參數量僅為原來1%,北郵等利用超分算法提出高性能視頻傳輸方法
互聯網視頻在過去幾年發生了爆發式增長,這給視頻傳輸基礎設施帶來了巨大的負擔。網絡視頻傳輸系統的質量很大程度上取決于網絡帶寬。受客戶端 / 服務器日益增長的計算能力和深度學習的最新進展的啟發,一些工作提出將深度神經網絡 (DNN) 應用于視頻傳輸系統的工作,以提高視頻傳輸質量。這些 DNN 的方法將一整個視頻平均分成一些視頻段,然后傳輸低分辨率的視頻段和其對應的 context-aware 模型到客戶端,客戶端用這些訓練好的模型推理對應的低分辨率視頻段。通過這種方式,可以在有限的互聯網帶寬下獲得更好的用戶體驗質量 (QoE)。其中,傳輸一段長視頻需要同時傳輸多個超分辨率模型。
近日,來自北京郵電大學和英特爾中國研究院的研究者首先探索了不同視頻段所對應的不同模型間的關系,然后設計了一種引入內容感知特征調制(Content-aware Feature Modulation,CaFM)模塊的聯合訓練框架,用來壓縮視頻傳輸中所需傳輸的模型大小。該研究的方法讓每一個視頻段只需傳輸原模型參數量的 1%,同時還達到了更好的超分效果。該研究進行了大量的實驗在多種超分辨率 backbone、視頻時長和超分縮放因子上展現了該方法的優勢和通用性。另外,該方法也可以被看作是一種新的視頻編解碼方式。在相同的帶寬壓縮下,該方法的性能(PSNR)優于商用的 H.264 和 H.265,體現了在行業應用中的潛能。

- 論文鏈接:http://arxiv.org/abs/2108.08202
- GitHub 地址:https://github.com/Neural-video-delivery/CaFM-Pytorch-ICCV2021
與當前單圖像超分辨率 (SISR)和視頻超分辨率 (VSR)的方法相比,內容感知 DNN 利用神經網絡的過擬合特性和訓練策略來實現更高的性能。具體來說,首先將一個視頻分成幾段,然后為每段視頻訓練一個單獨的 DNN。低分辨率視頻段和對應的模型通過網絡傳輸給客戶端。不同的 backbone 都可以作為每個視頻段的模型。與 WebRTC 等商業視頻傳輸技術相比,這種基于 DNN 的視頻傳輸系統取得了更好的性能。
盡管將 DNN 應用于視頻傳輸很有前景,但現有方法仍然存在一些局限性。一個主要的限制是它們需要為每個視頻段訓練一個 DNN,從而導致一個長視頻有大量單獨的模型。這為實際的視頻傳輸系統帶來了額外的存儲和帶寬成本。在本文中,研究者首先仔細研究了不同視頻段的模型之間的關系。盡管這些模型在不同的視頻段上實現了過擬合,但該研究觀察到它們的特征圖之間存在線性關系,并且可以通過內容感知特征調制(CaFM)模塊進行建模。這促使研究者設計了一種方法,使得模型可以共享大部分參數并僅為每個視頻段保留私有的 CaFM 層。然而,與單獨訓練的模型相比,直接微調私有參數無法獲得有競爭力的性能。因此,研究者進一步設計了一個巧妙的聯合訓練框架,該框架同時訓練所有視頻段的共享參數和私有參數。通過這種方式,與單獨訓練的多個模型相比,該方法可以獲得相對更好的性能。
該研究的主要貢獻包括:
- 提出了一種新穎的內容感知特征調制(CaFM)模塊的聯合訓練框架,用于網絡間的視頻傳輸;
- 對各種超分辨率 backbone、視頻時間長度和縮放因子進行了廣泛的實驗,證明了該方法的優勢和通用性;
