云原生大數據架構中實時計算維表和結果表的選型實踐
一、前言
傳統的大數據技術起源于 Google 三架馬車 GFS、MapReduce、Bigtable,以及其衍生的開源分布式文件系統 HDFS,分布式計算引擎 MapReduce,以及分布式數據庫 HBase。最初的大數據技術與需求往往集中在超大規模數據存儲、數據處理、在線查詢等。在這個階段,很多公司會選擇自建機房部署 Hadoop 的方式,大數據技術與需求集中在離線計算與大規模存儲上,常見的體現方式有 T+1 報表,大規模數據在線查詢等。
隨著互聯網技術的日漸發展、數據規模的擴大與復雜的需求場景的產生,傳統的大數據架構無法承載。大數據架構在近些年的演進主要體現下以下幾方面:
1. 規模化:這里的規模化主要體現在大數據技術的使用規模上和數據規模的增長。大數據技術的使用規模增長代表越來越多的復雜需求產生,而數據規模的增長決定了傳統的準大數據技術(如 MySQL)無法解決所有問題。因此,拿存儲組件舉例來說,通常會劃分到不同的數據分層,面向規模、成本、查詢和分析性能等不同維度的優化偏向,以滿足多樣性的需求。
2. 實時化:傳統的 T+1 的離線大數據技術無法滿足推薦、監控類近實時的需求,整個大數據生態和技術架構在過去十年發生了很大的升級換代。就存儲上來說,傳統的 HDFS 文件存儲、Hive 數倉無法滿足低成本,可更新迭代的需求,因此滋生出 Hudi 等數據方案。就計算上來說,傳統的 MapReduce 批處理的能力無法做到秒級的數據處理,先后出現 Storm 較原始的實時處理和 Spark Streaming 的微批處理,目前由 Flink 基于 Dataflow 模型的實時計算框架在實時計算領域占據絕對主導地位。
3. 云原生化:傳統的公司往往會選擇自建機房,或者在云上購買機器部署實例這種云托管的形式,但這種架構存在低谷期利用率低,存儲計算不分離導致的存儲和計算彈性差,以及升級靈活度低等各種問題。云原生大數據架構就是所謂的數據湖,其本質就是充分利用云上的彈性資源來實現一個統一管理、統一存儲、彈性計算的大數據架構,變革了傳統大數據架構基于物理集群和本地磁盤的計算存儲架構。其主要技術特征是存儲和計算分離和 Serverless。在云原生大數據架構中,每一層架構都在往服務化的趨勢演進,存儲服務化、計算服務化、元數據管理服務化等。每個組件都被要求拆分成不同的單元,具備獨立擴展的能力,更開放、更靈活、更彈性。
本篇文章將基于云原生大數據架構的場景,詳細討論實時計算中的維表和結果表的架構選型。
二、大數據架構中的實時計算
1、實時計算場景
大數據的高速發展已經超過 10 年,大數據也正在從計算規模化向更加實時化的趨勢演進。實時計算場景主要有以下幾種最常見的場景:
- 實時數倉:實時數倉主要應用在網站 PV / UV 統計、交易數據統計、商品銷量統計等各類交易型數據場景中。在這種場景下,實時計算任務通過訂閱業務實時數據源,將信息實時秒級分析,最終呈現在業務大屏中給決策者使用,方便判斷企業運營狀況和活動促銷的情況。
- 實時推薦:實時推薦主要是基于 AI 技術,根據用戶喜好進行個性化推薦。常見于短視頻場景、內容資訊場景、電商購物等場景。在這種場景下,通過用戶的歷史點擊情況實時判斷用戶喜好,從而進行針對性推薦,以達到增加用戶粘性的效果。
- 數據 ETL:實時的 ETL 場景常見于數據同步任務中。比如數據庫中不同表的同步、轉化,或者是不同數據庫的同步,或者是進行數據聚合預處理等操作,最終將結果寫入數據倉庫或者數據湖進行歸檔沉淀。這種場景主要是為后續的業務深度分析進行前期準備工作。
- 實時診斷:這種常見于金融類或者是交易類業務場景。在這些場景中,針對行業的獨特性,需要有反作弊監管,根據實時短時間之內的行為,判定用戶是否為作弊用戶,做到及時止損。該場景對時效性要求極高,通過實時計算任務對異常數據檢測,實時發現異常并進行及時止損。
