交大ACM班畢業生在Google的新工作:自動寫Excel的表格公式
表格版的公式生成器來了!交大ACM班畢業生,伯克利博士陳昕昀在Google帶來了她在ICML 2021的新工作,能夠自動幫你補全公式,準確率在測試階段已達57.4%。目前Google Sheets已上線該功能,快去試用吧!
Excel可以說是最熟悉的陌生人了,每天都在使用,但高級用法卻說不上來幾個。
寫公式就是Excel的一個重要功能,公式可以讓用戶對數據進行復雜的分析和轉換。但盡管表格中的公式語言比編程語言更容易學習,但編寫這些公式仍然很復雜,并且一個符號沒注意可能就會導致錯誤。
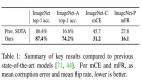
Google在2014年時開發了一個工具Smart Autofill,能夠自動識別表格的pattern來填充每一列的缺失值,主要方法使用機器學習算法來預測新數據。
例如,一個表格中包含了所用車輛的四個特征:年份、英里數、車門數和車輛類型(汽車或卡車),根據這四個特征制定車輛的價格。這是一個典型的數據分析預測的場景,可以使用算法根據表格內已經提供的數據(作為訓練集)來估計缺失的價格。
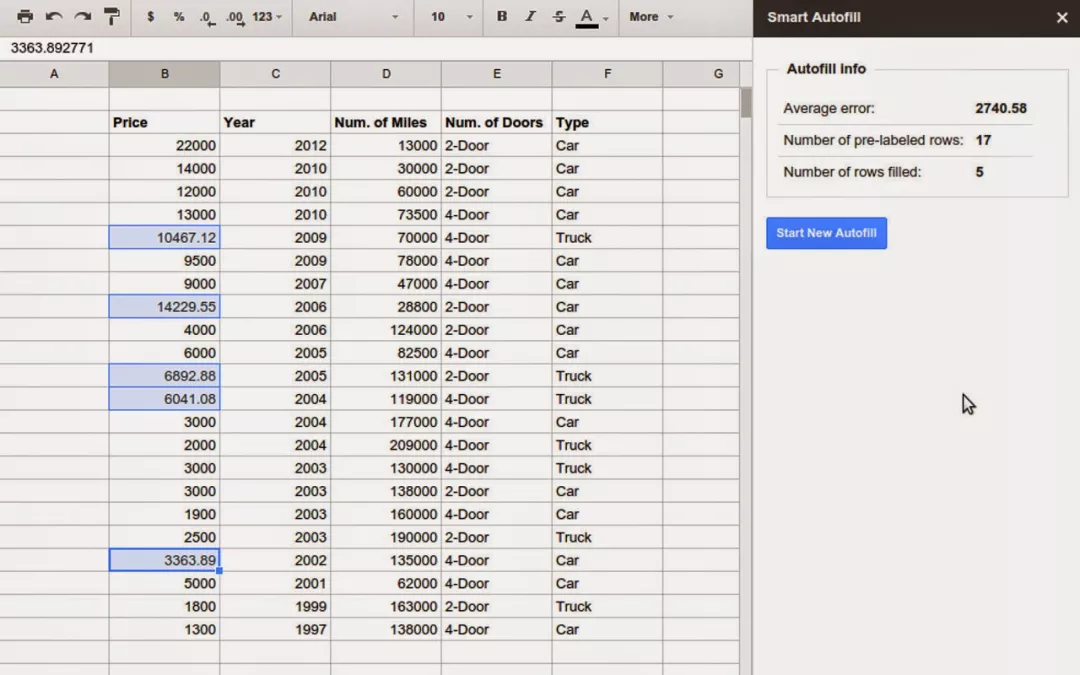
這個工具雖好,但它卻無法學習到復雜的公式,并且人工修正也十分麻煩。
時間來到2021年,借助BERT在序列模型上的威力,Google在ICML 2021上提出了一個新模型,能夠基于目標單元周圍的上下文自動生成公式。

論文的第一作者是陳昕昀,目前是加州大學伯克利分校的在讀博士,由Dawn Song教授指導。本科畢業于上海交通大學ACM班,獲得計算機科學學士學位。目前是Deepmind的一名研究實習生,曾于2019年、2020年在Google Brain做實習生。主要研究興趣包括神經網絡程序綜合和對抗機器學習。
當用戶開始在目標單元格中編寫帶有「=」符號的公式時,系統通過學習歷史表格中公式的模式,為該單元格生成可能的相關公式。該模型使用目標單元格的相鄰行和列中的數據以及標題行作為上下文。
它首先將相鄰單元和標題單元組成的表格的上下文結構編碼為一個embedding,然后使用該上下文嵌入生成所需的表格公式。
公式生成部分包括兩個組件:
- 運算符序列(例如,sum、if等);
- 應用運算符的表格范圍(例如A2:A10)。
目前Google Sheets 的用戶已經可以正式使用這個功能了!
