谷歌讓NLP模型也能Debug,只要給一張「草稿紙」就行
本文經AI新媒體量子位(公眾號ID:QbitAI)授權轉載,轉載請聯系出處。
現在的大型語言模型,能力個個都挺強。
但,它們的計算能力都不太行:
比如GPT-3,沒法做超過三位數的加法。
再比如它們當中的大多數都可以寫代碼,但是理解代碼卻很費勁——稍微遇到點帶循環的程序就gg。
不過,來自MIT和谷歌的研究人員發現:
不用修改模型的底層架構,只需訓練它們學會像程序員debug時那樣“打斷點”,讀代碼的能力就唰唰唰地漲上去了。

將同樣的思路用于大數加法、多項式計算,那就更不在話下了。
所以,語言模型的數學能力終于也要跟上了?!
教語言模型用“打斷點”的方法做加法、讀程序
前面說的“打斷點”,其實指的是在計算步驟較多的程序中,讓模型把每一步都編碼為文本,并將它們記錄到一個稱為“便簽”的暫存器中,或者叫“草稿紙”。
聽起來是個“笨”方法,但正是這樣才使得模型的計算過程變得清晰有條理,性能也就比以往直接計算的方式提升了很多。
具體操作也很簡單。
就比如在簡單的加法計算中,計算“29+57”的方式就是像這樣的:

其中C表示進位,#表注釋。
先計算9+7,進位1;再計算2+5+進位1,最后得出86。
從上可以看出,這個訓練示例由“輸入”和“目標”組成。
訓練時將兩者都喂給模型;測試時,模型就能根據“輸入”預測出正確的“目標”。
而“目標”就是要發送到臨時暫存器上的內容,通過關注其上下文就可以引用;實際操作中,還可以對“草稿”內容進行檢查糾錯。
顯著提高語言模型的計算能力
研究人員選用了僅含解碼器結構的Transformer語言模型來實驗,其參數規模介于200萬到1370億之間。
原則上,任何序列模型都可以使用這個方法,包括編-解碼器模型或循環網絡等。
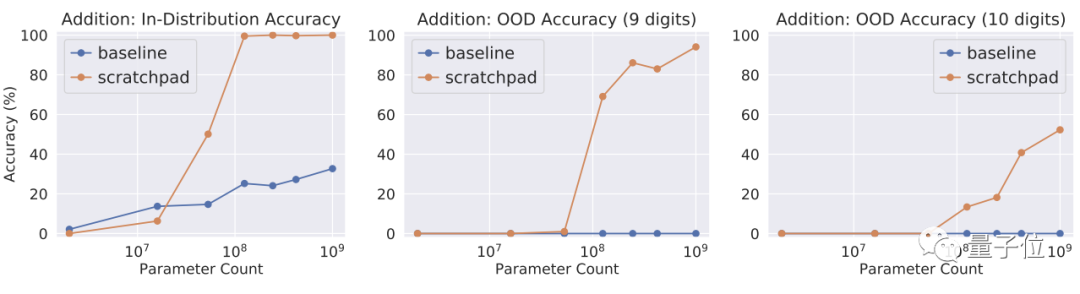
首先,他們按這種“打斷點”的方式訓練語言模型進行1-8位數的整數加法。
訓練包含10萬個示例,并進行了5000步的微調,batch size為32。
然后分別用1萬個數據來測試訓練分布內的加法;1千個數據來測試訓練分布之外,也就是9位和10位數的加法。
將結果分別與直接運算的語言模型進行比較,發現:
即使超出臨界模型大小,用了“打斷點”法的模型也能夠進行加法運算,而直接運算的基線模型就沒法做到這一點。
而在分布外的任務中,直接運算的基線模型完全掛掉——“沒練過就不會做”,而用了“斷點”法的模型隨著規模的增大hold住了9-10位數的加法。
好,大數加法搞定。
接下來上多項式。
他們生成了一個包含1萬個多項式的訓練數據集和2000個數據的測試集。
其中項數一般不超過3項,系數范圍在-10到+10之間,結果在-1000到+10000之間。
多項式的訓練示例如下:

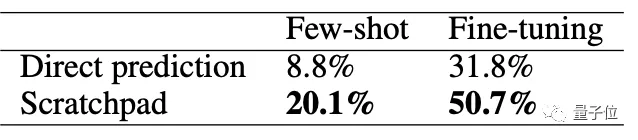
結果發現:無論是微調還是少樣本訓練之后,“斷點”法的性能都優于直接預測。
最后就是讀Python代碼了。
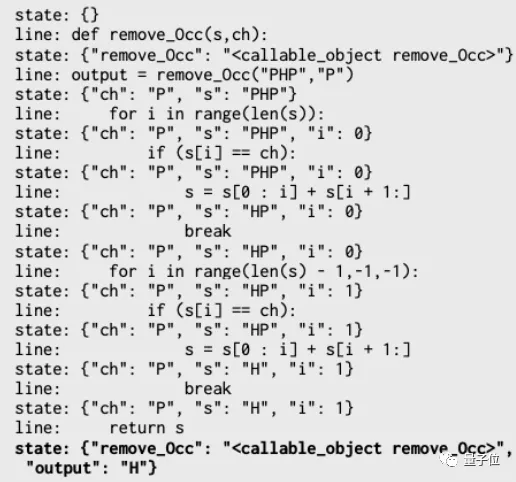
代碼的訓練示例中,記錄了正在執行的是哪行代碼,以及此時各變量的值,用json格式表示。
此前的語言模型讀代碼的能力都表現不佳。“打斷點”的方式可以讓它們一改常態么?
首先,經過200個程序(都是人工編寫的,包括簡單的while循環和if語句)的測試發現,“斷點法”整體執行精度更高。
與直接執行的模型相比,微調還可以將模型性能從26.5%提高到41.5%。

一個真實例子:
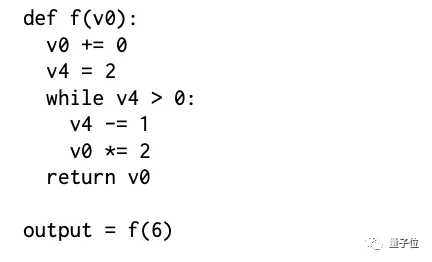
“斷點”法經過3次while循環,最終給出了正確的變量值。

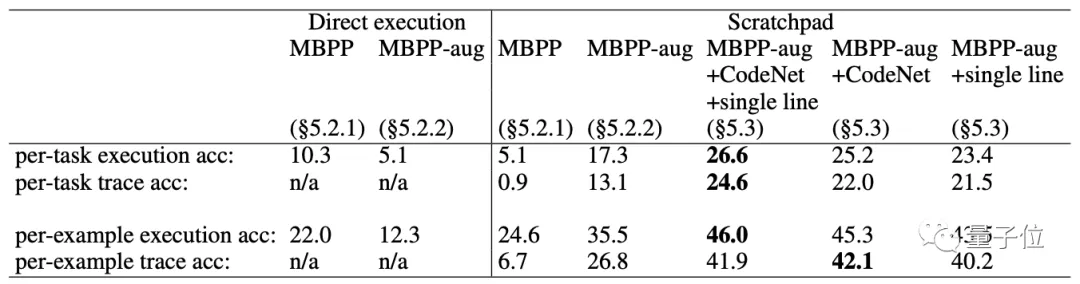
接著,他們又用包含了1000個程序的MBPP數據集進行訓練和測試。
這些程序涉及多種數據類型的計算,包括整數、字符串、浮點數等,以及涉及循環、API調用和遞歸等流程結構。
并添加訓練數據之外的“single line”程序集和CodeNet程序集進行測試。
結果發現,模型也可以很好地擴展。
當然,這個方法也有局限性:
比如復雜的計算可能需要很“長”的暫存器,這可能需要進一步改進Transformer生成窗口的大小。好在這也是NLP領域的一個活躍研究領域。
而在未來,他們可能會嘗試在無監督情況下用強化學習讓語言模型學會“打斷點”。
總之,語言模型的計算能力、讀代碼的能力會越來越強。
論文地址:
https://arxiv.org/abs/2112.00114