2、Flink SQL 實時計算
實時計算需要后臺有一套極其強大的大數據計算能力,Apache Flink 作為一款開源大數據實時計算技術應運而生。由于傳統的 Hadoop、Spark 等計算引擎,本質上是批計算引擎,通過對有限的數據集進行數據處理,其處理時效性是不能保證的。而 Apache Flink ,從設計之初就以定位為流式計算引擎,它可以實時訂閱實時產生的流式數據,對數據進行實時分析處理并產生結果,讓數據在第一時間發揮價值。
Flink 選擇了 SQL 這種聲明式語言作為頂層 API,方便用戶使用,也符合云原生大數據架構的趨勢:
- 大數據普惠,規模生產:Flink SQL 能夠根據查詢語句自動優化,生成最優的物理執行計劃,屏蔽大數據計算中的復雜性,大幅降低用戶使用門檻,以達到大數據普惠的效果。
- 流批一體:Flink SQL 具備流批統一的特性,無論是流任務還是批處理任務都給用戶提供相同的語義和統一的開發體驗,方便業務離線任務轉實時。
- 屏蔽底層存儲差異:Flink 通過提供 SQL 統一查詢語言,屏蔽底層數據存儲的差異,方便業務在多樣性的大數據存儲中進行靈活切換,對云上大數據架構進行更開放、靈活的調整。
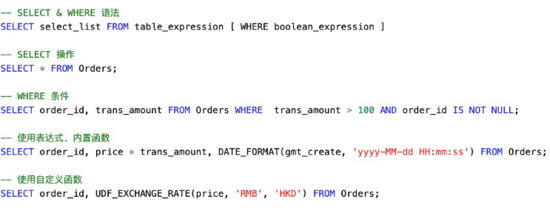
上圖是 Flink SQL 的一些基本操作。可以看到 SQL 的語法和標準 SQL 非常類似,示例中包括了基本的 SELECT、FILTER 操作,可以使用內置函數(如日期的格式化),也可以在注冊函數后使用自定義函數。
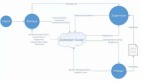
Flink SQL 將實時計算拆分成源表,結果表和維表三種,將這三種表的 DDL 語句(比如 CREATE TABLE)注冊各類輸入、輸出的數據源,通過 SQL 的 DML(比如 INSERT INTO)表示實時計算任務的拓撲關系,以達到通過 SQL 完成實時計算任務開發的效果。
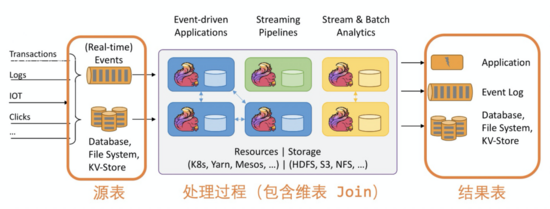
- 源表:主要代表消息系統類的輸入,比如 Kafka,MQ(Message Queue),或者 CDC(Change Data Capture,例如將 MySQL binlog 轉換成實時流)輸入。
- 結果表:主要代表 Flink 將每條實時處理完的數據寫入的目標存儲,如 MySQL,HBase 等數據庫。
- 維表:主要代表存儲數據維度信息的數據源。在實時計算中,因為數據采集端采集到的數據往往比較有限,在做數據分析之前,就要先將所需的維度信息補全,而維表就是代表存儲數據維度信息的數據源。常見的用戶維表有 MySQL,Redis 等。
下圖是一個完整的實時計算示例,示例中的 Flink SQL 任務,這個任務的目標是計算每分鐘不同商品分類的 GMV (Gross Merchandise Volume,即商品交易總額)。在這個任務中,Flink 實時消費用戶訂單數據的 Kafka 源表,通過 Redis 維表將商品 id 關聯起來獲取到商品分類,按照 1 分鐘間隔的滾動窗口按商品分類將總計的交易金額計算出來,將最后的結果寫入 RDS(Relational Database Service,如 MySQL) 結果表中。
- # 源表 - 用戶訂單數據,代表某個用戶(user_id)在 timestamp 時按 price 的價格購買了商品(item_id)
- CREATE TEMPORARY TABLE user_action_source (
- `timestamp` BIGINT,
- `user_id` BIGINT,
- `item_id` BIGINT,
- `price` DOUBLE,SQs
