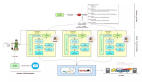
手把手教你寫網絡爬蟲(6):分布式爬蟲
作者:佚名
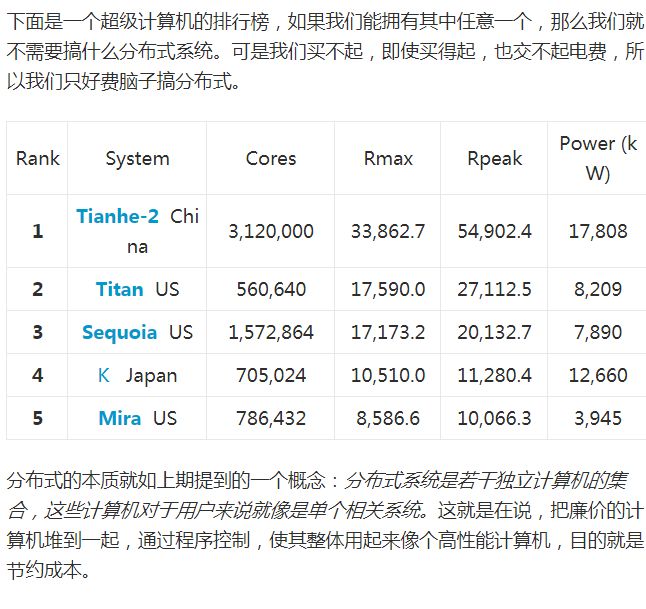
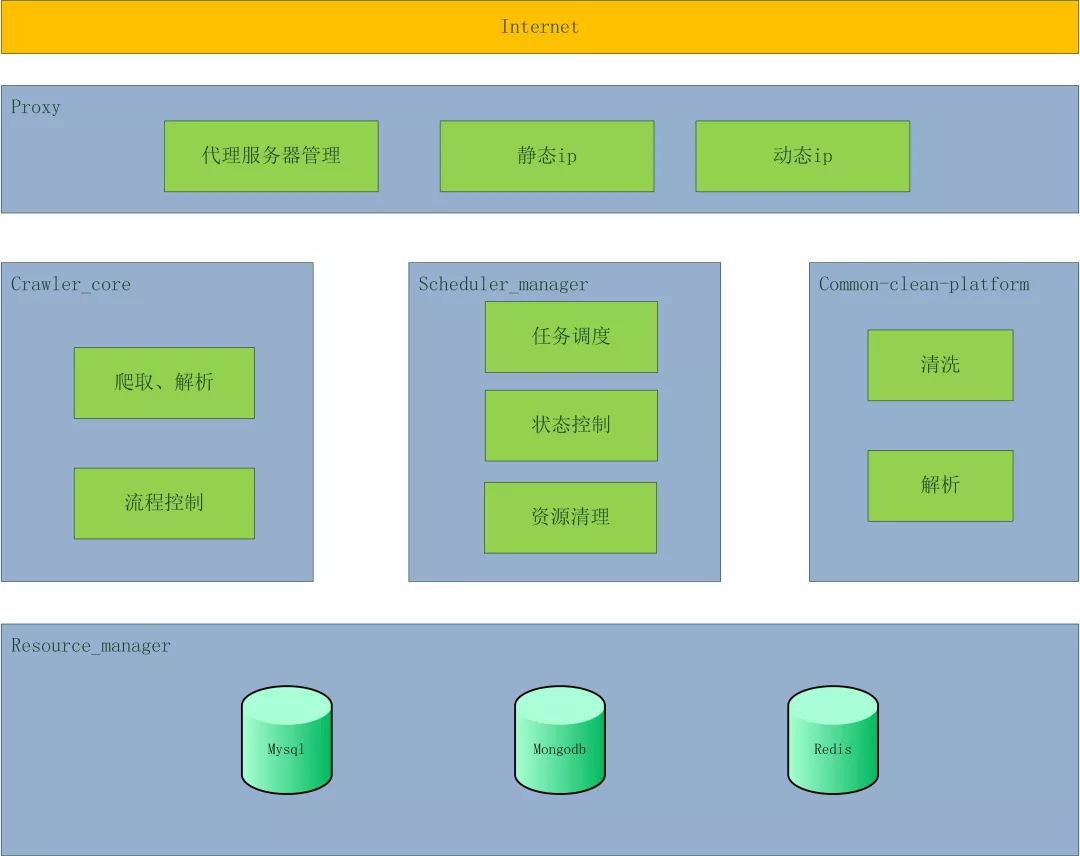
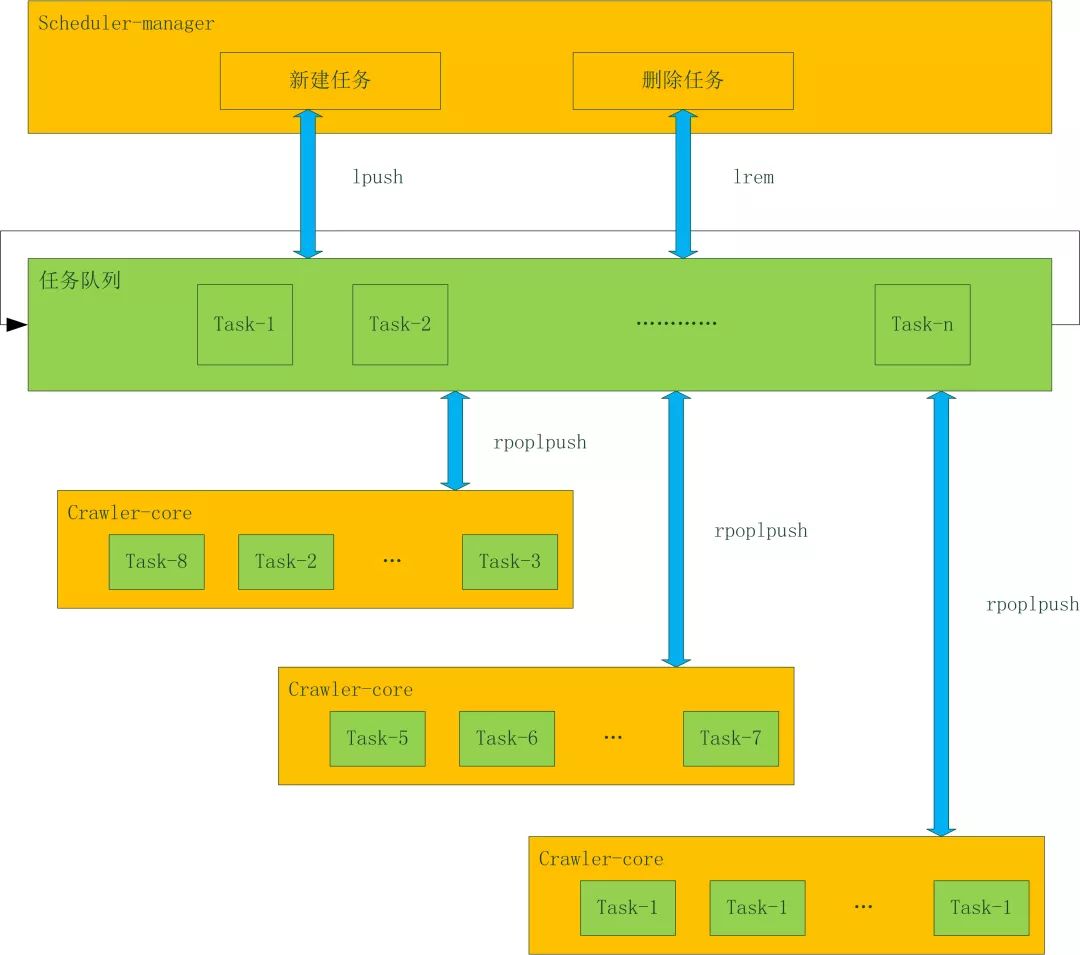
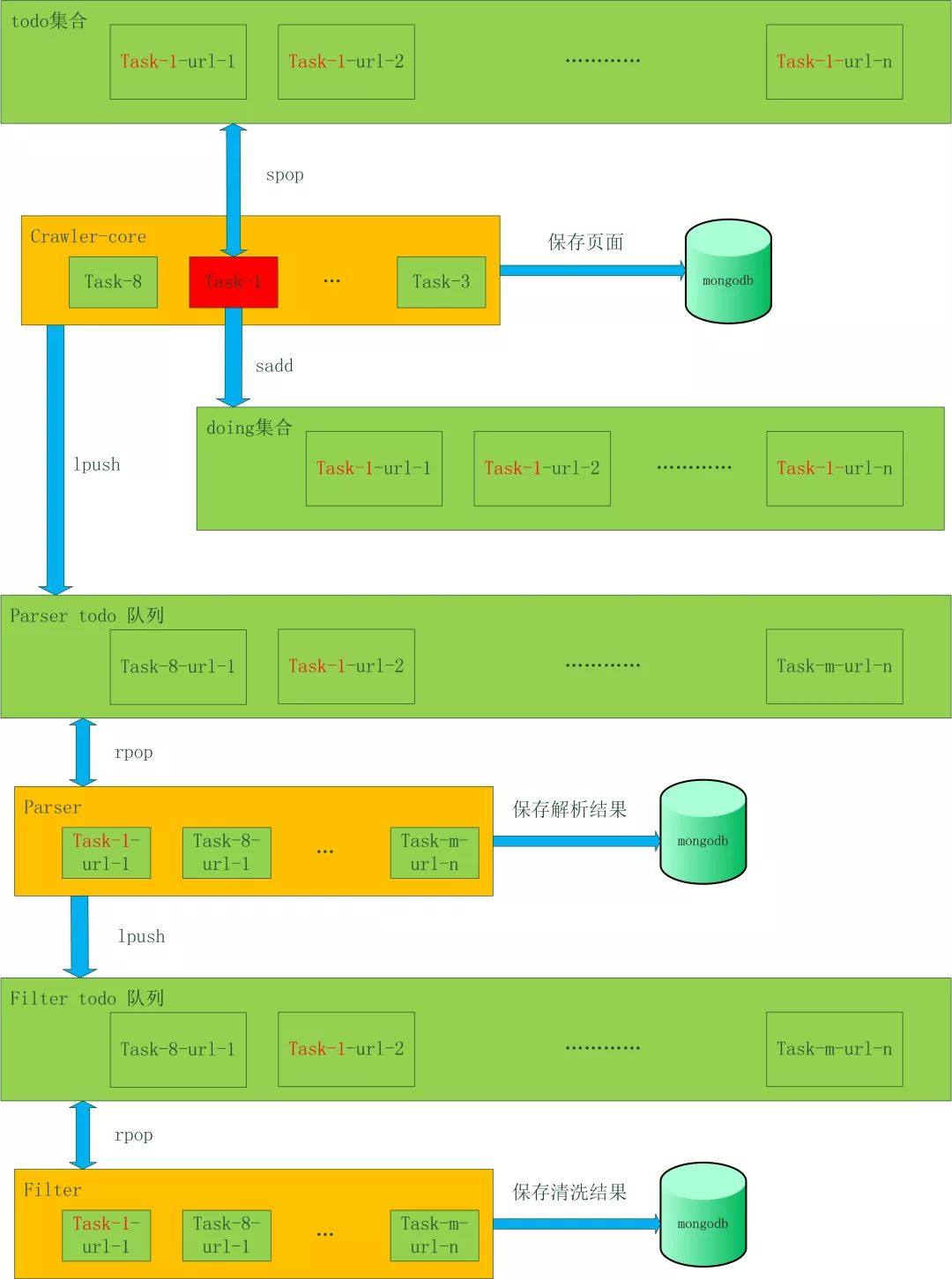
對于分布式爬蟲系統來說,假設1臺機器能10天爬完一個任務,如果部署10臺機器,那么1天就會完成這個任務。這樣就用可以接受的成本,讓系統的效率提高十倍。之前介紹的單機架構師達不到這種效果的,是時候介紹信的架構了!
本系列:
- 《手把手教你寫網絡爬蟲(1):網易云音樂歌單》
- 《手把手教你寫網絡爬蟲(2):迷你爬蟲架構》
- 《手把手教你寫網絡爬蟲(3):開源爬蟲框架對比》
- 《手把手教你寫網絡爬蟲(4):Scrapy入門》
- 《手把手教你寫網絡爬蟲(5):PhantomJS實戰》


筆者以前看過一個電影叫《Who Am I – No System Is Safe》,劇中的黑客老大“Who Am I”就用代理來隱藏自己,躲避FBI和其他黑客組織的追蹤。



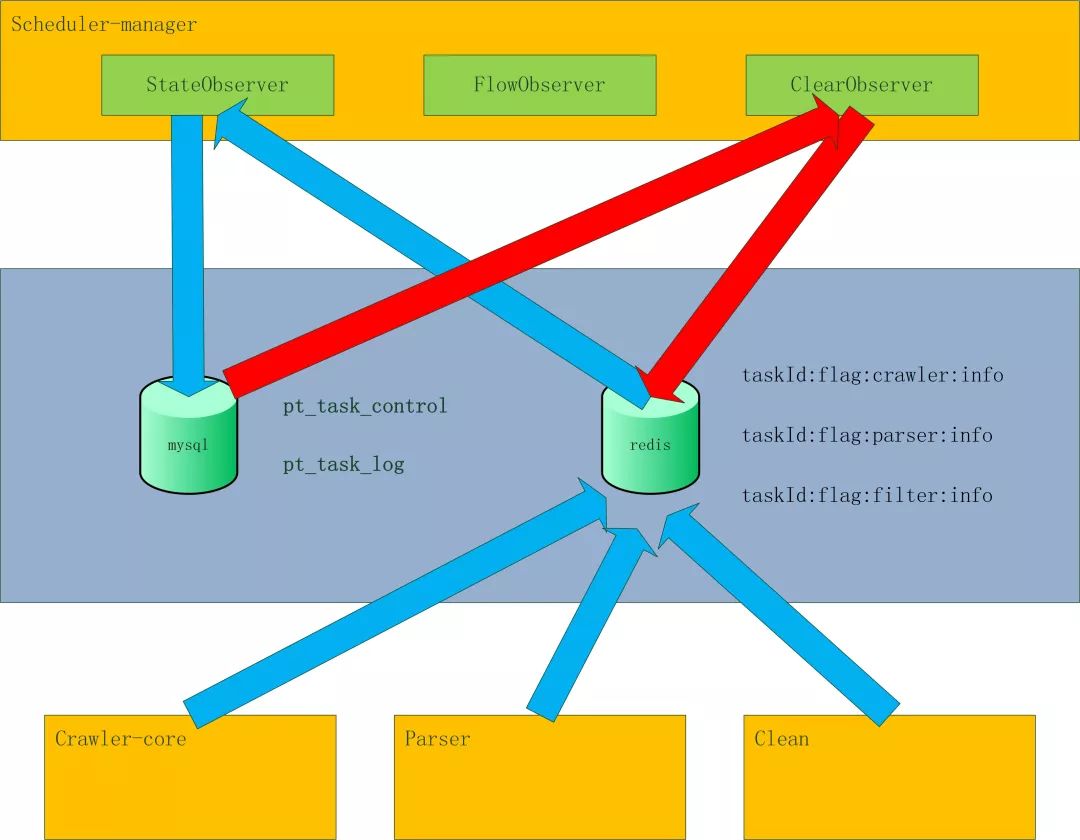

| taskId:flag:crawler:info | ||
| Filed | value | 說明 |
| totalCnt | 10000 | 抓取的url總數:抓取完成,不管成功失敗,都加1 |
| failCnt | 0 | 抓取的url失敗數:抓取失敗,加1 |
| switch | 1 | 任務狀態:0:停止,1:啟動,2:暫停,3:暫停啟動 |
| priority | 1 | 任務優先級 |
| retryCnt | 0 | 重試次數 |
| status | 0 | 任務執行狀態:1:進行中,2:完成 |
| Ref | 0 | url引用數:每消費一個url,減1;生成一個url,加1。等于0則任務完成 |
| maxThreadCnt | 100 | 任務的***線程數 |
| remainThreadCnt | 10 | 剩余可用線程數 |
| lastFetchTime | 1496404451532 | 上一次抓取時間 |
