圖靈獎得主 Geoffrey Hinton 和谷歌研究院的幾位研究者近日提出了一個用于目標檢測的簡單通用框架 Pix2Seq。與顯式集成相關任務先驗知識的現有方法不同,該框架簡單地將目標檢測轉換為以觀察到的像素輸入為條件的語言建模任務。其中,將對目標的描述(例如邊界框和類標簽)表示為離散 token 的序列,并且該研究還訓練神經網絡來感知圖像并生成所需的序列。

論文地址:https://arxiv.org/abs/2109.10852
該方法主要基于一種直覺,即如果神經網絡知道目標的位置和內容,那么就只需要教它如何讀取目標。除了使用特定于任務的數據增強之外,該方法對任務做出了最少的假設。但在 COCO 數據集上的測試結果表明,新方法完全可以媲美高度專業化和優化過的檢測算法。
Pix2Seq 框架
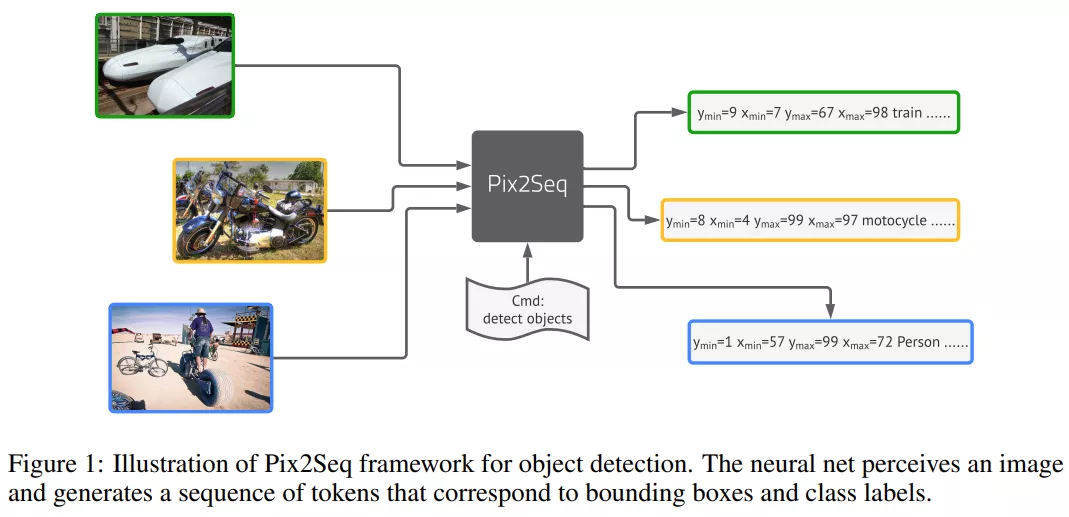
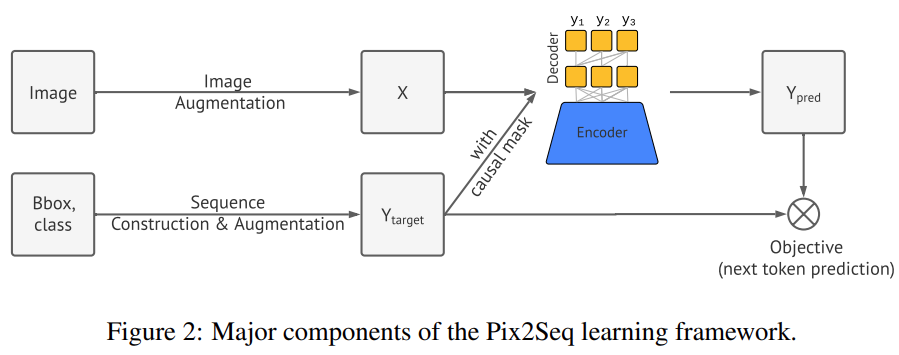
該研究提出的 Pix2Seq 框架將目標檢測作為語言建模任務,其中以像素輸入為條件。上圖所描述的 Pix2Seq 架構和學習過程有四個主要組成部分,如下圖 2 所示,包括:
- 圖像增強:在訓練計算機視覺模型中很常見,該研究使用圖像增強來豐富一組固定的訓練樣例(例如,隨機縮放和剪裁)。
- 序列構建和增強:由于圖像的目標注釋通常表征為一組邊界框和類標簽,該研究將它們轉換為離散 token 的序列。
- 架構:該研究使用編碼器 - 解碼器的模型架構,其中編碼器感知像素輸入,解碼器生成目標序列(一次一個 token)。
- 目標 / 損失函數:該模型經過訓練以最大化 token 的對數似然。
基于目標描述的序列構建
在常見的目標檢測數據集中,例如 Pascal VOC、COCO 等,圖像中往往具有數量不一的目標,這些目標被表征一組邊界框和類標簽,Pix2Seq 將它們表示為離散 token 的序列。
