自動駕駛存在不確定性的運動規劃:基于強化學習的方法
arXiv上2021年10月1日上傳的論文“Motion Planning for Autonomous Vehicles in the Presence of Uncertainty Using Reinforcement Learning“,作者來自加拿大的華為諾亞實驗室和魁北克大學。

存在不確定性的運動規劃是開發自動駕駛車的主要挑戰之一。本文專注于有限的視野、遮擋和傳感距離限制導致的感知不確定性。通常是考慮遮擋區域或傳感器感知范圍之外的隱藏目標這個假設來解決這個問題,保證被動安全。然而,這可能導致保守的規劃和昂貴的計算,特別是需要考慮大量假設目標存在時。
作者提出一種基于 強化學習 (RL) 的解決方案,對最壞情況結果通過優化處理不確定性。這種方法和傳統的 RL 形成對比,傳統 RL代理只是試圖最大化平均預期獎勵,是不安全和魯棒的做法,而該方法建立在 分布RL (Distributional RL) 之上,其策略優化方法最大化隨機結果的下限。這種修正方式可以應用于一系列 RL 算法。作為概念驗證,這里應用于兩種不同的 RL 算法, Soft Actor-Critic (SAC) 和 Deep Q-Network(DQN) 。
該方法針對兩個具有挑戰性的駕駛場景進行評估,即 遮擋情況下的行人穿越 和 有限視野的彎曲道路 。該算法用 SUMO 交通模擬器進行訓練和評估。與傳統的 RL 算法相比,所提出的方法用于生成更好的運動規劃行為,與人類的駕駛風格相當。
RL方法主要有兩種:基于價值和基于策略。本文分別討論兩種方法的不確定性問題。
分布RL (論文“ Distributional reinforcement learning with quantile regression ,” AA Conference on Artificial Intelligence, 2018)旨在估計每個狀態-動作對可能結果的分布。 通過訪問獎勵分布,可以將一個狀態的價值指定為其可能結果的最壞情況(下限)。
在RL中估計隨機變量分布的一種有效方法是 分位數回歸 ( Quantile Regression,QR) ,用 N 個分位數定義的分布,其第一個分位數是可能的獎勵近似下限。這種方法, QR-DQN ,可以應用于任何包含價值函數的RL算法。 為此,需要增強價值函數,估計 N 個分位數,近似其分布。
用分位數回歸(QR)來估計分位數價值時,回歸過程會得到價值從最低到最高的排序。 因此,直接使用第一個價值作為下限估計。這個方法,稱為 保守QR-DQN(CQR-DQN) 。
另一種 RL 算法 SAC(見論文“ Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor ,” ICLR 2018),遵循 Actor-Critic 框架。它 訓練 Q -網絡估計遵循策略的價值,并訓練策略最大化 Q -值。 這里用分位數回歸(QR)擴展 SAC,即 QR-SAC 。
實際上,Q -網絡被擴展估計分位數。 然后類似于 QR-DQN,估計狀態-動作對的 Q-值,即分位數第一個價值作為下限估計。依此,修改QR-DQN的分布Bellman方程,可以得到Critic的分布SAC Bellman更新規則。該方法,稱為 保守QR-SAC(CQR-SAC) 。
在輸入的感知中,OGM 提供有關遮擋區域的信息,道路網絡的光柵圖像,識別道路使用者可能存在的位置。 此外,希望運動規劃器從 OGM 中感知目標,無需提供場景目標的任何明確信息。為解決這個運動規劃問題,在 Frenet 框架搜索最佳軌跡。 這類似于 Frenet 框架的傳統運動規劃方法。
在 Frenet 框架中,沿著車道中心的軌跡變為直線軌跡, 簡化了搜索空間。每個軌跡包括當前速度、當前橫向偏距、最終速度和最終橫向偏距。該軌跡建立之后,車輛速度和橫向位置在預定的時間內按照一階指數軌跡從初始值逐漸變化到最終值。
RL智體的輸入包括 2 幀 (當前和之前時刻)OGM、道路網絡的當前幀和當前速度,獎勵定義為安全、舒適度和移動性等方面。
一個思路,從RL角度來看,如果智體動作被定義為軌跡,假設智體在未來狀態的動作與當前狀態的動作相同,那么評估軌跡等效于估計 Q-值。這樣的算法分別記做 (CQR-DQN,CQR-SAC)價值版 。
另一個思路,在 RL 公式中未來狀態的動作(軌跡)取決于智體策略,在知道未來動作可能與當前動作不同的情況下進行評估。 如果遵循智體策略,分配給狀態-動作對的 Q-值是預期的獎勵。這樣的算法分別記做 (CQR-DQN,CQR-SAC)策略版 。
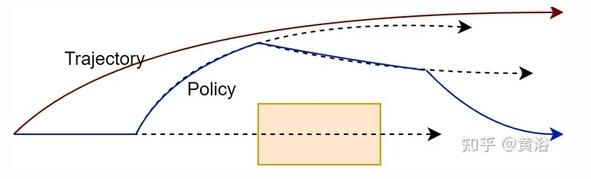
遵循和評估一個策略帶來更大靈活性,并且運動規劃器可能會找到更好的解決方案。如圖所示說明在評估軌跡與策略時要評估的路徑:
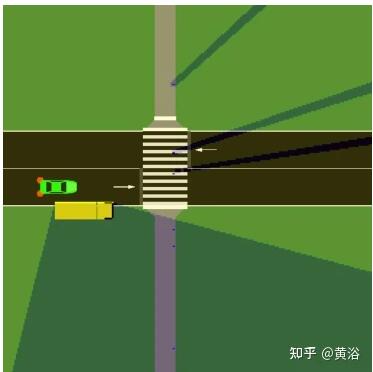
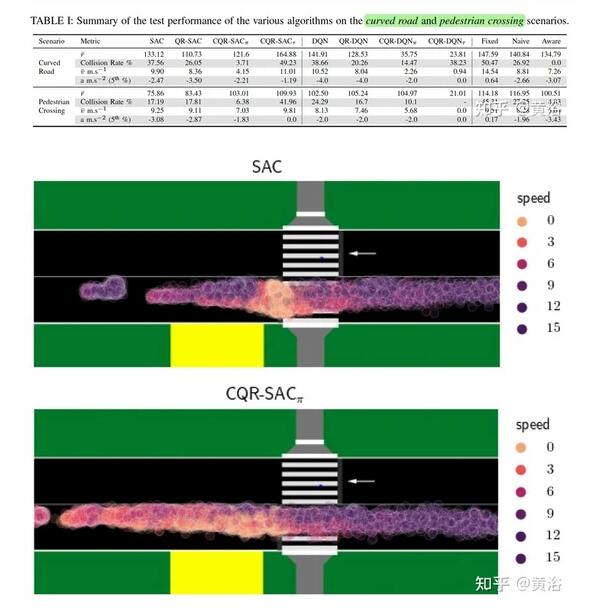
實驗分兩個場景。一是如圖的行人過馬路,有遮擋:
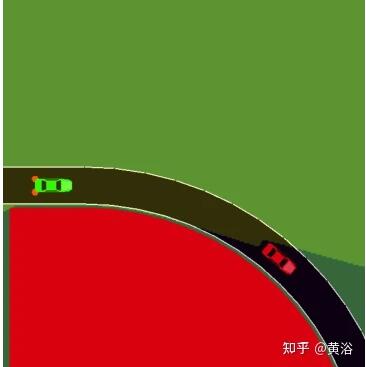
二是如圖彎曲道路造成的遮擋:
實驗采用SUMO模擬。比較的RL方法包括:SAC, QR-SAC, CQR-SAC策略版, CQR-SAC價值版, DQN, QR-DQN, CQR-DQN策略版, CQR-DQN價值版。
作為基準的規則方法有:固定fixed、幼稚naive和覺察 aware三種。
- 固定法 限速行駛,不考慮其他目標。
- 幼稚法 忽略遮擋,限速行駛,除非在其行駛路徑看到一個目標。 這種情況下,它會以恒定減速度剎車,最高可達 -4 [m/s2],結果是在目標前停住。
- 覺察法 采用知道遮擋的 IADSR 算法(論文“ What lies in the shadows? safe and computation-aware motion planning for autonomous vehicles using intent-aware dynamic shadow regions ,” ICRA, 2019)。 假設一個目標存在于遮擋區域,如果一個目標從遮擋區域出現,那么它剎車減速(以 -4 [m/s2] 減速度)到完全停止而不會發生碰撞。 此外,覺察法還會遠離遮擋機動以增加遮擋附近的視野。
實驗結果比較如下:其中下標Pai是策略版,下標Tao是價值版。
這項工作針對由遮擋引起不確定性的運動規劃問題,討論在實際 RL 問題中,采用最大化最壞情況獎勵的策略如何更好地匹配所需行為,利用分布RL 最大化最壞情況獎勵而不是平均獎勵。用分位數回歸(QR)擴展 SAC 和 DQN,找到優化最壞情況的動作。
用 SUMO 模擬環境設計和評估一組遮擋情況下的自動駕駛運動規劃器。提出基于 CQR-SAC和 CQR-DQN 的運動規劃器,避免與被遮擋視圖發生碰撞,無需微調獎勵函數。
未來的工作想應用于更復雜和多樣化的環境,包括交叉路口、環形交叉路口以及包含移動車輛的場景。工作期望是,自車智體可以從其他車輛的行為隱式地推斷出遮擋區域的狀態。