Open Vocabulary Detection 開(kāi)放世界目標(biāo)檢測(cè)競(jìng)賽 2023獲勝團(tuán)隊(duì)方案分享

OVD技術(shù)簡(jiǎn)介
目標(biāo)檢測(cè)是計(jì)算機(jī)視覺(jué)領(lǐng)域中的一項(xiàng)核心任務(wù),其主要目標(biāo)是讓計(jì)算機(jī)能夠自動(dòng)識(shí)別圖片中目標(biāo)的類(lèi)別,并準(zhǔn)確標(biāo)示每個(gè)目標(biāo)的位置。目前,主流的目標(biāo)檢測(cè)方法主要針對(duì)閉集目標(biāo)的開(kāi)發(fā),即在任務(wù)開(kāi)始之前需要對(duì)待檢測(cè)目標(biāo)進(jìn)行類(lèi)別定義,并進(jìn)行人工數(shù)據(jù)標(biāo)注,通過(guò)有監(jiān)督模型的訓(xùn)練來(lái)實(shí)現(xiàn)目標(biāo)檢測(cè)。這種方法通常適用于待檢測(cè)目標(biāo)數(shù)量較少的情況,一般限定在幾十個(gè)類(lèi)別以?xún)?nèi)。然而,當(dāng)待檢測(cè)目標(biāo)的類(lèi)別數(shù)量增加到幾千甚至萬(wàn)級(jí)時(shí),以上述方式進(jìn)行數(shù)據(jù)標(biāo)注已經(jīng)無(wú)法滿(mǎn)足需求。同時(shí),已經(jīng)訓(xùn)練好的模型也無(wú)法應(yīng)對(duì)新出現(xiàn)的類(lèi)別。當(dāng)新的類(lèi)別出現(xiàn)時(shí),需要手動(dòng)進(jìn)行標(biāo)注并重新訓(xùn)練模型,整體效率較低。
開(kāi)放詞集目標(biāo)檢測(cè)(Open Vocabulary Detection, OVD),亦即開(kāi)放世界目標(biāo)檢測(cè),提供了解決上述問(wèn)題的新思路。借助于現(xiàn)有跨模態(tài)模型(CLIP[1]、ALIGN[2]、R2D2[3] 等)的泛化能力,OVD可以實(shí)現(xiàn)以下功能:1)對(duì)已定義類(lèi)別的few shot檢測(cè);2)對(duì)未定義類(lèi)別的zero-shot檢測(cè)。OVD技術(shù)的出現(xiàn)吸引了計(jì)算機(jī)視覺(jué)研究者們的廣泛關(guān)注,首先,對(duì)于已定義類(lèi)別的few shot檢測(cè),OVD的強(qiáng)大泛化能力可以讓算法在僅有少量樣本的情況下,準(zhǔn)確地識(shí)別出新的目標(biāo)類(lèi)別。其次,對(duì)于未定義類(lèi)別的zero-shot檢測(cè),OVD的能力更是令人驚嘆。通過(guò)學(xué)習(xí)各種物體的視覺(jué)特征和語(yǔ)義信息,OVD可以在沒(méi)有見(jiàn)過(guò)的類(lèi)別中進(jìn)行目標(biāo)檢測(cè),進(jìn)一步將語(yǔ)言大模型技術(shù)引入OVD,將會(huì)進(jìn)一步提升OVD對(duì)未知類(lèi)別的檢測(cè)能力。OVD技術(shù)有望成為未來(lái)目標(biāo)檢測(cè)算法開(kāi)發(fā)的新范式。

