













強化學習應用在自動駕駛中:一種通過人指導并基于優先經驗的方法
arXiv在2021年9月26日上傳的論文“Prioritized Experience-based Reinforcement Learning with Human Guidance: Methodology and Application to Autonomous Driving“,作者來自新加坡NTU(南洋理工)。

強化學習(RL)需要定義和計算來解決優化和控制問題,這可能會損害其發展前景。將人的指導引入強化學習是提高學習性能的一種很有前途的方法,本文建立了一個基于人指導的強化學習框架。
所提出的是一種在強化學習過程中適應人指導的 優先經驗重放(prioritized experience replay,PER) 機制,提高RL算法的效率和性能。為減輕人的繁重工作量,基于增量在線學習(incremental online learning)方法建立一個行為模型來模仿人。
作者設計了兩個具有挑戰性的自動駕駛任務來評估所提出的算法:一個是T-路口無保護左轉,另一個是高速堵車。
最近強化學習引入深度神經網絡提出了一些流行方法,如rainbow deep Q-learning, proximal policy optimization (PPO) 和 soft actor-critic (SAC), 能夠處理高維環境表征和泛化等。
不過問題是環境和智體的交互比較低效率。為此引入人的指導,有3個途徑:1)人的專家反饋,給行為打分(behavior score);2)人的干預,一般是reward shaping方法;3)人的演示,上下文中監督學習。
如圖是本文方法的RL算法框架:
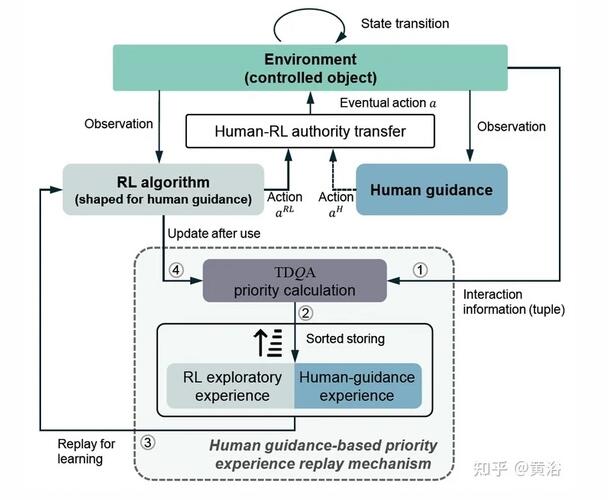
提出的基于人指導優先經驗回放(PER)機制中,TDQA表示提出的優先計算方案,即Time Difference Q-advantage,數字1-4表示數據的流向順序,動作信號的虛線表示該框架允許間歇性的人在環(human-in-the-loop )的指導。
強化學習基于離散MDP來定義交互過程,這里采用不帶策略的AC(actor- critic)架構。策略函數(即 actor )最大化價值函數Q,Q來自累計的未來reward,基于一個Bellman價值函數(即 critic )。
這個Bellman 價值函數只對最優策略進行評估,而不管執行交互的策略。 因此,RL 將策略評估過程和策略行為解耦,這使智體以一種不帶策略的方式更新狀態。
作者用神經網絡作為函數逼近來制定actor和 critic,然后可以通過損失函數實現目標。
傳統上,緩沖區存儲的經驗服從均勻分布,用均勻隨機抽樣從緩沖區獲取批量經驗,用于 RL 訓練。在有限經驗重放機制中,經驗受制于非均勻分布,實際優先級取決于TD誤差(temporal difference error)。
較大的 TD誤差表明,經驗值得在更高程度上學習。 因此,基于 TD誤差的優先經驗回放(PER)機制可以提高 RL 的訓練效率。
在強化學習的訓練中,采用了兩種人指導的行為方式:干預和演示。
干預 :人的參與者識別 RL 交互場景,并根據先驗知識和推理能力確定是否應該進行指導。 如果人參與者決定進行干預,可以操縱設備從 RL 智體(部分或全部)獲得控制權。 干預通常發生在 RL 智體做災難性操作或陷入局部最優陷阱。 因此,RL 可以學會避免干預出現的不利情況。
演示 :當干預事件發生時,人的參與者會執行行動,產生相應的獎勵信號和下一步狀態。 生成的轉換組(transition tuple)可以看作是一段演示數據,因為是由人策略而不是 RL 行為策略造成的。 RL 算法可以從演示中學習人的專家行為。
在 RL 智體與環境的標準交互中,RL 的行為策略會輸出探索環境的動作。一旦動作被發送到環境,交互的轉換組將被記錄并存儲到經驗重放緩存(buffer)。 特別注意的是,來自人的策略和 RL 策略的操作存儲在同一個緩沖區中。
由于先驗知識和推理能力,人的演示通常比 RL 行為策略的大多數探索更重要。 因此,需要一種更有效的方法來加權緩存的專家演示。 文中采用一種 基于優點的度量( advantage-based measure ) ,而不是傳統的優先經驗重放(PER) TD 誤差,以建立優先專家演示重放機制。
除了TD 誤差度量外,該優點度量(因為基于Q計算,故稱為 QA ,即 Q-advantage )也評估應該在多大程度去檢索特定的專家演示轉換組。通過 RL 訓練過程,RL 智體的能力發生變化,一個專家演示轉換組的優先級也隨之變化,這就產生了動態優先機制。整個機制稱為 TDQA ,把兩個度量組合成一個對人的指導測度。
優先機制引入了對價值函數期望估計的偏差,因為它改變了緩存中的經驗分布。 有偏的價值網絡對強化學習漸近性影響不大,但在某些情況下可能會影響成熟策略的穩定性和魯棒性。 作為可選操作,可以通過引入重要性采樣(importance-sampling )權重到價值網絡的損失函數,來退火偏差。
下面討論人的參與者在 RL 訓練環的行為:人的參與者可以干預該過程獲得控制權,并用專家行動替代 RL 智體行動;由于持續重復訓練情節和未成熟的 RL 策略,人的參與者在訓練過程中不斷進行演示顯得很乏味,因此間歇性干預(intermittent intervention)成為更可行的解決方案。 這種情況下,人參與者只會干預那些關鍵場景(災難行為或陷入局部最優)拯救 RL 智體并延長訓練時間。
這里采用reward shaping方法,可防止 RL 陷入那些人為干預的狀態。 然而,它僅在一個人為干預事件的第一時間觸發懲罰。 這背后的原理是,一旦人的參與者獲得控制權,其專家演示會慣性地持續一段時間,這里只有最初的場景被確認為關鍵場景。
下面把上述組件集成在一起,即優先人在環( Prioritized Human-In-the-Loop,即PHIL ) RL。具體來說,通過基于人指導的actor- critic框架,配備優先專家演示重放和基于干預的reward shaping 機制來獲得整體的人在環 (human-in-the-loop)RL 配置。 基于不帶策略 RL 算法,即雙延遲深度確定性策略梯度(twin delayed deep deterministic policy gradient, TD3 ),來實例化這個 PHIL 算法。 上述組件適用于各種 不帶策略的 actor-critic RL 算法。
最后,整個PHIL-TD3算法總結如下所示:

