從引力波探測到RNA測序,AI如何加速科學發現
本文轉自雷鋒網,如需轉載請至雷鋒網官網申請授權。
越來越復雜的實驗和日益增長的數據為科學探索帶來了新的挑戰,而實驗表明,機器學習,尤其是深度神經網絡架構的通用性能夠解決廣泛且復雜的問題, ImageNet 等大型數據集的激增,引導了許多不同深度學習方法的深入探索。
這篇綜述論文重點關注機器學習和實驗設計的融合,以及如何通過加速數據處理、實時決策來解決關鍵的科學問題。
在過去幾年,許多機器學習的進步源于異構計算硬件的使用,特別是圖形處理器(GPUs)使大型機器學習算法得以快速進步。經過大數據集訓練的AI模型已經能夠執行復雜的任務,同時,以減少計算量而實現快速和高效訓練的新型深度學習算法也開始越來越多的出現。
強大的機器學習技術與實驗設計的結合,可以縮短科學發現的時間,從嵌入實時特征到跨分布式網絡,計算數據中心的大規模機器學習在許多不同的科學應用實驗上取得大的跨越。不過,高效的解決方案依然需要領域專家、機器學習研究人員和計算機架構設計師之間的共同合作。
隨著機器學習工具變得越來越復雜,如何構建大模型來解決復雜的問題成為了新得關注點,例如語言翻譯和語音識別,它們的出現使得科學應用在快速發展中廣泛收益。目前這些應用已經出現多樣化,因為人們不得不意識到如何調整他們的科學方法從而更好地利用人工智能的好處,包括人工智能對事件的實時分類能力,如識別粒子碰撞或引力波合并;包括系統控制,如來自等離子體和粒子加速器的反饋機制的響應控制。在這些所有情況下,機器學習都是以設計目標為驅動因素的。
考慮到文章篇幅,我們將從三個部分對整篇綜述報告進行呈現,第一,機器學習如何探索廣泛的科學問題;第二,快速機器學習作為一種顛覆性技術,如何改變我們處理數據的方式,通用的數據表示法和實驗程序有哪些。第三,從算法設計到系統架構的硬件對機器學習進行整體設計。
1、機器學習應用:從基礎物理,醫學工程到邊緣計算
隨著科學生態系統規模的快速增長,數據處理和新范式需要集成到系統設計層面來完成。通過復雜數據處理過程的研究,作者發現,不同領域和架構之間實現機器學習可能會有很大差異,但仍然具有相似的底層數據表示和集成機器學習的需求。報告中列舉了大量科學領域的應用案例,涵蓋現有技術和未來需求。接下來,我們將重點介紹機器學習在物理學、生物醫學工程學以及無線網絡和邊緣計算三個領域的應用現狀和挑戰。
基礎物理學
正如愛因斯坦在 1916 年預測的那樣,引力波在廣義相對論中表現為時空度量的變化,并在時空結構中以光速進行傳播。例如,美國激光干涉引力波天文臺(LIGO)、歐洲“處女座”(Virgo)引力波探測器和日本神岡引力波探測器(KAGRA)均采用公里級激光干涉儀網絡探測引力波。
引力波為基礎物理研究提供了一種獨特的方法,包括在強場域測試廣義相對論、引力波的傳播速度和極化、物質在核密度下的狀態、黑洞的形成、量子引力效應等,它以一種與電磁和中微子天文學相輔相成的方式,打開了全新觀察宇宙的窗口。在未來的觀察中,LIGO、Virgo 和 KAGRA 將探測到越來越多的引力波后備,但這對當前的檢測框架提出了計算挑戰,該框架依賴于匹配濾波技術,需要將來自模擬的參數化波形(模板)與引力波時間序列數據相匹配 。
隨著儀器低頻靈敏度的提高,以及引力波搜索參數空間擴展到自旋效應和低質量致密物體,匹配濾波尺度將變差。為了估測引力波的物理特性,迄今為止一直使用隨機貝葉斯后驗采樣器(比如馬爾可夫鏈蒙特卡羅法和嵌套采樣法)。這些分析方法可能需要數小時到數天才能完成,搜索和參數估計也產生了不可避免的延遲,進而可能阻礙時間敏感源(如雙星、超新星和其他未知系統)的電磁跟蹤。
此外,引力波瞬態的觀測也容易受到環境和儀器噪聲的影響。瞬態噪聲偽影可能被誤識為潛在來源,特別是當引力波瞬態具有未知的形態時(例如超新星、中子星故障)。儀器噪聲譜中的線路噪聲會影響對連續引力波(如自旋中子星)和隨機引力波(例如未解的致密雙星系統引力波的天體物理背景)的搜索。這些噪聲源很難模擬,目前的噪聲減除技術不足以去除更復雜的噪聲源,如線路噪聲和非平穩噪聲源。
近年來,機器學習算法在引力波物理學的不同領域進行了探索。卷積神經網絡已被應用于探測和分類二元結的引力波、 超新星核坍塌的爆發引力波以及連續引力波;遞歸神經網絡(RNNs)的自動編碼器使用無監督策略檢測引力波;FPGA遞歸神經網絡在引力波低延遲檢測方面發揮著潛力。
此外,概率生成機器學習模型用于引力波參數估計的后驗采樣,在模擬數據上取得與貝葉斯采樣器相當的性能,大大縮短了完成時間。機器學習算法也被用于提高引力波數據質量,減少噪聲。瞬態噪聲偽影可以通過時頻變換和恒Q變換或檢查LIGO的輔助通道來進行識別和分類。
盡管機器學習算法在引力波數據分析中顯示出了很大的潛力,但其中許多算法仍處于概念驗證階段,尚未成功應用于實時分析。目前需要努力的方向是,為了降低低延遲分析創建計算基礎設施,提高訓練數據的質量(例如擴展參數空間,使用更真實的噪聲模型),并更好地量化這些算法在較長的數據延伸上的性能。
生物醫學工程
由于高分辨率和高通量生物醫學設備的進步,我們已經看到生物醫學數據的爆炸式增長,如生物醫學圖像、基因組序列和蛋白質結構。各種機器學習算法已經被廣泛應用于醫療場景中,如AI增強現實顯微鏡能夠自動分析細胞圖像和實時表征細胞。機器學習用硅片預測熒光標記、無標記罕見細胞分類、形態表征和RNA測序。對于原位細胞分選、實時治療反應預測和增強現實顯微鏡輔助診斷,深度學習模型的數據結構也能夠大幅提高速度和效率。
現階段,機器學習臨床應用面臨的主要挑戰是訓練和測試數據不足。對于需要專家知識的超大圖像和視頻數據集,醫學數據標注過程既耗時又昂貴。訓練模型推理的延遲也給實時診斷和手術操作帶來了計算困難,而時間關鍵型醫療保健的服務質量要求小于300毫秒,就像實時視頻通信一樣。為了達到每秒60幀(FPS)的高質量醫療視頻,深度學習模型的效率和性能變得至關重要。
推理精度和速度是機器學習算法需要改進的主要方面。一些先進的機器學習模型可以達到很高的推理速度。如常用于醫學成像的對象檢測模型YOLOv3-tiny,可以在標準數據集上以超過200 FPS的速度處理圖像;基于GPU和FPGA的分布式無線傳感器網絡和基于5G高速Wi-Fi的機器學習模型都部署在醫療AI應用中。用于腦卒中、血栓形成、結腸息肉、癌癥和癲癇快速診斷的機器學習模型顯著減少了病灶檢測和臨床決策的時間。實時人工智能輔助手術可以改進圍手術期工作流程,實現視頻分割、手術器械檢測、組織變形可視化。高速機器學習在遠程診斷、手術和監測等數字健康領域發揮著至關重要的作用。
