













國內數十位NLP大佬合作,綜述預訓練模型的過去、現在與未來
BERT 、GPT 等大規模預訓練模型(PTM)近年來取得了巨大成功,成為人工智能領域的一個里程碑。由于復雜的預訓練目標和巨大的模型參數,大規模 PTM 可以有效地從大量標記和未標記的數據中獲取知識。通過將知識存儲到巨大的參數中并對特定任務進行微調,巨大參數中隱式編碼的豐富知識可以使各種下游任務受益。現在 AI 社區的共識是采用 PTM 作為下游任務的主干,而不是從頭開始學習模型。
本文中,來自清華大學計算機科學與技術系、中國人民大學信息學院等機構的多位學者深入研究了預訓練模型的歷史,特別是它與遷移學習和自監督學習的特殊關系,揭示了 PTM 在 AI 發展圖譜中的重要地位。

論文地址:http://keg.cs.tsinghua.edu.cn/jietang/publications/AIOPEN21-Han-et-al-Pre-Trained%20Models-%20Past,%20Present%20and%20Future.pdf
清華大學教授、悟道項目負責人唐杰表示:這篇 40 多頁的預訓練模型綜述基本上算是從技術上理清了預訓練的來龍去脈。
此外,該研究還回顧了 PTM 的最新突破。這些突破得益于算力的激增和數據可用性的增加,目前正在向四個重要方向發展:設計有效的架構、利用豐富的上下文、提高計算效率以及進行解釋和理論分析。最后,該研究討論了關于 PTM 一系列有待解決的問題和研究方向,并且希望他們的觀點能夠對 PTM 的未來研究起到啟發和推動作用。
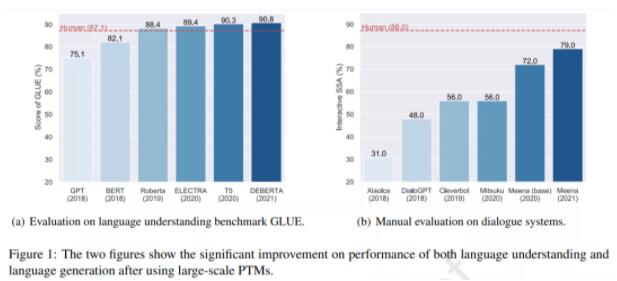
使用大規模 PTM 后語言理解和語言生成任務上性能出現了顯著提升。
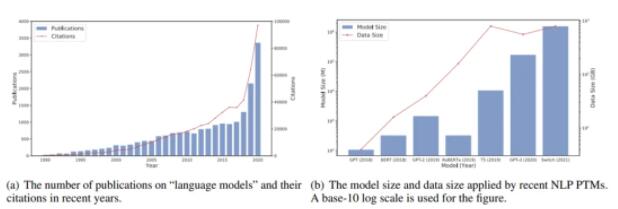
圖(a)近年來語言模型相關的發表文章的數量,圖(b)近年來應用 NLP PTM 后模型大小和數據大小的增長趨勢。
背景介紹
最近 PTM 引起了研究人員的關注,但預訓練并不是一種新穎的機器學習工具。事實上,預訓練作為機器學習的一種范式已經發展很多年了。本節介紹了 AI 領域中預訓練的發展,從早期監督預訓練到當前的自監督預訓練,了解這些有助于了解 PTM 的背景。
遷移學習和有監督預訓練
早期預訓練的研究主要涉及遷移學習。遷移學習的研究很大程度上是因為人們可以依靠以前學到的知識來解決新問題,甚至取得更好的結果。更準確的說,遷移學習旨在從多個源任務中獲取重要知識,然后將這些知識應用到目標任務中。
在遷移學習中,源任務和目標任務可能具有完全不同的數據域和任務設置,但處理這些任務所需的知識是一致的。一般來說,在遷移學習中有兩種預訓練方法被廣泛探索:特征遷移和參數遷移。
在一定程度上,表征遷移和參數遷移奠定了 PTM 的基礎。詞嵌入是在特征遷移框架下建立起來的,被廣泛應用于 NLP 任務的輸入。
自監督學習和自監督預訓練
如圖 4 所示,遷移學習可以分為四個子設置:歸納(inductive)遷移學習、transductive 遷移學習、自我(self-taught)學習和無監督遷移學習。
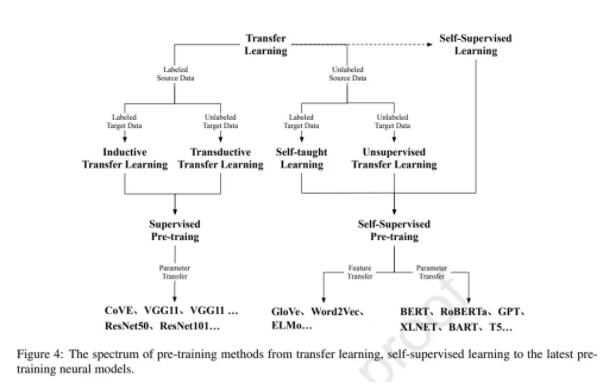
在這四種設置中,歸納和 transductive 設置是研究的核心,因為這兩種設置旨在將知識從有監督的源任務遷移到目標任務。
自監督學習和無監督學習在它們的設置上有許多相似之處。在一定程度上,自監督學習可以看作是無監督學習的一個分支,因為它們都適用于未標記的數據。然而,無監督學習主要側重于檢測數據模式(例如,聚類、社區發現和異常檢測),而自監督學習仍處于監督設置(例如分類和生成)的范式中。
