













錯誤率減半需要超過500倍算力!深度學習的未來,光靠燒錢能行嗎?
本文轉自雷鋒網,如需轉載請至雷鋒網官網申請授權。
深度學習的誕生,可以追溯到1958年。
那一年,時任康奈爾大學航空實驗室研究心理學家與項目工程師的 Frank Rosenblatt 受到大腦神經元互連的啟發,設計出了第一個人工神經網絡,并將其稱為一項"模式識別設備"。
這項設備完成后,被嫁接在龐大的 IBM 704 計算機中,經過50次試驗,能夠自動區分標志在左邊或右邊的卡片。這使 Frank Rosenblatt 倍感驚喜,他寫道:
"能夠創造出一臺具有人類品質的機器,一向是科幻小說的熱門題材,而我們即將見著這樣一臺能夠感知、并在沒有任何人工控制的情況下識別周圍環境的機器的誕生。"
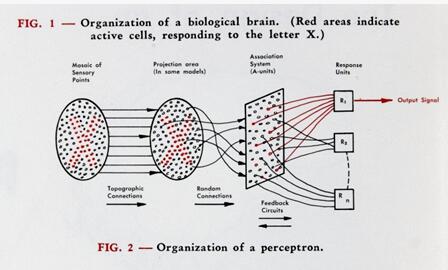
圖注:感知機的運作原理
不過,與此同時,Frank Rosenblatt 也深知,當時的計算機能力無法滿足神經網絡的運算需求。在他的開創性工作中,他曾感嘆:"隨著神經網絡中的連接數量不斷增加……傳統數字計算機的負載將會越來越重。"
圖注:Frank Rosenblatt。2004年,IEEE特地成立了"IEEE Frank Rosenblatt Award",以表紀念
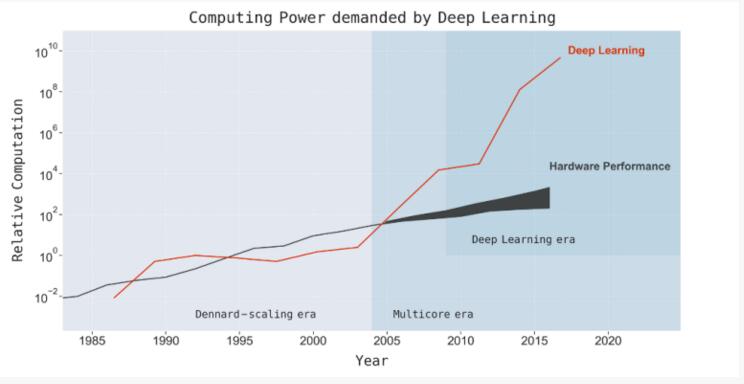
所幸,經過數十年的發展,在摩爾定律與其他計算機硬件的改進加持下,計算機的計算能力有了質的飛躍,每秒可執行的計算量增加了1000萬倍,人工神經網絡才有了進一步發展的空間。得益于計算機的強大算力,神經網絡擁有了更多的連接與神經元,也具備了更大的、對復雜現象建模的能力。這時,人工神經網絡新增了額外的神經元層,也就是我們熟知的"深度學習"。
如今,深度學習已被廣泛應用于語言翻譯、預測蛋白質折疊、分析醫學掃描與下圍棋等任務。神經網絡在這些應用中的成功,使深度學習一項默默無名的技術,成為了如今計算機科學領域的領頭羊。
但是,今天的神經網絡/深度學習似乎又遇到了與數十年前一致的發展瓶頸:計算能力的限制。
近日,IEEE Spectrum 發表了一篇論文,對深度學習的發展未來進行了一番探討。為什么算力會成為當今深度學習的瓶頸?可能的應對方法是什么?如果實在無法解決計算資源的限制,深度學習應該何去何從?