競(jìng)賽介紹
OVD技術(shù)的研究在國(guó)內(nèi)尚處于起步階段,為了促進(jìn)國(guó)內(nèi)OVD技術(shù)的發(fā)展,并加強(qiáng)OVD技術(shù)的生態(tài)社區(qū)建設(shè),360人工智能研究院聯(lián)合中國(guó)圖象圖形學(xué)學(xué)會(huì)于ICIG2023大會(huì)上開(kāi)設(shè)了Open Vocabulary Detection Contest - 開(kāi)放世界目標(biāo)檢測(cè)2023競(jìng)賽。大賽于4月12日啟動(dòng)報(bào)名,報(bào)名期間吸引了來(lái)自新加坡南洋理工大學(xué)、清華大學(xué)、北京大學(xué)、香港大學(xué)、中國(guó)科學(xué)院自動(dòng)化研究所紫東太初大模型研究中心、鵬城實(shí)驗(yàn)室、華中科技大學(xué)、字節(jié)跳動(dòng)、滴滴等知名大學(xué)與公司機(jī)構(gòu)共140支隊(duì)伍參加競(jìng)賽。此次大賽所使用的賽題數(shù)據(jù)、競(jìng)賽提交平臺(tái)與賽題設(shè)置均由360人工智能研究院提供支持。
賽題數(shù)據(jù)主要涵蓋了服裝、數(shù)碼產(chǎn)品等眾多商品類(lèi)目,對(duì)于一件商品,均給出了它的圖片以及對(duì)應(yīng)的檢測(cè)框標(biāo)注信息作為訓(xùn)練數(shù)據(jù)。商品數(shù)據(jù)在互聯(lián)網(wǎng)搜索、推薦中具有重要價(jià)值,是非常貼近業(yè)務(wù)場(chǎng)景的實(shí)用數(shù)據(jù)。其次商品數(shù)據(jù)集的難度較大,同類(lèi)別商品之間普遍存在一些細(xì)節(jié)差異,而這一點(diǎn)也限制了傳統(tǒng)目標(biāo)檢測(cè)技術(shù)的泛化能力,進(jìn)而體現(xiàn)出OVD技術(shù)的優(yōu)勢(shì)性。
賽題設(shè)置:參賽者運(yùn)用OVD相關(guān)的方法,對(duì)圖像中的商品目標(biāo)進(jìn)行檢測(cè)。對(duì)于一件商品,主辦方會(huì)給出它的圖片以及bbox作為訓(xùn)練數(shù)據(jù)。目標(biāo)類(lèi)別有兩類(lèi):base類(lèi)和novel類(lèi)。類(lèi)別均為中文商品詞組。base類(lèi)的目標(biāo)提供少量已標(biāo)注的訓(xùn)練樣本,novel類(lèi)的目標(biāo)則沒(méi)有訓(xùn)練樣本。評(píng)測(cè)分別在base類(lèi)的測(cè)試集和novel類(lèi)的測(cè)試集上進(jìn)行,評(píng)測(cè)指標(biāo)為novel和base類(lèi)的mAP@50,競(jìng)賽按照novel和base類(lèi)別的整體mAP@50排序。
競(jìng)賽共分為初賽與復(fù)賽兩個(gè)階段,由初賽到復(fù)賽,賽題難度逐步提升,考驗(yàn)選手對(duì)開(kāi)放世界目標(biāo)檢測(cè)賽題的熟悉程度與靈活應(yīng)變能力。比賽中,各位選手的方案追逐激烈,最終前三名團(tuán)隊(duì)的復(fù)賽分?jǐn)?shù)十分接近。經(jīng)過(guò)初賽與復(fù)賽的層層選拔,最終有6支隊(duì)伍脫穎而出,由來(lái)自南洋理工大學(xué)的吳思澤團(tuán)隊(duì)摘得桂冠。獲得二等獎(jiǎng)的是來(lái)自華中科技大學(xué)的STAR團(tuán)隊(duì)與來(lái)自中國(guó)科學(xué)院自動(dòng)化研究所紫東太初大模型研究中心的咱們組有名稱(chēng)嗎團(tuán)隊(duì),獲得三等獎(jiǎng)的是來(lái)自北京大學(xué)的OVD團(tuán)隊(duì)、來(lái)自哈爾濱工業(yè)大學(xué)的wzmwzr團(tuán)隊(duì)與來(lái)自武漢郵電科學(xué)研究院的藍(lán)色閃團(tuán)隊(duì)。Open Vocabulary Detection Contest - 開(kāi)放世界目標(biāo)檢測(cè)競(jìng)賽的官網(wǎng)鏈接:開(kāi)放世界目標(biāo)檢測(cè)競(jìng)賽2023 (360cvgroup.github.io)
在各個(gè)競(jìng)賽團(tuán)隊(duì)的積極參與、中國(guó)圖象圖形學(xué)學(xué)會(huì)與360人工智能研究院的大力支持下,Open Vocabulary Detection Contest - 開(kāi)放世界目標(biāo)檢測(cè)競(jìng)賽已經(jīng)正式結(jié)束,在征集各個(gè)競(jìng)賽團(tuán)隊(duì)的許可后,我們將部分優(yōu)勝團(tuán)隊(duì)的技術(shù)方案匯總并公開(kāi)分享,詳見(jiàn)本文下半部分。