結合前面的PHIL-RL,需要一個人的策略模型。該模型通過模仿實際人參與者的行為策略,來減輕人在環 RL 過程的工作量。
雖然人參與者進行 PHIL-RL 對提高性能最有幫助,但過度參與會使人疲勞。 作者訓練了一個回歸模型,與 RL 運行同時模仿人類策略,這個策略模型在必要時可以替代人。
分析一下RL 訓練過程的人行為:人類干預間歇性地施加到環中,人演示逐漸補充到訓練集(緩存)中;考慮到這一點,利用在線-和基于增量-的模仿學習算法(即Data Aggregation,DAgger)訓練人策略模型,該算法不受離線大規模演示數據的收集影響。
注意:如果使用這個人策略模型與 PHIL 合作,模型的激活條件將根據特定環境手動定義。
下面討論如何應用在自動駕駛場景:選擇端到端問題的兩個應用,即T-路口無保護左轉和高速堵車。
如圖是自動駕駛任務的環境配置: a 在 CARLA 建立的 T -路口設計的無保護左轉場景; b 左轉場景鳥瞰圖,紅色虛線表示左轉軌跡; c 設計的在 CARLA 建立的高速公路擁堵場景; d 擁堵場景的鳥瞰圖,其中紅色虛線表示跟車軌跡。
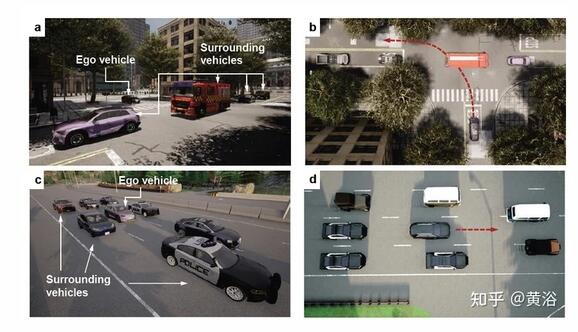
T-路口無保護左轉 :小路的自車試圖左轉并匯入主干道,路口沒有交通信號引導車輛;假設自車的橫向路徑由其他技術規劃,而縱向控制分配給 RL 智體;周圍車輛以 [4, 6] m/s 范圍隨機的不同速度進行初始化,并由intelligent driver model (IDM) 控制執行車道保持行為;所有周圍的駕駛員都具有侵略性,這意味著他們不會讓路給自車;所有車輛的控制間隔設為 0.1 秒。
高速擁堵 :自車陷入嚴重擁堵并被其他車輛緊緊包圍; 因此它試圖縮小與領先車的差距,并以目標速度進行跟車;假設縱向控制由 IDM 完成,目標速度為 6m/s,而橫向控制分配給 RL 智體;周圍車輛初始化速度范圍為 [4, 6] m/s,并由 IDM 控制以執行跟車行為;所有車輛的控制間隔設置為 0.1 秒;擁擠的周圍車輛覆蓋了車道標記,而自車道沒有特定的前車,在這種情況下可能導致傳統的橫向規劃方法無效。
下面定義RL的狀態
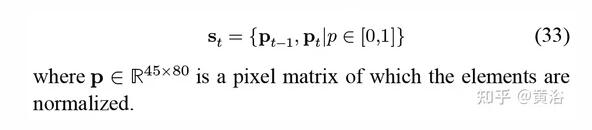
RL的動作對兩個場景是不同的:
T-路口左轉

高速擁堵

獎勵(reward)對兩個場景也是不同的:
T-路口左轉
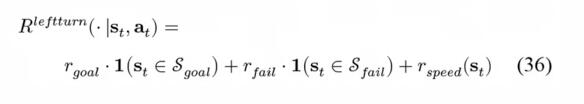
高速

價值和策略函數的近似采用Deep CNN,如圖所示:a)策略函數;b)價值函數
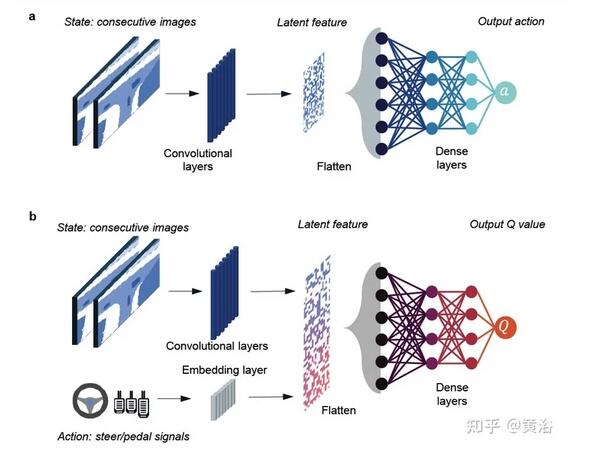
輔助函數:主要做車輛控制;當RL操縱方向盤時,縱向控制由IDM實現;當 RL 操縱踏板縫隙時,橫向運動目標是通過比例積分 (PI) 控制器跟蹤規劃的航路點。
實驗比較的基準算法是:
- IA-TD3:Intervention Aided Reinforcement Learning (IARL)
- HI-TD3:Human Intervention Reinforcement Learning (HIRL)
- RD2-TD3:Recurrent Replay Distributed Demonstration-based DQN (R2D3)
- PER-TD3:vanilla Prioritized experience replay (PER)
RL訓練和推理的實驗工作流如圖(a-b)所示:
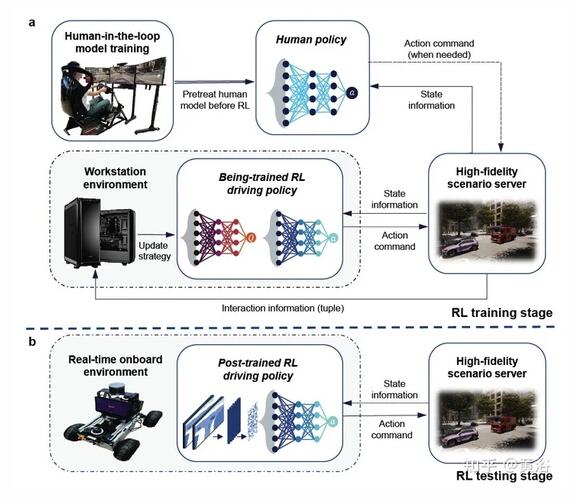
訓練 硬件包括駕駛模擬器和高性能工作站。駕駛模擬器用于收集人駕駛數據以訓練人的策略模型,工作站專門處理 RL 訓練。 采用高保真自動駕駛仿真平臺 CARLA來實現駕駛場景并生成RL-環境交互信息。
測試 硬件是機器人車輛。訓練后的RL策略在車輛的計算平臺上實現,通過無線網絡與CARLA服務器進行通信。車載 RL 策略從 CARLA 接收狀態信息并將其控制命令發回,遠程操作完成自動駕駛任務。機器人車輛旨在測試 RL 策略在當前車載計算和通信情況下是否有效。
部分實驗結果比較如下:
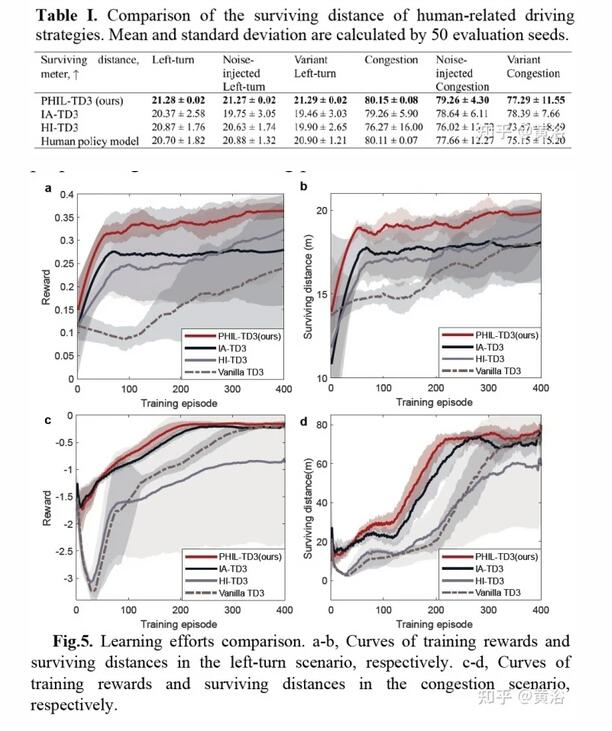
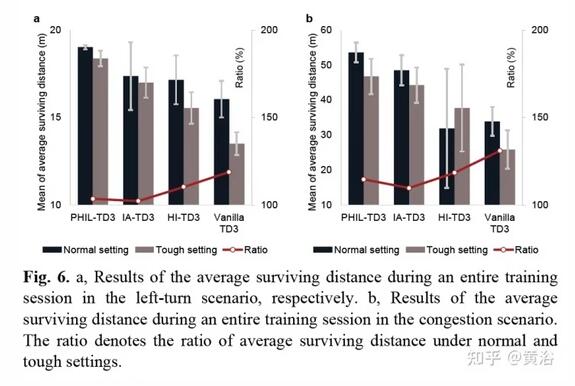

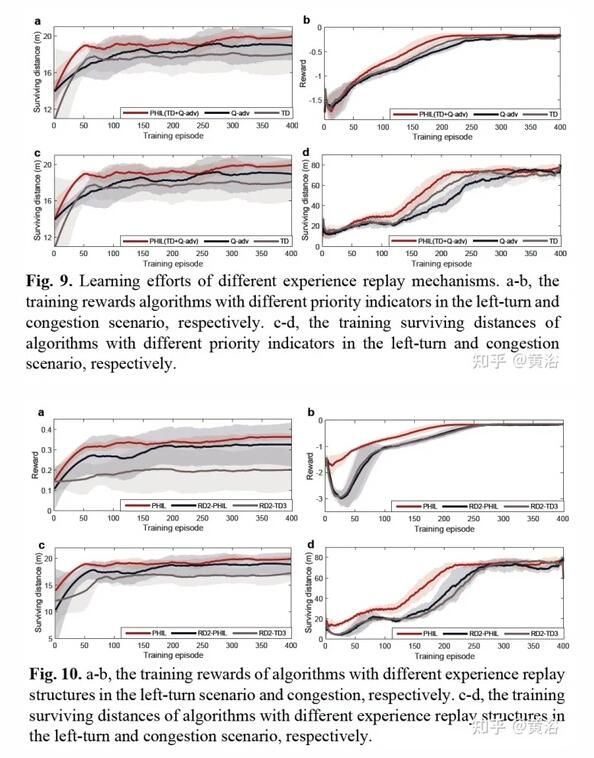
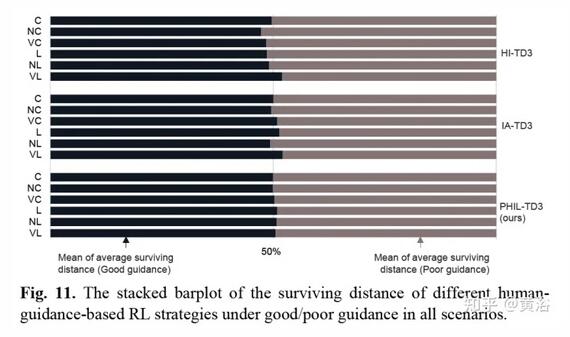
作者提出了一種算法 PHIL-TD3,旨在提高人在環 (human-in-the-loop )RL 的算法能力。 另外,引入了人的行為建模機制來減輕人參與者的工作量。 PHIL-TD3 解決兩個具有挑戰性的自動駕駛任務,即無保護T-路口左轉和高速擁堵。























