













北大林宙辰團(tuán)隊(duì)全新混合序列建模架構(gòu)MixCon:性能遠(yuǎn)超Mamba
在自然語言處理、語音識(shí)別和時(shí)間序列分析等眾多領(lǐng)域中,序列建模是一項(xiàng)至關(guān)重要的任務(wù)。然而,現(xiàn)有的模型在捕捉長程依賴關(guān)系和高效建模序列方面仍面臨諸多挑戰(zhàn)。
因此,北京大學(xué)林宙辰、徐鑫提出了一種全新混合序列建模架構(gòu) ——MixCon,它為解決這些難題帶來了創(chuàng)新性的方案。經(jīng)實(shí)驗(yàn)驗(yàn)證,其性能遠(yuǎn)超 Mixtral、Mamba 和 Jamba。論文已在 European Conference on Artificial Intelligence (ECAI) 2024 上發(fā)表。
- 論文標(biāo)題:MixCon: A Hybrid Architecture for Efficient and Adaptive Sequence Modeling
- 論文地址:https://zhouchenlin.github.io/Publications/2024-ECAI-MixCon.pdf
一、現(xiàn)有序列建模模型的困境
線性注意力 Transformer
線性注意力 Transformer 旨在通過近似注意力機(jī)制來提高原始 Transformer 模型的效率,將計(jì)算復(fù)雜度從 降低到
降低到 或
或 ,但在處理長序列時(shí)可能會(huì)面臨性能下降和計(jì)算開銷增加的問題。
,但在處理長序列時(shí)可能會(huì)面臨性能下降和計(jì)算開銷增加的問題。
例如,早期利用局部敏感哈希方案雖降低復(fù)雜度,但引入大常數(shù)因子;近期通過改變計(jì)算順序等方法近似 Softmax 函數(shù),但仍存在性能不如 Softmax 注意力且可能增加額外開銷的情況。
線性 RNN 模型
線性 RNN 模型如 Mamba 等通過將序列表示為狀態(tài)空間并利用掃描操作,以線性時(shí)間復(fù)雜度提供了序列建模的新解決方案。
然而,它們可能缺乏復(fù)雜序列建模任務(wù)所需的適應(yīng)性和動(dòng)態(tài)特性,并且像傳統(tǒng)序列模型一樣,缺少反饋機(jī)制和自適應(yīng)控制。
MoE 模型
MoE 模型通過結(jié)合專家模塊,能有效處理長序列并保持計(jì)算效率,根據(jù)輸入數(shù)據(jù)自適應(yīng)選擇專家模塊。
但 MoE 模型的專家模塊稀疏激活可能導(dǎo)致訓(xùn)練穩(wěn)定性問題,部分參數(shù)不常使用降低參數(shù)效率,在處理長序列時(shí)可能在計(jì)算效率和訓(xùn)練穩(wěn)定性方面面臨挑戰(zhàn),且對(duì)動(dòng)態(tài)變化適應(yīng)性不足。
二、MixCon 的核心架構(gòu)與技術(shù)
Conba 模型架構(gòu)
1. 狀態(tài)空間方程
Conba 將序列建模任務(wù)表示為狀態(tài)空間系統(tǒng),狀態(tài)空間定義為 和
和 ,其中
,其中 、
、 和
和 分別為時(shí)間步
分別為時(shí)間步 的狀態(tài)、輸入和輸出,
的狀態(tài)、輸入和輸出, 和
和 是非線性函數(shù),可由神經(jīng)網(wǎng)絡(luò)近似。
是非線性函數(shù),可由神經(jīng)網(wǎng)絡(luò)近似。
 ,其中
,其中 和
和 是可學(xué)習(xí)參數(shù)矩陣。
是可學(xué)習(xí)參數(shù)矩陣。 ,
, 是可學(xué)習(xí)參數(shù)矩陣。
是可學(xué)習(xí)參數(shù)矩陣。
為處理長序列,Conba 采用選擇性狀態(tài)空間機(jī)制 ,以及引入延遲狀態(tài)
,以及引入延遲狀態(tài) 和動(dòng)態(tài)狀態(tài)縮放機(jī)制
和動(dòng)態(tài)狀態(tài)縮放機(jī)制 。
。
最后狀態(tài)空間系統(tǒng)表示為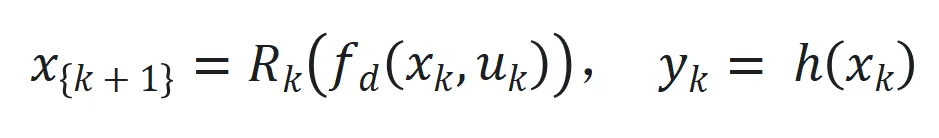 來捕捉長程依賴和適應(yīng)序列動(dòng)態(tài)變化。
來捕捉長程依賴和適應(yīng)序列動(dòng)態(tài)變化。
2. 自適應(yīng)控制機(jī)制
設(shè)計(jì)目標(biāo)是最小化實(shí)際輸出 和期望輸出
和期望輸出 之間的跟蹤誤差
之間的跟蹤誤差 。
。
控制增益矩陣 通過
通過 更新,其中
更新,其中 是跟蹤誤差向量
是跟蹤誤差向量 的 2 范數(shù),
的 2 范數(shù), 是學(xué)習(xí)率。
是學(xué)習(xí)率。
3. 實(shí)施細(xì)節(jié)

4. 模型架構(gòu)圖如下所示:

MixCon 模型架構(gòu)
MixCon 是結(jié)合注意力機(jī)制的 Transformer 層、Conba 層和 MoE 組件的創(chuàng)新混合解碼器架構(gòu)。
在內(nèi)存使用方面,通過平衡注意力和 Conba 層,相比 Mamba 可將 KV 緩存減少 32 倍。例如,在 256K 令牌上下文環(huán)境中,MixCon 仍能保持較小的 KV 緩存優(yōu)勢(shì)(如表 1 所示)。

在吞吐量方面,處理長序列時(shí),Conba 層計(jì)算效率更高,增加其比例可提高整體吞吐量。
基本配置單位是 MixCon 塊,由 Conba 或注意力層組合而成,每個(gè)層包含注意力模塊或 Conba 模塊,后接 MLP 或 MoE 層。MixCon 中的 MLP 層被 MoE 層替換,以增加模型容量同時(shí)保持較低計(jì)算負(fù)載。
對(duì)于 Conba 層實(shí)施,采用 RMSNorm 等技術(shù),模型詞匯量為 256K,使用 BPE 進(jìn)行訓(xùn)練,每個(gè)數(shù)字為單獨(dú)令牌。
模型架構(gòu)圖如下所示:

三、MixCon 的實(shí)驗(yàn)與評(píng)估
實(shí)施細(xì)節(jié)
選擇特定配置適應(yīng)單塊 80GB A800 NVIDIA GPU 的計(jì)算能力,實(shí)現(xiàn)質(zhì)量和吞吐量的優(yōu)化。
序列由 4 個(gè) MixCon 塊組成,每個(gè) MixCon 塊含 8 層 L = 8,注意力層和 Conba 層比例為 2:6 (a:c = 2:6),每隔一層 (e = 2) 用 MoE 替換 MLP 模塊,模型有 16 個(gè)專家 (n = 16),每個(gè)令牌使用 2 個(gè)頂級(jí)專家 (K = 2)。
上下文長度分析
MixCon 在單塊 80GB A800 GPU 上的最大上下文長度是 Jamba 的兩倍、Mixtral 的四倍、Llama - 2 - 70B 的十四倍(如圖 3 所示)。

吞吐量分析
1. 配置一:考慮不同批大小,在單塊 A800 80GB GPU(int8 量化)、8K 上下文長度下生成 512 個(gè)輸出令牌,MixCon 吞吐量是 Mixtral 的三倍、Jamba 的兩倍(如圖 4 所示)。

2. 配置二:單批次(批大小 = 1)、四塊 A800 GPUs(無量化)、不同上下文長度下生成 512 個(gè)輸出令牌,處理 128K 令牌時(shí),MixCon 吞吐量是 Jamba 的 1.5 倍、Mixtral 的 4.5 倍(如圖 5 所示)。

數(shù)據(jù)集評(píng)估
本文在一系列標(biāo)準(zhǔn)學(xué)術(shù)基準(zhǔn)測(cè)試中評(píng)估 Conba 性能,包括常識(shí)推理任務(wù)(如 HellaSwag、WinoGrande、ARC - E、ARC - Challenge)、閱讀理解任務(wù)(如 BoolQ、QuAC)、聚合基準(zhǔn)測(cè)試(如 MMLU、BBH),采用不同的學(xué)習(xí)策略。
MixCon 性能與類似或更大規(guī)模的先進(jìn)公開模型相當(dāng)或更優(yōu),盡管總參數(shù)比 Llama - 2 少,但作為稀疏模型,其活躍參數(shù)僅 5B,處理長序列時(shí) KV 緩存僅需 2GB,而 Mixtral 需 32GB(如表 2 所示)。

消融實(shí)驗(yàn)
展示注意力和 Conba 層結(jié)合的優(yōu)勢(shì)及最佳比例和交織技術(shù)。純 Conba 模型在上下文學(xué)習(xí)有困難,Attention - Conba 混合模型有類似純 Transformer 模型的上下文學(xué)習(xí)能力。
以 HellaSwag(10 - shot)、WinoGrande(5 - shot)、Natural Questions(NQ,5 - shot)為指標(biāo),MixCon 表現(xiàn)穩(wěn)健(如表 3 所示),MixCon(無 MoE)訓(xùn)練過程損失更低(如圖 6 所示)。

長上下文評(píng)估
利用問答基準(zhǔn)測(cè)試評(píng)估 MixCon 處理長上下文能力,使用 L - Eval 中最長上下文數(shù)據(jù)集的五個(gè)數(shù)據(jù)集,以少樣本格式(每個(gè)實(shí)驗(yàn)用三個(gè)例子)進(jìn)行實(shí)驗(yàn)。
在 NarrativeQA、LongFQA、Natural Questions(NQ)、CUAD 等數(shù)據(jù)集上評(píng)估,MixCon 在多數(shù)數(shù)據(jù)集上優(yōu)于 Mixtral 和 Jamba,平均性能優(yōu)越,且在長上下文任務(wù)中具有更好的吞吐量(如表 4 所示)。

結(jié)合注意力和 Conba 的優(yōu)勢(shì)及混合專家的影響
1. 注意力和 Conba 比例研究
用 13 億參數(shù)模型在 2500 億令牌上訓(xùn)練,MixCon 性能優(yōu)于純注意力或純 Mamba,注意力和 Conba 層比例為 2:6 或 1:7 時(shí)性能差異小(如表 5 所示)。
2. 混合專家的影響
當(dāng)在 MixCon 架構(gòu)的大規(guī)模情境(5B 參數(shù),在 50B 令牌上訓(xùn)練)中應(yīng)用 MoE 技術(shù)時(shí),性能有顯著提升(如表 6 所示)。

四、MixCon 的優(yōu)勢(shì)與展望
MixCon 作為創(chuàng)新的混合序列建模架構(gòu),通過整合多種技術(shù),在處理復(fù)雜動(dòng)態(tài)序列時(shí)具有高效的計(jì)算效率,在各項(xiàng)任務(wù)中展現(xiàn)出顯著優(yōu)勢(shì),能高效處理長序列、內(nèi)存使用低且吞吐量高,具有高可擴(kuò)展性和實(shí)用性。然而,它仍有改進(jìn)空間,如進(jìn)一步優(yōu)化狀態(tài)空間表示、長序列的自適應(yīng)控制、特定領(lǐng)域微調(diào)以及訓(xùn)練算法等。
總體而言,MixCon 為序列建模提供了新的解決方案,在復(fù)雜序列處理方面表現(xiàn)出色,為 NLP 及其他領(lǐng)域的應(yīng)用開辟了新道路。未來,我們期待它在更多領(lǐng)域發(fā)揮更大的作用,為技術(shù)發(fā)展帶來更多的突破和創(chuàng)新。


