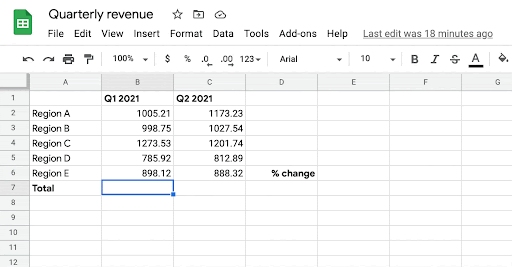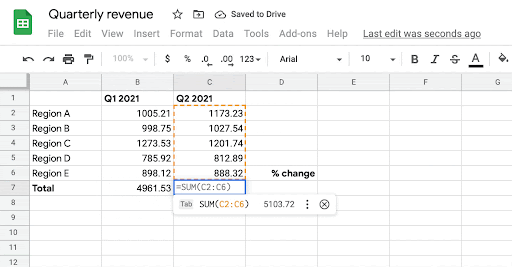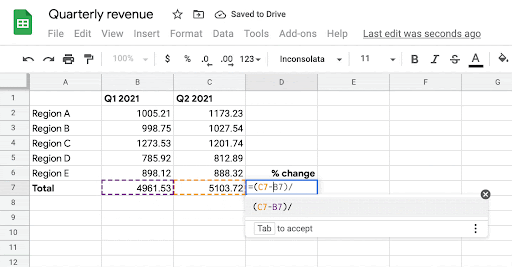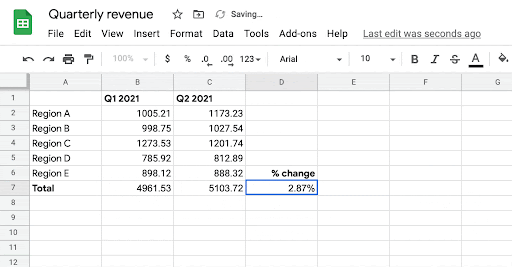
模型使用的架構仍然是encoder-decoder,這個結構也讓研究人員能夠靈活地將多種類型的上下文信息(例如包含在相鄰行、列、標題等中)嵌入到編碼器中,解碼器可以使用該結構生成所需的公式。
為了計算表格上下文的embedding,它首先使用基于BERT的模型架構對目標單元附近的多行(以及標題行)進行編碼。每個單元格中的內容包括其數據類型(如數字、字符串等)和值,同一行中的單元格內容被級聯到一個token序列中以便輸入到BERT encoder。