類標簽自然地被表示為離散 token,但邊界框不是。邊界框由其兩個角點(即左上角和右下角)或其中心點加上高度和寬度確定。該研究提出離散化用于指定角點的 x、y 坐標的連續數字。具體來說,一個目標被表征為一個由 5 個離散的 token 組成的序列,即 [y_min, x_min, y_max, x_max, c],其中每個連續的角坐標被均勻地離散為[1, n_bins] 之間的一個整數,c 為類索引。該研究對所有 token 使用共享詞表,因此詞匯量大小等于 bin 的數量 + 類(class)的數量。邊界框的這種量化方案使得在實現高精度的同時僅使用較小的詞匯量。例如,一張 600×600 的圖像只需要 600 個 bin 即可實現零量化誤差。這比具有 32K 或更大詞匯量的現代語言模型小得多。不同級別的量化對邊界框的影響如下圖 3 所示。

鑒于每個目標的描述表達為一個短的離散序列,接下來需要將多個目標的描述序列化,以構建一個給定圖像的單一序列。因為目標的順序對于檢測任務本身并不重要,因此研究者使用了一種隨機排序策略(每次顯示圖像時目標的順序是隨機化的)。此外,他們也探索了其他確定性排序策略,但是假設隨機排序策略和任何確定性排序是一樣有效的,給定一個可用的神經網絡和自回歸模型(在這里,網絡可以學習根據觀察到的目標來為剩余目標的分布建模)。
最后,因為不同的圖像通常有不同的目標數量,所生成的序列會有不同的長度。為了表示序列的結束,研究者合并了一個 EOS token。
下圖 4 展示了使用不同排序策略的序列構建過程。

架構、目標和推理
此處把從目標描述構建的序列作為一種「方言」來處理,轉向在語言建模中行之有效的通用體系架構和目標函數。
這里使用了一種編解碼器架構。編碼器可以是通用的感知像素圖像編碼器,并將它們編碼成隱藏的表征形式,比如 ConvNet (LeCun et al. ,1989; Krizhevsky et al. ,2012; He et al. ,2016) ,Transformer (Vaswani et al. ,2017; Dosovitskiy et al. ,2020) ,或者它們的組合(Carion et al. ,2020)。
