重新認識 Java 中的內存映射(Mmap)
mmap 基礎概念
mmap 是一種內存映射文件的方法,即將一個文件映射到進程的地址空間,實現文件磁盤地址和一段進程虛擬地址的映射。實現這樣的映射關系后,進程就可以采用指針的方式讀寫操作這一段內存,而系統會自動回寫臟頁到對應的文件磁盤上,即完成了對文件的操作而不必再調用 read,write 等系統調用函數。相反,內核空間對這段區域的修改也直接反映用戶空間,從而可以實現不同進程間的文件共享。
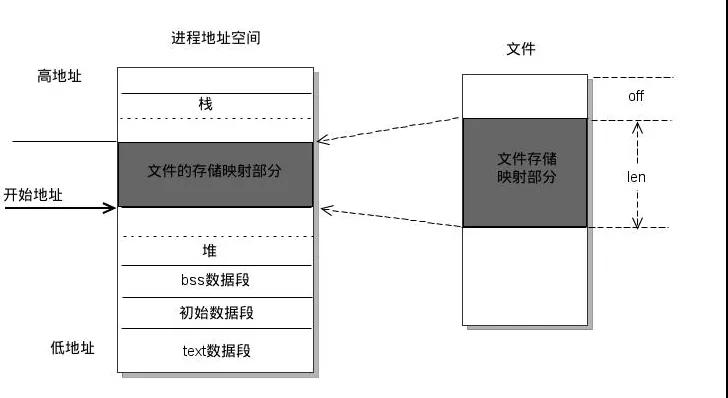
mmap工作原理
操作系統提供了這么一系列 mmap 的配套函數。
- void *mmap(void *start, size_t length, int prot, int flags, int fd, off_t offset);
- int munmap( void * addr, size_t len);
- int msync( void *addr, size_t len, int flags);
Java 中的 mmap
Java 中原生讀寫方式大概可以被分為三種:普通 IO,FileChannel(文件通道),mmap(內存映射)。區分他們也很簡單,例如 FileWriter,FileReader 存在于 java.io 包中,他們屬于普通 IO;FileChannel 存在于 java.nio 包中,也是 Java 最常用的文件操作類;而今天的主角 mmap,則是由 FileChannel 調用 map 方法衍生出來的一種特殊讀寫文件的方式,被稱之為內存映射。
mmap 的使用方式:
- FileChannel fileChannel = new RandomAccessFile(new File("db.data"), "rw").getChannel();
- MappedByteBuffer mappedByteBuffer = fileChannel.map(FileChannel.MapMode.READ_WRITE, 0, filechannel.size();
MappedByteBuffer 便是 Java 中的 mmap 操作類。
- // 寫
- byte[] data = new byte[4];
- int position = 8;
- // 從當前 mmap 指針的位置寫入 4b 的數據
- mappedByteBuffer.put(data);
- // 指定 position 寫入 4b 的數據
- MappedByteBuffer subBuffer = mappedByteBuffer.slice();
- subBuffer.position(position);
- subBuffer.put(data);
- // 讀
- byte[] data = new byte[4];
- int position = 8;
- // 從當前 mmap 指針的位置讀取 4b 的數據
- mappedByteBuffer.get(data);
- // 指定 position 讀取 4b 的數據
- MappedByteBuffer subBuffer = mappedByteBuffer.slice();
- subBuffer.position(position);
- subBuffer.get(data);
mmap 不是銀彈
促使我寫這一篇文章的一大動力,來自于網絡中很多關于 mmap 錯誤的認知。初識 mmap,很多文章提到 mmap 適用于處理大文件的場景,現在回過頭看,其實這種觀點是非常荒唐的,希望通過此文能夠澄清 mmap 本來的面貌。
FileChannel 與 mmap 同時存在,大概率說明兩者都有其合適的使用場景,而事實也的確如此。在看待二者時,可以將其看待成實現文件 IO 的兩種工具,工具本身沒有好壞,主要還是看使用場景。
mmap vs FileChannel
這一節,詳細介紹一下 FileChannel 和 mmap 在進行文件 IO 的一些異同點。
pageCache
FileChannel 和 mmap 的讀寫都經過 pageCache,或者更準確的說法是通過 vmstat 觀測到的 cache 這一部分內存,而非用戶空間的內存。
- procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----
- r b swpd free buff cache si so bi bo in cs us sy id wa st
- 3 0 0 4622324 40736 351384 0 0 0 0 2503 200 50 1 50 0 0
