













僅靠合成數據就能實現真實人臉分析!微軟這項新研究告別人工標注
本文經AI新媒體量子位(公眾號ID:QbitAI)授權轉載,轉載請聯系出處。

而且人臉分析任務上,準確性還不輸真實數據的那種。
這是微軟團隊的一項最新研究,論文標題就已經說明了一切。
Fake it till you make it.

文章介紹了一種程序生成的3D人臉模型與一個合成數據庫結合起來訓練圖像,結果人臉解析等任務上,效果與真實數據相當。
研究人員表示,為一些不可能實現人工標注的地方,開辟了新方法。
是不是以后真就告別人工標注了?!
如何實現?
要想讓人臉數據集更加多樣化、豐富化,靠收集和標注越來越難以實現。
且不說收集,比如網絡抓取,可能帶來重大的隱私和版權問題。而人工標注,很容易導致出錯或者標簽不一致的情況。
因此,研究團隊就考慮用合成數據來增加或替代真實數據。然鵝,此前因為人臉模型本身復雜實現難度較為困難。
那么這次是如何實現的呢?
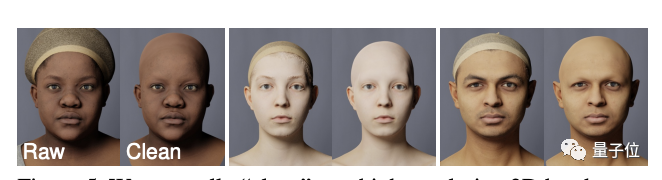
第一步,用程序生成合成面孔,包括身份、表情、面部紋理,以及發型和衣著,不同光線環境下的效果。

所有這些數據都是獨立采樣,提前“手動”去除噪音,以確保創建更多樣化的個體。
比如在人臉模型上,就是這樣滴~
還有像衣著,則是由服裝設計師和模擬軟體設計師手工制作的,共有30套各種各樣的衣服。
還包括頭飾(36件)、面具(7件)和眼鏡(11件) 。

除此以外,還合成了標簽。

接著到了訓練階段,研究人員創建了一個10萬張分辨率為512 × 512的圖像的數據集,并做了數據增強處理,共用了150 張NVIDIA M60 GPU渲染48小時。
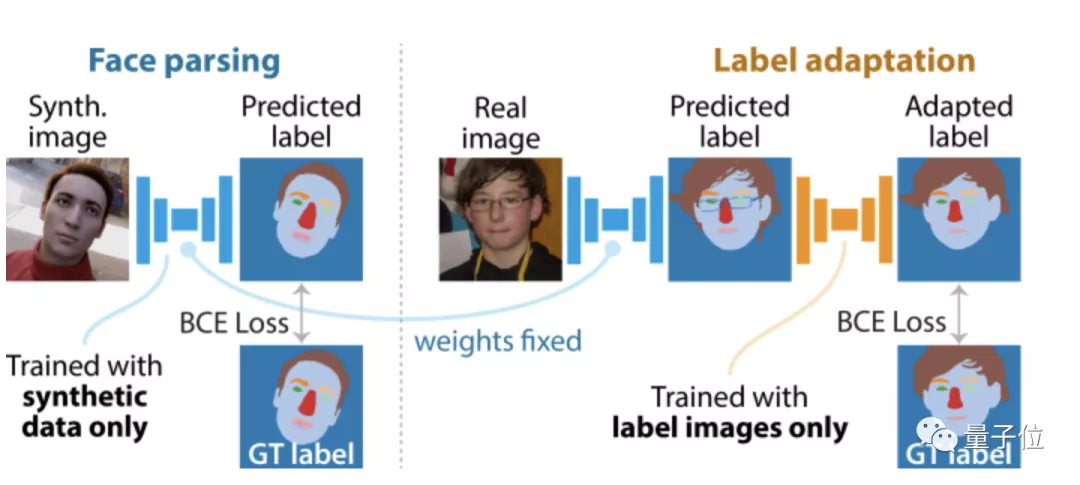
此外,團隊還訓練了人臉解析網絡(僅使用合成數據)和標簽適應網絡,以解決合成標簽和人工注釋標簽之間的系統差異。
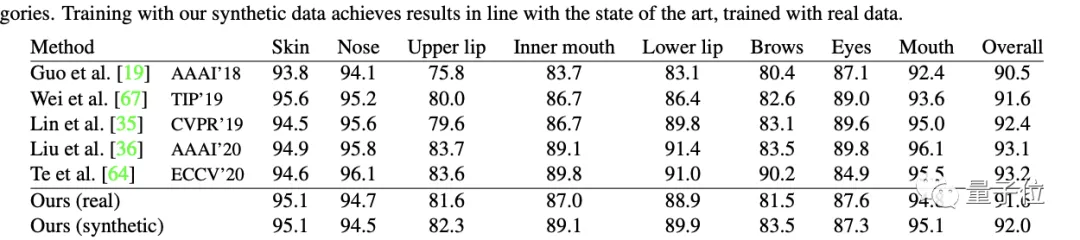
最終,人臉分析、地標定位等任務上的效果與其他采用真實數據的模型相當。

不過,研究人員也承認這項技術仍然有一定局限性。
比如人臉模型只有頭部和頸部、無法模擬真實的皺紋、隨機匹配人臉時會得到一些不合常理的面孔,比如有胡須的女性。
在接下來的工作中,他們計劃將解決這些局限性。
好了,感興趣的旁友可戳下方論文鏈接~
論文鏈接:
https://www.arxiv-vanity.com/papers/2109.15102/





