[1] A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clark, et al. Learning transferable visual models from natural language supervision. In International Conference on Machine Learning, pages 8748–8763. PMLR, 2021.
[2] C. Jia, Y. Yang, Y. Xia, Y.-T. Chen, Z. Parekh, H. Pham, Q. V. Le, Y. Sung, Z. Li, and T. Duerig. Scaling up visual and vision-language representation learning with noisy text supervision. In International Conference on Machine Learning, 2021.
[3] Xie C, Cai H, Song J, et al. Zero and R2D2: A Large-scale Chinese Cross-modal Benchmark and A Vision-Language Framework[J]. arXiv preprint arXiv:2205.03860, 2022.
冠軍方案講解
團(tuán)隊(duì)介紹
來(lái)自南洋理工大學(xué)的博士生吳思澤
賽題分析
1、數(shù)據(jù)集
本次主辦方提供的是商品數(shù)據(jù)集,總共466個(gè)物體類(lèi)別,其中訓(xùn)練中可見(jiàn)的有233個(gè)base類(lèi)別,測(cè)試時(shí)檢測(cè)器需要能夠同時(shí)識(shí)別base類(lèi)的物體意見(jiàn)另外233個(gè)novel類(lèi)別的物體。數(shù)據(jù)集中圖片以網(wǎng)購(gòu)商品圖為主,背景通常較為簡(jiǎn)單,每張圖物體數(shù)量不多,存在大量以物體為中心(object-centric)的圖片,訓(xùn)練集中平均每張圖的物體標(biāo)注數(shù)量<2。
2、解決思路
根據(jù)數(shù)據(jù)集屬性,可知互聯(lián)網(wǎng)中存在大量包含新類(lèi)別的商品圖片,由于圖片場(chǎng)景簡(jiǎn)單,物體單一,在圖像層級(jí)(image-level)上學(xué)習(xí)新類(lèi)別的表征,可很好泛化到檢測(cè)上。因此選擇基礎(chǔ)方案為Detic,使用爬蟲(chóng)獲取帶有新類(lèi)別tag的圖片,用于image-level的訓(xùn)練。
方案總覽
采用Detic[1]的訓(xùn)練策略,同時(shí)使用目標(biāo)檢測(cè)數(shù)據(jù)(base類(lèi))和圖像分類(lèi)數(shù)據(jù)(base類(lèi)+novel類(lèi))訓(xùn)練檢測(cè)器。

方案流程介紹
1、數(shù)據(jù)處理
選擇百度圖片為爬取對(duì)象,索引關(guān)鍵詞為”[中文名稱(chēng)] 商品圖片”,為保證類(lèi)別平衡,novel和base類(lèi)別均爬取40頁(yè)(大約1000張)。每個(gè)類(lèi)別爬取到的圖片存到一個(gè)路徑下,這些圖片只有類(lèi)別Tag,沒(méi)有物體框標(biāo)注。

2、類(lèi)別名稱(chēng)翻譯
為方便使用現(xiàn)有的開(kāi)源模型(CLIP),需要將466個(gè)中文名稱(chēng)均翻譯成英文,我們使用google translator翻譯每個(gè)名稱(chēng)并人工校對(duì)。

3、模型介紹
選擇ResNet50和SwinB作為檢測(cè)器backbone,檢測(cè)器結(jié)構(gòu)為CenterNet2,使用Detic公開(kāi)的在公開(kāi)數(shù)據(jù)集LVIS和ImageNet上預(yù)訓(xùn)練的模型權(quán)重作為初始化。CLIP模型選擇ViT-L-14(只用text encoder)來(lái)得到類(lèi)別名稱(chēng)的embeddings。分類(lèi)的損失函數(shù)為BCE Loss。
4、Learnable Prompt
為了獲取類(lèi)別名稱(chēng)的text embeddings,在訓(xùn)練過(guò)程中學(xué)習(xí)一組長(zhǎng)度為4的learnable prompt以獲得更好的text表征。具體方案參考了coop[2]。