至于說 mmap 映射的這部分內存能不能稱之為 pageCache,我并沒有去調研過,不過在操作系統看來,他們并沒有太多的區別,這部分 cache 都是內核在控制。后面本文也統一稱 mmap 出來的內存為 pageCache。
缺頁中斷
對 Linux 文件 IO 有基礎認識的讀者,可能對缺頁中斷這個概念也不會太陌生。mmap 和 FileChannel 都以缺頁中斷的方式,進行文件讀寫。
以 mmap 讀取 1G 文件為例, fileChannel.map(FileChannel.MapMode.READ_WRITE, 0, _GB); 進行映射是一個消耗極少的操作,此時并不意味著 1G 的文件被讀進了 pageCache。只有通過以下方式,才能夠確保文件被讀進 pageCache。
- FileChannel fileChannel = new RandomAccessFile(file, "rw").getChannel();
- MappedByteBuffer map = fileChannel.map(MapMode.READ_WRITE, 0, _GB);
- for (int i = 0; i < _GB; i += _4kb) {
- temp += map.get(i);
- }
關于內存對齊的細節在這里就不拓展了,可以詳見 java.nio.MappedByteBuffer#load 方法,load 方法也是通過按頁訪問的方式觸發中斷
如下是 pageCache 逐漸增長的過程,共計約增長了 1.034G,說明文件內容此刻已全部 load。
- procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----
- r b swpd free buff cache si so bi bo in cs us sy id wa st
- 2 0 0 4824640 1056 207912 0 0 0 0 2374 195 50 0 50 0 0
- 2 1 0 4605300 2676 411892 0 0 205256 0 3481 1759 52 2 34 12 0
- 2 1 0 4432560 2676 584308 0 0 172032 0 2655 346 50 1 25 24 0
- 2 1 0 4255080 2684 761104 0 0 176400 0 2754 380 50 1 19 29 0
- 2 3 0 4086528 2688 929420 0 0 167940 40 2699 327 50 1 25 24 0
- 2 2 0 3909232 2692 1106300 0 0 176520 4 2810 377 50 1 23 26 0
- 2 2 0 3736432 2692 1278856 0 0 172172 0 2980 361 50 1 17 31 0
- 3 0 0 3722064 2840 1292776 0 0 14036 0 2757 392 50 1 29 21 0
- 2 0 0 3721784 2840 1292892 0 0 116 0 2621 283 50 1 50 0 0
- 2 0 0 3721996 2840 1292892 0 0 0 0 2478 237 50 0 50 0 0
兩個細節:
mmap 映射的過程可以理解為一個懶加載, 只有 get() 時才會觸發缺頁中斷
預讀大小是有操作系統算法決定的,可以默認當作 4kb,即如果希望懶加載變成實時加載,需要按照 step=4kb 進行一次遍歷
而 FileChannel 缺頁中斷的原理也與之相同,都需要借助 PageCache 做一層跳板,完成文件的讀寫。
內存拷貝次數
很多言論認為 mmap 相比 FileChannel 少一次復制,我個人覺得還是需要區分場景。
例如需求是從文件首地址讀取一個 int,兩者所經過的鏈路其實是一致的:SSD -> pageCache -> 應用內存,mmap 并不會少拷貝一次。
但如果需求是維護一個 100M 的復用 buffer,且涉及到文件 IO,mmap 直接就可以當做是 100M 的 buffer 來用,而不用在進程的內存(用戶空間)中再維護一個 100M 的緩沖。
用戶態與內核態
用戶態和內核態
操作系統出于安全考慮,將一些底層的能力進行了封裝,提供了系統調用(system call)給用戶使用。這里就涉及到“用戶態”和“內核態”的切換問題,私認為這里也是很多人概念理解模糊的重災區,我在此梳理下個人的認知,如有錯誤也歡迎指正。
先看 FileChannel,下面兩段代碼,你認為誰更快?
- // 方法一: 4kb 刷盤
- FileChannel fileChannel = new RandomAccessFile(file, "rw").getChannel();
- ByteBuffer byteBuffer = ByteBuffer.allocateDirect(_4kb);
- for (int i = 0; i < _4kb; i++) {
- byteBuffer.put((byte)0);
- }
- for (int i = 0; i < _GB; i += _4kb) {
- byteBuffer.position(0);
- byteBuffer.limit(_4kb);
- fileChannel.write(byteBuffer);
- }
- // 方法二: 單字節刷盤
- FileChannel fileChannel = new RandomAccessFile(file, "rw").getChannel();
- ByteBuffer byteBuffer = ByteBuffer.allocateDirect(1);
- byteBuffer.put((byte)0);
- for (int i = 0; i < _GB; i ++) {
- byteBuffer.position(0);
- byteBuffer.limit(1);
- fileChannel.write(byteBuffer);
- }
使用方法一:4kb 緩沖刷盤(常規操作),在我的測試機器上只需要 1.2s 就寫完了 1G。而不使用任何緩沖的方法二,幾乎是直接卡死,文件增長速度非常緩慢,在等待了 5 分鐘還沒寫完后,中斷了測試。
使用寫入緩沖區是一個非常經典的優化技巧,用戶只需要設置 4kb 整數倍的寫入緩沖區,聚合小數據的寫入,就可以使得數據從 pageCache 刷盤時,盡可能是 4kb 的整數倍,避免寫入放大問題。但這不是這一節的重點,大家有沒有想過,pageCache 其實本身也是一層緩沖,實際寫入 1byte 并不是同步刷盤的,相當于寫入了內存,pageCache 刷盤由操作系統自己決策。那為什么方法二這么慢呢?主要就在于 filechannel 的 read/write 底層相關聯的系統調用,是需要切換內核態和用戶態的,注意,這里跟內存拷貝沒有任何關系,導致態切換的根本原因是 read/write 關聯的系統調用本身。方法二比方法一多切換了 4096 倍,態的切換成為了瓶頸,導致耗時嚴重。
階段總結一下重點,在 DRAM 中設置用戶寫入緩沖區這一行為有兩個意義:
方便做 4kb 對齊,ssd 刷盤友好
減少用戶態和內核態的切換次數,cpu 友好
但 mmap 不同,其底層提供的映射能力不涉及到切換內核態和用戶態,注意,這里跟內存拷貝還是沒有任何關系,導致態不發生切換的根本原因是 mmap 關聯的系統調用本身。驗證這一點,也非常容易,我們使用 mmap 實現方法二來看看速度如何:
- FileChannel fileChannel = new RandomAccessFile(file, "rw").getChannel();
- MappedByteBuffer map = fileChannel.map(MapMode.READ_WRITE, 0, _GB);
- for (int i = 0; i < _GB; i++) {
- map.put((byte)0);
- }
在我的測試機器上,花費了 3s,它比 FileChannel + 4kb 緩沖寫要慢,但遠比 FileChannel 寫單字節快。
這里也解釋了我之前文章《文件 IO 操作的一些最佳實踐》中一個疑問:"一次寫入很小量數據的場景使用 mmap 會比 fileChannel 快的多“,其背后的原理就和上述例子一樣,在小數據量下,瓶頸不在于 IO,而在于用戶態和內核態的切換。
mmap 細節補充
copy on write 模式