- ) WITH (
- 'connector' = 'kafka',
- 'topic' = '<your_topic>',
- 'properties.bootstrap.servers' = 'your_kafka_server:9092',
- 'properties.group.id' = '<your_consumer_group>'
- 'format' = 'json',
- 'scan.startup.mode' = 'latest-offset'
- );
- # 維表 - 物品詳情
- CREATE TEMPORARY TABLE item_detail_dim (
- id STRING,
- catagory STRING,
- PRIMARY KEY (id) NOT ENFORCED
- ) WITH (
- 'connector' = 'redis',
- 'host' = '<your_redis_host>',
- 'port' = '<your_redis_port>',
- 'password' = '<your_redis_password>',
- 'dbNum' = '<your_db_num>'
- );
- # 結果表 - 按時間(分鐘)和分類的 GMV 輸出
- CREATE TEMPORARY TABLE gmv_output (
- time_minute STRING,
- catagory STRING,
- gmv DOUBLE,
- PRIMARY KEY (time_minute, catagory)
- ) WITH (
- type='rds',
- url='<your_jdbc_mysql_url_with_database>',
- tableName='<your_table>',
- userName='<your_mysql_database_username>',
- password='<your_mysql_database_password>'
- );
- # 處理過程
- INSERT INTO gmv_output
- SELECT
- TUMBLE_START(s.timestamp, INTERVAL '1' MINUTES) as time_minute,
- d.catagory,
- SUM(d.price) as gmv
- FROM
- user_action_source s
- JOIN item_detail_dim FOR SYSTEM_TIME AS OF PROCTIME() as d
- ON s.item_id = d.id
- GROUP BY TUMBLE(s.timestamp, INTERVAL '1' MINUTES), d.catagory;
這是一個很常見的實時計算的處理鏈路。后續章節中,我們將針對實時計算的維表和結果表的關鍵能力進行展開分析,并分別進行架構選型的討論。
三、實時計算維表
1、關鍵需求
在數據倉庫的建設中,一般都會圍繞著星型模型和雪花模型來設計表關系或者結構。實時計算也不例外,一種常見的需求就是為數據流補齊字段。因為數據采集端采集到的數據往往比較有限,在做數據分析之前,就要先將所需的維度信息補全。比如采集到的交易日志中只記錄了商品 id,但是在做業務時需要根據店鋪維度或者行業緯度進行聚合,這就需要先將交易日志與商品維表進行關聯,補全所需的維度信息。這里所說的維表與數據倉庫中的概念類似,是維度屬性的集合,比如商品維度、用戶度、地點維度等等。
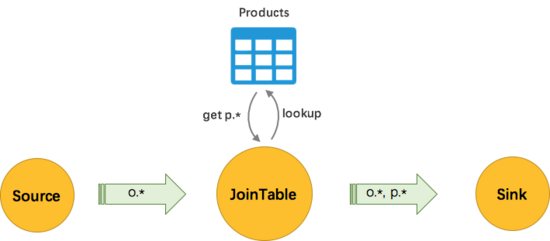
作為保存用戶維度信息的數據存儲,需要應對實時計算場景下的海量低延時訪問。根據這樣的定位,我們總結下對結構化大數據存儲的幾個關鍵需求:
(1)高吞吐與低延時的讀取能力
首當其沖,在不考慮開源引擎 Flink 自身維表的優化外,維表必須能承擔實時計算場景下的海量(上萬 QPS)的數據訪問,也能在極低(毫秒級別)的延時下返回查詢數據。
(2)與計算引擎的高整合能力
在維表自身的能力之外,出于性能、穩定性和成本的考慮,計算引擎自身往往也會有些流量卸載的能力,在一些情況下無需每次請求都需要去訪問下游維表。例如,Flink 在維表場景下支持 Async IO 和緩存策略等優化特性。 一個比較好的維表需要和開源計算引擎有著較高程度的對接,一方面可以提升計算層的性能,一方面也可以有效的卸載部分流量,保障維表不被過多訪問擊穿,并降低維表的計算成本。
(3)輕存儲下的計算能力的彈性
維表通常是一張共享表,存儲維度屬性等元數據信息,訪問規模往往較大,而存儲規模往往不會特別大。對維表的訪問規模極大地依賴實時數據流的數據量。比如,如果實時流的數據規模擴大了數十倍,此時對維表的訪問次數會大大提升;又比如,如果新增了多個實時計算任務訪問該維表,該維表的查詢壓力會激增。在這些場景下,存儲規模往往不會顯著增加。
所以,計算最好是按需的,是彈性的。無論是新增或者下線實時計算任務,或者增加訪問流量,都不會影響訪問性能。同時,計算和存儲是應該分離的,不會單純因為訪問計算量的激增就增加存儲成本。
2、架構選型
MySQL
大數據和實時計算技術起步之初,互聯網早期大量流行 LAMP (Linux + Apache + MySQL + PHP)架構快速開發站點。因此,由于業務歷史數據已經存在 MySQL 中,在最初的實時計算維表選型中大量使用 MySQL 作為維表。
隨著大數據架構的更新,MySQL 云上架構也在不斷改進,但在維表的應用場景下仍然存在以下問題:
- 存儲側擴展靈活性差,擴展成本較高:MySQL 在存儲側的擴展需要進行數據復制遷移,擴展周期長且靈活性差。同時 MySQL 的分庫分表每次擴展需要雙倍資源,擴展成本較高。
- 存儲成本高:關系數據庫是結構化數據存儲單位成本最高的存儲系統,所以對于大數據場景來說,關系型數據庫存儲成本較高。
以上這些限制使 MySQL 在大數據維表場景下存在性能瓶頸,成本也比較高。但總體來說,MySQL 是非常優秀的數據庫產品,在數據規模不怎么大的場景下,MySQL 絕對是個不錯的選擇。
Redis
在云上應用架構中,由于 MySQL 難以承載不斷增加的業務負載,往往會使用 Redis 作為 MySQL 的查詢結果集緩存,幫助 MySQL 來抵御大部分的查詢流量。
在這種架構中,MySQL 作為主存儲服務器,Redis 作為輔助存儲,MySQL 到 Redis 的同步可以通過 binlog 實時同步或者 MySQL UDF + 觸發器的方式實現。在這種架構中,Redis 可以用來緩存提高查詢性能,同時降低 MySQL 被擊穿的風險。
由于在 Redis 中緩存了一份弱一致性的用戶數據,Redis 也常常用來作為實時計算的維表。相比于 MySQL 作為維表,Redis 有著獨特的優勢:
- 查詢性能極高:數據高速緩存在內存中,可以通過高速 Key-Value 形式進行結果數據查詢,非常符合維表高性能查詢的需求。
- 存儲層擴展靈活性高:Redis 可以非常方便的擴展分片集群,進行橫向擴展,支持數據多副本的持久化。
Redis 有其突出的優點,但也有一個不可忽視的缺陷:雖然 Redis 有著不錯的擴展方案,但由于高速緩存的數據存在內存中,成本較高,如果遇到業務數據的維度屬性較大(比如用戶維度、商品維度)時,使用 Redis 作為維表存儲時成本極高。
Tablestore
Tablestore是阿里云自研的結構化大數據存儲產品,具體產品介紹可以參考 官網 以及 權威指南 。在大數據維表的場景下,Tablestore 有著獨特的優勢:
- 高吞吐訪問:Tablestore 采用了存儲計算分離架構,可以彈性擴展計算資源,支持高吞吐下的數據查詢。
- 低延時查詢:Tablestore 按照 LSM 存儲引擎實現,支持 Block Cache 加速查詢,用戶也通過配置豐富的索引,優化業務查詢。
- 低成本存儲和彈性計算成本:在存儲成本上,Tablestore 屬于結構化 NoSQL 存儲類型,數據存儲成本比起關系型數據庫或者高速緩存要低很多;在計算成本上,Tablestore 采用了存儲計算架構,可以按需彈性擴展計算資源。
- 與 Flink 維表優化的高度對接:Tablestore 支持 Flink 維表優化的所有策略,包括 Async IO 和不同緩存策略。
方案對比
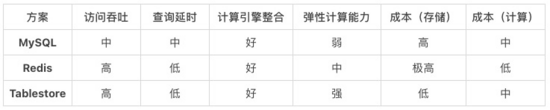
上面是前文提到的幾個維表方案在各個維度的對比。接下來,將舉幾個具體的場景細致對比下成本:
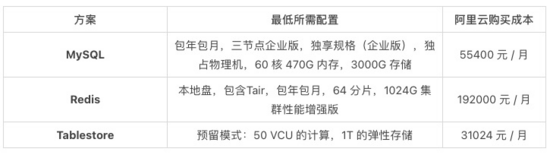
1. 高存儲高計算:維表需要存 100 億條訂單維度的數據,總計存儲量需要 1T,盡管業務在 Flink 任務端配置了緩存策略,但仍然有較高的 KV 查詢下沉到維表,到維表的 QPS 峰值 10 萬,均值 2.5 萬。不同維表所需的配置要求和購買成本如下:
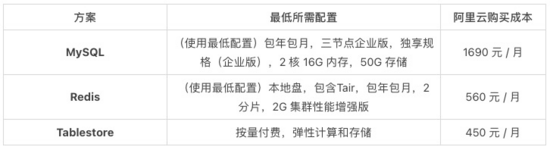
2. 低存儲低計算:維表需要存 100 萬條地域維度的數據,總計存儲量需要 10M,業務端在 Flink 任務中的維表配置了 LRU 緩存策略抵御了絕大部分的流量,到維表的 QPS 峰值 1000 均值 250。不同維表所需的配置要求和購買成本如下:
3. 高存儲低計算:維表需要存 100 億條訂單維度的數據,總計存儲量需要 1T,業務端在 Flink 任務中的維表配置了 LRU 緩存策略抵御了絕大部分的流量,到維表的 QPS 峰值 1000 均值 250。不同維表所需的配置要求和購買成本如下:

4. 低存儲高計算:Redis 作為內存數據庫,具有超高頻的數據 KV 查詢能力,僅 4 核 8G 內存的 Redis集群,即可支持 16 萬 QPS的并發訪問,成本預計 1600 元 / 月,在低存儲高計算場景有著鮮明的成本優勢。
從上面的成本對比報告中可見:
1)MySQL 由于缺乏存儲和計算的彈性,以及關系型數據庫固有的缺點,在不同程度的存儲和計算規模下成本均較高。
2)Redis 作為內存數據庫,在低存儲(約 128G 以下)高計算場景有著鮮明的成本優勢,但由于內存存儲成本很高、缺乏彈性,隨著數據規模的提升,成本呈指數增長。
3)Tablestore 基于云原生架構可以按量對存儲和計算進行彈性,在數據存儲和訪問規模不大時成本較低。
4)Tablestore 作為 NoSQL 數據庫存儲成本很低,在高存儲(128G 以上)場景下有著鮮明的成本優勢。
四、實時計算結果表
1、需求分析
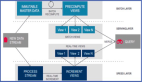
結果表作為實時計算完成后數據導入的存儲系統,主要可分為關系數據庫、搜索引擎、結構化大數據離線存儲、結構化大數據在線存儲幾種分類,具體差異通過以下表格進行了歸納。
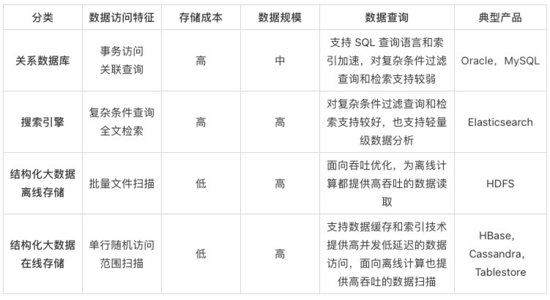
對于這幾種數據產品,在各自場景下各有優勢,起源的先后也各有不同。為了方便探究,我們將問題域縮小,僅僅考慮實時計算的場景下,一個更好的結果表存儲需要承擔什么樣的角色。
上文提到了實時計算的主要幾個場景中,實時數倉,實時推薦,實時監控三個場景需要考慮結果表的選型。我們一一分析。