5、重要參數(shù)
- 模型初始化:使用LVIS和ImageNet上預(yù)訓(xùn)練的模型作為初始化。
- 總迭代次數(shù):18000。
- image-level分支的batch size: 8x96,檢測(cè)分支batch size: 8x4。
- image-level的權(quán)重:1.2,det分支權(quán)重:1.0。
- 圖像分辨率:image-level分支448, 檢測(cè)分支 896。
6、測(cè)試結(jié)果
這里介紹的測(cè)試結(jié)果是隨著我們模塊和參數(shù)改變的變化,我們初始使用R50 backbone作為baseline, image-level分支的batch size為32,訓(xùn)練資源8xV100,增加到64之后需要8xA100 (或者整體batch size縮小,迭代數(shù)增加)。以下結(jié)果均來(lái)自初賽。

- ADetecting Twenty-thousand Classes using Image-level Supervision, Zhou et.al ECCV 2022.
- Prompt Learning for Vision-Language Models, Zhou et.al IJCV 2022.
亞軍方案講解(第二名)
團(tuán)隊(duì)介紹
來(lái)自華中科技大學(xué)的團(tuán)隊(duì),成員有冷福星,易成龍。
賽題分析
1、數(shù)據(jù)集
- 訓(xùn)練數(shù)據(jù):233類(lèi)已知類(lèi)別的目標(biāo)檢測(cè)框
- 初賽:7401張圖像
- 復(fù)賽:14802張圖像
數(shù)據(jù)特點(diǎn):
- 全部是電商類(lèi)的商品圖像
- 單張圖像中的目標(biāo)類(lèi)別相同
- 存在部分有效的OCR信息
2、解決思路
利用前景檢測(cè)器對(duì)圖片進(jìn)行目標(biāo)定位,利用LLM來(lái)擴(kuò)充文本信息,最后結(jié)合ChineseCLIP進(jìn)行多模態(tài)圖文對(duì)齊生成類(lèi)別信息。
方案總覽
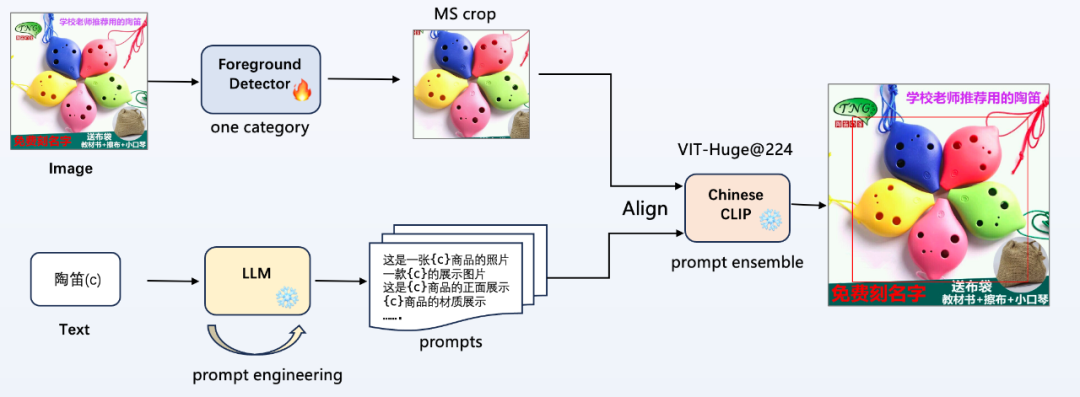
如圖所示,是本次比賽中提出的算法 pipeline,不需要使用提供的類(lèi)別信息,不引入額外的數(shù)據(jù),即可進(jìn)行任意商品類(lèi)別的目標(biāo)檢測(cè):
- 前景檢測(cè)器(Foreground Detector):不需要使用提供的233類(lèi)類(lèi)別信息,只使用位置坐標(biāo)訓(xùn)練一個(gè)前景檢測(cè)器,整個(gè) pipeline 中只有這里進(jìn)行梯度更新;
- 提示詞工程(prompt engineering):使用大語(yǔ)言模型(LLM)進(jìn)行半自動(dòng)化的提示詞工程,輸入類(lèi)別 c,給定模板規(guī)范,生成更多風(fēng)格多樣的提示詞;
- 多模態(tài)圖文對(duì)齊:使用 Chinese CLIP 進(jìn)行圖文特征對(duì)齊,進(jìn)行類(lèi)別分類(lèi),使用提示詞集成(prompt ensemble)提高性能;
方案流程介紹
1、前景檢測(cè)器

當(dāng)前主流的檢測(cè)器如圖所示,主要包括 Anchor Based 和 Anchor Free 兩類(lèi)檢測(cè)器,前者精度高但速度慢,后者精度略差但速度快;
- 前景 proposal 使用 WBF(Weighted Boxes Fusio)集成了CBNetV2_Swin,CascadeRCNN_Convnext,CascadeRCNN_Hornet,CascadeRCNN_resnext101,DetecotoRS_r101,VFNet_resnext101;實(shí)際使用CBNetV2_Swin單個(gè)檢測(cè)器分?jǐn)?shù)不低,集成在分?jǐn)?shù)提升大概1個(gè)點(diǎn);
- 使用訓(xùn)練好的前景檢測(cè)器檢測(cè)目標(biāo),進(jìn)行多尺度裁剪(外擴(kuò)+0,+30像素),并加入全圖(利用有效的OCR信息,如圖2中右上角的陶笛文本)一起進(jìn)行圖文對(duì)齊,將3個(gè)尺度的輸出 logits 進(jìn)行平均;
2、提示詞工程
CLIP模型是雙塔結(jié)構(gòu),直接使用類(lèi)別信息進(jìn)行文本對(duì)齊的效果不是最佳的,為了充分挖掘文本 encode 的潛力,需要進(jìn)行一定的提示詞工程;在實(shí)驗(yàn)中,使用 “c” 和 一張“c”的圖片,驗(yàn)證集上后者分?jǐn)?shù)高5個(gè)點(diǎn);
可以使用 ChahtGPT/LLMA 2 進(jìn)行交互,逐步引導(dǎo) LLM 生成想要的提示詞模板;最后得到多條 prompts,可以進(jìn)行 prompt ensemble,ensemble 的方法有以下三種,實(shí)際只使用了最簡(jiǎn)單的 Uniform averaging;
- Uniform averaging
- Weighted averaging
- Majority Voting

3、消融實(shí)驗(yàn)與實(shí)驗(yàn)結(jié)果
驗(yàn)證集:初賽訓(xùn)練集,(訓(xùn)練中沒(méi)有使用類(lèi)別信息,用來(lái)評(píng)測(cè)CLIP模型分類(lèi)能力)
- PE:prompt engineering
- CME:CLIP model ensemble(0.7*VIT-H@224+0.3*VIT-L@336)

4、拓展思路
上述提出的 pipeline 使用了位置信息進(jìn)行訓(xùn)練,使用 CLIP 也可不進(jìn)行訓(xùn)練進(jìn)行任意目標(biāo)檢測(cè):

