













終于有人把 Hadoop 生態的核心講明白了!
Hadoop是一個由Apache基金會開發的分布式系統基礎架構。開發人員可以在不了解分布式底層細節的情況下開發分布式程序,充分利用集群的威力進行高速并行運算以及海量數據的分布式存儲。Hadoop大數據技術架構如圖1所示。
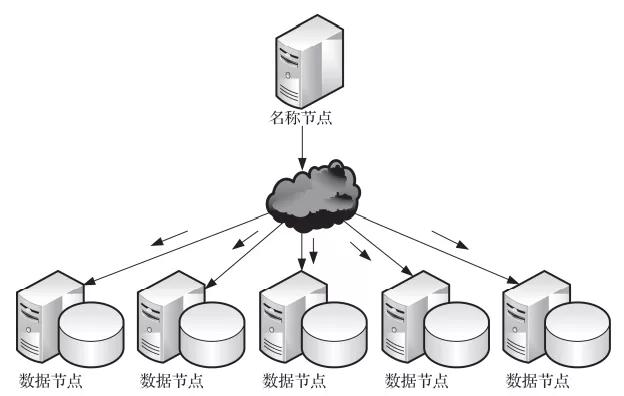
圖1 Hadoop大數據技術架構
然而,Hadoop不是一個孤立的技術,而是一套完整的生態圈,如圖2所示。在這個生態圈中,Hadoop最核心的組件就是分布式文件系統HDFS和分布式計算框架MapReduce。HDFS為海量的數據提供了存儲,是整個大數據平臺的基礎,而MapReduce則為海量的數據提供了計算能力。在它們之上有各種大數據技術框架,包括數據倉庫Hive、流式計算Storm、數據挖掘工具Mahout和分布式數據庫HBase。此外,ZooKeeper為Hadoop集群提供了高可靠運行的框架,保證Hadoop集群在部分節點宕機的情況下依然可靠運行。Sqoop與Flume分別是結構化與非結構化數據采集工具,通過它們可以將海量數據抽取到Hadoop平臺上,進行后續的大數據分析。
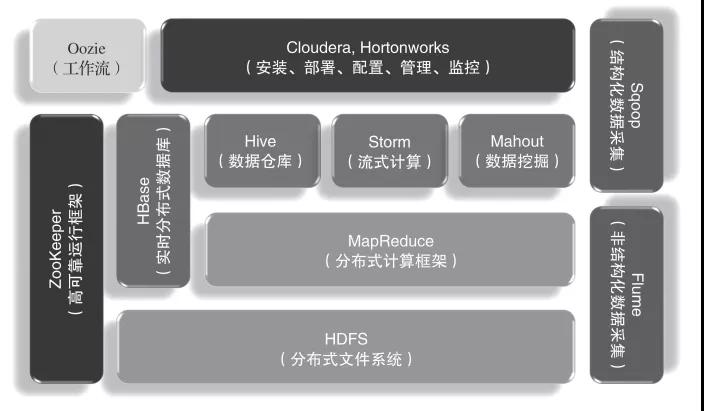
圖2 Hadoop大數據生態圈
Cloudera與Hortonworks是大數據的集成工具,它們將大數據技術的各種組件集成在一起,簡化安裝、部署等工作,并提供統一的配置、管理、監控等功能。Oozie是一個業務編排工具,我們將復雜的大數據處理過程解耦成一個個小腳本,然后用Oozie組織在一起進行業務編排,定期執行與調度。
01分布式文件系統
過去,我們用諸如DOS、Windows、Linux、UNIX等許多系統來在計算機上存儲并管理各種文件。與它們不同的是,分布式文件系統是將文件散列地存儲在多個服務器上,從而可以并行處理海量數據。
Hadoop的分布式文件系統HDFS如圖3所示,它首先將服務器集群分為名稱節點(NameNode)與數據節點(DataNode)。名稱節點是控制節點,當需要存儲數據時,名稱節點將很大的數據文件拆分成一個個大小為128MB的小文件,然后散列存儲在其下的很多數據節點中。當Hadoop需要處理這個數據文件時,實際上就是將其分布到各個數據節點上進行并行處理,使性能得到大幅提升。
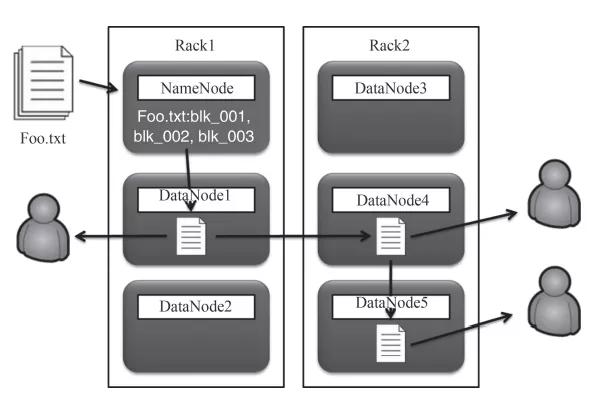
圖3 分布式文件系統HDFS
同時,每個小文件在存儲時,還會進行多節點復制(默認是3節點復制),一方面可以并行讀取數據,另一方面可以保障數據的安全,即任何一個節點失效,數據都不會丟失。當一個節點宕機時,如果該節點的數據不足3份,就會立即發起數據復制,始終保持3節點的復制。正因為具有這樣高可靠的文件存儲,Hadoop的部署不需要備份,也不需要磁盤鏡像,在Hadoop集群的各個節點中掛載大容量的磁盤并配置Raid0就可以了。
02分布式計算框架
Hadoop的另一個關鍵組件是分布式計算框架MapReduce,它將海量數據的處理分布到許多數據節點中并行進行,從而提高系統的運行效率。
MapReduce計算詞頻的處理過程如圖4所示。在這個過程中,首先輸入要處理的數據文件,經過Splitting將其拆分到各個節點中,并在這些節點的本地執行Mapping,將其制作成一個Map。不同的任務可以設計不同的Map。譬如,現在的任務是計算詞頻,因此該Map的key是不同的詞,value是1。這樣,在后續的處理過程中,將相同詞的1加在一起就是該詞的詞頻了。

圖4 分布式計算框架MapReduce
Mapping操作執行完以后,就開始Shuffling操作。它是整個執行過程中效率最差的部分,需要在各個節點間交換數據,將同一個詞的數據放到同一個節點上。如何有效地降低交換的數據量成為優化性能的關鍵。接著,在每個節點的本地執行Reducing操作,將同一個詞的這些1加在一起,就得到了詞頻。最后,將分布在各個節點的結果集中到一起,就可以輸出了。
整個計算有6個處理過程,那么為什么它的名字叫MapReduce呢?因為其他處理過程都被框架封裝了,開發人員只需要編寫Map和Reduce過程就能完成各種各樣的數據處理。這樣,技術門檻降低了,大數據技術得以流行起來。
03優缺點
與傳統的數據庫相比,MapReduce分布式計算雖然有無與倫比的性能優勢,但并不適用于所有場景。MapReduce沒有索引,它的每次計算都是“暴力全掃描”,即將整個文件的所有數據都掃描一遍。如果要分析的結果涉及該文件80%以上的數據,與關系型數據庫相比,能獲得非常優異的性能。如果只是為了查找該文件中的某幾十條記錄,那么它既耗費資源,性能也沒有關系型數據庫好。因此,MapReduce的分布式計算更適合在后臺對批量數據進行離線計算,即一次性對海量數據進行分析、整理與運算。它并不適用于在前臺面向終端用戶的在線業務、事務處理與隨機查詢。
同時,MapReduce更適合對大數據文件的處理,而不適合對海量小文件的處理。因此,當要處理海量的用戶文檔、圖片、數據文件時,應當將其整合成一個大文件(序列文件),然后交給MapReduce處理。唯有這樣才能充分發揮MapReduce的性能。
本文摘編自《架構真意:企業級應用架構設計方法論與實踐》,經出版方授權發布。




















