













MySQL innodb的B+樹到底長什么樣,為什么MySQL要這樣設計?
背景
最近也許是我們公司給的活動太給力,業務數據量劇增,于是要考慮優化數據庫,作為程序猿的我們都知道數據是我們的命脈,我們做的工作就是處理數據,優化數據是我們一直要面臨的問題。
MySQL優化維度
一般優化數據庫都需要從以下四個維度進行:
- 硬件
- 系統配置
- 數據庫表結構
- SQL 及索引
對于寫業務的我們的最直接就是SQL及索引優化,效果最顯著性、價比最高的是索引優化。
認識索引
索引是幫助數據庫(Mysql)高效獲取數據的排好順序的數據結構。
原理
通過不斷的縮小想要獲得數據的范圍來篩選出最終想要的結果,同時把隨機的事件變成順序的事件,也就是我們總是通過同一種查找方式來鎖定數據。
MySQL索引的數據結構有以下幾種:
- Hash表
- B+樹
使用Hash算法作為索引,有以下問題,所以大部分我們選擇的是BTREE。
- 存在Hash碰撞。
- 只能精確查找,無法用于局部查找和范圍查找。
MySQL的B+樹
我們先來回顧下大學數據結構里面的B+樹,長這個樣子。
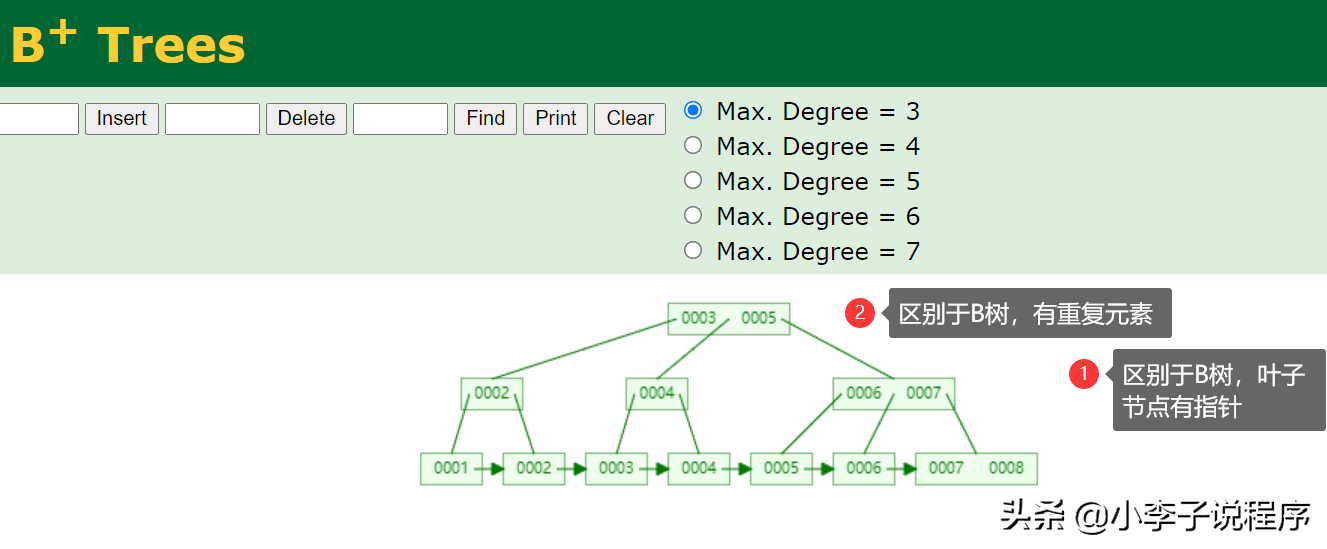
MySQL中的B+數其實是對傳統的B+樹做了改進。
將葉子節點的數據單向指針變成雙向指針,樹高為2。
MySQL每次查1條數據都會查出1頁數據(16K),然后在內存里面遍歷,減少IO,大大提高查詢效率。
Mysql 在插入數據后,會自動給我們排序。為什么要這樣做呢?
