手把手教你使用Curl2py自動構造爬蟲代碼并進行網絡爬蟲
大家好,我是Python進階者。
前言
前幾天給大家分享了小小明大佬的兩篇文章,分別是盤點一個小小明大佬開發的Python庫,4個超贊功能和手把手教你用Python網絡爬蟲獲取B站UP主10萬條數據并用Pandas庫進行趣味數據分析,這兩篇文章里邊都有說到curl2py命令,這個命令十分的神奇,通過curl2py命令將網頁請求參數直接轉換為python代碼。
curl2py命令是小小明大佬開發的filestools庫下四大神器之一,filestools目前包含四個工具包,分別是樹形目錄顯示、文件差異比較、圖片加水印和curl請求轉python代碼。關于其他三個神器的介紹,在上面那個超鏈接里邊也有,這里給出源地址出處,直擊小小明大佬開發的庫。
https://pypi.org/project/filestools/
前幾天有粉絲在問這個curl2py命令不知道怎么使用,今天這篇文章就是一個手把手教程,希望大家后面都可以用上,下面一起來看看吧!
一、安裝
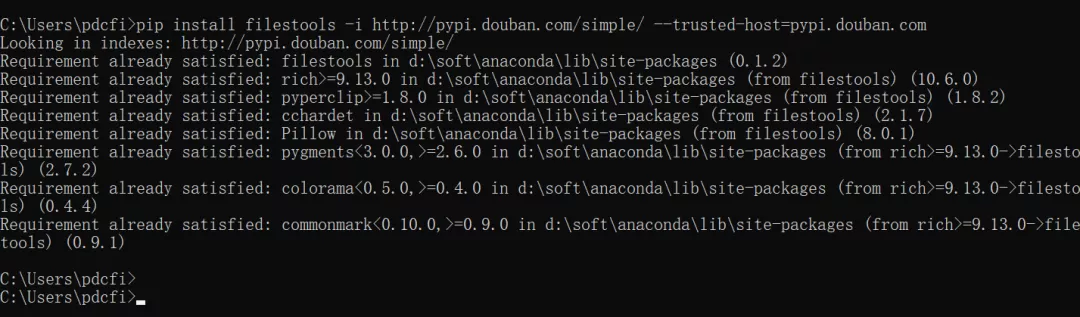
你可以選擇在命令提示符使用pip安裝filestools庫,安裝命令:
- pip install filestools
- 或者
- pip install filestools -i http://pypi.douban.com/simple/ --trusted-host=pypi.douban.com
二、傳統方法
1、目標網站
安裝之后,我們就可以進行使用了。這里我們以小小明大佬之前介紹過的這個網站為例,進行說明。
小小數據網站:https://xxkol.cn/kol
【注意】:如果是初次登錄這個網站,需要進行微信掃碼登錄,才能有瀏覽權限噢!
2、網頁請求
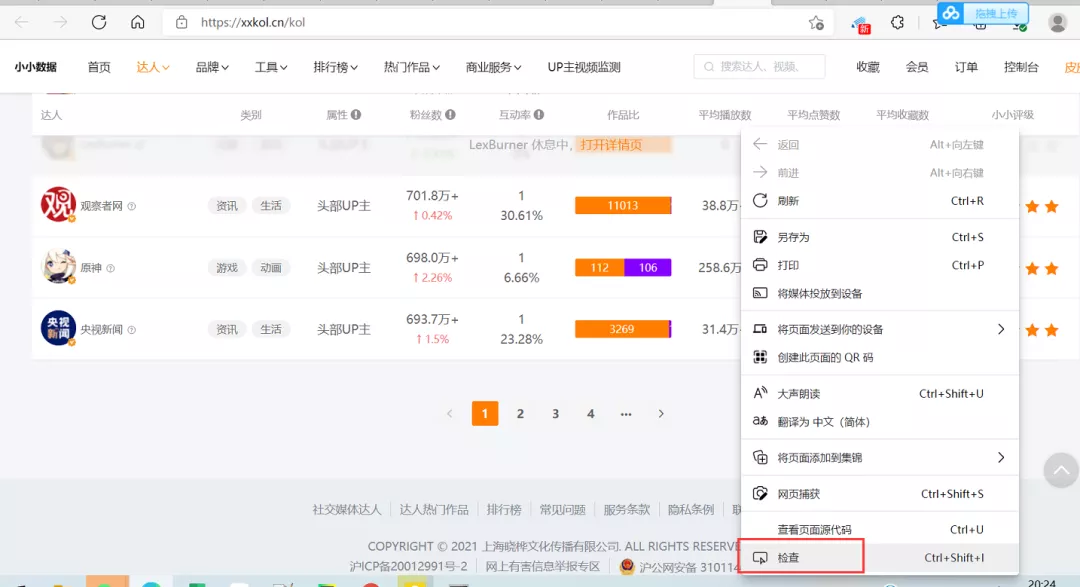
那么現在我們需要獲取這個網站的數據,就需要對改網站進行請求。老規矩,右鍵選擇“檢查”(如下圖所示)或者直接按下鼠標快捷鍵F12,可以進入開發者模式。
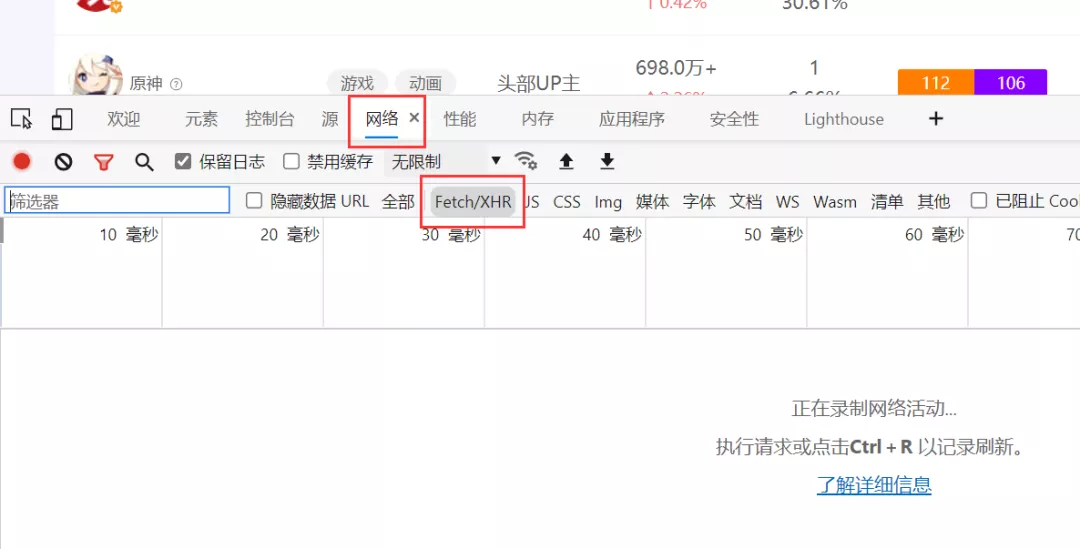
進入到開發者模式,如下圖所示。依次選擇網絡-->Fetch/XHR。
我們嘗試進行翻頁查看數據的話,發現這個網站其實是JS加載的,那么就需要構造請求頭,如下圖所示。
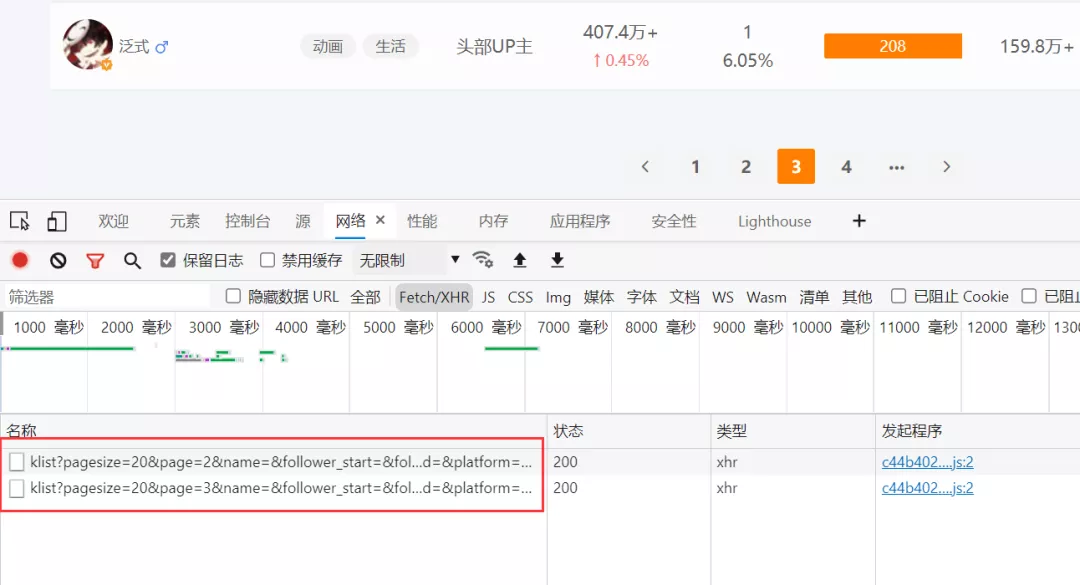
按照以往的做法,我們肯定是需要手動的去把這些cookies、headers和params參數挨個的去復制粘貼到我們的代碼文件里邊。這么做肯定是可以的,但是容易出現出錯或者漏了某一個參數,而且費時費力,萬一出錯了,你還得挨個從頭到尾去檢查,十分的頭大。
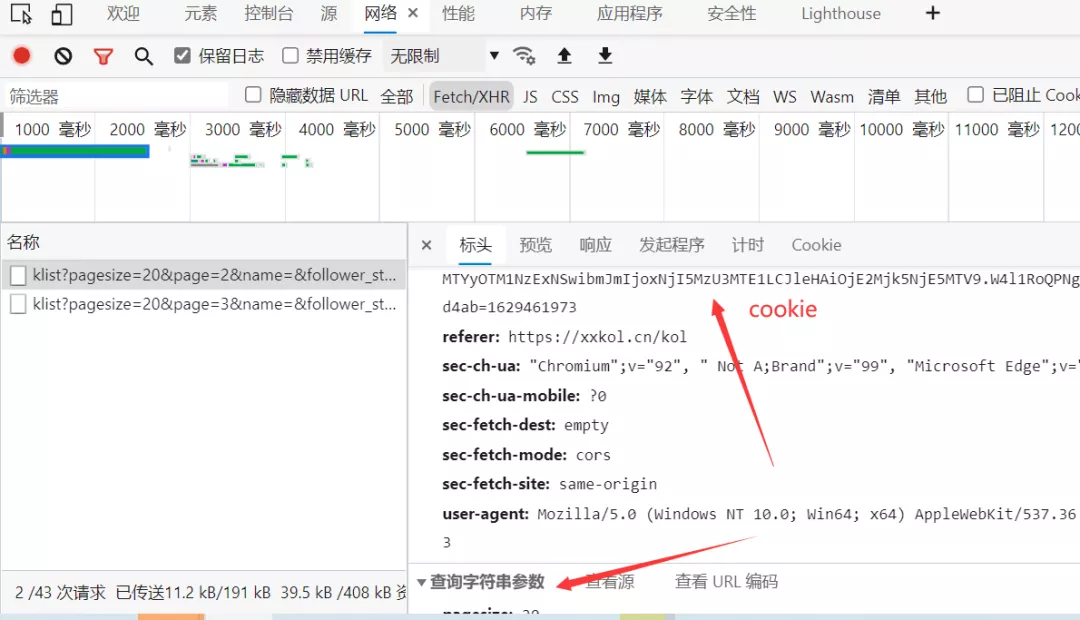
那現在小小明大佬給我們開發的這個curl2py工具呢,就直接解放了我們的雙手,我直呼小小明yyds!下面一起來看看如何使用吧。
三、curl2py工具
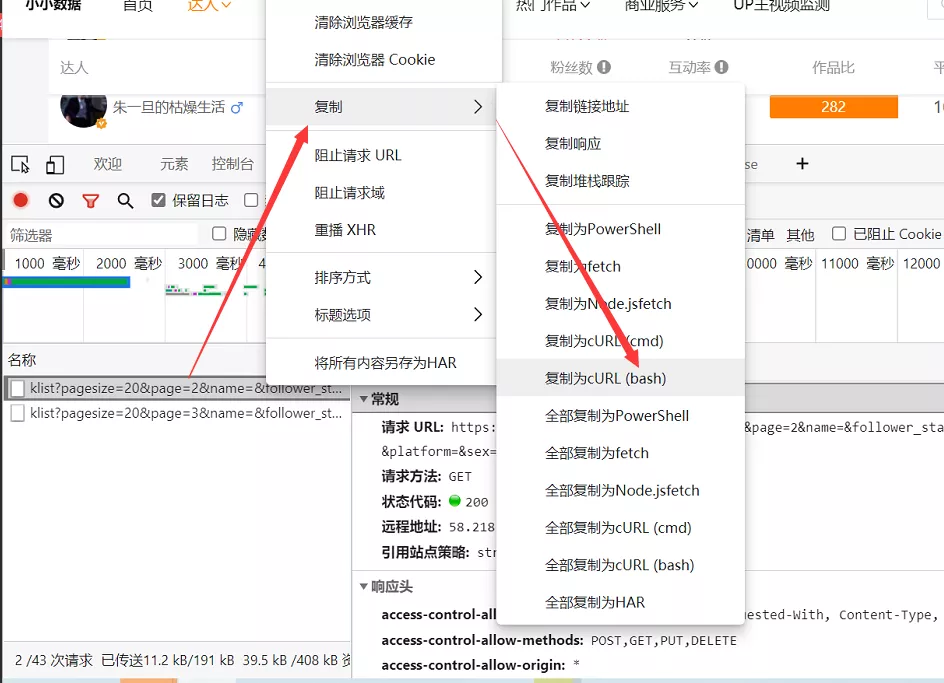
1、復制為cURL(bash)
繼續沿用上一步的網站和分析情況,我們只需要在JS網址上進行右鍵,然后依次選擇復制-->復制為cURL(bash),如下圖所示。
2、使用curl2py工具轉換代碼
復制好之后,我們只需要在Pycharm中運行以下代碼,其中代碼中的xxx,就是上面復制到的curl命令,直接粘貼替換下面的xxx即可。
- from curl2py.curlParseTool import curlCmdGenPyScript
- curl_cmd = """xxx"""
- output = curlCmdGenPyScript(curl_cmd)
- print(output)
3、實例
下面來看實際操作,以剛剛這個網站為例,小編剛剛已經復制了,然后替換粘貼代碼,代碼如下所示。
- from curl2py.curlParseTool import curlCmdGenPyScript
- curl_cmd = '''
- curl 'https://xxkol.cn/api/klist?pagesize=20&page=2&name=&follower_start=&follower_end=&inter_start=&inter_end=&xxpoint_start=&xxpoint_end=&platform=&sex=&attribute=&category=&sort_type=' \
- -H 'authority: xxkol.cn' \
- -H 'sec-ch-ua: "Chromium";v="92", " Not A;Brand";v="99", "Microsoft Edge";v="92"' \
- -H 'accept: application/json, text/plain, */*' \
- -H 'authorization: eyJ0eXAiOiJKV1QiLCJhbGciOiJIUzI1NiJ9.eyJ1c2VyaW5mbyI6eyJvcGVuaWQiOiJvcEowYzB0V2p4RmJ4bTMwQ1FyZE9QSXNaWmlJIiwiaWQiOjEzMzc2fSwiaXNzIjoiaHR0cHM6XC9cL2JhY2sueHhrb2wuY24iLCJhdWQiOiJodHRwczpcL1wvYmFjay54eGtvbC5jbiIsImlhdCI6MTYyOTM1NzExNSwibmJmIjoxNjI5MzU3MTE1LCJleHAiOjE2Mjk5NjE5MTV9.W4l1RoQPNgCXBBBobO49QcfMjgYsM4nuKNtCmKshhHA' \
- -H 'sec-ch-ua-mobile: ?0' \
- -H 'user-agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.131 Safari/537.36 Edg/92.0.902.73' \
- -H 'sec-fetch-site: same-origin' \
- -H 'sec-fetch-mode: cors' \
- -H 'sec-fetch-dest: empty' \
- -H 'referer: https://xxkol.cn/kol' \
- -H 'accept-language: zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6' \
- -H 'cookie: Hm_lvt_d4217dc2524e360ff487588dd84ad4ab=; xxtoken=eyJ0eXGciOiJIUzI1NiJ9.eyJ1c2VyaW5mbyI6eyJvcGVuaWQiOiJvcEowYzB0V2p4RmJ4bTMwQ1FyZE9QSXNaWmlJIiwiaWQiOjEzMzc2fSwiaXNzIjoiaHR0cHM6XC9cL2JhY2sueHhrb2wuY24iLCJhdWQiOiJodHRwczpcL1wvYmFjay54eGtvbC5jbiIsImlhdCI6MTYyOTM1NzExNSwibmJmIjoxNjI5MzU3MTE1LCJleHAiOjE2Mjk5NjE5MTV9.W4l1RoQPNgCXBBBobO49QcfMjgYsM4nuKNtCmKshhHA; Hm_lpvt_d4217dc2524e360ff487588dd84ad4ab=1629212' \
- --compressed
- '''
- output = curlCmdGenPyScript(curl_cmd)
- print(output)
運行代碼之后,我們在控制臺會得到具體的爬蟲代碼,如下圖所示。
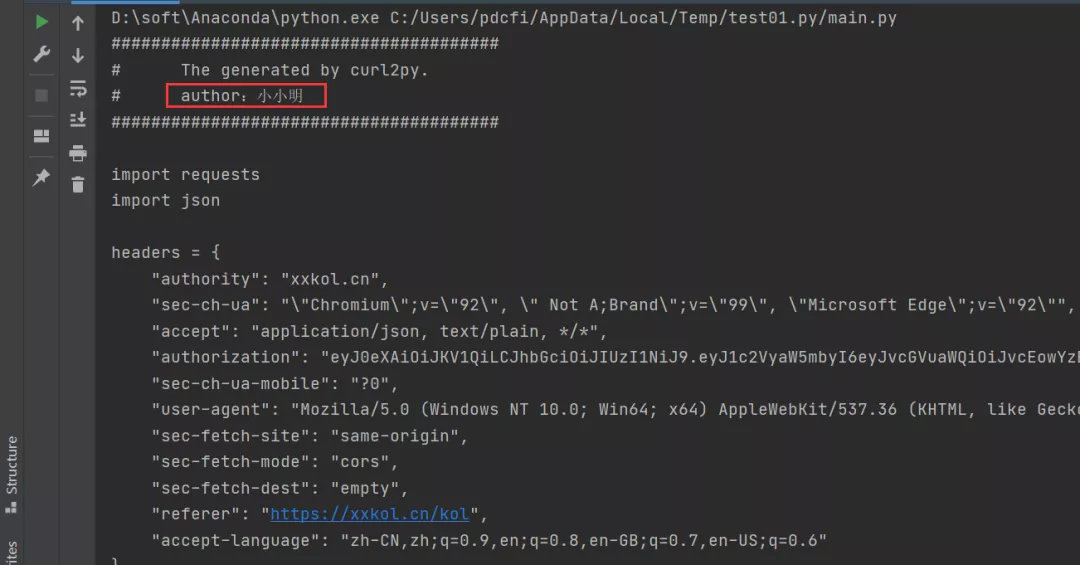
也就是說,都不需要你動手,小小明大佬直接給你把代碼都構造出來了,是不是個狠人?
這里我把控制臺輸出的代碼直接拷貝出來,粘貼到這里,這樣大家看得可能會更直觀一些。
- #######################################
- # The generated by curl2py.
- # author:小小明
- #######################################
- import requests
- import json
- headers = {
- "authority": "xxkol.cn",
- "sec-ch-ua": "\"Chromium\";v=\"92\", \" Not A;Brand\";v=\"99\", \"Microsoft Edge\";v=\"92\"",
- "accept": "application/json, text/plain, */*",
- "authorization": "eyJ0eXAiOiJKV1QiLCJhbGciOiJIUzI1NiJ9.eyJ1c2VyaW5mbyI6eyJvcGVuaWQiOiJvcEowYzB0V2p4RmJ4bTMwQ1FyZE9QSXNaWmlJIiwiaWQiOjEzMzc2fSwiaXNzIjoiaHR0cHM6XC9cL2JhY2sueHhrb2wuY24iLCJhdWQiOiJodHRwczpcL1wvYmFjay54eGtvbC5jbiIsImlhdCI6MTYyOTM1NzExNSwibmJmIjoxNjI5MzU3MTE1LCJleHAiOjE2Mjk5NjE5MTV9.W4l1RoQPNgCXBBBobO49QcfMjgYsM4nuKNtCmKshhHA",
- "sec-ch-ua-mobile": "?0",
- "user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.131 Safari/537.36 Edg/92.0.902.73",
- "sec-fetch-site": "same-origin",
- "sec-fetch-mode": "cors",
- "sec-fetch-dest": "empty",
- "referer": "https://xxkol.cn/kol",
- "accept-language": "zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6"
- }
- cookies = {
- "Hm_lvt_d4217dc2524e36588dd84ad4ab": "1629232919",
- "xxtoken": "eyJ0eXAiOiJKVhbGciOiJIUzI1NiJ9.eyJ1c2VyaW5mbyI6eyJvcGVuaWQiOiJvcEowYzB0V2p4RmJ4bTMwQ1FyZE9QSXNaWmlJIiwiaWQiOjEzMzc2fSwiaXNzIjoiaHR0cHM6XC9cL2JhY2sueHhrb2wuY24iLCJhdWQiOiJodHRwczpcL1wvYmFjay54eGtvbC5jbiIsImlhdCI6MTYyOTM1NzExNSwibmJmIjoxNjI5MzU3MTE1LCJleHAiOjE2Mjk5NjE5MTV9.W4l1RoQPNgCXBBBobO49QcfMjgYsM4nuKNtCmKshhHA",
- "Hm_lpvt_d4217dc2524e360ff488dd84ad4ab": "16292212"
- }
- params = {
- "pagesize": "20",
- "page": "2",
- "name": "",
- "follower_start": "",
- "follower_end": "",
- "inter_start": "",
- "inter_end": "",
- "xxpoint_start": "",
- "xxpoint_end": "",
- "platform": "",
- "sex": "",
- "attribute": "",
- "category": "",
- "sort_type": ""
- }
- res = requests.get(
- "https://xxkol.cn/api/klist",
- params=params,
- headers=headers,
- cookies=cookies
- )
- print(res.text)
喲嚯,這代碼,直接給你呈現出來了,講真,這代碼比我們自己寫出來的還要好呢,真是tql!
有的吃瓜群眾可能就要問了,小編啊,這個代碼能跑嘛?當然可以了!下面一起來運行下吧!直接在Pycharm里邊復制控制臺的代碼,將首尾兩行Pycharm自帶的提示去除,就可以跑了,右鍵運行,得到下圖的結果。
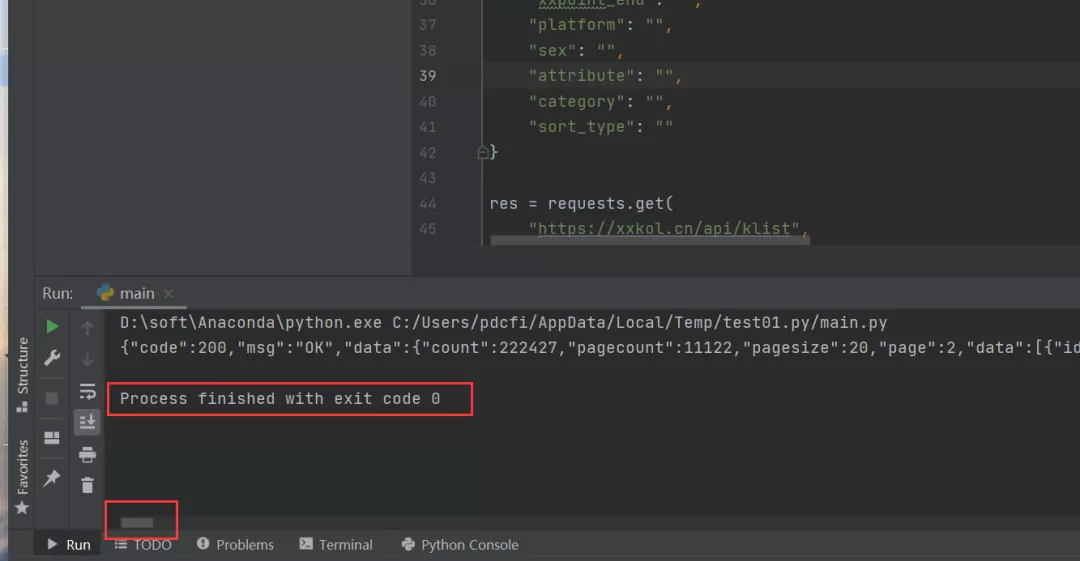
可以看到返回code 0,說明程序運行成功,而且可以看到滾動條那么小,可以想象數據量還是蠻大的,這個數據一看就是json格式的,直接將結果放到在線json網站中去看看。
json在線解析網址:https://www.sojson.com/
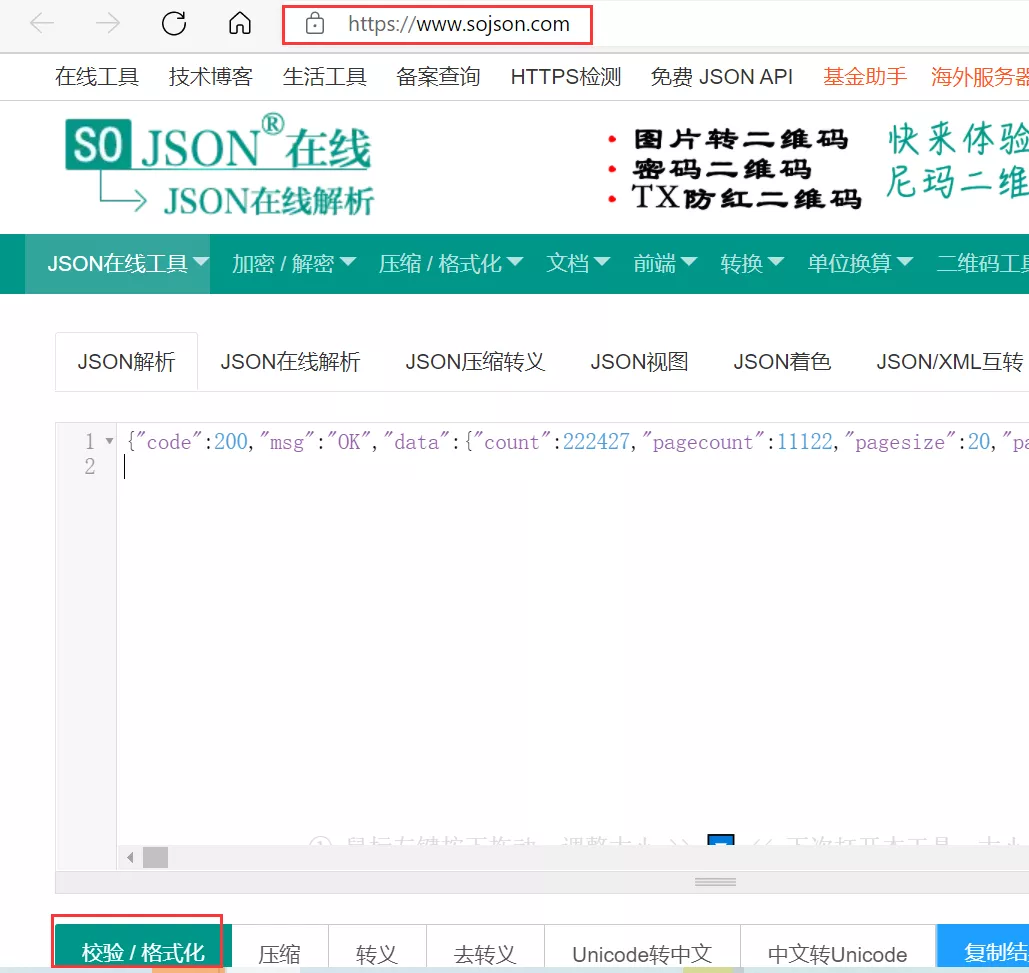
然后點擊紅色框框中的校驗/格式化,可以看到json格式的數據,如下圖所示。
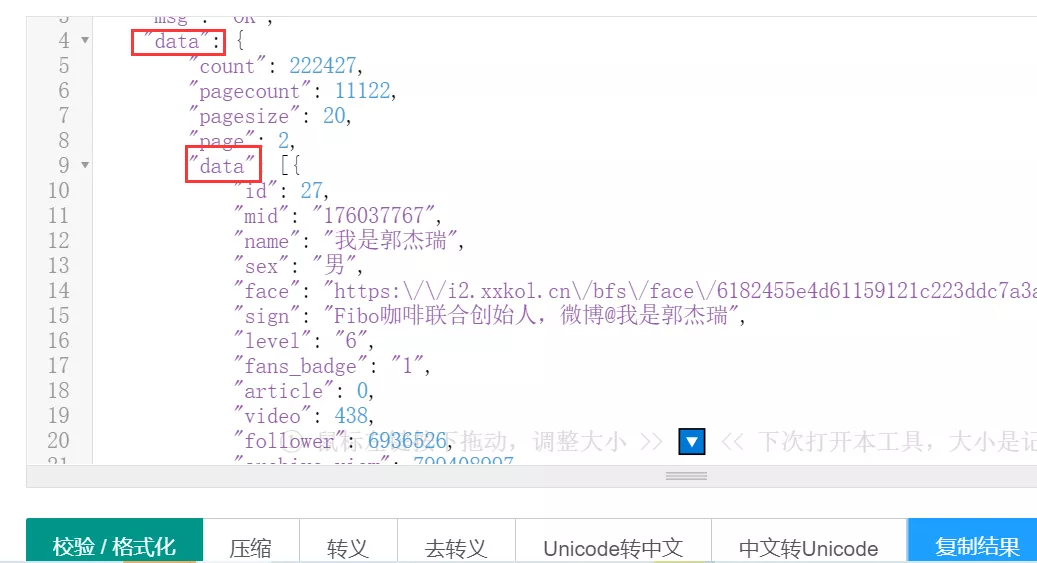
這下看上去是不是清爽很多了呢?
四、總結
我是Python進階者,這篇文章主要給大家介紹了curl2py工具及其用法。curl2py工具的確是一個神器,功能強大,而且十分方便,有了它,基本上網頁請求數據的復制、粘貼等傳統方式都通通幫你搞定了,而且省事省心省力,還不用擔心翻車。小伙伴們,你學會了嘛?快快用起來吧!