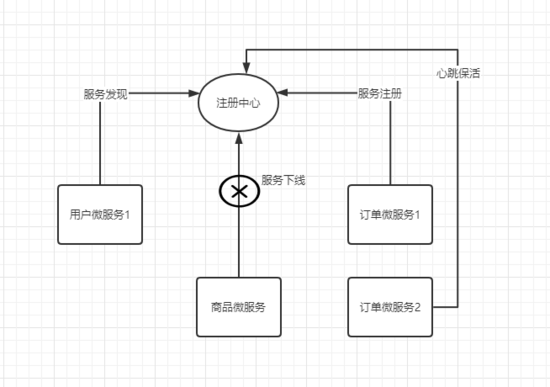
1. 服務注冊
2. 服務心跳保活
3. 服務下線(正常下線、異常下線)
4. 服務發現
基本上實現上面四點,一個單體的注冊中心就實現了。然后如果考慮分布式,還要設計它如何實現 CP/AP 模式。
03 下載源代碼,提取精華
很多人看源碼,學源碼,往往都是看了一個寂寞,為了寂寞而寂寞。 到底要看什么?
1. 源碼看什么?
看源碼,要看作者怎么架構、怎么設計、怎么實現,并思考為什么要這么實現,通過源碼看到了它里面的精髓,才算真看了源碼。不然就是看了個西瓜,吃了就沒了,就是個吃瓜群眾。相反,看源代碼 ,提煉模型、原理、機制、設計模式、并發經驗、網絡經驗、 OS 存儲機制等 ,那你才算真看了源碼,吸收了它的營養。
2.源代碼怎么看呢?
拋開技術積累和經驗因素外,方法也是很重要的一個部分。很多看源代碼都沒有經驗,看到源代碼復雜,代碼又多,一看就懵逼,也不知道從哪里看起。
我先分享 3 個經驗:
( 1 )找源頭,就是啟動的地方, 這個一般從腳本里看可以到,大部分中間件都是封裝了啟動腳本的,你就從這個啟動腳本里找啟動類,讓源碼能跑起來,后續可以 debug 驗證。
( 2 )只看主線代碼。 就是我們上面提煉的功能模型。那些日志、統計分析、異常分支、非主線分支第一次都不要看。
( 3 )先靜態看源碼, 不要動態 debug ,因為 debug ,很容易陷入細節,陷入各種分支,幾繞幾繞就懵逼了,然后就放棄了。靜態看源代碼,就是不斷鍛煉自己,讓自己只看主線代碼,那種明顯是分支的直接跳過不看,這樣快速的過主線。 實在有疑惑了,然后 debug 驗證下。
我們來看看 Nacos 的源碼,版本是 1.4.2 ,分析下我是怎么看的。
( 1 )服務注冊如何實現的?如何確保高并發?
客戶端啟動的時候,會通過 http 請求發送注冊請求,請求鏈接采用 restful 模式。 服務端接受到注冊請求后,會把請求參數封裝放到一個阻塞隊列里,然后基于一個線程不斷的獲取這個阻塞隊列的信息,放入到注冊表中。
可以看到高并發設計的一個關鍵點:異步。 這里還可以對比延伸, zookeeper 如何實現的? Eureka 如何實現的?這些實現之間有什么優劣?它們能否做到高并發?是否也是異步? 這些就留給讀者探索了。
(2)服務注冊表是如何設計的?為什么這么設計?以及怎么防止多節點的讀寫并發沖突?
Nacos 支持 CP 和 AP 模式,如果不懂 CP 和 AP 的自己百度了,這種簡單的概念我就不科普了。
①AP 模式下,是基于內存存儲的,底層其實是一個雙重的 map 結構。 CP 模式下,數據是存儲到文件的。這里我們主要還是研究 AP 模式。因為大多數場景下,我們注冊中心更適合 AP 模式。

