













Facebook在ICCV 2021 發布兩個3D模型,自監督才是終極答案?
長久以來CV的訓練一直停留在二維數據上,三維數據因為標注成本高等原因都需要專業人員來開發專用模型。Facebook在ICCV 2021 發布兩個3D模型3DETR和DepthContrast,將模型的通用性全面升級,也許標志著CV研究全面進入三維時代!
從大規模的數據中進行預訓練,在計算機視覺中得到了廣泛應用,也是在特定任務上得到高性能模型的基礎。
但這種方法有一個致命缺陷,那就是如果目標數據類型還沒有大量標注數據的話,就沒辦法使用這種模式。
例如3D 掃描、識別的標注數據集就很稀缺,主要是因為3D 數據集的標注十分耗時,并且用于 3D 理解的模型通常依賴于與用于訓練的特定 3D 數據集的手工架構設計。
在 ICCV 2021 上,Facebook AI提出了兩個新模型3DETR和DepthContrast,這兩個互補的新模型可促進3D理解并更容易上手。新模型建立了簡化的3D理解的通用架構,并且能夠通過不需要標簽的自監督學習方法來解決這些問題。
代碼目前也已開源。

出于各種原因,目前的CV 模型還主要集中在二維圖片,但構建機器以了解有關世界的 3D 數據非常重要。例如自動駕駛汽車需要 3D 理解才能移動并避免撞到障礙物,而 AR/VR 應用程序可以幫助人們完成實際任務,例如可以可視化沙發是否適合客廳。
來自 2D 圖像和視頻的數據表示為規則的像素網格,而 3D 數據則反映為點坐標。由于 3D 數據更難獲取和標記,因此 3D 數據集通常也比圖像和視頻數據集小得多。這意味著它們通常在整體大小和它們包含的類或概念的數量方面受到限制。
以前,專注于 3D 理解的從業者需要大量的領域知識來調整標準的 CV 架構。單視圖 3D 數據(取自一臺同時記錄深度信息的相機)比多視圖 3D 更容易收集,后者利用兩個或更多相機記錄同一場景。多視圖3D數據往往是通過對單視圖3D進行后處理生成的,但是這個處理步驟有失敗的可能,一些研究人員估計,由于源圖像模糊或相機運動過度等原因,這個失敗率可能高達 78%。
DepthContrast 主要解決了這些數據上的問題,因為它可以從任何 3D 數據(無論是單視圖還是多視圖)訓練自監督模型,因此消除了處理小型未標記數據集的挑戰。一般的CV 模型即使是對大量 2D 圖像或視頻進行預訓練也不太可能為 AR/VR 等復雜應用產生準確的 3D 理解。

https://arxiv.org/abs/2101.02691
自監督學習一直是研究界和FAIR的主要興趣領域, DepthContrast也是業界在不使用標記數據的情況下學習強大3D表示的最新嘗試。這項研究繼承自FAIR 之前的工作PointContrast,也是3D的一種自我監督技術。
現在獲得3D數據的機會很多。傳感器和多視圖立體算法通常為視頻或圖像提供補充信息。然而,理解這些數據以前一直是一個挑戰,因為3D數據具有不同的物理特性,這取決于它的獲取方式和位置。
例如,與來自室外傳感器(如 LiDAR)的數據相比,來自商用手機傳感器的深度數據看起來非常不同。AI研究中使用的大多數3D數據都是以單視圖深度圖的形式獲取的,這些數據通過為3D registration的步驟進行后處理以獲得多視圖3D。先前的工作依賴于多視圖3D數據來學習自監督特征,訓練目標主要考慮3D點對應關系。
雖然將單視圖數據轉換為多視圖數據的失敗率很高,但DepthContrast表明僅使用單視圖3D數據就足以學習最先進的3D特征。
使用3D數據增強可以從單視圖深度圖生成略有不同的3D深度圖。DepthContrast通過使用對比學習來對齊從這些增強深度圖獲得的特征來實現這一點。
并且研究結果表明該學習信號可用于預訓練不同類型的3D架構,例如PointNet++和Sparse ConvNets。
更重要的是,DepthContrast可以應用于任何類型的3D數據,無論是在室內還是室外,單視圖還是多視圖。我們的研究表明,使用DepthContrast預訓練的模型在ScanNet 3D檢測基準上絕對是最先進的。
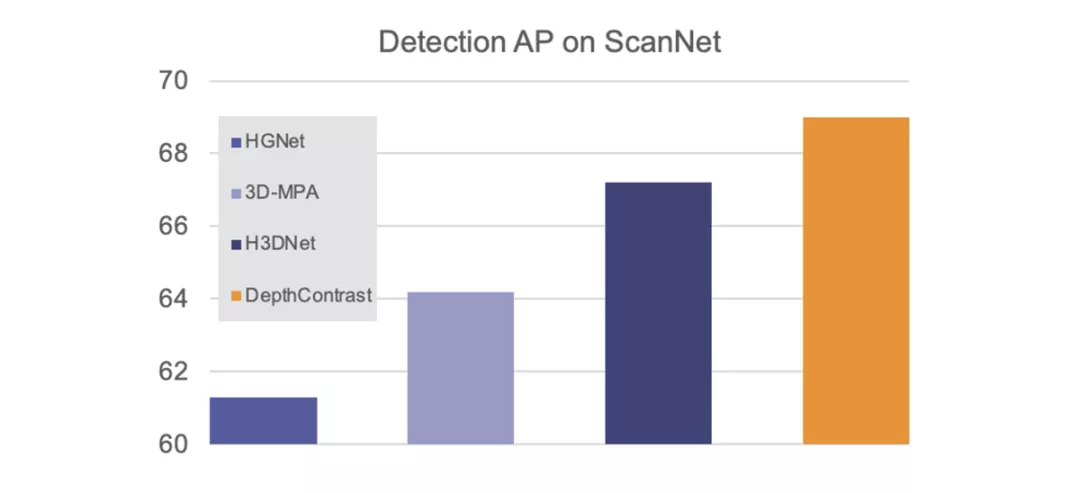
DepthContrast的功能在形狀分類、對象檢測和分割等任務的各種3D基準測試中提供了增益。

DepthContrast表明自監督學習也有希望用于3D理解。事實上,DepthContrast分享了學習增強不變特征的基本原理,該原理已被用于支持自監督模型,例如Facebook AI的SEER。
第二個工作3DETR是3D Detection Transformer的縮寫。該模型是一種基于Transformer的簡單三維檢測和分類架構,可作為檢測和分類任務的通用三維模型,該模型簡化了用于訓練3D檢測模型的損失函數,更容易實現。它的性能也相當于或超過了依賴于手動調整的3D架構和損耗函數的現有最先進的方法。

https://arxiv.org/abs/2109.08141
3DETR將三維場景(表示為點云或一組XYZ點坐標)作為輸入,并為場景中的對象生成一組三維邊界框。這項新的研究建立在VoteNet和Detection Transformers(DETR)的基礎上,其中VoteNet是FAIR在3D點云中檢測物體的模型,DETR是Facebook AI為重新定義物體檢測挑戰而創建的一種更簡單的架構。

為了實現2D檢測的飛躍,Facebook AI之前的研究確定了兩個重要的變化,需要解決Transformer的3D理解工作,還需要非參數查詢嵌入和傅立葉編碼。因為點云在大量空白空間和噪聲點之間具有不同的密度,所以這兩種設計決策都是必需的。
3DETR使用兩種技術來處理此問題,與DETR和其他變壓器模型/DETR中使用的標準(正弦)嵌入相比,傅里葉編碼是表示XYZ坐標的更好方法。
其次,DETR使用一組固定的參數(稱為查詢)來預測對象的位置,研究結果發現此設計決策不適用于點云。取而代之的是,我們從場景中采樣隨機點,并預測相對于這些點的對象。實際上沒有一組固定的參數來預測位置,而是隨機點采樣適應3D點云的不同密度。
使用點云輸入,Transformer編碼器生成場景中對象形狀和位置的坐標表示通過一系列的自注意操作來捕獲識別所需的全局和局部上下文。例如,它可以檢測3D場景的幾何特性如放置在圓桌周圍的椅子的腿和靠背。

Transformer解碼器將這些點特征作為輸入并輸出一組 3D 邊界框,它對點特征和查詢嵌入應用了一系列交叉注意操作。解碼器的自注意力表明它專注于對象以預測它們周圍的邊界框。
Transformer編碼器也足夠通用,可以用于其他3D任務,例如形狀分類。
總的來說,3DETR比之前的工作更容易實現。在3D基準測試中,3DETR的性能與之前手工制作的3D架構相比也有優勢。它的設計決策也與之前的3D工作兼容,使研究人員能夠靈活地將3DETR中的組件適應他們自己的pipeline。
從幫助機器人導航世界到為使用智能手機和未來設備(如AR眼鏡)的人們帶來豐富的新VR/AR體驗,這些模型都具有巨大的潛力。
隨著手機中3D傳感器的普及,研究人員甚至可以從自己的設備上獲取單視圖3D數據來訓練模型。深度對比技術是以自我監督的方式使用這些數據的第一步。通過處理單視圖和多視圖數據類型,DepthContrast大大增加了3D自監督學習的潛在使用案例。
自監督學習仍然是跨文本、圖像和視頻學習表示的強大工具。現在,大多數智能手機都配備了深度傳感器,這為提高3D理解和創造更多人可以享受的新體驗提供了重要機會。



















