













何愷明時隔2年再發(fā)一作論文:為視覺大模型開路,全文沒一個公式
本文經(jīng)AI新媒體量子位(公眾號ID:QbitAI)授權(quán)轉(zhuǎn)載,轉(zhuǎn)載請聯(lián)系出處。
大神話不多,但每一次一作論文,必定引發(fā)江湖震動。
這不,距離上一篇一作論文2年之后,何愷明再次以一作身份,帶來最新研究。
依然是視覺領(lǐng)域的研究,依然是何愷明式的大道至簡。
簡潔:通篇論文沒有一個公式。
有效:大巧不工,用最簡單的方法展現(xiàn)精妙之美。
江湖震動:“CVPR 2022最佳論文候選預(yù)定”。
所以,何愷明新作:
Masked Autoencoders Are Scalable Vision Learners

究竟有怎樣的思想和研究成果?
用于CV的自監(jiān)督學(xué)習(xí)方案
本文提出了一種用于計算機(jī)視覺的Masked AutoEncoders 掩蔽自編碼器,簡稱MAE。
——一種類似于NLP技術(shù)的自我監(jiān)督方法。
操作很簡單:對輸入圖像的隨機(jī)區(qū)塊進(jìn)行掩蔽,然后重建缺失的像素。

主要有兩個核心設(shè)計。
一個是非對稱的編碼-解碼架構(gòu),一個高比例遮蔽輸入圖像。
先來看編碼-解碼架構(gòu)。
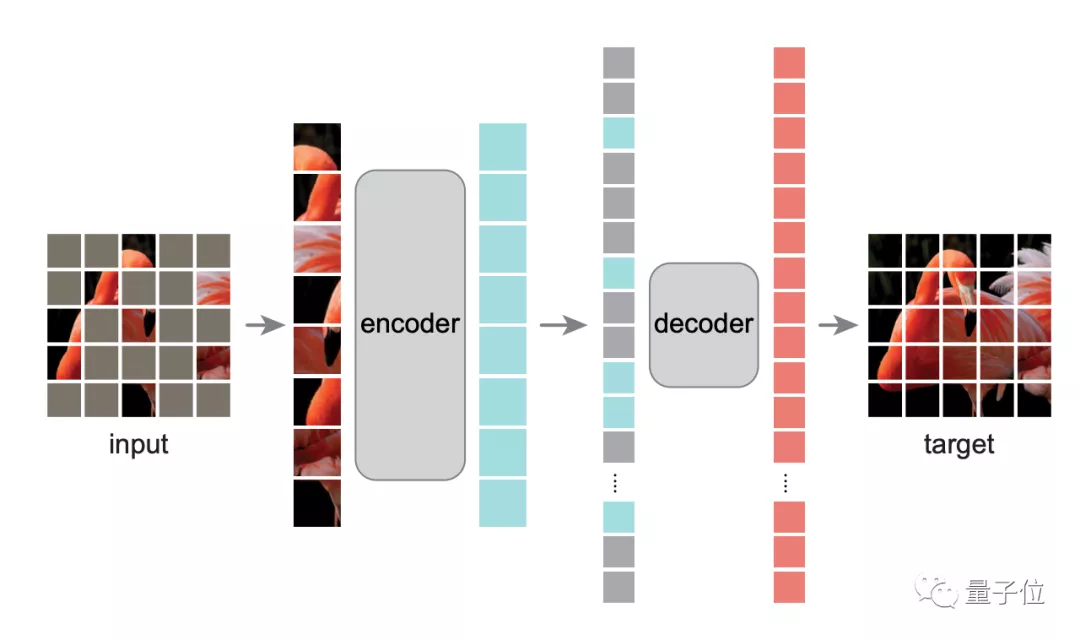
如圖所示,編碼器是ViT,它僅對可見區(qū)塊進(jìn)行操作,然后用一個輕量級編碼器——僅在預(yù)訓(xùn)練期間負(fù)責(zé)圖像重建任務(wù)。
具體而言,作者先將圖像均勻劃分為非重疊區(qū)塊,然后隨機(jī)對區(qū)塊進(jìn)行采樣。
以遮蔽比例75%為例,它先在輸入圖像中掩蔽75%的隨機(jī)區(qū)塊,編碼器只在可見的25%區(qū)塊子集上運(yùn)行,這樣就可以只用非常少的計算和顯存,來訓(xùn)練非常大的編碼器。
然后解碼器將可見的token和掩碼token組合,并向所有token中添加位置嵌入,通過預(yù)測每個掩蔽區(qū)塊的像素值來重建圖像信號。
這樣一來,在預(yù)訓(xùn)練時解碼器可以獨(dú)立于編碼器,從而可以用非常輕量級解碼器實(shí)驗(yàn),大量減少預(yù)訓(xùn)練時間。
另一個特點(diǎn)則是對輸入圖像的高比例進(jìn)行遮蔽時,自監(jiān)督任務(wù)效果非常好。
比如,掩蔽掉80%隨機(jī)patch的效果如下:

其中最左列為輸入圖像,中間列為MAE方法重建效果,最右側(cè)為原圖效果。
不同掩蔽比例在重建圖像中的表現(xiàn)對比如下:

將這兩種設(shè)計結(jié)合,結(jié)果用來訓(xùn)練大模型:
訓(xùn)練速度提升3倍以上,還提高準(zhǔn)確率的那種。
除此之外,基于該方案所得出的大模型具備很好的泛化能力:
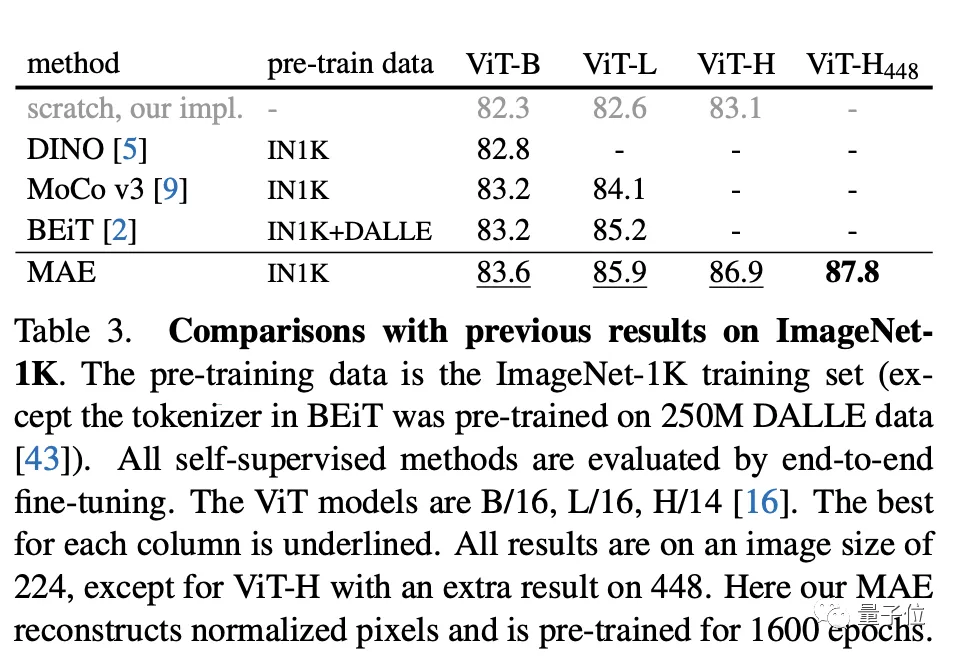
比如,在僅使用ImageNet-1K數(shù)據(jù)時,ViT-Huge模型準(zhǔn)確性達(dá)87.8%。
在COCO數(shù)據(jù)集中的表現(xiàn)如下,雖然重建效果不清晰,但是基本語義是正確的。

研究者還對MAE遷移學(xué)習(xí)的性能進(jìn)行了評估。
結(jié)果在下游任務(wù),比如目標(biāo)檢測、實(shí)例分割、語義分割等任務(wù)都優(yōu)于監(jiān)督預(yù)訓(xùn)練。
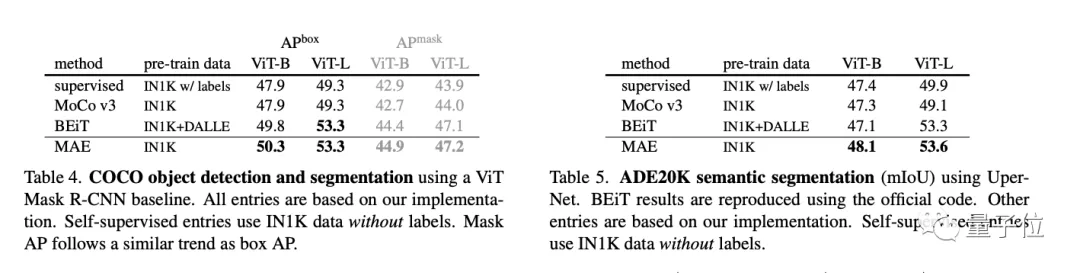
在對比中可以看到,隨機(jī)遮蔽75%、整塊遮蔽50%和網(wǎng)格遮蔽50%的三種采樣方法中,隨機(jī)遮蔽75%重建圖像的質(zhì)量最好。

基于這些研究成果,何愷明團(tuán)隊在最后也表達(dá)了他們的看法。
一方面,擴(kuò)展性好的簡單算法是深度學(xué)習(xí)的核心。
在計算機(jī)視覺中,盡管自監(jiān)督學(xué)習(xí)方面取得了進(jìn)展,但實(shí)際預(yù)訓(xùn)練仍需受到監(jiān)督。
這項研究中,作者看到ImageNet和遷移學(xué)習(xí)任務(wù)中,自編碼器表現(xiàn)出了非常強(qiáng)的可擴(kuò)展優(yōu)勢。
為此作者認(rèn)為,CV中自監(jiān)督學(xué)習(xí)現(xiàn)在可能正走上與NLP類似的軌道。
另一方面,作者注意,圖像和語言是不同性質(zhì)的信號,這種差異需要小心處理。
圖像僅僅是記錄下來的光,并沒有語義分解為文字的視覺類似物。
他們不是去試圖去除物體,而是去除可能不構(gòu)成語義段的隨機(jī)區(qū)塊。重建的像素,也并不是語義實(shí)體。
研究團(tuán)隊
論文的研究團(tuán)隊,來自Facebook AI研究院(FAIR),每個人都屢屢獲譽(yù),堪稱夢之隊。

除了幾位老將,我們這次再多說說里面的華人面孔。
Xinlei Chen,本科畢業(yè)于浙江大學(xué)計算機(jī)專業(yè),隨后在卡內(nèi)基梅隆大學(xué)攻讀博士學(xué)位,曾在UCLA、谷歌云、MSR實(shí)習(xí)。
謝賽寧,本科畢業(yè)于上海交通大學(xué)ACM班,隨后在UC圣迭戈分校攻讀計算機(jī)博士學(xué)位,曾在谷歌、DeepMind實(shí)習(xí)。
Yanghao Li,本科畢業(yè)于北京大學(xué)計算機(jī)專業(yè),隨后留在本校繼續(xù)攻讀碩士學(xué)位。
最后,再次隆重介紹下何愷明。
一作何愷明,想必大家都不陌生。作為Mask R-CNN的主要提出者,他已4次斬獲頂會最佳論文。
何愷明是2003年廣東高考狀元,并保送了清華,進(jìn)入楊振寧發(fā)起設(shè)立的物理系基礎(chǔ)科學(xué)班。
碩博階段,何愷明前往香港中文大學(xué)多媒體實(shí)驗(yàn)室,導(dǎo)師正是后來的商湯科技創(chuàng)始人湯曉鷗。
此間,何愷明還進(jìn)入微軟亞洲研究院實(shí)習(xí),在孫劍指導(dǎo)下,以一作身份發(fā)表ResNet研究,一舉成名天下知,榮獲2016年CVPR最佳論文。
同年何愷明進(jìn)入由Yann Lecun(獲2019年圖靈獎)掌舵的Facebook人工智能實(shí)驗(yàn)室,與Ross Girshick、Piotr Dollar——本次研究中的其他幾位老面孔,組成了FAIR在AI研究領(lǐng)域的夢之隊。
更加令人欽佩的是,何愷明年少成名,但這幾年來依然不斷潛心研究,一直帶來新驚喜。
甚至他的新研究,很多都是那種可以開枝散葉的成果。
這一次,MAE同樣被視為這樣的延續(xù)。
你怎么看MAE?
論文鏈接
https://arxiv.org/abs/2111.06377
