- 實時數倉:實時數倉主要應用在網站實時 PV / UV 統計、交易數據統計等實時分析場景。實時分析(即OLAP)場景分為預聚合、搜索引擎和 MPP(Massively Parallel Processing,即大規模并行處理)三種 OLAP 模型。對于預聚合模型來說,可以通過 Flink 計算層進行數據聚合寫入結果表,也可以全量寫入結果表中,通過結果表自身的預聚合能力進行數據存儲,在這種形態中極大地依賴結果表數據查詢與分析能力的支撐。對于搜索引擎模型來說,數據將全量寫入結果表中,通過搜索引擎的倒排索引和列存特性進行數據分析,在這種形態中需要結果表有高吞吐的數據寫入能力和大規模數據存儲能力。MPP 模型是計算引擎,如果訪問的是列式存儲,可以更好地發揮分析查詢特性。實時 OLAP 存儲和計算引擎眾多,在一個完整的數據系統架構下,需要有多個存儲組件并存。并且根據對查詢和分析能力的不同要求,需要數據派生派生能力在必要時擴展到其他類型存儲。另外,實時數倉中隨著業務規模的擴大,存儲量會大幅增長,相較來說數據查詢等計算規模變化一般不會特別明顯,所以結果表需要做到存儲和計算成本分離,極大地控制資源成本。
- 實時推薦:實時推薦主要是根據用戶喜好進行個性化推薦,在常見的用戶商品個性化推薦場景下,一種常見的做法是將用戶的特征寫入結構化大數據存儲(如 HBase )中,而該存儲將作為維表另一條用戶點擊消費行為數據進行關聯,提取出用戶特征與行為關聯輸入,作為推薦算法的輸入。這里的存儲既需要作為結果表提供高吞吐的數據寫入能力,也需要作為維表提供高吞吐低延時的數據在線查詢能力。
- 實時監控:應用的實時監控常見于金融類或者是交易類業務場景,該場景對時效性要求極高,通過對異常數據檢測,可以實時發現異常情況而做出一個止損的行為。在這種場景下無論是通過閾值進行判斷還是通過異常檢測算法,都需要實時低延時的數據聚合查詢能力。
2、關鍵能力
通過以上的需求分析,我們可以總結出幾項實時大數據結果表的關鍵能力:
1. 大規模數據存儲
結果表存儲的定位是集中式的大規模存儲,作為在線數據庫的匯總,或者是實時計算(或者是離線)的輸入和輸出,必須要能支撐 PB 級規模數據存儲。
2. 豐富的數據查詢與聚合分析能力
結果表需要擁有豐富的數據查詢與聚合分析能力,需要為支撐高效在線查詢做優化。常見的查詢優化包括高速緩存、高并發低延遲的隨機查詢、復雜的任意字段條件組合查詢以及數據檢索。這些查詢優化的技術手段就是緩存和索引,其中索引的支持是多元化的,面向不同的查詢場景提供不同類型的索引。例如面向固定組合查詢的基于 B+tree 的二級索引,面向地理位置查詢的基于 R-tree 或 BKD-tree 的空間索引或者是面向多條件組合查詢和全文檢索的倒排索引。
3. 高吞吐寫入能力
實時計算的數據表需要能承受大數據計算引擎的海量結果數據集導出。所以必須能支撐高吞吐的數據寫入,通常會采用一個為寫入而優化的存儲引擎。
4. 數據派生能力
一個完整的數據系統架構下,需要有多個存儲組件并存。并且根據對查詢和分析能力的不同要求,需要在數據派生體系下對存儲進行動態擴展。所以對于大數據存儲來說,也需要有能擴展存儲的派生能力,來擴展數據處理能力。而判斷一個存儲組件是否具備更好的數據派生能力,就看是否具備成熟的 CDC 技術。
5. 云原生架構:存儲與計算成本分離
在云原生大數據架構中,每一層架構都在往服務化的趨勢演進,存儲服務化、計算服務化、元數據管理服務化等。每個組件都被要求拆分成不同的單元,作為結果表也不例外,需要具備獨立擴展的能力,更開放、更靈活、更彈性。
單就從結果表來說,只有符合云原生架構的組件,即基于存儲計算分離架構實現的產品,才能做到存儲和計算成本的分離,以及獨立擴展。存儲和計算分離的優勢,在大數據系統下會更加明顯。舉一個簡單的例子,結構化大數據存儲的存儲量會隨著數據的積累越來越大,但是數據寫入量是相對平穩的。所以存儲需要不斷的擴大,但是為了支撐數據寫入或臨時的數據分析而所需的計算資源,則相對來說比較固定,是按需的。
3、架構選型