1.先看一個例子,查詢一條不存在的數據。
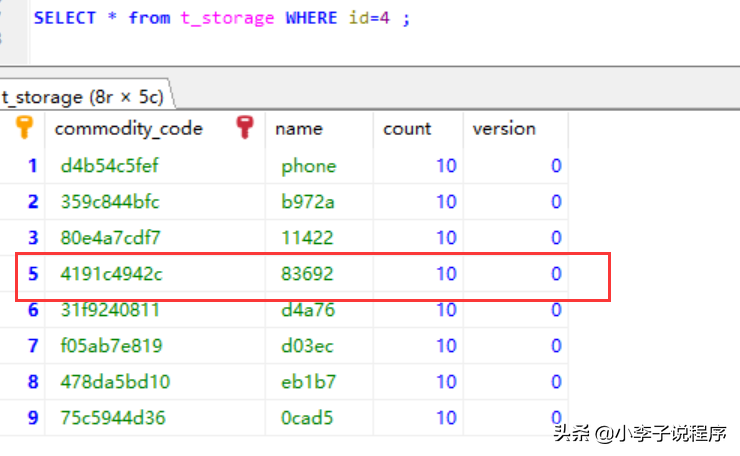
如果排序后,只用遍歷到第4條記錄,就可以不用查了,如果不排序,就要遍歷所有的數據。
2.比較多的數據查詢,還是一頁數據。
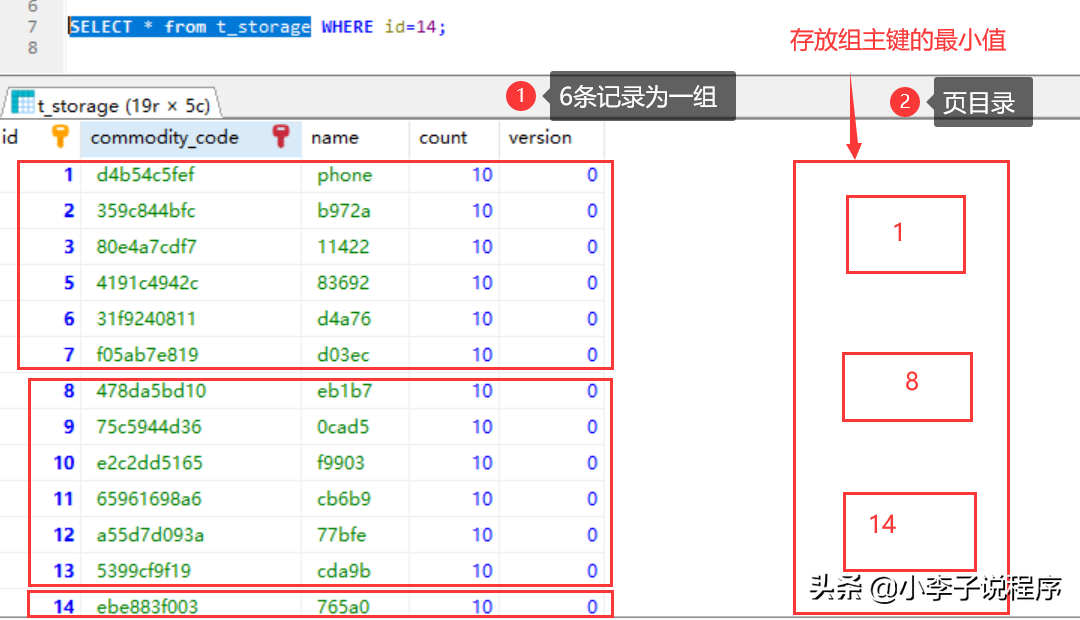
在頁模式底部存儲的數據,采用了鏈表的結構,插入比較快,但是查詢比較慢,數據量比較大的時候就需要用空間換時間,給頁面加個目錄,先去查頁目錄(通過二分法查找)。不加目錄則需要查13次,加了目錄只需要3次就就可以找到數據。這是排序的最主要原因。
3.隨著數據量的進一步增大,會出現很多頁數據,然后再對多頁數據進行索引,即采用了頁目錄的目錄項,從而管理頁,而頁目錄管理行。
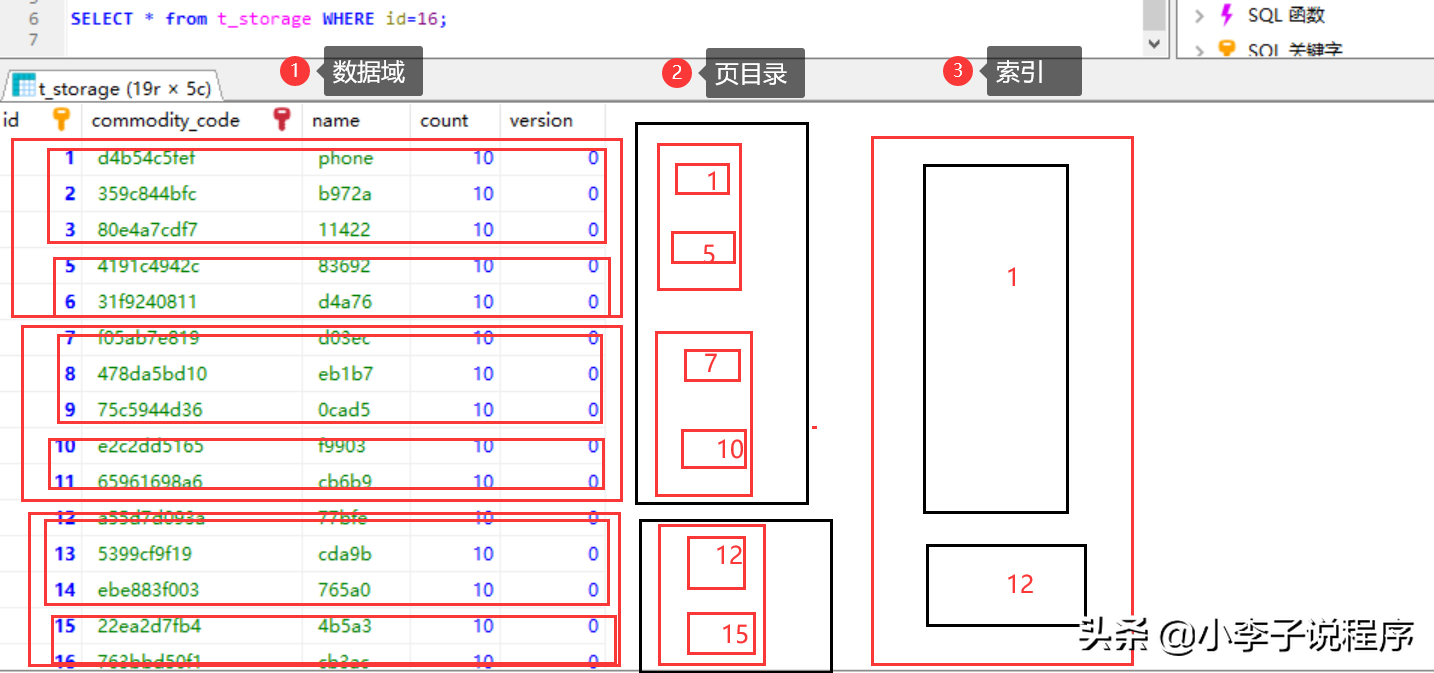
目錄頁的本質也是頁,存的數據是普通頁的地址。所以不管是目錄頁還是頁目錄,都和數據存放在一起。這就是聚簇索引的由來(即主鍵索引和數據放在一起)。這樣就形成了B+樹。
一棵樹存放的數據量
一行存放數據大小按1k算,則一頁存放16行數據。高度為3的b +樹,主鍵為BigInt(占8個字節),innodb 指針占(6個字節),就可以存放(16*1024/(8+6)*(16*1024/(8+6)*16=2千多萬行數據。這就是一般一個表的數據超過2千萬就不建議走索引,要分庫分表的原因了。這樣的結構就可以使得2千萬的數據,只需要3次IO.
雙向指針的原因
范圍查找時,如果查找小于某個值的記錄,就需根據指針要反向查找,所以需要反向指針。
回表
當有多個字段組成組合索引時,此時的索引是非聚簇索引,葉子節點不存儲數據,存儲的是數據行地址,因為數據量比較大。這樣查出后,通過記錄主鍵反查完整記錄。這就是回表。
注意
InnoDB中一定有主鍵索引,主鍵一定是聚簇索引,如果沒有則會使用一個unique索引作為主鍵索引,如果沒有unique索引,則會使用數據庫內部的一個隱藏行id來當作主鍵索引。有且只有一個聚簇索引。非聚簇索引都需要回表。




