無線網絡和邊緣計算
在許多科學研究中,無線設備和服務已經成為收集和傳遞大數據的關鍵工具。此外,移動信息已被證明在了解人類活動及其對環境和公共健康的影響方面十分有用。數據流量的指數級增長給無線基礎設施帶來了巨大的壓力。特別是,小區間干擾大大影響了可靠性和延遲性。為了滿足用戶對數據通信和增值AI/機器學習業務的需求,無線提供商必須:1) 開發更智能的無線電資源管理學習算法,以適應復雜多變的通信量和干擾條件; 2)在邊緣設備上實現大量機器學習/AI計算和功能,以達到更低的延遲和更高的通信效率。
機器學習模型的常規實現,尤其是深度學習算法,遠遠落后于實用程序的數據包級動態。為了提高效率,現有的機器學習/AI服務通常在云中執行,但代價是通信開銷大和延遲高。無線網絡和邊緣計算面臨的主要挑戰是如何構建可以在小型蜂窩接入點內以低于10毫秒的低延遲執行復雜任務的計算平臺。
研究人員提出了許多種學習算法,希望通過神經網絡完成特定的無線電資源管理任務。最初訓練神經網絡控制電力傳輸采用的是監督學習。最近,有人提議采用深度強化學習可以更好地改善通路和網絡的不確定性問題,而且只需要少量先驗訓練數據。
后來許多工作開始集中在邊緣計算和深度學習間的融合。有研究人員使用聯邦學習的方式訓練AI模型,而不是將所有數據發送給中央控制器進行訓練。由于缺乏既快速又高效的實用型ML/AI解決方案,上述工作基本上停留在仿真階段。更具體地說,開發一種計算平臺,使得該平臺能夠以小于10ms的速度執行復雜ML模型,且可以配置在小型小區接入點是現階段的主要目標。
2、數據處理的三種主要形式
實時、加速的人工智能推理有望在當前和未來的科學儀器領域提高探測能力。為設計高性能的AI系統,我們需要重點關注目標域機器學習算法的性能系數,它可能受到推理延遲、計算成本、可靠性、安全性和極端環境下運行能力的影響。例如,機器學習在大型強子對撞機上觸發需要延遲100 ns的稀有事件采集系統。
此外,先進科學儀器的實時分析必須不間斷地分配計算資源,無線醫療設備處理患者敏感信息必須保密。上述特征和特性為人們分辨出域和應用程序之間的差異和共性提供了可量化的準則。這些準則可以解決不同科學領域的不同需求。合適的數據表達是設計過程中重要一步,也是第一步,因為它能夠決定模型的應用場景。
數據表示
在特定領域使用的數據表達方式對計算系統和數據存儲均有影響。國際上,跨域數據表達可以分為原始數據和重構數據。數據表達方式通常因重建階段和數據處理管道中的上游步驟而異。當數據具有圖像性質時,現有的應用程序包括完全連接的CNN模型在內,通常將預處理的熟練特征變量作為輸入值或 CNN模型。現有的CNN算法發展成果得益于變量的精準性和高效性。
為了充分挖掘CNN模型的力量,使其信息損失降到最低水平,需要采用一種合適的原始數據表達方式,例如點云,它根據不同實驗和測量系統的原始數據可以明顯得出:
-
