BERT是圖像預訓練未來?字節iBOT刷新十幾項SOTA,部分指標超MAE
前段時間,何愷明等人的一篇論文成為了計算機視覺圈的焦點。這篇論文僅用簡單的 idea(即掩蔽自編碼器,MAE)就達到了非常理想的性能,讓人們看到了 Transformer 擴展到 CV 大模型的光明前景,給該領域的研究者帶來了很大的鼓舞(參見《大道至簡,何愷明新論文火了:Masked Autoencoders 讓計算機視覺通向大模型》)。

那么,MAE 就是大模型視覺模型預訓練方法的巔峰了嗎?顯然不是,一大波挑戰者已經在路上了,比如字節跳動、約翰霍普金斯大學等機構組成的聯合團隊。
在一篇最新的論文中,他們提出了適用于視覺任務的大規模預訓練方法 iBOT,通過對圖像使用在線 tokenizer 進行 BERT [1]式預訓練讓 CV 模型獲得通用廣泛的特征表達能力。該方法在十幾類任務和數據集上刷新了 SOTA 結果,在一些指標上甚至超過了 MAE [2]。

論文鏈接:https://arxiv.org/abs/2111.07832
方法介紹
在 NLP 的大規模模型訓練中,MLM(Masked Language Model)是非常核心的訓練目標,其思想是遮住文本的一部分并通過模型去預測這些遮住部分的語義信息,通過這一過程可以使模型學到泛化的特征。NLP 中的經典方法 BERT 就是采用了 MLM 的預訓練范式,通過 MLM 訓練的模型已經被證明在大模型和大數據上具備極好的泛化能力,成為 NLP 任務的標配。
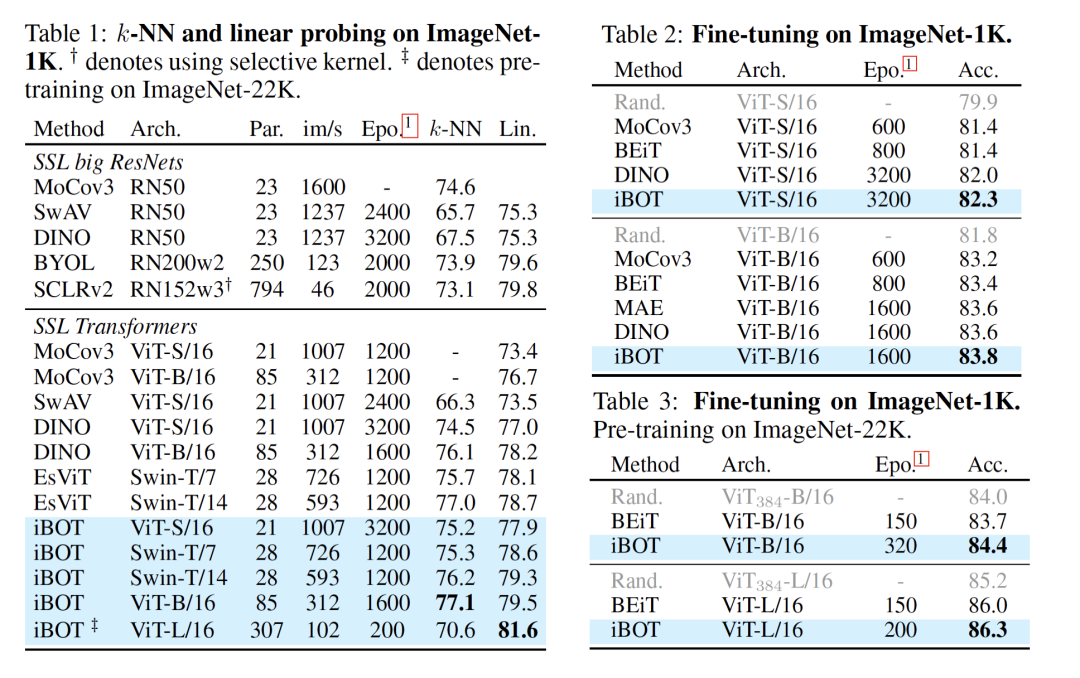
在該工作中,研究者主要探索了這種在 NLP 中主流的 Masked Modeling 是否能應用于大規模 Vision Transformer 的預訓練。作者給出了肯定的回答,并認為問題關鍵在于 visual tokenizer 的設計。不同于 NLP 中 tokenization 通過離線的詞頻分析即可將語料編碼為含高語義的分詞,圖像 patch 是連續分布的且存在大量冗余的底層細節信息。而作者認為一個能夠提取圖像 patch 中高層語義的 tokenizer 可幫助模型避免學習到冗余的這些細節信息。作者認為視覺的 tokenizer 應該具備兩個屬性:(a)具備完整表征連續圖像內容的能力;(b) 像 NLP 中的 tokenizer 一樣具備高層語義。
如何才能設計出一個 tokenizer,使之同時具備以上的屬性呢?作者首先將經過 mask 過的圖片序列輸入 Transformer 之后進行預測的過程建模為知識蒸餾的過程:
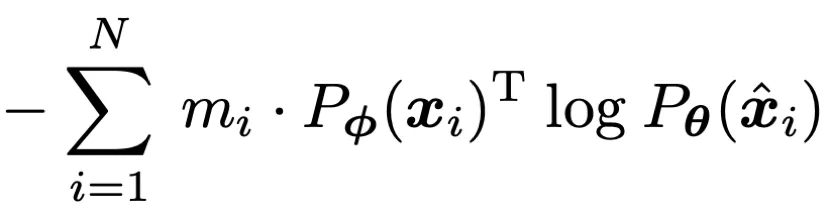