1、算力:福兮,禍之所倚
深度學習被譽為現代人工智能的主流。早期,人工智能系統是基于規則,應用邏輯與專業知識來推理出結果;接著,人工智能系統是依靠學習來設置可調參數,但參數量通常有限。
今天的神經網絡也學習參數值,但這些參數是計算機模型的一部分:如果參數足夠大,它們會成為通用的函數逼近器,可以擬合任何類型的數據。這種靈活性使得深度學習能被應用于不同領域。
神經網絡的靈活性來源于(研究人員)將眾多輸入饋送到模型中,然后網絡再以多種方式將它們組合起來。這意味著,神經網絡的輸出是來自于復雜公式的應用,而非簡單的公式。也就是說,神經網絡的計算量會很大,對計算機的算力要求也極高。
比方說,Noisy Student(一個圖像識別系統)在將圖像的像素值轉換為圖像中的物體概率時,它是通過具有 4.8 億個參數的神經網絡來實現。要確定如此大規模參數的值的訓練更是讓人瞠目結舌:因為這個訓練的過程僅用了 120 萬張標記的圖像。如果聯想到高中代數,我們會希望得到更多的等式,而非未知數。但在深度學習方法中,未知數的確定才是解決問題的關鍵。
深度學習模型是過度參數化的,也就是說,它們的參數量比可用于訓練的數據點還要多。一般來說,過度參數也會導致過度擬合,這時,模型不僅僅會學習通用的趨勢,還會學習訓練數據的隨機變幻。為了避免過度擬合,深度學習的方法是將參數隨機初始化,然后使用隨機梯度下降方法來迭代調整參數集,以更好地擬合數據。實驗證明,這個方法能確保已學習的模型具有良好的泛化能力。
深度學習模型的成功在機器翻譯中可見一斑。數十年來,人們一直使用計算機軟件進行文本翻譯,從語言 A 轉換為語言 B。早期的機器翻譯方法采用的是語言學專家設計的規則。但是,隨著一項語言的可用文本數據越來越多,統計方法,比如最大熵、隱馬爾可夫模型與條件隨機場等方法,也逐漸應用在機器翻譯中。
最初,每種方法對不同語言的有效性由數據的可用性和語言的語法特性決定。例如,在翻譯烏爾都語、阿拉伯語和馬來語等語言時,基于規則的方法要優于統計方法。但現在,所有這些方法都已被深度學習超越。凡是深度學習已觸及的領域,幾乎都展示了這項機器學習方法的優越性。
一方面,深度學習有很強的靈活性;但另一方面,這種靈活性是基于巨大的計算成本的。
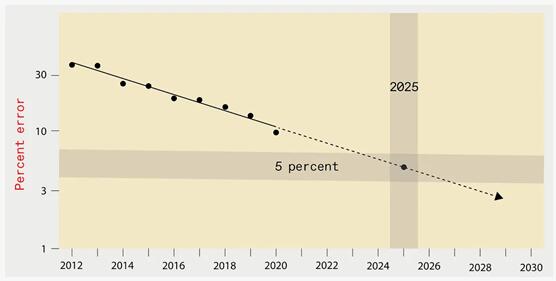
如下圖顯示,根據已有研究,到2025年,為識別 ImageNet 數據集中的目標物體而設計的最佳深度學習系統的錯誤水平應該降低到僅 5%:
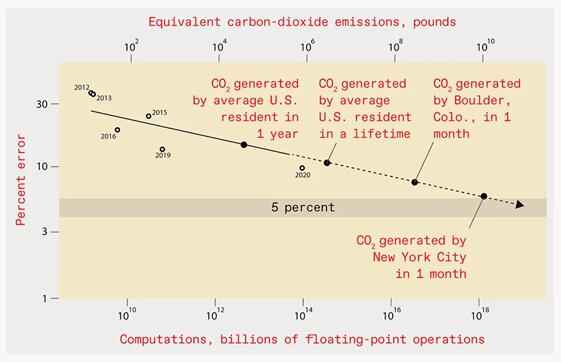
但是,訓練這樣一個系統所需的計算資源和能耗卻是巨大的,排放的二氧化碳大約與紐約市一個月所產生的二氧化碳一樣多:
計算成本的提升,主要有兩方面的原因:1)要通過因素 k 來提高性能,至少需要 k 的 2 次方、甚至更多的數據點來訓練模型;2)過度參數化現象。一旦考慮到過度參數化的現象,改進模型的總計算成本至少為 k 的 4 次方。這個指數中的小小的“4”非常昂貴:10 倍的改進,就至少需要增加 10,000 倍計算量。
如果要在靈活性與計算需求之間取一個平衡點,請考慮一個這樣的場景:你試圖通過患者的 X 射線預測 TA 是否患有癌癥。進一步假設,只有你在 X 射線中測量 100 個細節(即“變量”或“特征”),你才能找到正確的答案。這時,問題的挑戰就變成了:我們無法提前判斷哪些變量是重要的,與此同時,我們又要在大量的候選變量中做選擇。
基于專家知識的系統在解決這個問題時,是讓有放射科與腫瘤學知識背景的人來標明他們認為重要的變量,然后讓系統只檢查這些變量。而靈活的深度學習方法則是測試盡可能多的變量,然后讓系統自行判斷哪些變量是重要的,這就需要更多的數據,而且也會產生更高的計算成本。