將圖像分成小 patch,滑動(dòng)窗口 crop 圖像送入 CLIP 模型提取圖文相似性。每個(gè)窗口根據(jù)閾值判斷目標(biāo)類(lèi)別,也可以將當(dāng)前窗口圖像置0,看整圖類(lèi)別相似性哪個(gè)下降最多。但該方法,滑動(dòng)窗口的方式替代 proposal 的檢出比較耗時(shí),實(shí)測(cè)精度也沒(méi)有上述方法高;
季軍方案講解(第三名)
團(tuán)隊(duì)介紹
“我們組有名稱(chēng)嗎”團(tuán)隊(duì)來(lái)自中國(guó)科學(xué)院自動(dòng)化研究所紫東太初大模型研究中心,紫東太初大模型研究中心致力于構(gòu)建低功耗萬(wàn)億突觸多模態(tài)認(rèn)知大模型,建立面向開(kāi)放復(fù)雜環(huán)境的可解釋、可信、可演化的多模態(tài)人工智能基礎(chǔ)平臺(tái),建成新一代人工智能重大基礎(chǔ)設(shè)施,形成創(chuàng)新應(yīng)用生態(tài)。比賽團(tuán)隊(duì)由兩名博士生(詹宇飛、楊帆)、一名碩士生(趙弘胤)和一名本科生(王天琦)組成,在朱優(yōu)松老師指導(dǎo)下共同完成本次比賽,目前團(tuán)隊(duì)主要研究方向?yàn)橐曈X(jué)大模型、目標(biāo)檢測(cè)、開(kāi)放詞匯目標(biāo)檢測(cè)及長(zhǎng)尾目標(biāo)檢測(cè)等。
賽題分析
1、數(shù)據(jù)集
在開(kāi)放詞匯目標(biāo)檢測(cè)的研究中,端到端訓(xùn)練方法由于其在訓(xùn)練速度的優(yōu)勢(shì)和公平對(duì)比的要求獲得了更為廣泛的使用。在本次商品場(chǎng)景下的開(kāi)放世界目標(biāo)檢測(cè)競(jìng)賽中,主要存在以下四個(gè)問(wèn)題:
- 噪聲大---數(shù)據(jù)標(biāo)注噪聲大,各類(lèi)別均存在誤標(biāo)、漏標(biāo)等情況,標(biāo)注方式不統(tǒng)一;
- 定位難---少樣本訓(xùn)練設(shè)定下,端到端微調(diào)精準(zhǔn)定位和分類(lèi)效果差;
- 易混淆---類(lèi)別細(xì)粒度程度高,且多為商品數(shù)據(jù),類(lèi)內(nèi)方差大,通用中文圖文模型無(wú)法有效區(qū)分;
- 主體判斷難---該場(chǎng)景設(shè)定下,每張圖中只可識(shí)別出主要商品,共同出現(xiàn)的其他商品需被抑制。
2、解決思路
為解決上述問(wèn)題,通過(guò)對(duì)數(shù)據(jù)的類(lèi)別分布和實(shí)例位置分布的分析,我們發(fā)現(xiàn)圖片的實(shí)例以單類(lèi)別形式出現(xiàn),且居中分布,具備任務(wù)解耦的基礎(chǔ)。因此,我們選擇雙階段的方法,將框回歸和商品物體分類(lèi)進(jìn)行剝離,分別實(shí)現(xiàn)類(lèi)別無(wú)關(guān)的框回歸以解決定位難和主題判斷難得問(wèn)題,和基于CLIP特征的零樣本和少樣本分類(lèi)以解決噪聲大和易混淆得問(wèn)題。且將任務(wù)拆分為兩個(gè)子任務(wù),分別迭代,有效提高了優(yōu)化速度。
方案總覽
方案整體框架下圖所示,按照子任務(wù)拆分,我們將訓(xùn)練分為檢測(cè)器訓(xùn)練和圖文模型優(yōu)化兩部分,將最終優(yōu)化好的模型在推理階段進(jìn)行組合,在推理規(guī)則的輔助下完成對(duì)場(chǎng)景中的少樣本和零樣本類(lèi)別的檢測(cè)。

方案流程介紹
1、用于目標(biāo)定位的數(shù)據(jù)補(bǔ)充
為抑制模型產(chǎn)生大框的傾向和糾正在部分情況下錯(cuò)誤產(chǎn)生部件框造成得定位難問(wèn)題,我們額外爬取659張Base類(lèi)別商品圖片,利用訓(xùn)練好的模型打偽標(biāo)簽的形式構(gòu)建,選取置信度大于0.8的預(yù)測(cè)框并采用人工校驗(yàn)的方式進(jìn)行清洗過(guò)濾,去掉其中的局部框等,構(gòu)建了包含659張圖片的糾正數(shù)據(jù)子集,用于模型的微調(diào)。
2、目標(biāo)定位模塊
在商品目標(biāo)定位部分,考慮到在開(kāi)放詞匯目標(biāo)檢測(cè)任務(wù)下,檢測(cè)器首先應(yīng)當(dāng)定位出所有可能的物體,其中包括不具備檢測(cè)標(biāo)注的novel類(lèi)別。因此,我們選擇將檢測(cè)器訓(xùn)練為二分類(lèi)商品檢測(cè)器,用于提取圖片中可能存在的商品。我們選擇Cascade-RCNN訓(xùn)練二分類(lèi)的商品檢測(cè)模型,利用多個(gè)級(jí)聯(lián)的回歸分支提升模型對(duì)于物體的識(shí)別與定位能力。為提高模型的特征提取能力,我們選擇以Swin-Transformer Small為骨干網(wǎng)絡(luò),Neck默認(rèn)使用了FPN融合高層語(yǔ)義特征與低層的細(xì)節(jié)特征,最后輸出物體得分大于0.1的候選框中選擇排名前100個(gè)檢測(cè)框。
3、用于目標(biāo)分類(lèi)的數(shù)據(jù)補(bǔ)充
為解決低數(shù)據(jù)量下的噪聲和混淆問(wèn)題,在開(kāi)放詞匯任務(wù)設(shè)定的啟發(fā)下,我們分別采用關(guān)鍵字“類(lèi)別名稱(chēng) 商品圖片”搜索和相似圖片搜索的方式,從百度、谷歌、電商平臺(tái)等網(wǎng)絡(luò)數(shù)據(jù)中收集了70w的數(shù)據(jù)用于模型的微調(diào),并利用ChatGLM對(duì)類(lèi)別和圖片生成描述,提高圖文對(duì)的語(yǔ)義豐富度,進(jìn)而增強(qiáng)模型的判別能力,如圖2所示。通過(guò)對(duì)微調(diào)方式的對(duì)比,我們對(duì)比了目前較優(yōu)的三種微調(diào)方式Finetune、Lora及LiT,如表1所示,發(fā)現(xiàn)Lora進(jìn)行微調(diào)時(shí)能夠更準(zhǔn)確的識(shí)別novel類(lèi)別,當(dāng)采用全量微調(diào)時(shí)能夠,能夠獲得更好的base類(lèi)別識(shí)別效果,因此在最終的模型中我們將這兩者進(jìn)行融合。