自監督學習的發展使得對大規模無監督數據進行預訓練成為可能。與作為深度學習時代 CV 基石的監督預訓練相比,自監督預訓練在 NLP 領域取得了巨大進步。
隨著用于 NLP 任務的 PTM 的最新進展,基于 Transformer 的 PTM 作為 NLP 任務的主干已成為流程標準。受 NLP 中自監督學習和 Transformers 成功的啟發,一些研究人員探索了自監督學習和 Transformers 用于 CV 任務。這些初步努力表明,自監督學習和 Transformer 可以勝過傳統的有監督 CNN。
Transformer 和表征型 PTM
論文的第三部分從占主導地位的基本神經架構 Transformer 開始,然后介紹了兩個具有里程碑意義的基于 Transformer 的 PTM,GPT 和 BERT,它們分別使用自回歸語言建模和自編碼語言建模作為預訓練目標。這部分的最后簡要回顧了 GPT 和 BERT 之后的典型變體,以揭示 PTM 的最新發展。
Transformer
在 Transformer 之前,RNN 長期以來一直是處理序列數據(尤其是自然語言)的典型神經網絡。與 RNN 相比,Transformer 是一種編碼器 - 解碼器結構,它應用了自注意力機制,可以并行建模輸入序列的所有詞之間的相關性。
在 Transformer 的編碼和解碼階段,Transformer 的自注意力機制計算所有輸入詞的表征。下圖 5 給出了一個示例,其中自注意力機制準確地捕獲了「Jack」和「he」之間的參考關系,從而產生了最高的注意力分數。

由于突出的性質,Transformer 逐漸成為自然語言理解和生成的標準神經架構。
GPT
GPT 是第一個將現代 Transformer 架構和自監督預訓練目標結合的模型。實驗表明,GPT 在幾乎所有 NLP 任務上都取得了顯著的成功,包括自然語言推斷、問答等。
在 GPT 的預訓練階段,每個詞的條件概率由 Transformer 建模。如下圖 6 所示,對于每個詞,GPT 通過對其前一個詞應用多頭自注意力操作,再通過按位置的前饋層來計算其概率分布。
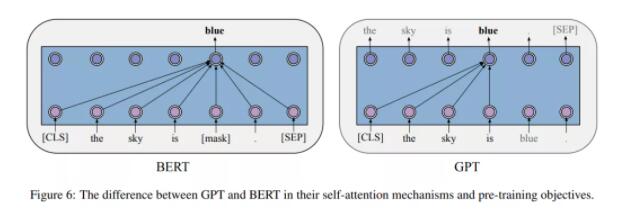
BERT
BERT 的出現也極大地推動了 PTM 領域的發展。理論上,不同于 GPT ,BERT 使用雙向深度 Transformer 作為主要結構。還有兩個獨立的階段可以使 BERT 適應特定任務,即預訓練和微調(如下圖 7 所示)。
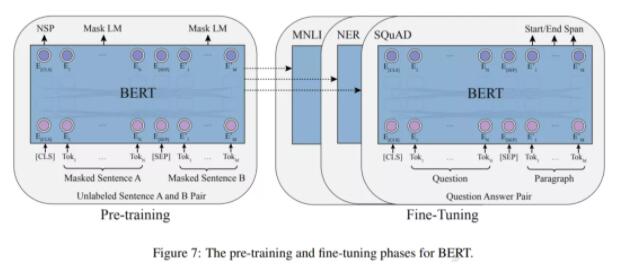
經過預訓練,BERT 可以獲得下游任務的穩健參數。GPT 之后,BERT 在 17 個不同的 NLP 任務上進一步取得了顯著的提升,包括 SQuAD(優于人類的表現)、GLUE(7.7% 的絕對提升)、MNLI(4.6% 的絕對提升)等。
GPT 和 BERT 之后
在 GPT 和 BERT 之后也出現了一些改進模型,例如 RoBERTa 和 ALBERT。
如下圖 8 所示,為了更好地從未標記的數據中獲取知識,除了 RoBERTa 和 ALBERT 之外,近年來還提出了各種 PTM。一些工作改進了模型架構并探索了新的預訓練任務,例如 XLNet、MASS、SpanBERT 和 ELECTRA。
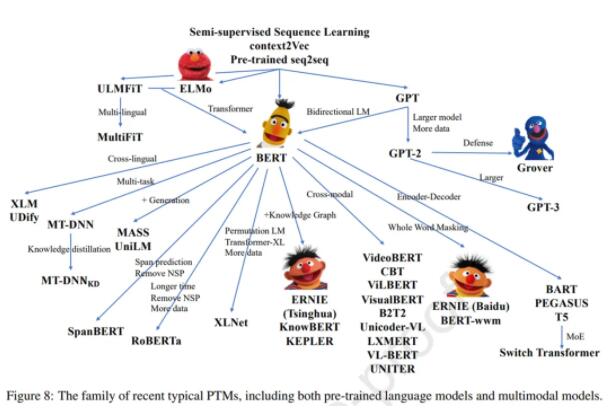
設計有效的架構
在這一部分中,論文更深入地探究了 after-BERT PTM。基于 Transformer 的 PTM 的成功激發了一系列用于自然語言及其他序列建模的新架構。一般來說,所有用于語言預訓練的 after-BERT Transformer 架構都可以被歸類為兩個動機:統一序列建模和認知啟發架構。此外,論文還在第三小節中簡述了其他重要的 BERT 變體,它們主要側重于改進自然語言理解。
統一序列建模
研究者發現,一系列新架構都在尋求將不同類型的語言任務與一個 PTM 統一起來。論文中闡述了這一方面的發展,并探討了它們為自然語言處理的統一帶來的靈感。
結合自回歸和自編碼建模,包括 XLNet (Yang 等, 2019) 和 MPNet (Song 等, 2020)。除了排列語言建模,還有一個方向是多任務訓練,例如 UniLM (Dong 等, 2019)。最近,GLM(Du 等,2021)提出了一種更優雅的方法來結合自回歸和自編碼。
有一些模型應用泛化的編碼器 - 解碼器,包括 MASS (Song 等, 2019)、T5 (Raffel 等, 2020)、BART (Lewis 等, 2020a) 以及在典型 seq2seq 任務中指定的模型,例如 PEGASUS (Zhang 等,2020a)和 PALM(Bi 等,2020 )。
受認知啟發的架構
為了追求人類水平的智能,了解我們認知功能的宏觀架構,包括決策、邏輯推理、反事實推理和工作記憶 (Baddeley, 1992) 至關重要。論文中概述了受認知科學啟發的新嘗試,并重點闡述了可維持的工作記憶和可持續的長期記憶。
可維持的工作記憶,包括基于 Transformer 的一些架構,例如 Transformer-XL (Dai 等, 2019)、CogQA (Ding 等, 2019) 和 CogLTX (Ding 等, 2020)。
可持續的長期記憶。REALM (Guu 等, 2020) 是探索如何為變形金剛構建可持續外部記憶的先驅。RAG (Lewis 等, 2020b) 將掩碼預訓練擴展到自回歸生成。
更多 PTM 變體
除了統一序列建模和構建受認知啟發的架構以外,當前大多數研究都集中在優化 BERT 的架構以提高語言模型在自然語言理解方面的性能。
一系列工作旨在改進掩碼策略,可以將其視為某種數據增強(Gu 等, 2020),包括 SpanBERT (Joshi 等, 2020)、ERNIE (Sun 等, 2019b,c)、NEZHA (Wei 等, 2019) 和 Whole Word Masking (Cui 等, 2019)。
另一個有趣的做法是將掩碼預測目標更改為更困難的目標,例如 ELECTRA(Clark 等,2020)。
利用多源數據
本節介紹了一些利用多源異構數據的典型 PTM,包括多語言 PTM、多模態 PTM 和知識增強型 PTM。
多語言預訓練
在大規模英語語料庫上訓練的語言模型在許多基準測試中取得了巨大成功。然而,我們生活在一個多語言的世界中,并且由于所需的成本和數據量,為每種語言訓練一個大型語言模型并不是一個最優的解決方案。因此,訓練一個模型來學習多語言表征而不是單語表征可能是更好的方法。
在 BERT 之前,一些研究人員已經探索了多語言表征。學習多語言表征主要有兩種方法:一種是通過參數共享來學習;另一種是學習與語言無關的約束。這兩種方式都使模型能夠應用于多語言場景,但僅限于特定任務。
BERT 的出現表明,先對一般的自監督任務進行預訓練,然后對特定的下游任務進行微調的框架是可行的。這促使研究人員設計任務來預訓練具有多功能的多語言模型。根據任務目標,多語言任務可分為理解任務和生成任務。
一些理解任務首先被用在非平行多語言語料庫上預訓練多語言 PTM。然而,MMLM( multilingual masked language modeling )任務不能很好地利用平行語料庫。
除了 TLM( translation language modeling ),還有一些其他有效的方法可以從平行語料庫中學習多語言表征,如 Unicoder(Huang et al.,2019a)、ALM(Yang et al.,2020)、InfoXLM(Chi et al.,2020b)、HICTL(Wei et al.,2021)和 ERNIE-M(Ouyang et al.,2020)。
此外,該研究還廣泛探索了多語言 PTM 的生成模型,如 MASS(Song et al,2019 年)、mBART(Liu et al,2020c)。
多模態預訓練
基于圖像 - 文本的 PTM,目前的解決方案是采用視覺 - 語言 BERT。ViLBERT(Lu et al,2019 年)是一個學習圖像和語言的 task-agnostic 聯合表征模型。它使用三個預訓練任務:MLM、句子 - 圖像對齊(SIA)和掩碼區域分類(MRC)。另一方面,VisualBERT(Li et al,2019 年)擴展了 BERT 架構。
一些多模態 PTM 設計用于解決特定任務,如 VQA。B2T2(Alberti et al,2019 年)是主要關注 VQA 的模型。LP(Zhou et al,2020a)專注于 VQA 和圖像字幕。此外,UNITER(Chen et al,2020e)學習兩種模式之間的統一表征。
OpenAI 的 DALLE (Ramesh et al., 2021) 、清華大學和 BAAI 的 CogView (Ding et al., 2021) 向條件零樣本圖像生成邁出了更大的一步。
最近,CLIP (Radford et al., 2021) 和 WenLan (Huo et al., 2021) 探索擴大網絡規模數據以進行 V&L 預訓練并取得了巨大成功。
增強知識預訓練
結構化知識的典型形式是知識圖譜。許多工作試圖通過集成實體和關系嵌入或其與文本的對齊來增強 PTM。
Wang et al.(2021) 基于維基數據實體描述的預訓練模型,將語言模型損失和知識嵌入損失結合在一起以獲得知識增強表征。一個有趣的嘗試是 OAGBERT (Liu et al., 2021a),它在 OAG(open academic graph) (Zhang et al., 2019a) 中集成了異構結構知識,并且涵蓋了 7 億個異構實體和 20 億個關系。
與結構化知識相比,非結構化知識更完整,但噪聲也更大。
六至八章內容概述
提升計算效率
研究者從以下三個方面介紹了如何提升計算效率:
- 系統級優化,包括單設備優化和多設備優化;
- 高效預訓練,包括高效訓練方法和高效模型架構;
- 模型壓縮,包括參數共享、模型剪枝、知識蒸餾和模型量化。
解釋和理論分析
在介紹了 PTM 在各種 NLP 任務上的卓越性能之外,研究者還花篇幅解釋了 PTM 的行為,包括理解 PTM 的工作方式,揭示 PTM 捕獲的模式。他們探索了 PTM 的幾個重要屬性——知識、穩健性和結構稀疏性 / 模塊性,還回顧了 PTM 理論分析方面的開創性工作。
關于 PTM 的知識,PTM 捕獲的隱式知識大致分為兩類,分別是語言知識和世界知識。關于 PTM 的穩健性,當研究人員為現實世界的應用部署 PTM 時,穩健性已經成為了一個嚴重的安全威脅。
未來方向
最后,研究者指出,在現有工作的基礎上,未來 PTM 可以從以下幾個方面得到進一步發展:
- 架構和預訓練方法
- 多語言和多模態預訓練
- 計算效率
- 理論基礎
- 模型邊緣學習
- 認知學習
- 新型應用。
事實上,研究社區在以上幾個方向上都做了大量努力,也取得了一些最新的進展。但應看到,還有一些問題需要得到進一步解決。
更多細節內容請參考原論文。



