作者發現,通過使用在線 tokenizer 監督 MIM 過程,即 tokenizer 和目標網絡同步學習,能夠較好地保證語義的同時并將圖像內容轉化為連續的特征分布。具體地,tokenizer 和目標網絡共享網絡結構,在線即指 tokenizer 其參數從目標網絡的歷史參數中滑動平均得出。該形式近期在 DINO [3]中以自蒸餾被提出,并被用以針對同一張圖片的兩個不同視野在 [CLS] 標簽上的優化:
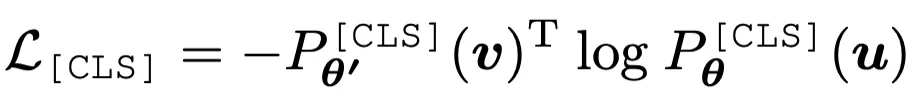
在該損失函數的基礎之上,作者將 MIM 同樣也使用自蒸餾的思路進行優化,其中在線 tokenizer 的參數即為目標網絡歷史參數的平均。其過程可表示為:
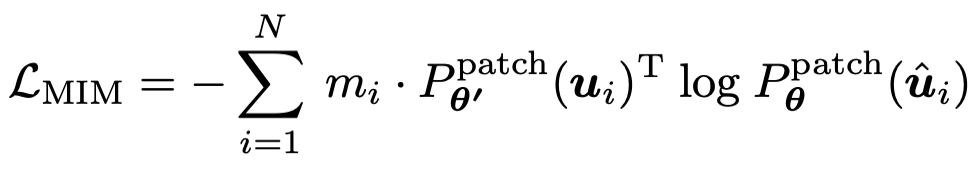
基于上述訓練目標,作者提出了一種新的自監督預訓練框架 iBOT。iBOT 同時優化上述兩項損失函數。其中,在 [CLS] 標簽上的自蒸餾保證了在線 tokenizer 學習到高語義特征,并將該語義遷移到 MIM 的優化過程中;而在 patch 標簽上的自蒸餾則將在線 tokenizer 表征的 patch 連續分布作為目標監督 masked patch 的復原。該方法在保證模型學習到高語義特征的同時,通過 MIM 顯式建模了圖片的內部結構。同時,在線 tokenizer 與 MIM 目標可以一起端到端地學習,無需額外的 tokenizer 訓練階段。