4、目標(biāo)分類(lèi)模塊
在商品目標(biāo)分類(lèi)部分,通過(guò)對(duì)當(dāng)前開(kāi)源的中文圖文模型的調(diào)研,我們選擇目前性能最優(yōu)的中文圖文模型Chinese-CLIP,該模型繼承于OpenCLIP,視覺(jué)分支采用ViT結(jié)構(gòu),文本分支采用RoBERTa結(jié)構(gòu),我們選擇ViT-H-224的模型進(jìn)行微調(diào)。
5、推理優(yōu)化
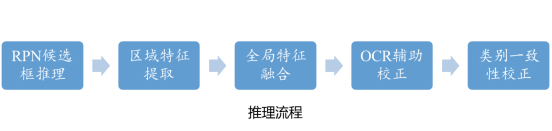
在推理階段,我們將數(shù)據(jù)先驗(yàn)(單一類(lèi)別、圖文并茂)以規(guī)則的形式加入其中,設(shè)計(jì)了全局概率融合、OCR輔助推理和類(lèi)別一致性校正三條規(guī)則,進(jìn)一步解決數(shù)據(jù)的易混淆和主體判斷難問(wèn)題。我們將規(guī)則和模型整理為如下的推理流程:
- RPN候選框推理:使用訓(xùn)練好的定位模型,對(duì)測(cè)試集中的每張圖進(jìn)行推理,得到每張圖的候選框;
- 圖文特征提取:對(duì)每一張圖,根據(jù)(1)中產(chǎn)生的候選框結(jié)果,截取對(duì)應(yīng)的感興趣區(qū)域,與全圖共同送入訓(xùn)練好的CLIP模型中提取區(qū)域特征和類(lèi)別文本特征;
- 全局特征融合:對(duì)每一個(gè)候選框產(chǎn)生的區(qū)域特征,按照8:2的比例與全局特征相加,校正得到最終的區(qū)域特征,與文本特征計(jì)算余弦相似度;
- OCR輔助校正:對(duì)于每一個(gè)候選框的分類(lèi)概率,結(jié)合全圖的OCR結(jié)果,根據(jù)所設(shè)計(jì)的OCR規(guī)則進(jìn)行類(lèi)別概率校正;
- 類(lèi)別一致性校正:對(duì)所有的候選框的分類(lèi)結(jié)果和全圖的分類(lèi)結(jié)果進(jìn)行對(duì)比,若候選框中存在與全圖類(lèi)別一致的候選框,則輸出一致候選框,若無(wú)則輸出所有框中分?jǐn)?shù)最高的候選框作為該圖片的最終結(jié)果。
6、測(cè)試結(jié)果
通過(guò)模型優(yōu)化和規(guī)則設(shè)計(jì),我們的方案在零樣本類(lèi)別上實(shí)現(xiàn)了50.08%的AP50,在少樣本類(lèi)別上實(shí)現(xiàn)了54.16%的AP50,最終識(shí)別效果如下: