













Flink SQL 知其所以然:Table 與 DataStream 的轉轉轉

1.序篇
廢話不多說,咱們先直接上本文的目錄和結論,小伙伴可以先看結論快速了解博主期望本文能給小伙伴們帶來什么幫助:
- 背景及應用場景介紹:博主期望你能了解到,Flink 支持了 SQL 和 Table API 中的 Table 與 DataStream 互轉的接口。通過這種互轉的方式,我們就可以將一些自定義的數據源(DataStream)創建為 SQL 表,也可以將 SQL 執行結果轉換為 DataStream 然后后續去完成一些在 SQL 中實現不了的復雜操作。肥腸的方便。
- 目前只有流任務支持互轉,批任務不支持:在 1.13 版本中,由于流和批的 env 接口不一樣,流任務為 StreamTableEnvironment,批任務為 TableEnvironment,目前只有 StreamTableEnvironment 支持了互轉的接口,TableEnvironment 沒有這樣的接口,因此目前流任務支持互轉,批任務不支持。但是 1.14 版本中流批任務的 env 都統一到了 StreamTableEnvironment 中,流批任務中就都可以進行互轉了。
- Retract 語義 SQL 轉 DataStream 需要重點注意:Append 語義的 SQL 轉為 DataStream 使用的 API 為 StreamTableEnvironment::toDataStream,Retract 語義的 SQL 轉為 DataStream 使用的 API 為 StreamTableEnvironment::toRetractStream,兩個接口不一樣,小伙伴萌一定要特別注意。
2.背景及應用場景介紹
相信大家看到本文的標題時,會比較好奇,要寫 SQL 就純 SQL 唄,要寫 DataStream 就純 DataStream 唄,為啥還要把這兩個接口做集成呢?
博主舉一個案例:在拼多多發優惠券的場景下,為了控制成本,希望能在每日優惠券發放金額加和超過 1w 時,及時報警出來,控制預算。
優惠券表的發放數據:
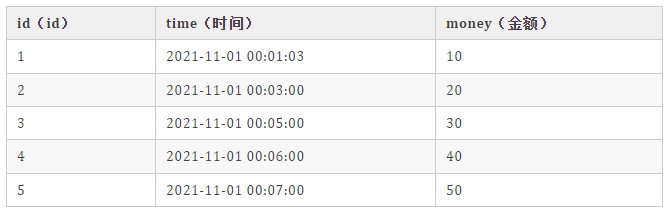
最終期望的結果是:每天的 money 之和超過 1w 的時候,報警報警報警!!!
那么針對上述場景,有兩種對應的解決方案:
- 方案 1:可想而知,DataStream 是必然能夠解決我們的問題的。
- 方案 2:DataStream 開發效率不高,可以使用 SQL 計算優惠券發放的結果,但是 SQL 無法做到報警。所以可以將 SQL 的查詢的結果(即 Table)轉為 DataStream,然后在 DataStream 后自定義報警邏輯的算子,超過閾值進行報警。
本節就介紹方案 2 的實現思路。
注意:
當然還有一些其他的比如模式識別監控異常然后報警的場景使用 DataStream 去實現就更加復雜了,所以我們也可以使用類似的思路,先 SQL 實現業務邏輯,然后接一個 DataStream 算子實現報警邏輯。
3.Table 與 DataStream API 的轉換具體實現
3.1.先看一個官網的簡單案例
官網的案例主要是讓大家看看要做到 Table 與 DataStream API 的轉換會涉及到使用哪些接口。
- import org.apache.flink.streaming.api.datastream.DataStream;
- import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
- import org.apache.flink.table.api.Table;
- import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
- import org.apache.flink.types.Row;
- StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
- StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
- DataStream<String> dataStream = env.fromElements("Alice", "Bob", "John");
- // 1. 使用 StreamTableEnvironment::fromDataStream API 將 DataStream 轉為 Table
- Table inputTable = tableEnv.fromDataStream(dataStream);
- // 將 Table 注冊為一個臨時表
- tableEnv.createTemporaryView("InputTable", inputTable);
- // 然后就可以在這個臨時表上做一些自定義的查詢了
- Table resultTable = tableEnv.sqlQuery("SELECT UPPER(f0) FROM InputTable");
- // 2. 也可以使用 StreamTableEnvironment::toDataStream 將 Table 轉為 DataStream
- // 注意:這里只能轉為 DataStream<Row>,其中的數據類型只能為 Row
- DataStream<Row> resultStream = tableEnv.toDataStream(resultTable);
- // 將 DataStream 結果打印到控制臺
- resultStream.print();
- env.execute();
- // prints:
- // +I[Alice]
- // +I[Bob]
- // +I[John]
可以看到重點的接口就是:
- StreamTableEnvironment::toDataStream:將 Table 轉為 DataStream
- StreamTableEnvironment::fromDataStream:將 DataStream 轉為 Table
3.2.實現第 2 節中的邏輯
我們使用上面介紹的兩個接口對優惠券發放金額預警的案例做一個實現。
- @Slf4j
- public class AlertExample {
- public static void main(String[] args) throws Exception {
- FlinkEnv flinkEnv = FlinkEnvUtils.getStreamTableEnv(args);
- String createTableSql = "CREATE TABLE source_table (\n"
- + " id BIGINT,\n"
- + " money BIGINT,\n"
- + " row_time AS cast(CURRENT_TIMESTAMP as timestamp_LTZ(3)),\n"
- + " WATERMARK FOR row_time AS row_time - INTERVAL '5' SECOND\n"
- + ") WITH (\n"
- + " 'connector' = 'datagen',\n"
- + " 'rows-per-second' = '1',\n"
- + " 'fields.id.min' = '1',\n"
- + " 'fields.id.max' = '100000',\n"
- + " 'fields.money.min' = '1',\n"
- + " 'fields.money.max' = '100000'\n"
- + ")\n";
- String querySql = "SELECT UNIX_TIMESTAMP(CAST(window_end AS STRING)) * 1000 as window_end, \n"
- + " window_start, \n"
- + " sum(money) as sum_money,\n"
- + " count(distinct id) as count_distinct_id\n"
- + "FROM TABLE(CUMULATE(\n"
- + " TABLE source_table\n"
- + " , DESCRIPTOR(row_time)\n"
- + " , INTERVAL '5' SECOND\n"
- + " , INTERVAL '1' DAY))\n"
- + "GROUP BY window_start, \n"
- + " window_end";
- // 1. 創建數據源表,即優惠券發放明細數據
- flinkEnv.streamTEnv().executeSql(createTableSql);
- // 2. 執行 query 查詢,計算每日發放金額
- Table resultTable = flinkEnv.streamTEnv().sqlQuery(querySql);
- // 3. 報警邏輯(toDataStream 返回 Row 類型),如果 sum_money 超過 1w,報警
- flinkEnv.streamTEnv()
- .toDataStream(resultTable, Row.class)
- .flatMap(new FlatMapFunction<Row, Object>() {
- @Override
- public void flatMap(Row value, Collector<Object> out) throws Exception {
- long l = Long.parseLong(String.valueOf(value.getField("sum_money")));
- if (l > 10000L) {
- log.info("報警,超過 1w");
- }
- }
- });
- flinkEnv.env().execute();
- }
- }
執行效果如下:
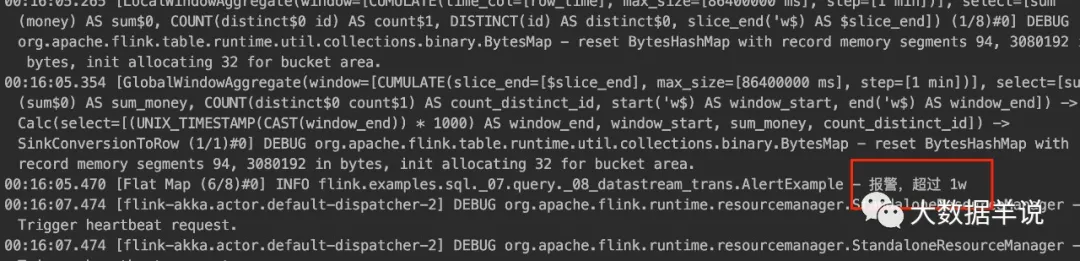
3.3.Table 和 DataStream 轉換注意事項
3.3.1.目前只支持流任務互轉(1.13)
目前在 1.13 版本中,Flink 對于 Table 和 DataStream 的轉化是有一些限制的:
目前流任務使用的 env 為 StreamTableEnvironment,批任務為 TableEnvironment,而 Table 和 DataStream 之間的轉換目前只有 StreamTableEnvironment 的接口支持。
所以其實小伙伴萌可以理解為只有流任務才支持 Table 和 DataStream 之間的轉換,批任務是不支持的(雖然可以使用流模式處理有界流(批數據),但效率較低,這種騷操作不建議大家搞)。
那什么時候才能支持批任務的 Table 和 DataStream 之間的轉換呢?
1.14 版本支持。1.14 版本中,流和批的都統一到了 StreamTableEnvironment 中,因此就可以做 Table 和 DataStream 的互相轉換了。
3.3.2.Retract 語義 SQL 轉 DataStream 注意事項
Retract 語義的 SQL 使用 toDataStream 轉換會報錯不支持。具體報錯截圖如下。意思是不支持 update 類型的結果數據。

如果要把 Retract 語義的 SQL 轉為 DataStream,我們需要使用 toRetractStream。如下案例:
- @Slf4j
- public class AlertExampleRetract {
- public static void main(String[] args) throws Exception {
- FlinkEnv flinkEnv = FlinkEnvUtils.getStreamTableEnv(args);
- String createTableSql = "CREATE TABLE source_table (\n"
- + " id BIGINT,\n"
- + " money BIGINT,\n"
- + " `time` as cast(CURRENT_TIMESTAMP as bigint) * 1000\n"
- + ") WITH (\n"
- + " 'connector' = 'datagen',\n"
- + " 'rows-per-second' = '1',\n"
- + " 'fields.id.min' = '1',\n"
- + " 'fields.id.max' = '100000',\n"
- + " 'fields.money.min' = '1',\n"
- + " 'fields.money.max' = '100000'\n"
- + ")\n";
- String querySql = "SELECT max(`time`), \n"
- + " sum(money) as sum_money\n"
- + "FROM source_table\n"
- + "GROUP BY (`time` + 8 * 3600 * 1000) / (24 * 3600 * 1000)";
- // 1. 創建數據源表,即優惠券發放明細數據
- flinkEnv.streamTEnv().executeSql(createTableSql);
- // 2. 執行 query 查詢,計算每日發放金額
- Table resultTable = flinkEnv.streamTEnv().sqlQuery(querySql);
- // 3. 報警邏輯(toRetractStream 返回 Tuple2<Boolean, Row> 類型),如果 sum_money 超過 1w,報警
- // Tuple2<Boolean, Row> f0 的 Boolean 標識是否是回撤消息
- flinkEnv.streamTEnv()
- .toRetractStream(resultTable, Row.class)
- .flatMap(new FlatMapFunction<Tuple2<Boolean, Row>, Object>() {
- @Override
- public void flatMap(Tuple2<Boolean, Row> value, Collector<Object> out) throws Exception {
- long l = Long.parseLong(String.valueOf(value.f1.getField("sum_money")));
- if (l > 10000L) {
- log.info("報警,超過 1w");
- }
- }
- });
- flinkEnv.env().execute();
- }
- }
4.總結與展望
本文主要介紹了 flink 中 Table 和 DataStream 互轉使用方式,并介紹了一些使用注意事項,總結如下:
- 背景及應用場景介紹:博主期望你能了解到,Flink 支持了 SQL 和 Table API 中的 Table 與 DataStream 互轉的接口。通過這種互轉的方式,我們就可以將一些自定義的數據源(DataStream)創建為 SQL 表,也可以將 SQL 執行結果轉換為 DataStream 然后后續去完成一些在 SQL 中實現不了的復雜操作。肥腸的方便。
- 目前只有流任務支持互轉,批任務不支持:在 1.13 版本中,由于流和批的 env 接口不一樣,流任務為 StreamTableEnvironment,批任務為 TableEnvironment,目前只有 StreamTableEnvironment 支持了互轉的接口,TableEnvironment 沒有這樣的接口,因此目前流任務支持互轉,批任務不支持。但是 1.14 版本中流批任務的 env 都統一到了 StreamTableEnvironment 中,流批任務中就都可以進行互轉了。
- Retract 語義 SQL 轉 DataStream 需要重點注意:Append 語義的 SQL 轉為 DataStream 使用的 API 為 StreamTableEnvironment::toDataStream,Retract 語義的 SQL 轉為 DataStream 使用的 API 為 StreamTableEnvironment::toRetractStream,兩個接口不一樣,小伙伴萌一定要特別注意。






