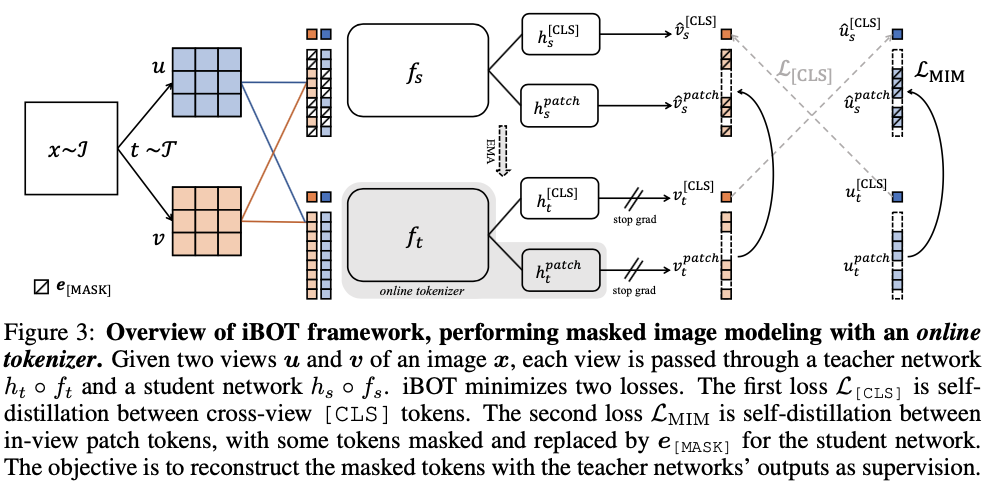
預訓練時采用孿生網絡結構,其中在線 tokenizer 可以看作教師分支的一部分。教師、學生兩分支包括結構相同的 backbone 網絡和 projection 網絡。作者廣泛驗證了 iBOT 方法搭配不同的 Transformers 作為 backbone,如 Vision Transformers(ViT-S/16, ViT-B/16, ViT-L/16)及 Swin Transformers(Swin-T/7, Swin-T/14)。作者發現共享 [CLS] 標簽與 patch 標簽的 projection 網絡能夠有效提升模型在下游任務上的遷移性能。作者還采用了隨機 MIM 的訓練機制,對每張圖片而言,以 0.5 的概率不進行 mask,以 0.5 的概率從 [0.1, 0.5] 區間隨機選取一個比例進行 mask。實驗表明隨機 MIM 的機制對于使用了 multi-crop 數據增強的 iBOT 非常關鍵。
實驗結果
為了驗證 iBOT 預訓練方法的有效性,作者在大量的下游任務上進行了驗證,同時也在附錄里提供了比較詳細的不同任務超參數對最終結果的影響。