看到這個 map 結構,有沒有思考過為什么這么設計? namespace 的目的是? group 的目的是什么? 如果有一定 Devops 經驗的同學知道,我們一個項目環境往往可能有多套,比如開發環境、測試環境、預發布環境、線上環境等。如果每一套環境都部署一個注冊中心,是不是很麻煩。所以這里 namespace 的目的,就是可以用同一套注冊中心,基于 namespace 來隔離這些不同的環境。
那么 group 的目的是什么呢?如果我們用過 dubbo 就知道這個概念了,對服務進行分組。有時候我們一個服務剛開始是一個大服務,但隨著業務擴展,有時候需要拆成幾個小服務,這樣就可以設置為一個 group。
這些都是基于 可擴展性 來考慮設計的。我們看看官方文檔的數據模型:

圖片來源: nac os 官方文檔
② 怎么防止讀寫沖突呢?
核心點:讀寫分離,采用了寫時復制模式,提升了高并發。 就是寫的時候,拷貝一份舊的實例,對這份拷貝數據修改,修改完后,再復制過去,讀直接讀舊實例。
讀寫分離這種模式,避免了加鎖沖突,提升了高并發能力。讀過 Eureka 源碼的了解,它的實現是基于多級緩存來實現的,然后緩存之間同步數據。時效性顯然沒有 Nacos 的好。
這里還要思考一個點,這里復制,復制的是什么?如果寫時復制,把所有的數據都復制,顯然內存吃不消的。這里研究下官網的服務模型,服務下面封裝的是一個個集群,集群下面是實例。
為什么有集群這個概念呢? 如果公司規模大一點的同學會知道,為了容災高可用,一個服務,可能是多機房部署的。比如一個服務可能在亦莊機房部署一個集群,兆維機房下也有一個集群。這里可以看到 nacos 模型設計的是非常巧妙的,基本上很多點都考慮到。
 圖片來源: nac os 官方文檔
圖片來源: nac os 官方文檔
我們看源代碼也可以驗證,可以看到 Service 下面,封裝了一個 clusterMap。

而 cluster 下面又封裝了具體的實例集合,畫橫線的部分。
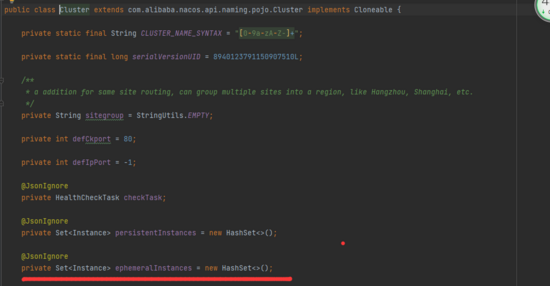
所以,這里的寫時復制,它復制的是這個實例所屬的集群結構,我把核心代碼截圖出來,
先復制舊的實例,放到一個 oldmap 里面。

對舊的 map 做一系列運算操作,比如下線一個實例 , 然后把結果放到 ips 。

最后把新的服務實例集合賦值回去。

可以看到這里面有很多技巧,這些都可以學習,以后自己設計中間件或者寫代碼的時候,都是可以直接用的。
(3)服務心跳是如何保活的?
客戶端每 5s 發送心跳給服務端,通過 http 請求調用發送給服務端。 服務端開啟健康檢查任務,每隔 5s 檢查一次,如果發現超過 15s 沒有收到心跳,設置健康狀態為 false. 如果超過 30s 沒有收到心跳,直接剔除實例。

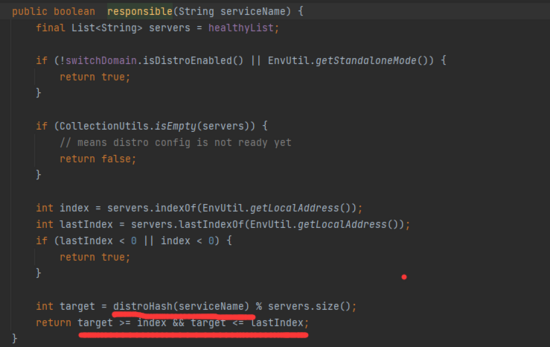
這里我們想一個問題,服務端開啟健康檢查任務,如果集群模式下,每個服務端都要判斷嗎?這個會不會很耗性能?