在生成上,研究者使用了廣泛用于現代語言建模 (Radford 等人,2018; Raffel 等人,2019) 的 Transformer 解碼器。它每次生成一個 token,取決于前面的 token 和編碼的圖像表征。這消除了目標檢測器結構中的復雜性和自定義,例如邊界框提名(bounding box proposal)和邊界框回歸(bounding box regression),因為 token 是由一個帶 softmax 的單詞表生成的。
與語言建模類似,給定一個圖像和前面的 token,Pix2Seq 被訓練用來預測 token,其具有最大似然損失,即
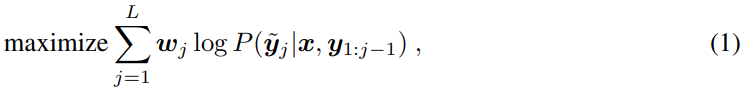
其中 x 是給定的圖像,y 和 y^~ 分別是相關的輸入序列和目標序列,l 是目標序列長度。在標準語言建模中,y 和 y^~ 是相同的。此外,wj 是序列中為 j-th token 預先分配的權重。我們設置 wj = 1,something j,但是可以根據 token 的類型 (如坐標 vs 類 token) 或相應目標的大小來權重 token。
在推理過程中,研究者從模型似然中進行了 token 采樣,即
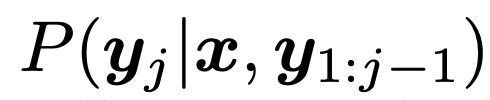
。也可以通過使用最大似然性 (arg max 采樣) 的 token,或者使用其他隨機采樣技術來實現。研究者發現使用核采樣 (Holtzman et al., 2019) 比 arg max 采樣 (附錄 b) 更能提高召回率。在生成 EOS token 時,序列結束。一旦序列生成,它直接提取和反量化了目標描述(即獲得預測邊界框和類標簽)。
序列增強
EOS token 會允許模型決定何時終止,但在實踐中,發現模型往往在沒預測所有目標的情況下終止。這可能是由于:
- 注釋噪音(例如,注釋者沒有標識所有的目標) ;
- 識別或本地化某些目標時的不確定性。因為召回率和準確率對于目標檢測來說都很重要,一個模型如果沒有很好的召回率就不可能獲得很好的整體性能(例如,平均準確率)。
獲得更高召回率的一個技巧是通過人為地降低其可能性來延遲 EOS token 的采樣。然而,這往往會導致噪聲和重復預測。
序列增強引入的修改如下圖 5 所示,詳細情況如下:

研究者首先通過以下兩種方式創建合成噪聲目標來增加輸入序列:
- 向現有的地面真值目標添加噪聲(例如,隨機縮放或移動它們的包圍盒) ;
- 生成完全隨機的邊框(帶有隨機相關的類標簽)。值得注意的是,其中一些噪聲目標可能與一些 ground-truth 目標相同或重疊,模擬噪聲和重復預測,如下圖 6 所示。

變化推理。使用序列增強,研究者能夠大幅度地延遲 EOS token,提升召回率,并且不會增加噪聲和重復預測的頻率,因此,他們令模型預測到最大長度,產生一個固定大小的目標列表。當從生成的序列中提取邊界框和類標簽時,研究者用在所有真實類標簽中具有最高似然的真實類標簽替換噪聲類標簽。他們還使用選定類標簽的似然作為目標的排名分數。
實驗結果
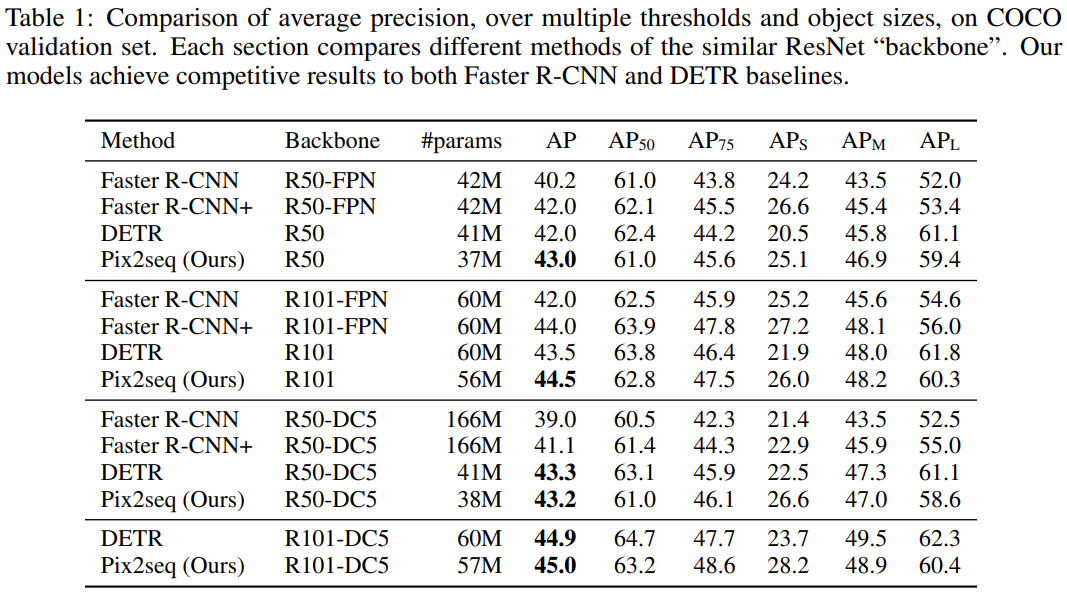
研究者主要與兩個被廣泛認可的基線方法進行比較,分別是 Facebook AI 于 2020 年提出的 DETR 和更早期的 Faster R-CNN。
結果如下表 1 所示,Pix2Seq 實現了媲美這兩個基線方法的性能,其中在小型和中型目標上的表現與 R-CNN 相當,但在大型目標上表現更好。與 DETR 相比,Pix2Seq 在中型和大型目標上表現相當或略差,但在小型目標上表現明顯更好(4-5 AP)。
序列構成的消融實驗
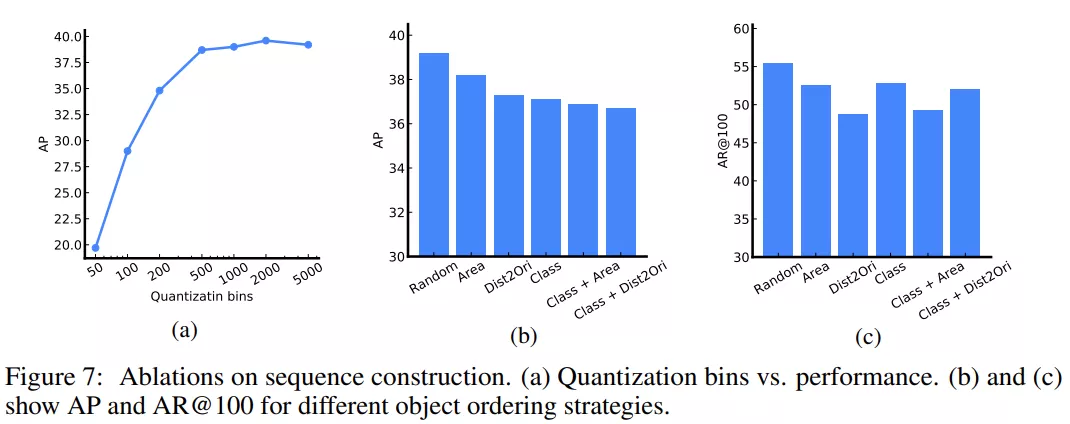
下圖 7a 探索了坐標量化對性能的影響。在這一消融實驗中,研究者考慮使用了 640 像素的圖像。該圖表表明量化至 500 或以上 bin 就足夠了,500 個 bin(每個 bin 大約 1.3 個像素)時不會引入顯著的近似誤差。事實上,只要 bin 的數量與像素數(沿著圖像的最長邊)一樣多,就不會出現由邊界框坐標量化導致的顯著誤差。
訓練期間,研究者還考慮了序列構成中的不同目標排序策略。這些包括 1)隨機、2)區域(即目標大小遞減)、3)dist2ori(即邊界框左上角到原點的距離)、4)類(名稱)、5)類+區域(即目標先按類排序,如果同類有多個目標,則按區域排序)、6)類+dist2ori。
下圖 7b 展示了平均精度(AP),7c 展示了 top-100 預測的平均召回率(AR)。在精度和召回率這兩方面,隨機排序均實現了最佳性能。研究者推測,使用確定性排序,模型可能難以從先前流失目標的錯誤中恢復過來,而使用隨機排序,則可以在之后檢索到它們。
增強的消融實驗
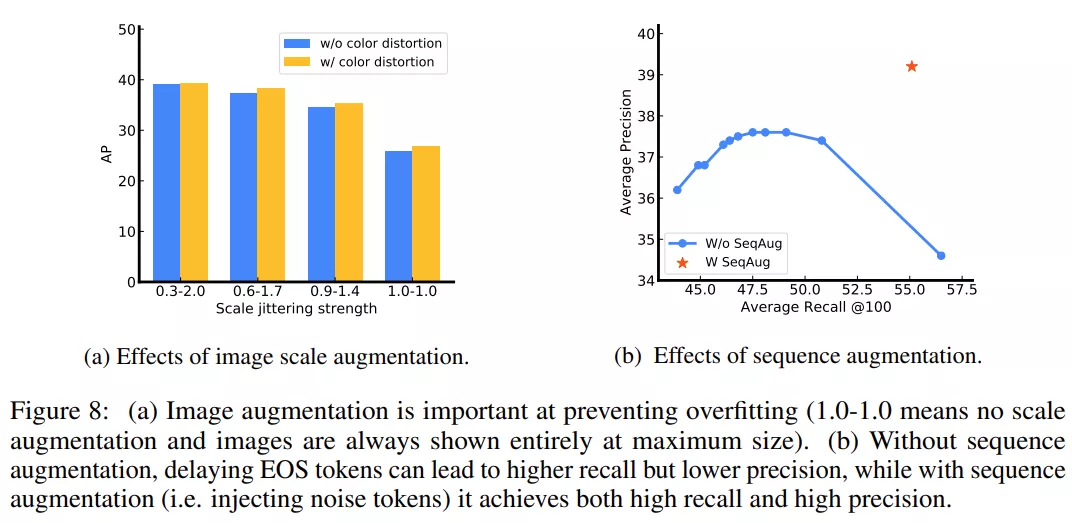
研究者主要使用的圖像增強方法是尺度抖動(scale jittering),因此比較了不同的尺度抖動強度(1:1 表示無尺度抖動)。下圖 8a 展示了模型在沒有合適尺度抖動時會出現過擬合(即驗證 AP 低但訓練 AP 高)。研究者預計,強大的圖像增強在這項研究中非常有用,這是因為 Pix2Seq 框架對任務做了最小假設。
研究者還探究了「使用和不使用序列增強訓練」的模型性能變化。對于未使用序列增強訓練的模型,他們在推理過程中調整 EOS token 似然的偏移量,以運行模型做更多預測,從而產生一系列召回率。如下圖 8b 所示,在無序列增強時,當 AR 增加時,模型會出現顯著的 AP 下降。使用序列增強時,模型能夠避免噪聲和重復預測,實現高召回率和高精度。
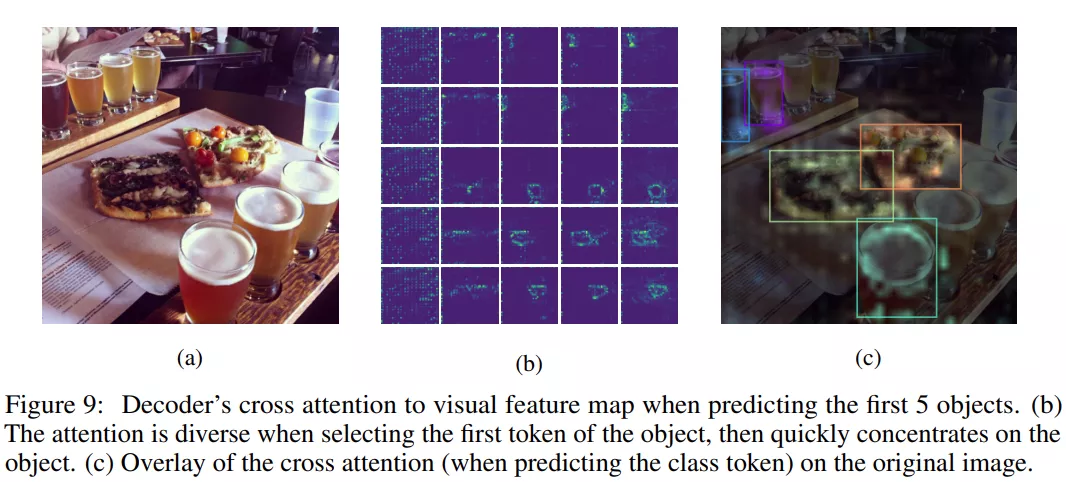
解碼器交叉注意力地圖的可視化
在生成一個新的 token 時,基于 Transformer 的解碼器在前面的 token 上使用自注意力,在編碼的視覺特征圖上使用交叉注意力。研究者希望在模型預測新的 token 時可視化交叉注意力(層和頭的平均值)。
下圖 9 展示了生成前幾個 token 時的交叉注意力圖,可以看到,在預測首個坐標 token(即 y_min)時,注意力呈現出了非常強的多樣性,但隨后很快集中并固定在目標上。
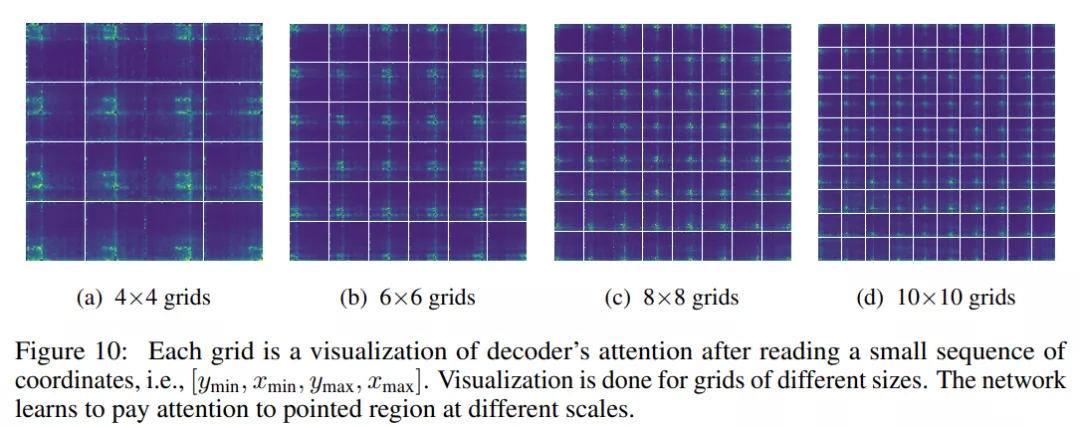
研究者進一步探索了模型「通過坐標關注指定區域」的能力。他們將圖像均勻地劃分為 N×N 的矩形區域網格,每個區域由邊界框的序列坐標制定。然后在讀取每個區域的坐標序列之后,他們將解碼器的注意力在視覺特征圖上實現可視化。最后,他們打亂圖像的像素以消除對現有目標的干擾,并為了清晰起見消除了 2%的 top 注意力。
有趣的是,如下圖 10 所示,模型似乎可以在不同的尺度上關注制定區域。