從 Linear probing(線性分類)及 k-NN 分類的結果上來看,iBOT 使用 ViT-B/16 達到 79.5% 線性分類準確度,超越了 DINO 的 78.2%;使用 Swin-T/14 達到 79.3% 準確度,超越了 EsViT 的 78.7%;使用 ViT-L/16 及 ImageNet-22K 作為預訓練數據達到 81.6% 準確度,為目前 ImageNet-1K 線性分類基準上最高的結果。
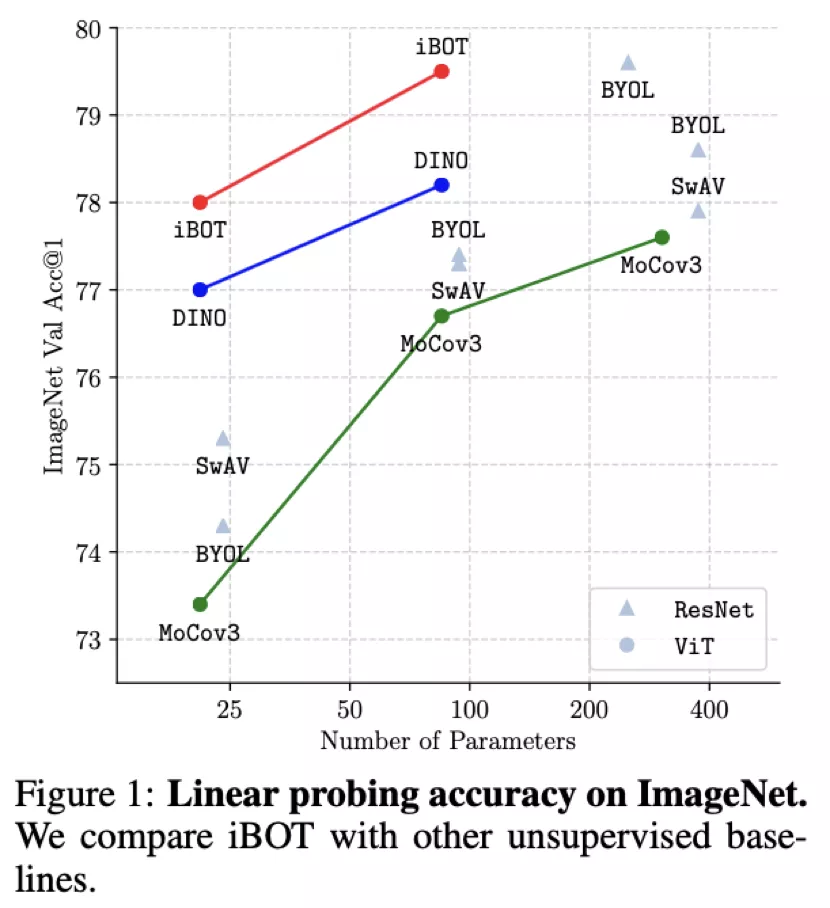
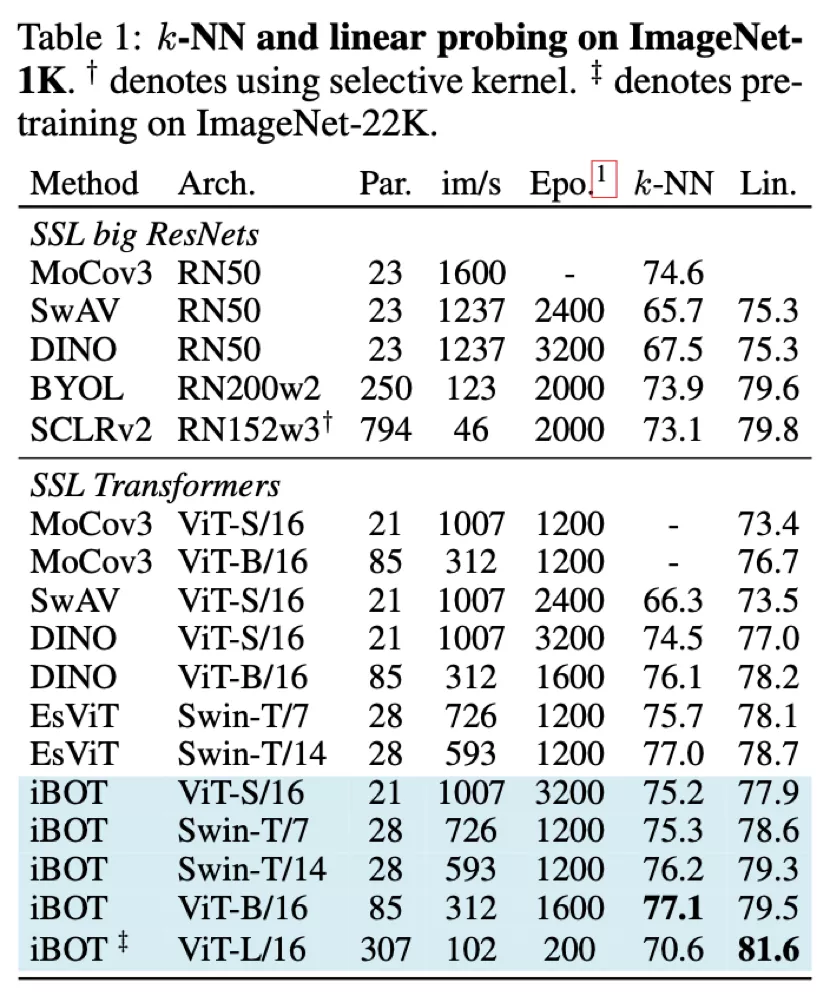
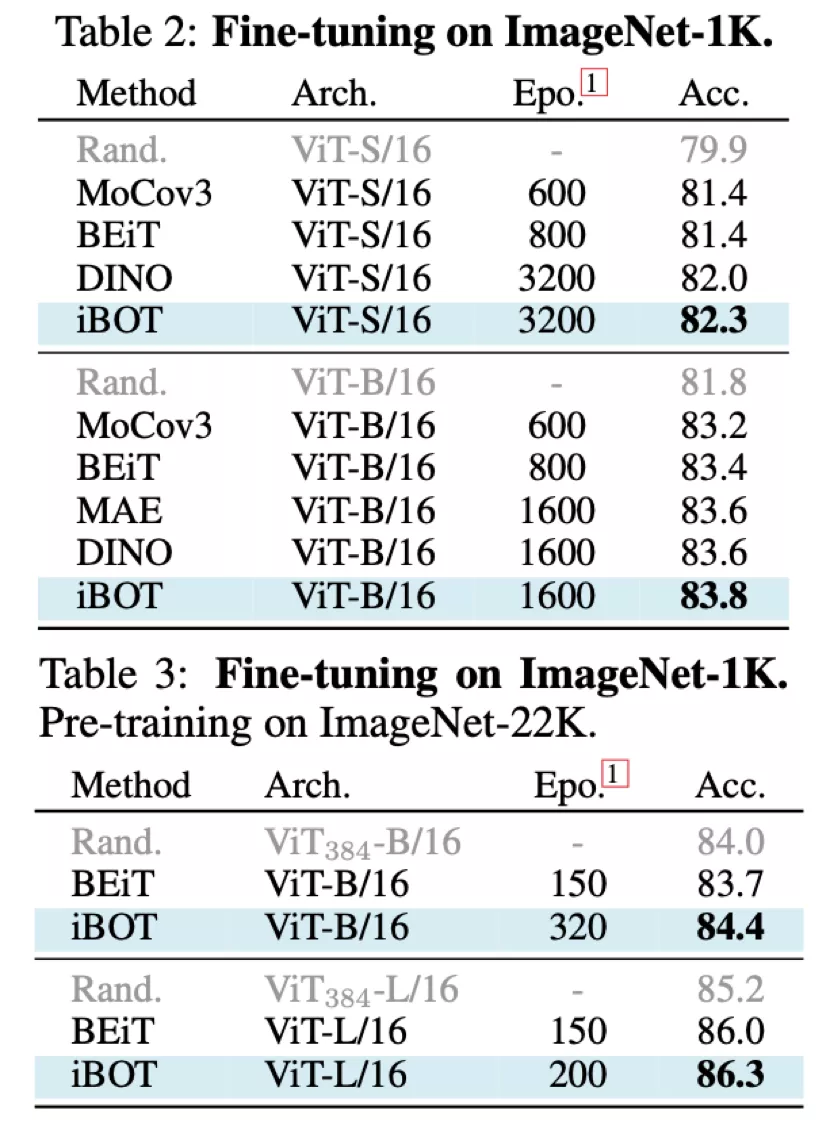
從 Fine-tuning 的結果上來看,使用 ImageNet-1K 作為預訓練數據及 ViT-B/16 時 iBOT 可達到 83.8% 準確率,高于 DINO、MAE 的 83.6%;使用 ImageNet-22K 作為預訓練數據及 ViT-L/16 時 iBOT 可達到 86.3%,高于 BEiT [4]的 86.0%。
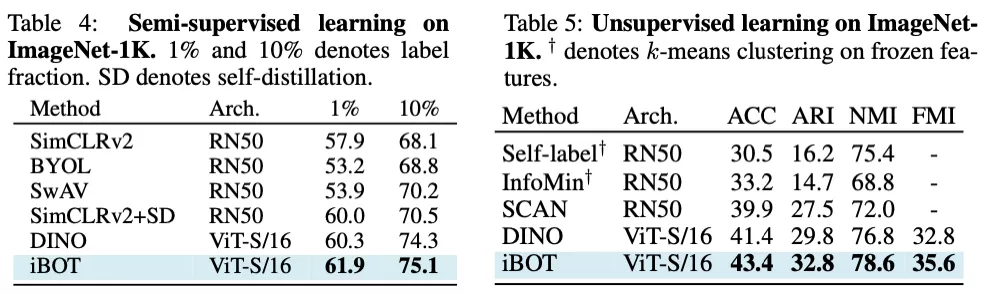
在半監督及無監督分類的結果上來看,iBOT 也顯著優于沒有 MIM 訓練目標的 DINO。其中在半監督的基準下,作者發現微調數據越少時,iBOT 的優勢越明顯。在無監督的基準下,iBOT 能達到 43.4% 的準確率以及 78.6% 的 NMI。
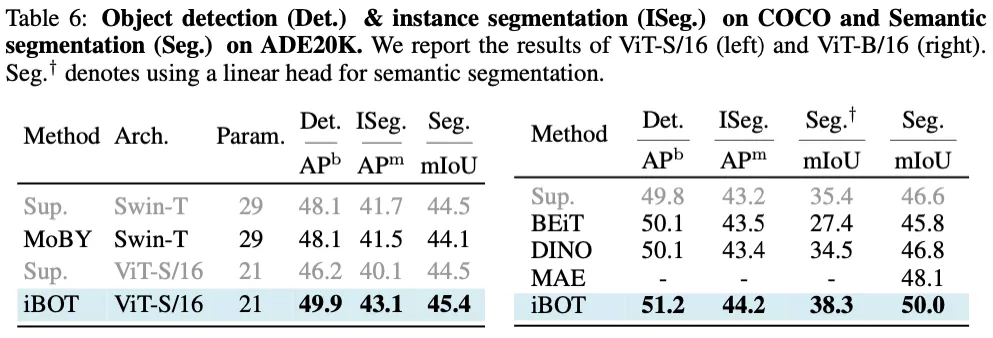
除此之外,因為 MIM 顯示建模了圖片內部結構,作者發現 iBOT 在密集的下游任務也有非常好的遷移結果。其中 iBOT 使用 ViT-B/16 及 Cascade Mask R-CNN 在目標檢測下可達到 51.2 APb;使用 ViT-B/16 及 UperNet 在語義分割下可達到 50.0 mAP,高于 MAE 達到的 48.1 mAP。
同時作者也進一步探究了 MIM 訓練目標所帶來的特性,以幫助分析 iBOT 在全局圖像任務及密集圖像任務出色表現的原因。作者根據 ImageNet 驗證集中所有圖片 patch 的概率分布,可視化了部分類別中心所代表的模式。作者在大量的可視化結果中發現 iBOT 針對局部語義有非常好的可視化結果,如下圖左一、左二中所示的車燈、狗耳朵展現了不同局部類別語義的出現,而在下圖左三、左四中展現了不同局部紋理語義的出現。

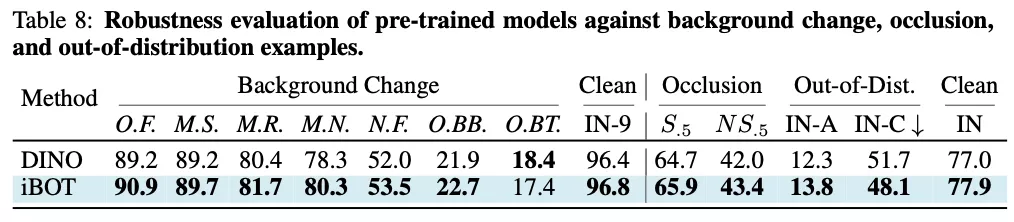
