地平線提出AlphaDrive,首個基于GRPO強化學習和規劃推理實現自動駕駛大模型
OpenAI 的 o1 和 DeepSeek 的 R1 模型在數學,科學等復雜領域達到甚至超過了人類專家的水平,強化學習訓練和推理技術是其中的關鍵。而在自動駕駛,近年來端到端模型大幅提升了規劃控車的效果,但是由于端到端模型缺乏常識和推理能力,在處理長尾問題上仍然效果不佳。
此前的研究嘗試將視覺語言模型(VLM)引入自動駕駛,然而這些方法通常基于預訓練模型,然后在駕駛數據上簡單的采用有監督微調(SFT),并沒有在訓練策略和針對決策規劃這一最終目標進行更多探索。
針對上面的問題,我們提出了 AlphaDrive, 一種針對決策規劃的 VLM 的強化學習和推理訓練框架。

- 項目主頁:https://github.com/hustvl/AlphaDrive
- 論文鏈接:https://arxiv.org/abs/2503.07608
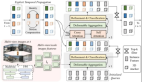
具體而言,AlphaDrive 提出了四種針對規劃的強化學習 GRPO rewards。另外,我們提出一種基于 SFT 和 RL 的兩階段規劃推理訓練策略。在強化學習階段,AlphaDrive 展出的涌現的多模態規劃能力,和 DeepSeek R1 的「Aha Moment」有相似之處,也證明了強化學習在自動駕駛大模型的應用潛力。據我們所知,AlphaDrive 實現了首次將基于 GRPO 強化學習和規劃推理引入自動駕駛規劃,在規劃性能和訓練效率上都取得顯著的進步。
AlphaDrive 解決的研究問題
當前已有一些將 VLM 應用于自動駕駛的研究,大致可以分為兩類,一類使用 VLM 實現對駕駛場景的感知理解,但是其主要關注感知任務;另一類則是直接使用 VLM 實現決策規劃,但是不像端到端模型專門用于預測軌跡。大模型的輸出空間是語言空間,并不擅長精確的數值預測,因此使用大模型直接預測軌跡可能會導致次優的結果,甚至有安全隱患;另一些工作則利用大模型做高維規劃,即通過自然語言的形式規劃自車未來的行為,例如「減速,向右變道」。這樣可以避免上述的缺陷,但是并沒有在訓練方法上進行更多探索。它們大多采用 SFT 的訓練方式,忽視了不同的訓練策略與規劃表現間的關系和訓練開銷問題。因此 AlphaDrive 主要嘗試解決如下的問題:
如何進一步提升大模型在自動駕駛決策規劃的效果?
采用推理技術的 OpenAI 的 o1 模型在數學,編程等領域能力突出。另外,最近火爆的 DeepSeek 的 R1 模型采用的 GRPO 強化學習技術,不僅讓大模型出現了 「涌現智能」的時刻,實現了頂級的性能,同時訓練開銷遠小于其他的同類模型。它們證明了推理技術和強化學習在大模型領域的巨大潛力。
因此,我們想要嘗試回答如下問題:如何將在通用大模型領域大放異彩的強化學習和推理技術應用于自動駕駛,尤其是決策規劃,從而提升大模型在自動駕駛任務上的表現,并降低訓練開銷。
如何設計針對駕駛規劃的大模型強化學習策略?
通過大量實驗,我們發現直接將現有的強化學習技術在自動駕駛規劃上效果不佳。我們認為主要有如下原因,首先,針對通用任務的強化學習 reward 設計并不適合于駕駛場景,例如對于視覺目標計數任務,reward 可以簡單的設計為判斷模型回答的正確與否。但是對于駕駛而言,雖然規劃也可以看作為多分類任務,但是由于不同駕駛行為的重要性存在區別,因此不能對于所有駕駛行為都賦予相同權重。
另外,不像數學或者 counting,規劃可能并不存在唯一的正確解,例如在一段空曠的直道上,你可以選擇勻速前進,也可以選擇加速前進。因此硬性的判斷模型規劃結果和實際的操作是否一致并不是最好的選擇。

如何將大模型 Reasoning 技術引入決策規劃?
在通用領域,像是數學或者編程,都擁有較多現成的 reasoning 數據可以利用,例如教科書的參考答案或者編程網站。但是在駕駛領域,目前幾乎沒有現成的決策推理過程的數據,采集這種數據的成本非常高昂,需要大量人工標注,因此推理技術的使用也很難直接復用現有方案。

AlphaDrive 的關鍵創新
- 我們提出了 AlphaDrive,一個用于自動駕駛高維規劃的視覺語言大模型,據我們所知,AlphaDrive 首次將基于 GRPO 的強化學習和規劃推理引入基于大模型的自動駕駛任務,大幅提升了模型的規劃表現和訓練效率。
- AlphaDrive 提出了四種強化學習 GRPO rewards,分別是規劃準確率 reward,action 權重 reward,輸出多樣性 reward 和規劃格式 reward。這些優化的 reward 設計讓 GRPO 更適合于自動駕駛規劃任務。
- 我們提出了基于知識蒸餾的 SFT 和 RL 的兩階段推理訓練策略,通過使用云端大模型生成的少量高質量規劃推理數據,相比于僅使用 RL 進行訓練或者沒有推理過程,AlphaDrive 達到了更好的規劃效果。
AlphaDrive 的實驗及應用效果
基于真實駕駛場景的大規模數據集上的實驗和消融驗證了 AlphaDrive 的先進性。與 SFT 訓練的模型相比,AlphaDrive 的規劃準確率顯著提升了 26%,并且在僅使用 1/5 的訓練數據的情況下,性能比 SFT 訓練的模型高出 35%。另外,在強化學習階段,AlphaDrive 展出的涌現的多模態規劃能力,和 DeepSeek R1 的「Aha Moment」有相似之處,證明了強化學習在自動駕駛大模型的應用潛力。



未來探索方向
AlphaDrive 初步探索了大模型強化學習和推理技術在自動駕駛領域的應用。下一步,我們將嘗試將 AlphaDrive 從 VLM 拓展到 VLA,實現一個統一的理解、決策、規劃的自動駕駛大模型。