手把手教你使用Scrapy框架來爬取北京新發地價格行情(實戰篇)
大家好!我是霖hero。上個月的時候,我寫了一篇關于IP代理的文章,手把手教你使用XPath爬取免費代理IP;前幾天,我又發布了第二篇文章,這篇文章主要是講Scrapy理論知識的,手把手教你使用scrapy框架來爬取北京新發地價格行情(理論篇),今天在這里分享我的第三篇文章,關于Scrapy實戰的應用文章,希望大家可以喜歡。
前言
關于Scrapy理論的知識,可以參考我的上一篇文章,這里不再贅述,直接上干貨。
實戰演練
爬取分析
首先我們進入北京新發地價格行情網頁并打開開發者工具,如下圖所示:
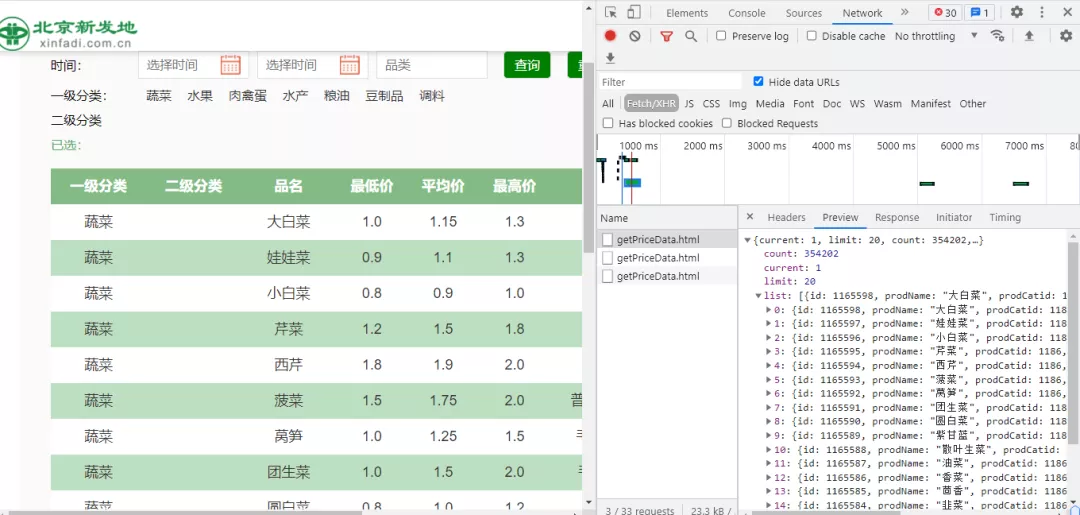
經過簡單的查找,發現每個getPriceData.html存放著價格行情的數據,由此可得,我們可以通過getPriceData.html來進行數據的獲取。
觀察Headers請求,如下圖所示:
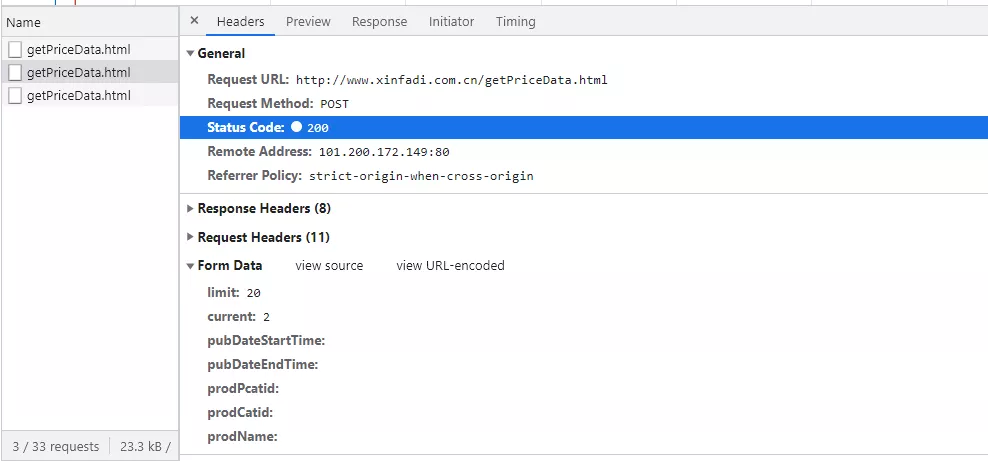
發現它是POST請求,請求URL鏈接是http://www.xinfadi.com.cn/getPriceData.html,current是翻頁的重要參數,limit是每頁有多少行數據,我們可以構造消息體,代碼如下所示:
- data={
- 'limit': '20',
- 'current':page
- }
通過scrapy.Request()方法將消息體傳入到參數里面。
或者我們可以根據測試和觀察規律,自己構造URL鏈接,通過觀察分析,請求的URL鏈接可以為:
- http://www.xinfadi.com.cn/getPriceData.html?limit=20¤t=1
- http://www.xinfadi.com.cn/getPriceData.html?limit=20¤t=2
- http://www.xinfadi.com.cn/getPriceData.html?limit=20¤t=3
創建Spider爬蟲
分析北京新發地價格行情后,接下來我們首先創建一個Scrapy項目,使用如下命令:
- scrapy startproject Vegetables
這樣我們就成功創建了一個Scrapy項目,項目文件如下所示:
接下來創建spider爬蟲,使用如下命令:
- scrapy genspider vegetables www.xinfadi.com.cn
創建后vegetables.py內容如下所示:
- import scrapy
- class VegetablesSpider(scrapy.Spider):
- name = 'vegetables'
- allowed_domains = ['www.xinfadi.com.cn']
- start_urls = ['https://www.xinfadi.com.cn']
- def parse(self, response):
- pass
提取數據
在提取數據前,我們首先把要爬取的數據字段在items.py文件中定義好,代碼如下所示:
- import scrapy
- class VegetablesItem(scrapy.Item):