- 在相同的帶寬壓縮下,與商業 H.264 和 H.265 標準進行比較,由于過度擬合的特性,該方法展示了更有潛力的結果。
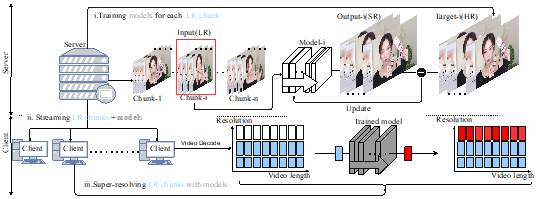
圖 1
方法
神經網絡視頻傳輸是在傳輸互聯網視頻時利用 DNN 來節省帶寬。與傳統的視頻傳輸系統不同,它們用低分辯率視頻和內容感知模型取代了高分辨率視頻。如上圖所示,整個過程包括三個階段:(i)在服務器上對每個視頻段的模型進行訓練;(ii) 將低分辨率視頻段與內容感知模型一起從服務器傳送到客戶端;(iii) 客戶端上對低分辨率視頻進行超分工作。但是,該過程需要為每個視頻段傳輸一個模型,從而導致額外的帶寬成本。所以該研究提出了一種壓縮方法,利用 CaFM 模塊結合聯合訓練的方式,將模型參數壓縮為原本的 1%。
動機和發現

圖 2
該研究將視頻分成 n 段,并相應地為這些視頻段訓練 n 個 SR 模型 S1、S2 ...Sn。然后通過一張隨機選擇的輸入圖片(DIV2K) 來分析 S1、S2...Sn 模型間的關系。該研究在圖 2 中可視化了 3 個 SR 模型的特征圖。每張圖像代表某個通道( channel)的特征圖,為了簡單起見,該研究只可視化了一層 SR 模型。具體來說,該研究將特征圖表示為

,其中 i 表示第 i 個模型,j 表示第 j 個 通道,k 表示 SR 模型 的第 k 層卷積。對于隨機選擇的圖像,可以計算
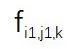
和
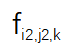
之間的余弦距離,來衡量這兩組特征圖之間的相似度。對于圖 2 中的特征圖,該研究計算了
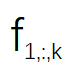
,
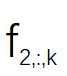
和
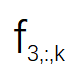
之間的余弦距離矩陣。如圖 3 所示,研究者觀察到雖然 S1 , S2 ...Sn 是在不同的視頻段上訓練的,但根據圖 3 中矩陣的對角線值可以看出“對應通道之間的余弦距離非常小”。該研究計算了 S1、S2 和 S3 之間所有層的余弦距離的平均值,結果分別約為 0.16 和 0.04。這表明雖然在不同視頻段上訓練得到了不同的 SR 模型,但是
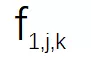
和
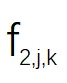
之間的關系可以通過線性函數近似建模。這也是該研究提出 CaFM 模塊的動機。

圖 3
內容感知特征調制模塊(CaFM)
該研究將內容感知特征調制 (CaFM) 模塊引入基線模型(EDSR),以私有化每個視頻段的 SR 模型。整體框架如圖 4 所示。正如上文動機中提到的,CaFM 的目的是操縱特征圖并使模型去擬合不同的視頻段。因此,不同段的模型可以共享大部分參數。該研究將 CaFM 表示為 channel-wise 線性函數:
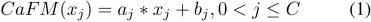
