













擴散模型圖像理解力刷新SOTA!字節復旦團隊提出全新「元提示」策略
Text-to-image(T2I)擴散模型在生成高清晰度圖像方面顯示出了卓越的能力,這一成就得益于其在大規模圖像-文本對上的預訓練。
這引發了一個自然的問題:擴散模型是否可以用于解決視覺感知任務?
近期,來自字節跳動和復旦大學的技術團隊提出了一種簡單而有效的方案:利用擴散模型處理視覺感知任務。

論文地址:https://arxiv.org/abs/2312.14733
開源項目:https://github.com/fudan-zvg/meta-prompts
團隊的關鍵洞察是引入可學習的元提示(meta prompts)到預訓練的擴散模型中,以提取適合特定感知任務的特征。
技術介紹
團隊將text-to-image擴散模型作為特征提取器應用于視覺感知任務中。
輸入圖像首先通過VQVAE編碼器進行圖像壓縮。這一步將圖像分辨率降低到原始大小的1/8,產生latent space中的特征表示,即。值得注意的是,VQVAE編碼器的參數是固定的,不參與后續訓練。
接下來,保持未添加噪聲的被送入到UNet進行特征提取。為了更好地適應不同任務,UNet同時接收調制的timestep embeddings和多個meta prompts,產生與形狀一致的特征。
在整個過程中,為了增強特征表達,該方法進行了步的recurrent refinement。這使得UNet內不同層的特征能夠更好地交互融合。在第次循環中,UNet的參數由特定的可學習的時間調制特征調節。
最終,UNet生成的多尺度特征輸入到專門為目標視覺任務設計的解碼器中。
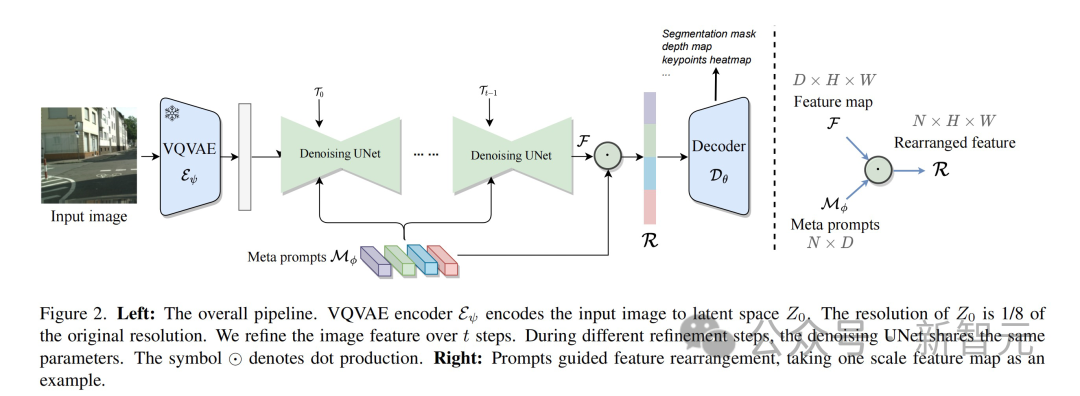
可學習的元提示(meta prompts)設計
Stable diffusion model采用UNet架構,通過交叉注意力將文本提示融入圖像特征中,實現了文生圖。這種整合確保了圖像生成在語境和語義上的準確性。
然而,視覺感知任務的多樣性超出了這一范疇,因為圖像理解面臨著不同的挑戰,往往缺乏文本信息作為指導,使得以文本驅動的方法有時顯得不切實際。
為應對這一挑戰,技術團隊的方法采用了更為多樣的策略——不依賴外部文本提示,而是設計了一種內部的可學習元提示,稱為meta prompts,這些meta prompts被集成到擴散模型中,以適應感知任務。

Meta prompts以矩陣 的形式表示,其中表示meta prompts的數量,表示維度。具備meta prompts的感知擴散模型避免了對外部文本提示的需求,如數據集類別標簽或圖像標題,也無需預訓練的文本編碼器來生成最終的文本提示。
Meta prompts可以根據目標任務和數據集進行端到端的訓練,從而為去噪UNet建立特別定制的適應條件。這些meta prompts包含豐富的、適應于特定任務的語義信息。比如:
- 在語義分割任務中,meta prompts有效地展示了對類別的識別能力,相同的meta prompts傾向于激活同一類別的特征。