- # define the fields for your item here like:
- productName = scrapy.Field()
- lowPrice=scrapy.Field()
- highPrice=scrapy.Field()
這里我們定義了三個字段分別是productName、lowPrice、highPrice
定義好字段后,接下來將在創建的vegetables.py文件中進行數據的提取,具體代碼如下
- import scrapy
- from Vegetables.items import VegetablesItem
- class VegetablesSpider(scrapy.Spider):
- name = 'vegetables'
- allowed_domains = ['www.xinfadi.com.cn']
- def start_requests(self):
- for i in range(1, 3):
- url = f'http://www.xinfadi.com.cn/getPriceData.html?limit=20¤t={i}'
- yield scrapy.Request(url=url, callback=self.parse)
- def parse(self, response):
- html = response.json()
- fooddata = html.get('list')
- for i in fooddata:
- item=VegetablesItem()
- item['highPrice'] =i.get('highPrice'),
- item['lowPrice'] = i.get('lowPrice'),
- item['prodName'] = i.get('prodName'),
- yield item
首先我們導入vegetablesitem,使用start_requests函數實現翻頁,大家可以使用剛才我們所講的方法實現翻頁,實現翻頁后,我們通過編寫parse()方法實現數據的獲取,首先我們把引擎響應的數據以json()格式存放在html里面,調用get()方法來提取我們想要的數據,最后通過yield生成器返回給引擎。
最后我們在settings.py設置引擎的啟動,代碼如下所示:
- ITEM_PIPELINES = {
- 'Vegetables.pipelines.VegetablesPipeline': 300,
- }
在這里我們就不保存數據在MongoDB數據庫里面了,我們直接啟動Spider爬蟲并把數據以csv格式輸出,使用如下命令:
- scrapy crawl vegetables -o 11.c
運行結果如下:
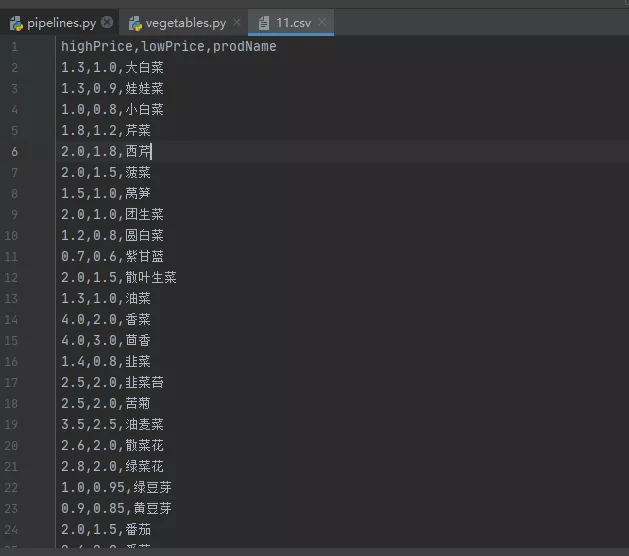
好了,Scrapy框架爬取北京新發地就講解到這里了,感謝觀看!!!
總結
大家好,我是霖hero。這篇文章基于上篇理論文章,主要給大家分享了Scrapy爬蟲框架的實戰內容,Scrapy是一個基于Twisted的異步處理框架,是純Python實現的爬蟲框架,是提取結構性數據而編寫的應用框架,其架構清晰,模塊之間的耦合程度低,可擴展性極強。
【編輯推薦】