已經由專家事先確認重要變量的模型能夠快速學習最適合這些變量的值,并且只需少量的計算——這也是專家方法(符號主義)早期如此流行的原因。但是,如果專家沒有正確標明應包含在模型中的所有變量,模型的學習能力就會停滯。
相比之下,像深度學習這樣的靈活模型雖然效率更低,且需要更多的計算來達到專家模型的性能,但通過足夠的計算(與數據),靈活模型的表現卻可以勝過專家模型。
顯然,如果你使用更多的計算能力來構建更大的模型,并使用更多數據訓練模型,那么你就可以提升深度學習的性能。但是,這種計算負擔會變得多昂貴?成本是否會高到阻礙進展?這些問題仍有待探討。
2、深度學習的計算消耗
為了更具體地回答這些問題,來自MIT、韓國延世大學與巴西利亞大學的研究團隊(以下簡稱“該團隊”)合作,從1000多篇研究深度學習的論文中搜集數據,并就深度學習在圖像分類上的應用進行了詳細探討。

論文地址:https://arxiv.org/pdf/2007.05558.pdf
在過去的幾年,為了減少圖像分類的錯誤,計算負擔也隨之增大。比如,2012 年,AlexNet 模型首次展示了在圖形處理單元 (GPU) 上訓練深度學習系統的能力:僅僅 AlexNet 的訓練就使用了兩個 GPU、進行了五到六天的訓練。到了 2018 年,NASNet-A 將 AlexNet 的錯誤率降低了一半,但這一性能的提升代價是增加了 1000 多倍的計算。
從理論上講,為了提升模型的性能,計算機的算力至少要滿足模型提升的 4 次方。但實際情況是,算力至少要提升至 9 次方。這 9 次方意味著,要將錯誤率減半,你可能需要 500 倍以上的計算資源。
這是一個毀滅性的代價。不過,情況也未必那么糟糕:現實與理想的算力需求差距,也許意味著還有未被發現的算法改進能大幅提升深度學習的效率。
該團隊指出,摩爾定律和其他硬件的進步極大地提高了芯片的性能。這是否意味著計算需求的升級無關緊要?很不幸,答案是否定的。AlexNet 和 NASNet-A 所使用的計算資源相差了 1000,但只有 6 倍的改進是來自硬件的改進;其余則要依靠更多的處理器,或更長的運行時間,這也就產生了更高的計算成本。
通過估計圖像識別的計算成本與性能曲線后,該團隊估計了需要多少計算才能在未來達到更出色的性能基準。他們估計的結果是,降低 5% 的錯誤率需要 10190 億次浮點運算。
2019年,馬薩諸塞大學阿默斯特分校的團隊發表了“Energy and Policy Considerations for Deep Learning in NLP”的研究工作,便首次揭示了計算負擔背后的經濟代價與環境代價,在當時引起了巨大轟動。

論文地址:https://arxiv.org/pdf/1906.02243.pdf
此前,DeepMind也曾披露,在訓練下圍棋的深度學習系統時花了大約 3500 萬美元。Open AI 在訓練 GPT-3時,也耗資超過400萬美元。后來,DeepMind在設計一個系統來玩星際爭霸 2 時,就特地避免嘗試多種方法來構建一個重要的組建,因為訓練成本實在太高了。
除了科技企業,其他機構也開始將深度學習的計算費用考慮在內。一家大型的歐洲連鎖超市最近便放棄了一個基于深度學習的系統。該系統能顯著提高超市預測要購買哪些產品的能力,但公司高管放棄了這一嘗試,因為他們認為訓練和運行系統的成本太高。
面對不斷上升的經濟和環境成本,深度學習的研究者需要找到一個完美的方法,既能提高性能,又不會導致計算需求激增。否則,深度學習的發展很可能就此止步。
3、現有的解決方法
針對這個問題,深度學習領域的研究學者也在不斷努力,希望能解決這個問題。
現有的策略之一,是使用專為高效深度學習計算而設計的處理器。這種方法在過去十年中被廣泛使用,因為 CPU 已讓位于 GPU,且在某種情況下,CPU 已讓位于現場可編程門陣列和為特定應用設計的 IC(包括谷歌的TPU)。
從根本上說,這些方法都犧牲了計算平臺的通用性來提高專門處理一類問題的效率。但是,這種專業化也面臨著收益遞減的問題。因此,要獲取長期收益將需要采用完全不同的硬件框架——比如,可能是基于模擬、神經形態、光子或量子系統的硬件。但到目前為止,這些硬件框架都還沒有產生太大的影響。
另一種減少計算負擔的方法是生成在執行時規模更小的神經網絡。這種策略會降低每次的使用成本,但通常會增加訓練成本。使用成本與訓練成本,哪一個更重要,要取決于具體情況。對于廣泛使用的模型,運行成本在投資總額中的占比最高。至于其他模型,例如那些經常需要重新訓練的模型,訓練成本可能是主要的。在任何一種情況下,總成本都必須大于訓練成本。因此,如果訓練成本太高,那么總成本也會很高。也就是說,第二種策略(減少神經網絡規模)的挑戰是:它們并沒有充分降低訓練成本。
比如,有一種方法是允許訓練大規模網絡、但代價是在訓練過程中會降低復雜性,還有一種方法是訓練一個大規模網絡、然后"修剪"掉不必要的連接。但是,第二種方法是通過跨多個模型進行優化來找到盡可能高效的架構,也就是所謂的“神經架構搜索”。雖然每一種方法都可以為神經網絡的運行帶來明顯提升,但對訓練的作用都不大,不足以解決我們在數據中看到的問題。但是,在大部分情況下,它們都會增加訓練的成本。
有一種可以降低訓練成本的新興技術,叫做“元學習”。元學習的觀點是系統同時學習各種各樣的數據,然后應用于多個領域。比如,元學習不是搭建單獨的系統來識別圖像中的狗、貓和汽車,而是訓練一個系統來識別圖像中的所有物體,包括狗、貓和汽車,且可以多次使用。
但是,MIT 的研究科學家 Andrei Barbu 與他的合作者在2019年發表了一項工作(“Objectnet: A large-scale bias-controlled dataset for pushing the limits of object recognition models”),揭示了元學習的難度。他們發現,即使原始數據與應用場景之間存在極小差距,也會嚴重降低模型(Objectnet)的性能。他們的工作證明,當前的圖像識別系統在很大程度上取決于物體是以特定的角度拍攝,還是以特定的姿勢拍攝。所以,即使是識別不同姿勢拍攝的相同物體,也會導致系統的準確度幾乎減半。
UC Berkeley 的副教授 Benjamin Recht 等人在“Do imagenet classifiers generalize to imagenet?”(2019)中也明確地說明了這一點:即使使用專門構建的新數據集來模仿原始訓練數據,模型的性能也會下降 10% 以上。如果數據的微小變化會導致性能的大幅下降,那么整個元學習系統所需的數據可能會非常龐大。因此,元學習的前景也暫時未能實現。雷鋒網
還有一種也許能擺脫深度學習計算限制的策略是轉向其他可能尚未發現或未被重視的機器學習類型。如前所述,基于專家的洞察力所構建的機器學習系統在計算上可以更高效,但如果這些專家無法區分所有影響因素,那么專家模型的性能也無法達到與深度學習系統相同的高度。與此同時,研究人員也在開發神經符號方法與其他技術,以將專家知識、推理與神經網絡中的靈活性結合起來。雷鋒網
不過,這些努力都仍在進行中。雷鋒網(公眾號:雷鋒網)
正如 Frank Rosenblatt 在神經網絡誕生之初所面臨的難題一樣,如今,深度學習也受到了可用計算工具的限制。面對計算提升所可能帶來的經濟和環境負擔,我們的出路只有:要么調整深度學習的方式,要么直面深度學習停滯的未來。
相形之下,顯然調整深度學習更可取。
如能找到一種方法,使深度學習更高效,或使計算機硬件更強大,那么我們就能繼續使用這些靈活性更高的深度學習模型。如果不能突破計算瓶頸,也許我們又要重返符號主義時代,依靠專家知識來確定模型需要學習的內容了。





