其中 x_j 是第 j 個輸入特征圖,C 是特征通道的數量,a_j 和 b_j 分別是 channel-wise 的縮放和偏置參數。該研究添加 CaFM 來調制基線模型的每個卷積層的輸出特征。以 EDSR 為例,CaFM 的參數約占 EDSR 的 0.6%。因此,對于具有 n 個段的視頻,可以將模型的大小從 n 個 EDSR 減少到 1 個共享 EDSR 和 n 個私有 CaFM 模塊。因此,與基線方法相比,該方法可以顯著降低帶寬和存儲成本。
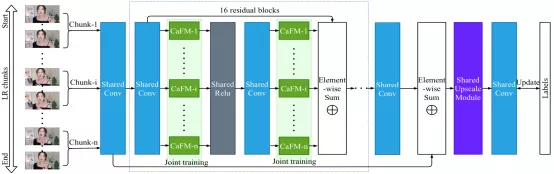
圖 4
聯合訓練
正如上文中所介紹的,該研究可以利用 CaFM 去替換每個視頻段的 SR 模型。但是通過在一個 SR 模型上微調n 個 CaFM 模塊的方式很難將精度提升到直接訓練 n 個 SR 模型的 PSNR。因此該研究提出了一種聯合訓練的框架,該框架可以同時訓練 n 個視頻段。公式可以表示為:
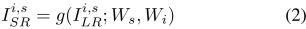
對于 SR 圖片
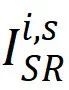
,i 表示第 i 個視頻段,s 表示該視頻段中的第 s 個 sample。公式中 W_s 表示共享的參數,W_i 表示每個視頻段私有的參數。對于每個視頻段,可以這樣計算損失函數:
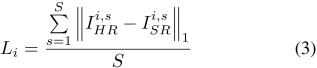
在訓練過程中,該研究從視頻段中統一采樣圖像來構建訓練數據。所有圖像用于更新共享參數 W_s,而第 i 個視頻段的圖像用于更新相應的 CaFM 參數 W_i。
VSD4K 數據集
Vimeo-90K 和 REDS 等公共視頻超分數據集僅包含相鄰幀序列(時常太短),不適用于視頻傳輸任務。因此,該研究收集了多個 4K 視頻來模擬實際的視頻傳輸場景。該研究使用標準的雙三次插值來生成低分辨率視頻。研究者選擇了六個流行的視頻類別來構建 VSD4K,其中包括: 游戲、vlog、采訪、體育競技、舞蹈、城市風景等。每個類別由不同的視頻長度組成,包括:15 秒、30 秒、45 秒、1 分鐘、2 分鐘、5 分鐘等。VSD4K 數據集的詳細信息可在論文的 Appendix 中閱讀,同時 VSD4K 數據集已在github項目中公開。
定性 & 定量分析
主實驗對比
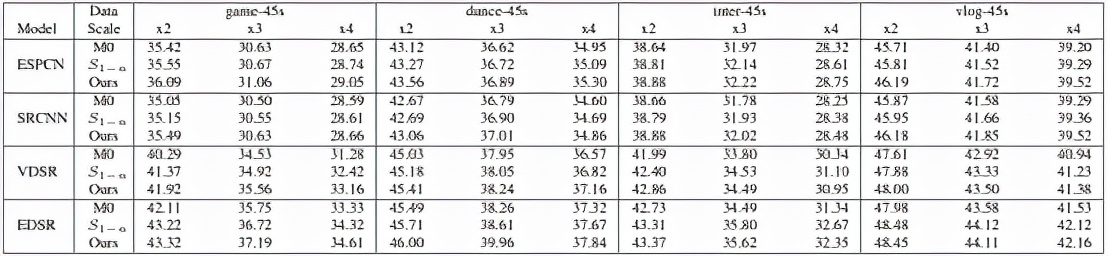
根據上表可以清晰地看到,在不同的視頻和超分尺度上該方法 (Ours) 不僅可以追趕上訓練 n 個模型 (S1-n) 的精度,并且可以在峰值信噪比上實現精度超越。注:M0 表示不對長視頻進行分段,在整段視頻上只訓練一個模型。
VS codec
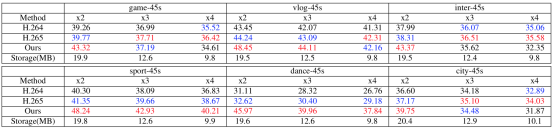
該部分實驗對本文提出的方法和傳統 codec 方法 (調低碼率做壓縮) 進行了定量比較。根據上表可以清晰地看到 (紅色表示第一名,藍色表示第二名),在相同的傳輸大小下(Storage),該方法(Ours) 在大多數情況下可以超越 H264 和 H265。同時視頻的長度越長,SR 模型所占傳輸大小的比例越小,該方法的優勢越明顯。
定性比較
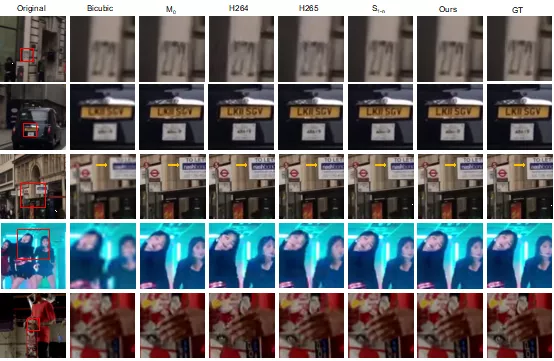
總體而言,該論文創新性地利用超分辯率算法定義網絡視頻傳輸任務,目的是減少網絡視頻傳輸的帶寬壓力。利用內容感知特征調制 (CaFM) 模塊結合聯合訓練的方式,對每個視頻段對應的模型參數量進行壓縮(1%)。為后續的研究者,提供了新的研究方向。