我們注意到 public abstract MappedByteBuffer map(MapMode mode,long position, long size) 的第一個參數,MapMode 其實有三個值,在網絡沖浪的時候,也幾乎沒有找到講解 MapMode 的文章。MapMode 有三個枚舉值 READ_WRITE、READ_ONLY、PRIVATE,大多數時候使用的可能是 READ_WRITE,而 READ_ONLY 不過是限制了 WRITE 而已,很容易理解,但這個 PRIVATE 身上似乎有一層神秘的面紗。
實際上 PRIVATE 模式正是 mmap 的 copy on write 模式,當使用 MapMode.PRIVATE 去映射文件時,你會獲得以下的特性:
其他任何方式對文件的修改,會直接反映在當前 mmap 映射中。
private mmap 之后自身的 put 行為,會觸發復制,形成自己的副本,任何修改不會會刷到文件中,也不再感知該文件該頁的改動。
俗稱:copy on write。
這有什么用呢?重點就在于任何修改都不會回刷文件。其一,你可以獲得一個文件副本,如果你正好有這個需求,直接可以使用 PRIVATE 模式去進行映射,其二,令人有點小激動的場景,你獲得了一塊真正的 PageCache,不用擔心它會被操作系統刷盤造成 overhead。假設你的機器配置如下:機器內存 9G,JVM 參數設置為 6G,堆外限制為 2G,那剩下的 1G 只能被內核態使用,如果想被用戶態的程序利用起來,就可以使用 mmap 的 copy on write 模式,這不會占用你的堆內內存或者堆外內存。
回收 mmap 內存
更正之前博文關于 mmap 內存回收的一個錯誤說法,回收 mmap 很簡單
- ((DirectBuffer) mmap).cleaner().clean();
mmap 的生命中簡單可以分為:map(映射),get/load (缺頁中斷),clean(回收)。一個實用的技巧是動態分配的內存映射區域,在讀取過后,可以異步回收掉。
mmap 使用場景
使用 mmap 處理小數據的頻繁讀寫
如果 IO 非常頻繁,數據卻非常小,推薦使用 mmap,以避免 FileChannel 導致的切態問題。例如索引文件的追加寫。
mmap 緩存
當使用 FileChannel 進行文件讀寫時,往往需要一塊寫入緩存以達到聚合的目的,最常使用的是堆內/堆外內存,但他們都有一個問題,即當進程掛掉后,堆內/堆外內存會立刻丟失,這一部分沒有落盤的數據也就丟了。而使用 mmap 作為緩存,會直接存儲在 pageCache 中,不會導致數據丟失,盡管這只能規避進程被 kill 這種情況,無法規避掉電。
小文件的讀寫
恰恰和網傳的很多言論相反,mmap 由于其不切態的特性,特別適合順序讀寫,但由于 sun.nio.ch.FileChannelImpl#map(MapMode mode, long position, long size) 中 size 的限制,只能傳遞一個 int 值,所以,單次 map 單個文件的長度不能超過 2G,如果將 2G 作為文件大 or 小的閾值,那么小于 2G 的文件使用 mmap 來讀寫一般來說是有優勢的。在 RocketMQ 中也利用了這一點,為了能夠方便的使用 mmap,將 commitLog 的大小按照 1G 來進行切分。對的,忘記說了,RocketMQ 等消息隊列一直在使用 mmap。
cpu 緊俏下的讀寫
在大多數場景下,FileChannel 和讀寫緩沖的組合相比 mmap 要占據優勢,或者說不分伯仲,但在 cpu 緊俏下的讀寫,使用 mmap 進行讀寫往往能起到優化的效果,它的根據是 mmap 不會出現用戶態和內核態的切換,導致 cpu 的不堪重負(但這樣承擔起動態映射與異步回收內存的開銷)。
特殊軟硬件因素
例如持久化內存 Pmem、不同代數的 SSD、不同主頻的 CPU、不同核數的 CPU、不同的文件系統、文件系統的掛載方式...等等因素都會影響 mmap 和 filechannel read/write 的快慢,因為他們對應的系統調用是不同的。只有 benchmark 過后,方知快慢。