- 在深度估計任務中,meta prompts表現出對深度的感知能力,激活值隨深度變化,使prompts能夠集中關注一致距離的物體。

- 在姿態估計中,meta prompts展現出一套不同的能力,特別是關鍵點的感知,這有助于人體姿態檢測。

這些定性結果共同突顯了技術團隊提出的meta prompts在各種任務中對任務相關激活能力的有效性。
作為文本提示的替代品,meta prompts很好地填補了了text-to-image擴散模型與視覺感知任務之間的溝壑。
基于元提示的特征重組
擴散模型通過其固有的設計,在去噪UNet中生成多尺度特征,這些特征在接近輸出層時聚焦于更細致、低級的細節信息。
雖然這種低級細節對于強調紋理和細粒度的任務來說足夠,但視覺感知任務通常需要理解既包括低級細節的又包括高級語義解釋的內容。
因此,不僅需要生成豐富的特征,確定這些多尺度特征的哪種組合方式可以為當前任務提供最佳表征也非常重要。
這就是meta prompts的作用所在——
這些prompts在訓練過程中保存了與所使用數據集特定相關的上下文知識。這種上下文知識使meta prompts能夠充當特征重組的過濾器,引導特征選取過程,從UNet產生的眾多特征中篩選出與任務最相關的特征。
團隊使用點積的方式將UNet的多尺度特征的豐富性與meta prompts的任務適應性結合起來。
考慮多尺度特征,其中每個。和表示特征圖的高度和寬度。Meta prompts 。每個尺度上重排的特征的計算為:
最后,這些經過meta prompts過濾的特征隨后輸入到特定任務的解碼器中。
基于可學習的時間調制特征的recurrent refinement
在擴散模型中,添加噪聲然后多步去噪的迭代過程構成了圖像生成的框架。
受此機制的啟發,技術團隊為視覺感知任務設計了一個簡單的recurrent refinement過程——沒有向輸出特征中添加噪聲,而是直接將UNet的輸出特征循環輸入到UNet中。
同時為了解決隨著模型通過循環,輸入特征的分布會發生變化但UNet的參數保持不變的不一致的問題,技術團隊對于每個循環引入了可學習的獨特的timestep embeddings,以調制UNet的參數。
這確保了網絡對于不同步驟中輸入特征的變化性保持適應性和響應性,優化了特征提取過程,并增強了模型在視覺識別任務中的性能。
結果顯示,該方法在多個感知任務數據集上都取得了最優。




應用落地和展望
該文章提出的方法和技術有廣泛的應用前景,可以在多個領域內推動技術的發展和創新:
- 視覺感知任務的改進:該研究能夠提升各種視覺感知任務的性能,如圖像分割、深度估計和姿態估計。這些改進可應用于自動駕駛、醫學影像分析、機器人視覺系統等領域。
- 增強的計算機視覺模型:所提出的技術可以使計算機視覺模型在處理復雜場景時更加準確和高效,特別是在缺乏明確文本描述的情況下。這對于圖像內容理解等應用尤為重要。
- 跨領域應用:該研究的方法和發現可以激勵跨領域的研究和應用,比如在藝術創作、虛擬現實、增強現實中,用于提高圖像和視頻的質量和互動性。
- 長期展望:隨著技術的進步,這些方法可能會進一步完善,帶來更先進的圖像生成和內容理解技術。
團隊介紹
智能創作團隊是字節跳動AI&多媒體技術中臺,覆蓋了計算機視覺、音視頻編輯、特效處理等技術領域,借助公司豐富的業務場景、基礎設施資源和技術協作氛圍,實現了前沿算法-工程系統-產品全鏈路的閉環,旨在以多種形式為公司內部各業務提供業界前沿的內容理解、內容創作、互動體驗與消費的能力和行業解決方案。
目前,智能創作團隊已通過字節跳動旗下的云服務平臺火山引擎向企業開放技術能力和服務。更多大模型算法相關崗位開放中,歡迎點擊「閱讀原文」查看。



