|
taskId:flag:parser:info |
||
| Filed | value | 說明 |
| totalCnt | 10000 | 解析總數:解析完成,不管成功失敗,都加1 |
| failCnt | 0 | 解析失敗數:解析失敗,加1 |
| crawlerStatus | 0 | 爬取狀態:0:進行中,2:完成 |
| ref | 10 | url引用數:crawler每保存一個網頁,加1;parser每解析完成一個網頁,減1。等于0不說明任務完成。若crawlerStatus等于2,ref等于0,則任務完成。 |
|
taskId:flag:filter:info |
||
| Filed | value | 說明 |
| totalCnt | 10000 | 清洗總數:清洗完成,不管成功失敗,都加1 |
| failCnt | 0 | 清洗失敗數:清洗失敗,加1 |
| crawlerStatus | 0 | 解析狀態:0:進行中,2:完成 |
| ref | 10 | url引用數:parser每保存一條數據,加1;filter每清洗完成一條數據,減1。等于0不說明任務完成。若parserStatus等于2,ref等于0,則任務完成。 |
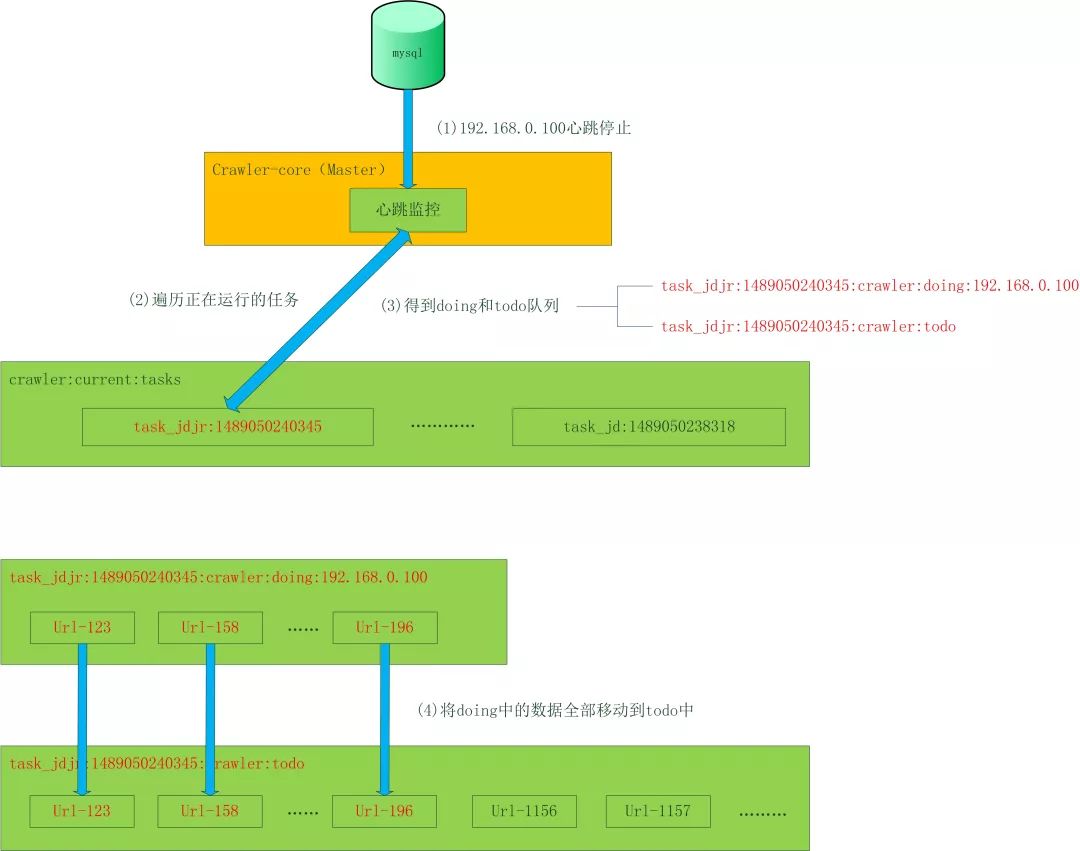
流程控制 – failover
如果一個Crawler_core的機器掛掉了,就會開始數據恢復程序,把這臺機器所有未完成的任務恢復到公共緩存中。

責任編輯:龐桂玉
來源:
Python開發者