分享一道用Python基礎+蒙特卡洛算法實現排列組合的題目(附源碼)
大家好,我是Python進階者。這篇文章的題目真的是很難取,索性先取這個了,裝個13好了。
前言
前幾天在才哥交流群里,有個叫【Rick Xiang】的粉絲在Python交流群里問了一道關于排列組合的問題,初步一看覺得很簡單,實際上確實是有難度的。
題目是:一個列表中有隨機15個數,沒有重復值。從列表里面任意選5個數,如何選出來包含a, a+1的所有組合。a可以是15個數中的任意一個。
一、思路
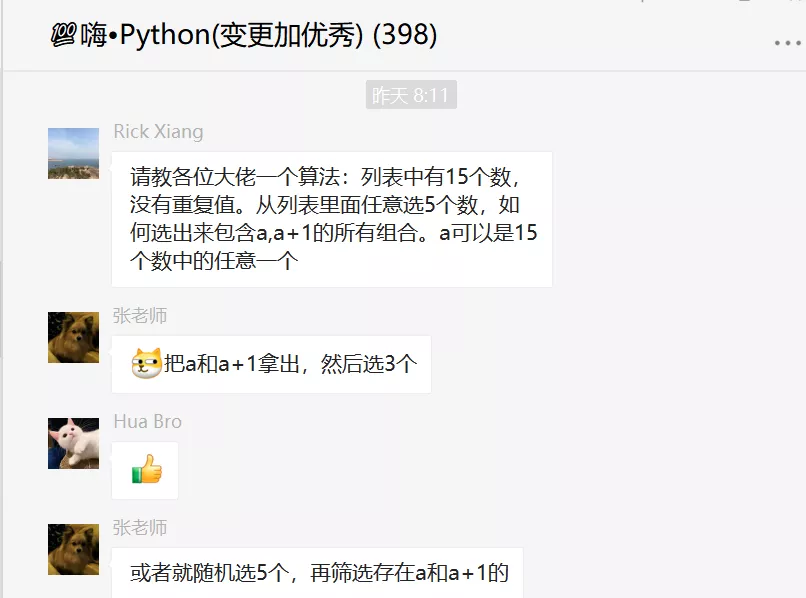
這個問題看似簡單,思路正如上圖的【張老師】說的那樣,分兩步走,理論上來說,確實是可以實現。正常我們計算排列組合公式,用下圖中的組合公式計算是沒問題的。

但是這道題目的實現,涉及到用Python程序進行實現,當然計算一個數值,對于Python和我們來說并不難,難的是需要回歸排列組合原本的狀態,然后用程序進行實現。本文借用了群成員【有點意思】所說的蒙特卡洛算法和代碼進行實現,下面一起來看看吧!

這里引用【張老師】提及的第二種方案,先隨機取14個數,然后從14個隨機數中隨機取一個,然后自增1,作為第15個隨機數,之后再從這15個隨機數中進行隨機取5個隨機數,再進行if判斷,看看連續值是否同時存在同一個列表中,之后把滿足條件的列表append到一個空列表中去,最后再去用set集合去重,得到最后的結果。
二、解決方法
1)偽代碼
這里先給出【有點意思】大佬的偽代碼,這樣看上去大家也更加好理解一些,如下圖所示。其實下面這個代碼也不算是偽代碼,現在Python也支持中文變量,下面這個代碼也是完全可以跑起來的,只不過看上去要比下文中的純英文代碼要更加好理解一些。

下面給出具體的實現過程,這里給出5份代碼,歡迎大家積極嘗試。
2)代碼一
- # coding: utf-8
- import random
- def quchong(list_data):
- list2 = []
- for i in list_data:
- if i not in list2:
- list2.append(i)
- return list2
- # 從隨機的15個數值中隨機取出5個數,放到一個數組
- # 生成不重復的14個隨機數
- random_14 = [random.randint(0, 100) for i in range(14)] # 這個寫法容易出現隨機值重復
- random_14 = random.sample(range(100), 14)
- print(random_14)
- random_1 = random.choice(random_14)
- random_2 = random_1 + 1
- random_14.append(random_2)
- random_15 = random_14
- print(random_1, random_2)
- final_list = []
- for i in range(100):
- select = [random.choice(random_15) for j in range(5)]
- quchong_select = set(select)
- if random_1 in quchong_select and random_2 in quchong_select:
- final_list.append(quchong_select)
- fina_result = quchong(final_list)
- print(len(fina_result))
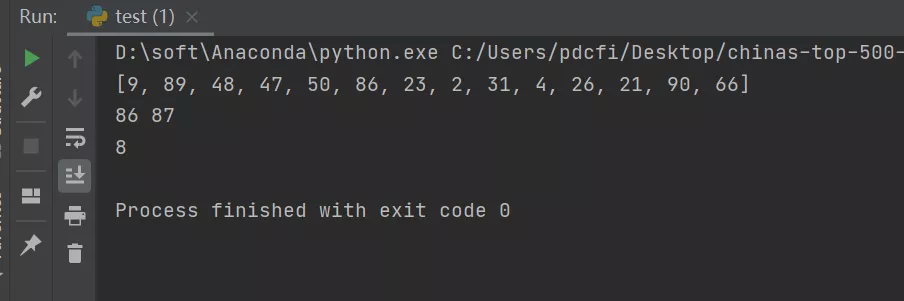
乍一看,這個方法確實可以實現,但是這里會有一個小bug,那就是random.randint()函數生成的隨機中會有重復值,而題目要求是生成不重復的隨機值。那么這個問題,將在代碼二中得到解決。
3)代碼二
使用random.sample()函數,這個函數可以隨機產生隨機值,而且不會重復,還是很奈斯的。另外,使用了numpy.random.choice()函數,可以直接選擇隨機的5個數,效率比代碼一更高一些。
- # -*- coding: utf-8 -*-
- import numpy as np
- import random
- def quchong(list_data):
- list2 = []
- for i in list_data:
- if i not in list2:
- list2.append(i)
- return list2
- # 從隨機的15個數值中隨機取出5個數,放到一個數組
- # 生成不重復的14個隨機數
- random_14 = random.sample(range(100), 14)
- print(random_14)
- random_1 = random.choice(random_14)
- random_2 = random_1 + 1
- random_14.append(random_2)
- random_15 = random_14
- print(random_1, random_2)
- final_list = []
- for i in range(100):
- sub_random_data = np.random.choice(random_15, 5)
- quchong_select = set(sub_random_data)
- if random_1 in quchong_select and random_2 in quchong_select:
- final_list.append(quchong_select)
- fina_result = quchong(final_list)
- print(len(fina_result))
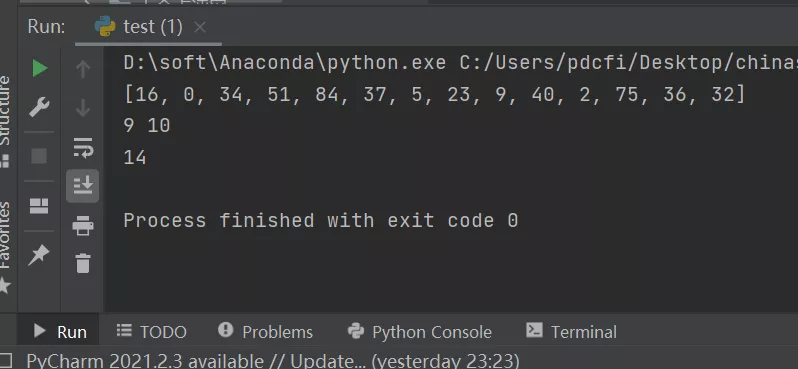
4)代碼三
代碼三主要是在代碼一和代碼二的基礎上加了一些函數,使得讀起來更加的有邏輯性和層次感。
- # -*- coding: utf-8 -*-
- # 模塊化
- import random
- import numpy as np
- # 從隨機的15個數值中隨機取出5個數,放到一個數組,生成不重復的14個隨機數
- def get_random15():
- random_14 = random.sample(range(1000), 14)
- print(random_14)
- random_1 = random.choice(random_14)
- random_2 = random_1 + 1
- random_14.append(random_2)
- random_15 = random_14
- print(random_1, random_2)
- get_final_result(random_1, random_2, random_15)
- def get_final_result(random_1, random_2, random_15):
- final_list = []
- for i in range(1000):
- sub_random_data = np.random.choice(random_15, 5)
- quchong_select = set(sub_random_data)
- if random_1 in quchong_select and random_2 in quchong_select:
- final_list.append(quchong_select)
- fina_result = quchong(final_list)
- print(len(fina_result))
- def quchong(list_data):
- list2 = []
- for i in list_data:
- if i not in list2:
- list2.append(i)
- return list2