MySQL
和維表一樣,大數據和實時計算技術起步之初,MySQL 是一個萬能存儲,幾乎所有需求都可以通過 MySQL 來完成,因此應用規模非常廣,結果表也不例外。隨著數據規模的不斷擴展和需求場景的日漸復雜,MySQL 有點難以承載,就結果表的場景下主要存在以下問題:
1. 大數據存儲成本高:這個在之前討論維表時已經提到,關系數據庫單位存儲成本非常高。
2. 單一存儲系統,提供的查詢能力有限:隨著數據規模的擴大,MySQL 讀寫性能的不足問題逐漸顯現了出來。另外,隨著分析類 AP 需求的產生,更適合 TP 場景的 MySQL 查詢能力比較有限。
3. 高吞吐數據寫入能力較差:作為 TP 類的關系型數據庫,并不是特別擅長高吞吐的數據寫入。
4. 擴展性差,擴展成本較高:這個在之前討論維表時已經提到,MySQL 在存儲側的擴展需要進行數據復制遷移,且需要雙倍資源,因此擴展靈活性差,成本也比較高。
以上這些限制使 MySQL 在大數據結果表場景下存在性能瓶頸,成本也比較高,但作為關系型數據庫,不是特別適合作為大數據的結果表使用。
HBase
由于關系型數據庫的天然瓶頸,基于 BigTable 概念的分布式 NoSQL 結構化數據庫應運而生。目前開源界比較知名的結構化大數據存儲是 Cassandra 和 HBase,Cassandra 是 WideColumn 模型 NoSQL 類別下排名 Top-1 的產品,在國外應用比較廣泛。這篇文章中,我們重點提下在國內應用更多的 HBase。 HBase 是基于 HDFS 的存儲計算分離架構的 WideColumn 模型數據庫,擁有非常好的擴展性,能支撐大規模數據存儲,它的優點為:
1. 大數據規模存儲,支持高吞吐寫入:基于 LSM 實現的存儲引擎,支持大規模數據存儲,并為寫入優化設計,能提供高吞吐的數據寫入。
2. 存儲計算分離架構:底層基于 HDFS,分離的架構可以按需對存存儲和計算分別進行彈性擴展。
3. 開發者生態成熟,與其他開源生態整合較好:作為發展多年的開源產品,在國內也有比較多的應用,開發者社區很成熟,與其他開源生態如 Hadoop,Spark 整合較好。
HBase有其突出的優點,但也有幾大不可忽視的缺陷:
1. 查詢能力弱,幾乎不支持數據分析:提供高效的單行隨機查詢以及范圍掃描,復雜的組合條件查詢必須使用 Scan + Filter 的方式,稍不注意就是全表掃描,效率極低。HBase 的 Phoenix 提供了二級索引來優化查詢,但和 MySQL 的二級索引一樣,只有符合最左匹配的查詢條件才能做索引優化,可被優化的查詢條件非常有限。
2. 數據派生能力弱:前面章節提到 CDC 技術是支撐數據派生體系的核心技術,HBase 不具備 CDC 技術。
3. 非云原生 Serverless 服務模式,成本高:前面提到結構化大數據存儲的關鍵需求之一是存儲與計算的成本分離,HBase 的成本取決于計算所需 CPU 核數成本以及磁盤的存儲成本,基于固定配比物理資源的部署模式下 CPU 和存儲永遠會有一個無法降低的最小比例關系。即隨著存儲空間的增大,CPU 核數成本也會相應變大,而不是按實際所需計算資源來計算成本。因此,只有云原生的 Serverless 服務模式,才要達到完全的存儲與計算成本分離。
4. 運維復雜:HBase 是標準的 Hadoop 組件,最核心依賴是 Zookeeper 和 HDFS,沒有專業的運維團隊幾乎無法運維。
國內的高級玩家大多會基于 HBase 做二次開發,基本都是在做各種方案來彌補 HBase 查詢能力弱的問題,根據自身業務查詢特色研發自己的索引方案,例如自研二級索引方案、對接 Solr 做全文索引或者是針對區分度小的數據集的 bitmap 索引方案等等。總的來說,HBase 是一個優秀的開源產品,有很多優秀的設計思路值得借鑒。
HBase + Elasticsearch
為了解決 HBase 查詢能力弱的問題,國內很多公司通過 Elasticsearch 來加速數據檢索,按照 HBase + Elasticsearch 的方案實現他們的架構。其中,HBase 用于做大數據存儲和歷史冷數據查詢,Elasticsearch 用于數據檢索,其中,由于 HBase 不具備 CDC 技術,所以需要業務方應用層雙寫 HBase 和 Elasticsearch,或者啟動數據同步任務將 HBase 同步至 Elasticsearch。
這個方案能通過 Elasticsearch 極大地補足 HBase 查詢能力弱的問題,但由于 HBase 和 Elasticsearch 本身的一些能力不足,會存在以下幾個問題:
1. 開發成本高,運維更加復雜:客戶要維護至少兩套集群,以及需要完成 HBase 到 Elasticsearch 的數據同步。如果要保證 HBase 和 Elasticsearch 的一致性,需要通過前文提到的應用層多寫的方式,這不是解耦的架構擴展起來比較復雜。另外整體架構比較復雜,涉及的模塊和技術較多,運維成本也很高。
2. 成本很高:客戶需要購買兩套集群,以及維護 HBase 和 Elasticsearch 的數據同步,資源成本很高。
3. 仍沒有數據派生能力:這套架構中,只是將數據分別寫入 HBase 和 Elasticsearch 中,而 HBase 和 Elasticsearch 均沒有 CDC 技術,仍然無法靈活的將數據派生到其他系統中。
Tablestore
Tablestore 是阿里云自研的結構化大數據存儲產品,具體產品介紹可以參考 官網 以及 權威指南 。Tablestore 的設計理念很大程度上顧及了數據系統內對結構化大數據存儲的需求,并且基于派生數據體系這個設計理念專門設計和實現了一些特色的功能。簡單概括下 Tablestore 的技術理念:
1. 大規模數據存儲,支持高吞吐寫入:LSM 和 B+ tree 是主流的兩個存儲引擎實現,其中 Tablestore 基于 LSM 實現,支持大規模數據存儲,專為高吞吐數據寫入優化。
2. 通過多元化索引,提供豐富的查詢能力:LSM 引擎特性決定了查詢能力的短板,需要索引來優化查詢。而不同的查詢場景需要不同類型的索引,所以 Tablestore 提供多元化的索引來滿足不同類型場景下的數據查詢需求。
3. 支持 CDC 技術,提供數據派生能力:Tablestore 的 CDC 技術名為 Tunnel Service,支持全量和增量的實時數據訂閱,并且能無縫對接 Flink 流計算引擎來實現表內數據的實時流計算。
4. 存儲計算分離架構:采用存儲計算分離架構,底層基于飛天盤古分布式文件系統,這是實現存儲計算成本分離的基礎。
5. 云原生架構,Serverless 產品形態,免運維:云原生架構的最關鍵因素是存儲計算分離和 Serverless 服務化,只有存儲計算分離和 Serverless 服務才能實現一個統一管理、統一存儲、彈性計算的云原生架構。由于是 Serverless 產品形態,業務方無需部署和維護 Tablestore,極大地降低用戶的運維成本。
方案對比
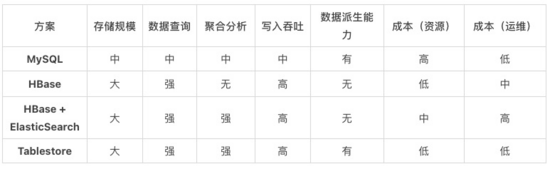
舉一個具體的場景,結果表需要存千億級別的電商訂單交易數據,總計存儲量需要 1T,用戶需要對于這類數據進行查詢與靈活的分析。日常訂單查詢與數據檢索頻率為 1000 次/秒,數據分析約每分鐘查詢 10 次左右。
以下是不同架構達到要求所需的配置,以及在阿里云上的購買成本:

五、總結
本篇文章談了云原生大數據架構下的實時計算維表和結果表場景下的架構設計與選型。其中,阿里云 Tablestore 在這些場景下有一些特色功能,希望能通過本篇文章對我們有一個更深刻的了解。