我們看到健康檢查任務里有這樣一段代碼 , 它會根據服務名稱通過 hash 運算后對機器結點數取模,判斷是否要執行健康檢查代碼。也就是說,集群模式下,不管啟動了多個服務實例,任何一個服務,正常情況下只有一個結點來執行健康檢查代碼。但可能以為時效性,如果其他節點多執行一次,也沒什么大影響對吧。當然這里面還有一些細節,都可以深扣,服務發現,時效性是多大?
(4)服務是如何下線的?
超過 30s 未收到心跳,就會剔除,這個上面我們知道了,剔除調用的其實是自己的 deregister 方法:

跟進去看一下,我們發現刪除方法對 service 也是加了鎖的,也就是說對同一個服務的修改,是做了防并發的。

最后刪除,本質也是基于異步的,這個和注冊邏輯類似。

(5)客戶端如何發現服務的,服務修改是如何感知的?
① 客戶端先從本地緩存獲取服務實例,如果為空,則從服務端拉取。

并啟動一個定時任務,定期更新服務端最新實例信息。
② 服務端修改后,通過 udp 協議推送
一方面基于 udp 推送提升了實時性,另一方面, udp 雖然可能丟包,但客戶端定時拉取可以作為兜底。這個設計真的很巧妙。
然后 Nacos 的 CP 模式,基于 raft 協議實現的一致性。還有它的配置中心架構是如何設計的,限于篇幅,就不再展開了。大家按照我的思路,去研究就好。記住看源碼,根據主線看,然后學習它的機制、原理。不要緊緊只是看個代碼。
3.提取源碼精華
看完源碼后,需要提取總結里面的精華,這里提取了部分用于舉例,大家可以根據自己的邏輯提取精華,不斷提取精華,不斷內化成自己的經驗,技術才能得到質的飛躍。
|
維度 |
核心點 |
描述 |
總結 |
|
接口設計 |
版本設計 |
/nacos/v1/ns/instance |
設計接口的時候考慮版本設計 |
|
設計模式 |
代理模式 |
DelegateConsistencyServiceImpl NamingClientProxyDelegate |
基于是否臨時節點選擇一致性協議具體實現,臨時節點是 Distro, 持久節點是 raft 客戶端代理 |
|
工廠模式 |
NacosFactory |
該類統一提供了創建 ConfigService (配置中心服務)、 NamingService (注冊中心服務)和 NamingMaintainService (注冊中心實例操作服務)的實例化方法,并且里面使用了反射機制 |
|
|
架構設計 |
可擴展設計 |
數據模型 |
命名空間支持環境隔離 服務分組 服務實例支持集群 |
|
高并發設計 |
異步、讀寫分離、寫時復制、緩存機制 |
熟悉基本套路,在考慮高并發時都可以套用 |
|
|
高可用設計 |
從客戶端、心跳機制、服務端多個角度確保了高可用機制 |
客戶端重試機制、客戶端本地緩存文件及故障轉移機制、服務端集群、一致性協議 (ap) |
|
|
分層架構設計 |
架構層次非常清晰 |
整體架構也好,服務注冊發現也好,架構分層很清晰。比如服務注冊發現: Controller ->ServiceManager->ConsistencyService |
|
|
中間件底層源碼機制 |
高并發容器 |
ArrayBlockingQueue 、 ConcurrentHashMap 、 |
大部分中間底層本質就是高并發容器、線程池、定時任務、網絡,剩下的就是具體業務。 |
|
線程池 |
ThreadPoolManager 線程池生命周期管理、 ThreadPoolExecutor |
||
|
定時任務 |
ScheduledThreadPoolExecutor |
4.學以致用
學習完源碼,吸取精華不是目的,目的還是要學以致用。常見的路徑有:參加開源社區,自研中間件投入到生產實踐,內部分享經驗,外部演講分享。
學以致用才是本質!
本文以研究Nacos為例,以實踐步驟分享研究技術的方法;對于微服務架構,后續將有其他同學分享Service Mesh,敬請關注!
