類似地,模型還會對目標單元格左側和右側的幾列進行編碼,然后在兩個 BERT 編碼器上執行行和列卷積以計算上下文的聚合表示。
解碼器則使用LSTM生成所需的目標公式作為token序列。首先模型預測出由公式運算符組成的公式結構(formula-sketch),然后使用與目標單元格相關的單元格地址生成相應的范圍。
模型還利用注意力機制來計算表頭和單元數據上的注意力向量,在做出預測之前,直接將這些注意力向量連接到LSTM輸出層。
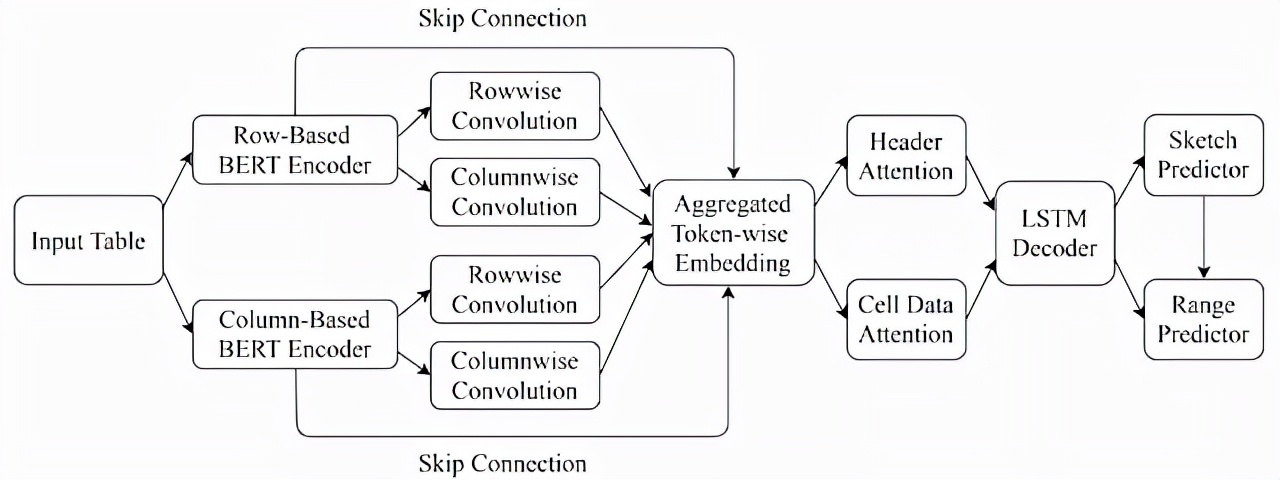
除了利用相鄰行和列中的數據外,該模型還利用來自頂層工作表結構(如標題)的其他信息,使用tpu進行模型預測,從而保證了以低延遲的效果生成公式建議,并且能夠在較少的機器上處理更多的請求。
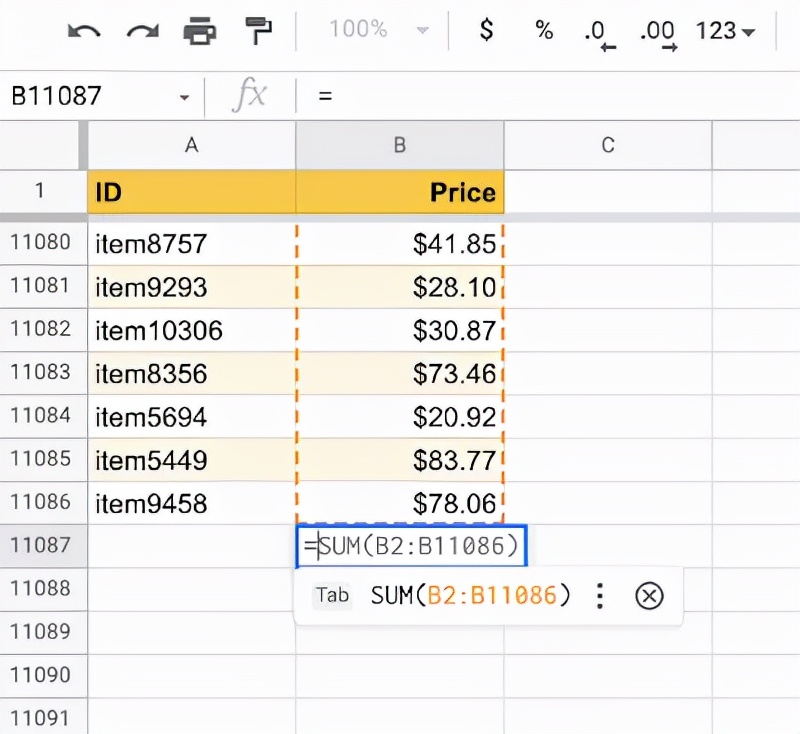
模型的訓練數據集主要是一個由Google創建并與Google共享的電子表格語料庫。數據集包含4.6萬張谷歌表格,其中4.2萬張用于訓練,2300張用于驗證,1700張用于測試。
實驗結果表明,該模型具有42.5%的完整公式精度和57.4%的完整公式框架精度,這兩個指標的準確率足夠高,足以支撐產品上線服務于初期用戶。并且隨著產品收集到更多數據,精度肯定還會上升。
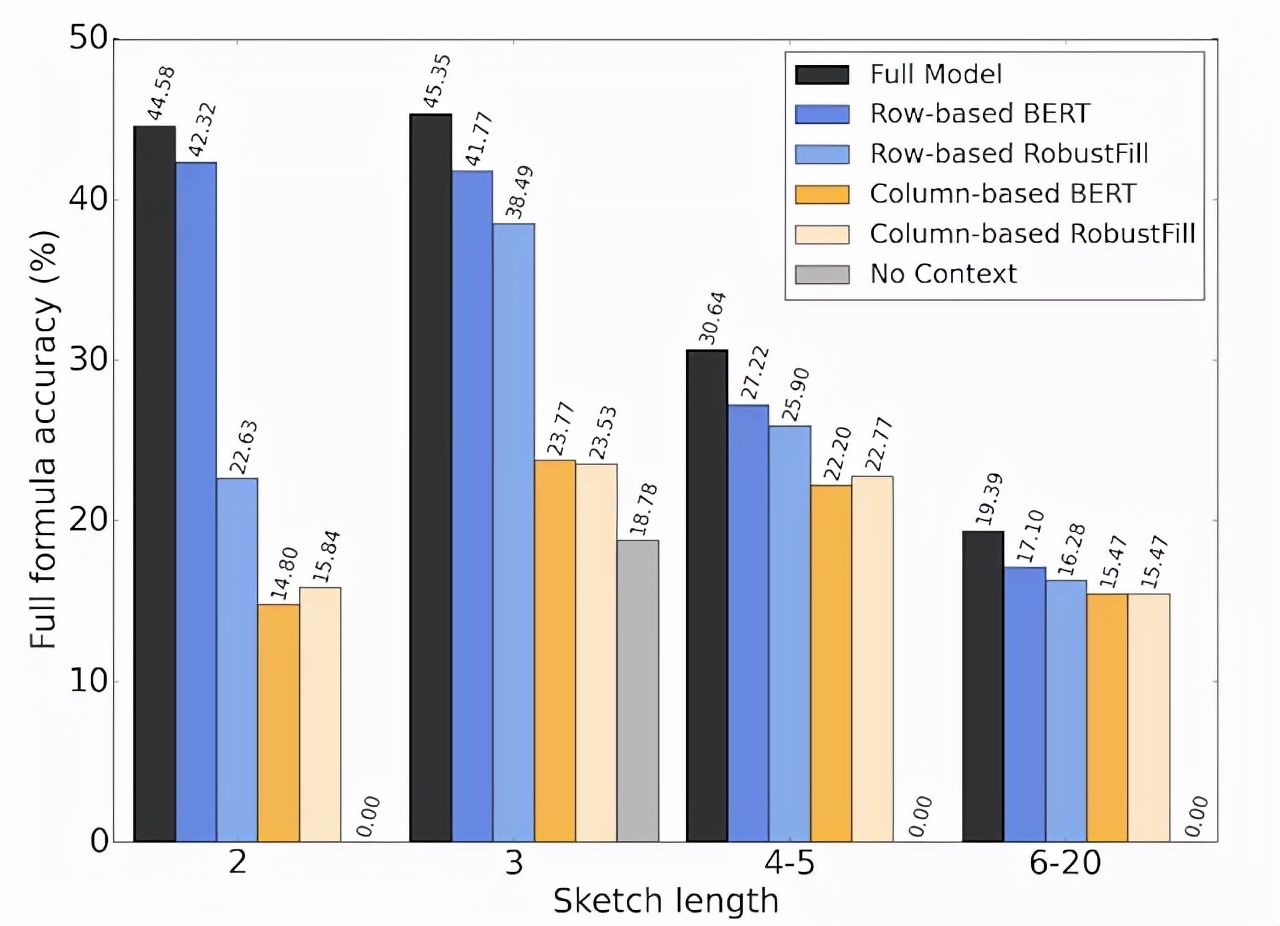
研究人員還進行了一項消融實驗,通過去除不同的組件來測試模型的幾種簡化版本,發現基于行和列的上下文嵌入以及標題信息對模型的性能至關重要。
未來可能會有更多基于這方面的研究,包括設計新的模型架構來合并更多表格結構,以及擴展模型以支持電子表格中bug檢測和自動圖表創建等更多應用。