- if __name__ == '__main__':
- get_random15()
5)代碼四
細心的朋友可能已經發現了一個問題,在隨機從np.random.choice(random_15, 5)取值的時候,也會取出重復的值,這樣也是不符合要求的,這里給出了一個方案,從15個隨機數中取出一個之后,然后remove掉這個取出的數,重新去剩下的列表中去取,這樣就完美的避開了這個問題。
- # 模塊化
- import random
- import numpy as np
- # 取出隨機的15個數值
- def get_random15():
- for i in range(2):
- random_15 = random.sample(range(20), 15)
- # print(random_15)
- get_random5(random_15)
- # 遍歷隨機的15個數值,取相鄰的兩個隨機數,并調用函數進行處理
- def get_random5(random_15):
- random_5 = []
- # 遍歷5次,從random_15中取5個不同的元素
- for i in range(5):
- random_data = np.random.choice(random_15)
- random_5.append(random_data)
- random_15.remove(random_data)
- # print(random_5)
- for num in random_5:
- random_1 = num
- random_2 = random_1 + 1
- get_final_result(random_1, random_2, random_5)
- # 判斷相鄰的兩數值是否同時存在隨機的15個數值的列表中,如果滿足要求,就存到一個列表中,并調用去重函數
- def get_final_result(random_1, random_2, random_5):
- final_list = []
- if random_1 in random_5 and random_2 in random_5:
- print(random_5)
- final_list.append(random_1)
- result = quchong(final_list)
- print(result)
- # 針對得到的所有列表,進行去重處理
- def quchong(list_data):
- list = []
- for i in list_data:
- if i not in list:
- list.append(i)
- return list
- if __name__ == '__main__':
- get_random15()
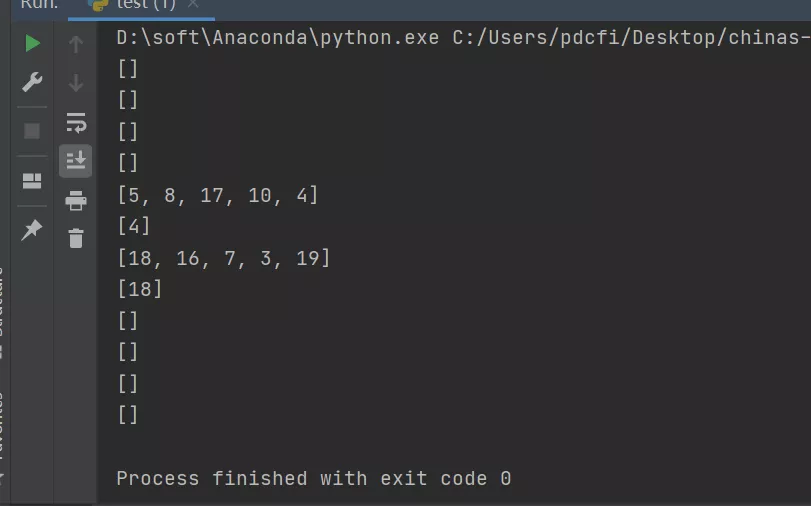
代碼寫到這里,已經比之前的方案要好很多了,比之前的三個代碼都要嚴謹一些,但是仍然存在不足。雖然解決了隨機生成重復性的問題,也解決了隨機從random_15中取出重復數的問題,但是弊端還是存在的。這個代碼遍歷挺多的,復雜度倒是正常,但是輸出的格式不太好看,沒有達到預期。這里我只是遍歷了2次,而且隨機數我只是開放到0-20,如果循環次數增多,數值越多的話,計算起來速度可就不好說了。
6)代碼五
經過【有點意思】大佬和我的共同努力,現在祭出終極版本,這個版本是迄今為止,針對該問題寫出的最嚴謹的一個版本了,代碼如下。
- # -*- coding: utf-8 -*-
- # 模塊化
- import random
- import numpy as np
- import time
- # 取出隨機的15個數值
- def get_random15():
- for i in range(100000):
- random_15 = random.sample(range(2000), 15)
- # print("隨機15數=",random_15,len(random_15))
