













DDIA 對 Raft 的這種極端場景的描述,要如何理解?
本文選自我在知乎的回答。

《設計數據密集型應用》(即 DDIA)中提到 Raft 的一個問題,即,Raft 算法存在一種失去活性(liveness)的極端情況:如果有一條網絡連接不可靠,Raft 當前領導者會不斷被迫下臺導致系統實質上毫無進展。
我們先來具體描述一下該問題。
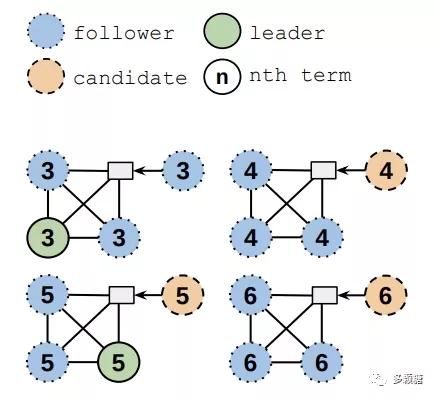
如圖所示的 4 節點 Raft 集群,其中有一個節點和其他三個網絡不太穩定,假設它能發送消息給別的節點但收不到其他節點的消息,那么它就會一直收不到心跳消息,然后轉為 candidate 自增任期并發起新的選舉,來自更大任期的 RequestVote 請求會導致現在的 Leader 下臺重新選舉。這樣一直反復,會導致集群無法正常工作。
Raft 大論文提到一種解決方式是加入一個新的 PreVote 階段,etcd 就這么干了,為此增加了一種新的節點狀態叫做 PreCandidate 狀態。
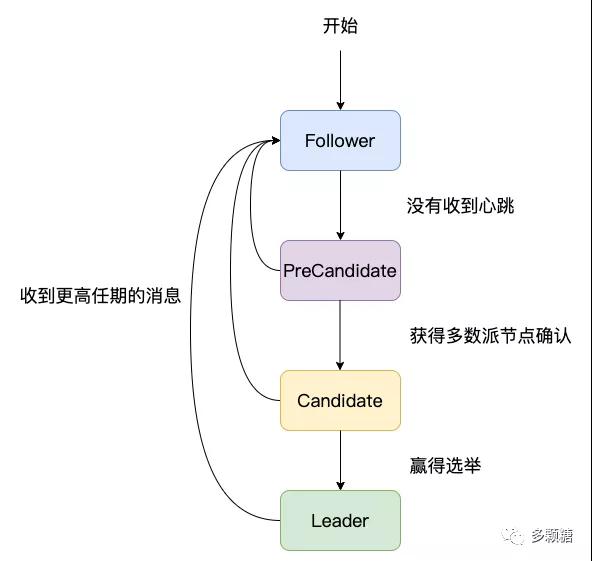
PreVote 階段作用是當一個節點想要發起選舉時,首先要確認自己確實有資格贏得投票而不是在浪費時間,才會真的自增任期發起新的選舉。
PreVote 階段的具體流程是,在發起真正的選舉之前,先發送 PreVote 消息給所有節點, PreVote消息和 RequestVote 消息一樣,但節點不會自增自己的任期,只會增加消息中的 term 參數。
收到 PreVote 消息的節點同意重新選舉的條件是:
參數中的任期更大,或者任期相同但 log index 更大;
至少一次 election timeout 時間內沒有收到領導者心跳;
只有超過半數節點同意 PreVote 消息,該節點才能真正去自增任期并發起新的選舉。
回到上述情況,網絡鏈路有問題的那個節點在 PreVote 階段會發現自己無法贏得超過半數節點同意自己發起選舉(別的節點都能收到心跳),因此不會自增任期去干擾 Leader 工作。
問題解決了嗎?
問題并沒有解決,只有 PreVote 階段還可能有一種極端情況會導致 Raft 失去活性。如圖所示:
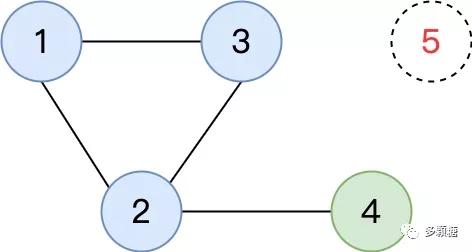
圖中是一個 5 節點組成的 Raft 集群,故障發生之前 4 是 Leader。現在故障發生了,5 宕機了,同時 4 只和 2 保持連接,1、2、3互相保持連接。這種情況下 1、3 收不到 Leader 的心跳,會發起 PreVote請求,但由于 2 能收到 Leader 節點 4 的心跳,所以 2 不會同意 PreVote 請求,因此節點 1、3 無法獲得多數派的 PreVote 同意。
該集群的問題是,無法選舉出新的 Leader,但舊的 Leader 又只能 AppendEntries 到兩個節點(2和自己),無法達成多數派,整個集群無法取得任何進展,不滿足活性。
此處 Raft 協議明明可以容忍 2 個節點故障,但增加了 PreVote 階段后反而無法容忍僅僅 1 個節點故障,其實沒有 PreVote 階段的話,1 和 3 是有機會當選 Leader 推進整個系統正常工作的。
因此 Raft 還需要增加一種機制來讓 Leader 主動下臺。
這個機制很簡單:Leader 沒有收到來自多數派節點的 AppendEntries 響應時就主動下臺。這樣,圖中 1、2 和 3 都有機會當選新的 Leader,整個集群依舊可以正常工作。
etcd 把這叫做 CheckQuorum,etcd 的 issue 中有關于此問題的討論:https://github.com/etcd-io/etcd/issues/3866
CheckQuorum 確保了如果當前 Leader 無法連接到多數派節點,它將會下臺并選舉出新的 Leader。PreVote 確保一旦 Leader 當選,整個系統將是穩定的,Leader 不會被迫下臺。
那么 PreVote + CheckQuorum 可以解決活性問題了嗎?
可以了!