在大量魯棒性分析及測評中,作者發現 iBOT 相較沒有 MIM 訓練目標的 DINO 有更出色的表現,這說明局部語義的出現能夠幫助模型在遮擋、模糊等一系列干擾存在的圖像識別任務下有更好的準確性。
方法對比
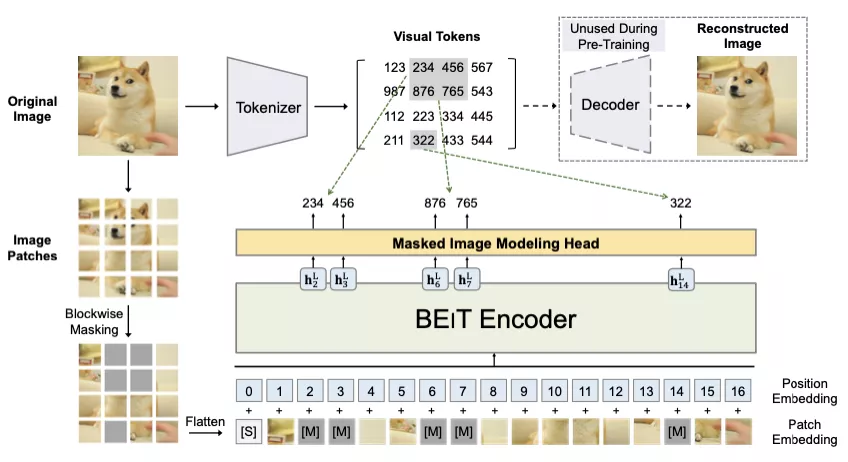
近期 masked autoencoding 的思路可謂在視覺領域大火,和近期一些工作對比,BEiT 使用了一個預訓練好的 DALL-E encoder 作為 tokenizer,將每個 patch 標簽離散化后的 one-hot 編碼作為目標模型的標簽。
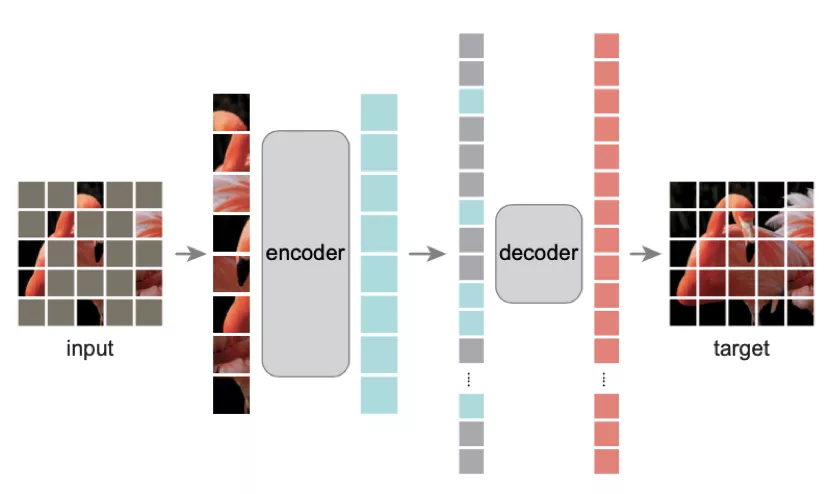
而 MPP [5]及近期較火的 MAE 則可將 tokenizer 視為恒等變換,即直接在像素空間內進行回歸而非分類。
而 iBOT 則指出了上述幾種方式的 tokenizer 存在過度關注低級信息的問題,這也可以從上述幾種方法線性分類的性能不是很高可以看出。但近期 MAE 中指出當圖片中被 mask 的比例足夠大時,可使網絡無法從相近 patches 中插值獲取信息從而迫使其學到全局信息;MAE 還指出線性分類并不是唯一評估特征表征能力的基準,且和下游遷移學習的表現不能較好相關。