- get_random5(random_15)
- # 遍歷隨機的15個數值,取相鄰的兩個隨機數,并調用函數進行處理
- def get_random5(random_15):
- random_5 = []
- # 遍歷5次,從random_15中取5個不同的元素
- for i in range(5):
- random_data = np.random.choice(random_15)
- random_5.append(random_data)
- random_15.remove(random_data)
- # print("random_5=",random_5)
- # print("random_15=",random_15)
- for num in random_5:
- random_1 = num
- random_2 = random_1 + 1
- # print(random_1,random_2)
- get_final_result(random_1, random_2, random_5)
- # 判斷相鄰的兩數值是否同時存在隨機的15個數值的列表中,如果滿足要求,就存到一個列表中,并調用去重函數
- def get_final_result(random_1, random_2, random_5):
- final_list = []
- if random_1 in random_5 and random_2 in random_5:
- # print(random_5)
- final_list.append(random_5)
- result = quchong(final_list)
- if result:
- if len(result[0]) == 5:
- # print(random_1,random_2)
- # print("result=",result)
- final_result.append(result)
- # 針對得到的所有列表,進行去重處理
- def quchong(list_data):
- list = []
- for i in list_data:
- if i not in list:
- list.append(i)
- return list
- if __name__ == '__main__':
- start_time = time.time()
- global final_result
- final_result = []
- get_random15()
- final_result = quchong(final_result)
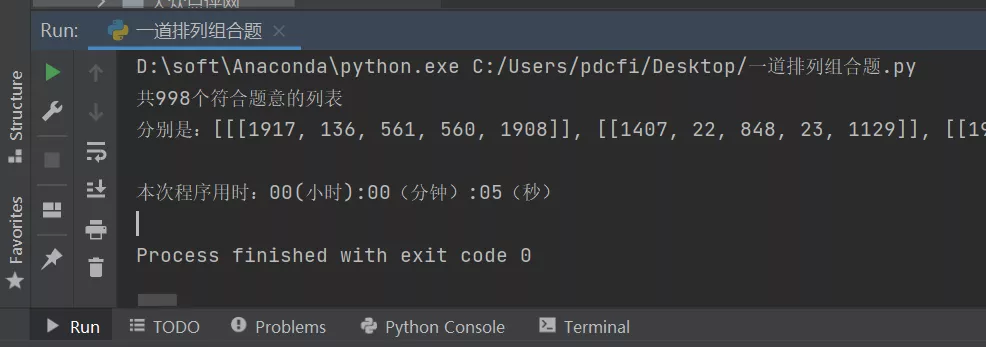
- print("共%d個符合題意的列表" % len(final_result))
- print("分別是:%s" % final_result)
- end_time = time.time()
- used_time = end_time - start_time
- print()
- print("本次程序用時:{}".format(time.strftime('%H(小時):%M(分鐘):%S(秒)', time.gmtime(used_time))))
這個代碼運行之后,可以看到符合題意列表的具體個數,還有具體的列表數值,還有耗時時間。
經過測試,在10萬次循環以內,符合要求的數據大概有1000左右,運行時間也只是秒級的。如果繼續擴大循環力度,程序的復雜度會更加大,更加貼近理論的排列組合值,因為耗時太長,這里不再做測試,感興趣的話,自己可以改下參數進行調試。
三、總結
我是Python進階者。本文基于粉絲針對排列組合問題的提問,給出了一個利用Python基礎+蒙特卡洛算法的解決方案,基本上可以達到了粉絲的要求。
不過話說回來,這個方案還是存在一定的弊端的,隨著循環次數越多,隨機數越大,排列組合數就會越多,運行的時間也就會越長,當然得到的數據也就更加的精準了。