













谷歌研究院最新發現:訓練結果不準確,超大數據規模要背鍋!
目前AI領域 的一大趨勢是什么?沒錯,就是擴大數據集規模。然而最近Geogle reserach 的一篇論文,卻認為對超大規模數據集進行整理的趨勢,反而會阻礙有效開發人工智能系統。
數據規模真的越大越好?
算力和數據是人工智能兩大主要驅動力。無論是計算機視覺,還是自然語言處理等AI系統似乎都離不開數據集。
在超大規模數據時代,數據和學習結果是這樣的關系:
數據規模越大,AI模型越精準、高效。在大部分人眼里,這似乎是個不爭的事實。
數據規模和模型精確度難道真的是呈現正相關關系嗎?
最近,Geogle Research 上發布的一篇論文,對這一普遍持有的觀點,提出了質疑的呼聲。
規模一大, “飽和”就無處不在!
這篇名為Expolring the limits of pre-training model 挑戰了機器學習效果和數據關系的既有假設。經過試驗得出的結論是:無論是通過擴大數據規模還是超參數來改進上游性能,下游可能會出現“飽和”現象。
所謂飽和就是.....你懂的哈,就是沒有梯度信號傳入神經元,也無法到權重和數據,這樣網絡就很難以進行學習了。
為了證明飽和效應的觀點,作者對視覺變形器、ResNets和MLP-混合器進行了4800次實驗,每個實驗都有不同數量的參數,從1000萬到100億,都在各自領域現有的最高容量數據集進行訓練,包括ImageNet21K和谷歌自己的JFT-300M。

文中還提到了一種極端的情況,上游和下游的性能是互相矛盾的 ,也就是說:要想獲得更好的下游性能,可能得犧牲掉上游任務的精確度。
這一假設一旦得到驗證,就意味著 "超大規模 "數據集,如最近發布的LAION-400M(包含4億個文本/圖像對),以及GPT-3神經語言引擎背后的數據(包含1750億個參數),有可能受限于傳統機器學習的架構和方法。龐大的數據量可能會使得下游任務飽和,降低了其泛化的能力。
其實呢,之前的假設也不是完全在“胡言亂語”,只是要加上一個條件即:既定數據規模的超參數要在一個較為簡單的線性函數關系中 , 且是一個固定的值。
考慮到有限的計算資源和經濟成本等問題,先前的研究范圍較小,讓人們對數據集和有效AI系統間的關系產生了不全面的認知。原來以偏概全是通病!
事實上怎么可能有這么簡單呢?
文章又反駁道“先前關于論證數據規模有效性的研究,僅是在有限的范圍進行的。 因而不能妄下定論。“
唱反調也得有依據!文章為什么會得出這樣的結論呢?原來真相就在眼前!
上下游的關系不簡單!
先前的研究是在線性函數的假設基礎上,呈現出了對數關系。
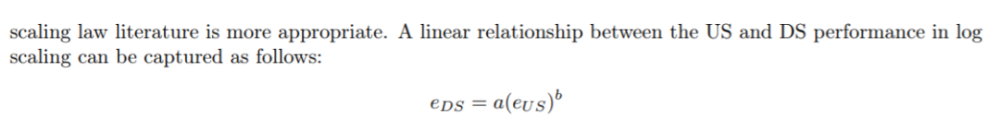
然而經過研究發現,情況是這樣的
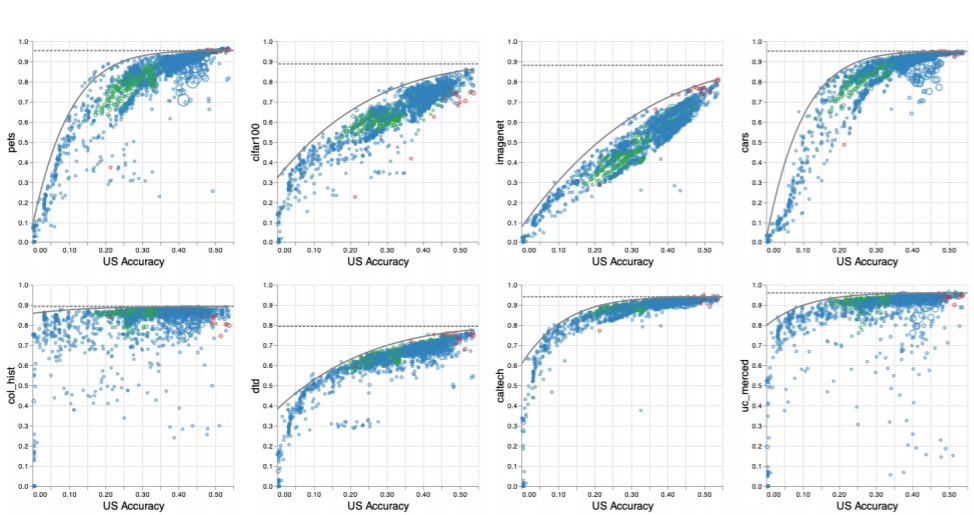
從圖中可以發現,下游任務在某些點,會發生飽和。但這些“飽和點”并不固定。因而文章推論,上下游之間的關系是非線性的。
數據、模型規模的擴大,倒是能提高上游性能。但是由于這種非線性關系的存在,提高上游的準確度的同時,下游準確度就不能夠保證了。
預訓練模型不能讓人們”一勞永逸“!
本文討論了 "預訓練 "的做法,這種措施旨在節省計算資源,減少從零開始訓練大規模數據所需的時間。
預訓練可以明顯提高模型的魯棒性和準確性。但新的論文表明,即使在相對較短的預訓練模板中,但是考慮到特征的復雜性,預訓練模型不適合于所有情況。如果研究人員繼續依賴預訓練模型,可能影響到最終結果的準確性。
論文最后提到,”我們不能期望找到適用于所有下游任務的預訓練模型。"
規模有多大,就有多準確?
Geogle research 的研究結果對這一定論,勇敢說出了”不“,的確讓人們眼前一亮!是否會對整個AI研究領域,帶來突破性的進展呢?也許會由此帶動更多的相關研究,會不知不覺掀起另一波”浪潮“?咱們走著瞧!


