空間數據:用于描述幾何空間中的物理對象。主要有兩種類型:矢量和柵格數據。矢量數據可以由點、線或多邊形組成;柵格數據是指由像素組成的網格,像素相依表示為圖像或其他的值,如強度、電荷、場強等。
-
點云:一種空間數據類型。這種數據表達是通過整理一組空間數據(即三維空間中的點)創建的,這些數據通常在空間中共同構成一個對象。
-
時序數據:用于表示系統/實驗在特定時間的狀態。跨時段收集而來的數據會按照特定的順序進行分類。時間序列數據是上述表達方式中的一個子集,其中的數據以固定的時間間隔進行采樣。
-
時空數據:可在空間和時間兩個維度上測量和觀測某個系統。在這種情況下,數據可以被認為是時空的。
-
多光譜數據:用于表達多個傳感器中的輸出值,上述傳感器能夠從電磁光譜的多個頻段捕獲測量值。多光譜表達通常用于成像,與能夠識別波長各異的光的傳感器有關。通常會涉及幾個到幾十個光譜的量級。
-
高光譜數據:用于表示從大量光譜(如100s)中得到的測量值。這些從各異的窄帶光譜中采集到的圖像被合并成一個高光譜立方體,該立方體具有三個主要維度,前兩個維度參考了二維空間位置(例如,地球表面),第三個維度代表了每個“像素”位置的完整頻譜內容。
點云
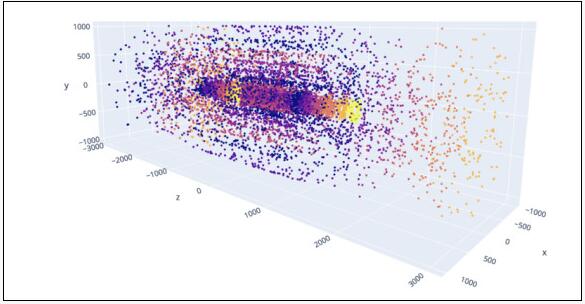
點云數據表達是高能粒子領域中一個常見的概念。在高能粒子領域里,經大量探測器收集而來的測量數據被合并成一個數據集。在眾多高能粒子應用中,點云通常用于表示數據尺寸超過1Pb/s的粒子射流。通俗地說,點云可以用來捕捉任何三維空間事件和空間中運動部件的相互作用。
質子之間發生碰撞后的殘余物在定制化和優化后的探測器中產生信號,在空間中以點的形式顯示。掃描后的各類圖像數據可以按照點云的方式呈現,生物醫學工程和虛擬實境中的CT和PET掃描也是利用點云進行成像,還有用于產品設計、實體對象建模、體系結構和基礎設施設計的三維掃描儀。
上述成像任務中,大部分都是按照從GB到TB的順序生成相應大小的點云。域共享點云表達(例如高能粒子和生物醫學成像)也會涉及到空間特性。
多/高光譜數據
多光譜數據在無線醫療監測和無線通信系統之間普遍存在。一組生理傳感器通常代表不同的模式,被合并成一個多光譜數據集,用于醫療監測和干預系統。對于無線通信而言,通過多光譜數據捕獲信號干擾情況和網絡流量狀況,兩個領域都會跨時間捕獲數據,因此也會顯示出時間特性。
與其他領域相比,這兩個領域中生成的數據大小可以被認為相對較小(從100s Mb/s到10s Gb/s)。高光譜數據被用于許多天文學應用、醫學成像和電子顯微鏡領域,用于實現更多的材料科學設計和發現應用。
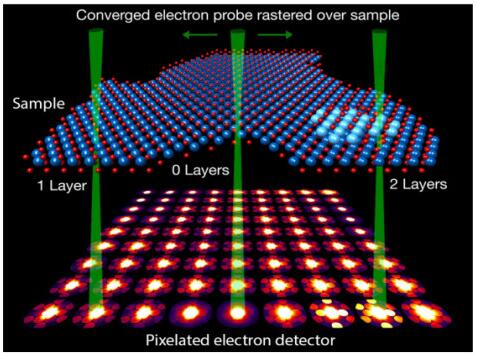
如圖7所示,電子顯微鏡中顯示的是高光譜數據。將電子探針柵格化在所研究的樣品上,并在像素探測器上捕獲衍射圖。當電子探針在樣品上掃描時,像素探測器進行圖像捕捉。新興的多信使天文學應用進一步提升了高光譜數據表達的效用,這些數據表達是結合了大量探測器和望遠鏡的觀測結果匯總而成。
3、實現低延時、高效率的ML算法
作者重點對如何構建高效機器學習算法的技術和技巧進行了簡要概述。在考慮硬件的情況下,構建算法實現協同設計,需要為硬件編程提供高效的平臺。為實現這這一點將從三個部分進行介紹:重點討論神經網絡設計和訓練,以便實現硬件的有效應用;將機器學習硬件計算平臺分為“常規CMOS硬件”和“新興的超CMOS硬件”兩部分進行介紹。前者將解決近期的硬件方案,后者專注于頻譜的投機端。
同時,由于編程新硬件領域發展迅速,作者以一個具體示例闡明設備家族面臨的選擇和挑戰:即現場可編程門陣列(FPGA),希望從FPGA的細節中,為讀者了解軟件設計的基本方法提供幫助。本文將以用于高效部署機器學習模型的系統方法為例進行簡單介紹。
科學領域中的許多機器學習問題要求延遲時間短,資源較為有限。然而,大多數現有的先進CNN模型延遲度非常高,且占用內存大,消耗量高。出于上述原因,實踐者被迫使用非理想精度的次優模型(例如淺層CNN)來避免這一延遲問題。大量的文獻致力于通過解決上述延遲問題,以提升CNN模型有效性,大致歸納如下:
- 設計全新的高效NN架構;
- NN架構與硬件的協同設計;
- 量化(低精度推斷);
- 剪枝和稀疏推斷;
- 知識蒸餾。
作者在文中闡述了需要在高吞吐量和低延遲環境下的機器學習算法,既包括系統設計和培訓,也包括機器學習模型的高效部署和應用。在硬件應用方面主要討論了兩類內容:現有的傳統CMOS技術和超CMOS技術。在常規的CMOS案例中,在摩爾定律的基礎上,人們重點研究機器學習設計的先進硬件架構。對于眾多硬件來說,機器學習算法的協同設計是特定科學領域對硬件(包括其體系結構和可編程性)要求的關鍵,一個高度相關和極其重要的硬件平臺的示例就是FPGA,作者認為,這些技術提供了令人興奮和超級高效的技術,雖然它們可能具有投機性,但相對于常規技術,已經大幅提升了現有的技術水平。
4、總結與展望
這篇綜述報告主要闡述了高效的機器學習算法的應用,如何使跨領域的科學發現成為現實。這個過程中,科學探索時常產生令人激動的新研究和新發現。然而,這是一個相對嶄新的領域,蘊藏著豐富的潛力,也面臨著跨領域的開放性挑戰。除了報告中闡述的內容之外,我們希望通過這篇文章對科學用例及其交疊的呈現能夠給讀者提供在其他研究中展開應用的靈感。
機器學習的訓練和部署手段以及計算機體系結構都是一個非常迅速發展的領域,新的任務接踵而至。在機器學習和科學領域中不斷引入新方法,同時理解不同硬件下新算法的協同設計以及部署這些算法的工具流的易用性就顯得尤為重要。這里的創新之處將快速和廣泛采用強大的新機器學習硬件得以實現。在超CMOS技術的情況下,這些應用性設計是很重要的,同時也要考慮到技術的成熟程度、融入計算體系結構以及如何編程這類器件。
我們期待著在不久的將來能夠重溫這些話題,看看在應用程序、機器學習技術和硬件平臺領域的發展速度——最重要的是它們的融合,在科學上領域上取得的顛覆性突破。
注:這篇綜述報告是第二屆年度Fast Machine Learning大會的概述,匯集了從粒子物理學家、材料學家到健康監測研究人員,以及機器學習學者和計算機系統架構師等多個科學專家的內容,希望通過專家觀點和概念找到特定領域應用、機器學習、實驗和計算機系統架構之間匯合點,以加快科學發現。以下是整篇報告的具體章節: