













Flink SQL知其所以然:Flink SQLTumble Window 的奇妙解析之路
1.序篇-本文結構
針對 datastream api 大家都比較熟悉了,還是那句話,在 datastream 中,你寫的代碼邏輯是什么樣的,它最終的執行方式就是什么樣的。
但是對于 flink sql 的執行過程,大家還是不熟悉的。上節使用 ETL,group agg(sum,count等)簡單聚合類 query 帶大家走進一條 flink sql query 邏輯的世界。幫大家至少能夠熟悉在 flink sql 程序運行時知道 flink 程序在干什么。
此節就是窗口聚合章節的第一篇,以一個最簡單、最常用的分鐘 tumble window 聚合案例給大家介紹其使用方式和原理。
由于 flink 1.13 引入了 window tvf,所以 1.13 和 1.12 及之前版本的實現不同。本節先介紹 flink 1.12 及之前的 tumble window 實現。這也是大家在引入 flink sql 能力時最常使用的。
本節依然從以下幾個章節給大家詳細介紹 flink sql 的能力。
1.目標篇-本文能幫助大家了解 flink sql 什么?
- 回顧上節的 flink sql 適用場景的結論
2.概念篇-先聊聊常見的窗口聚合
- 窗口竟然拖慢數據產出?
- 常用的窗口
3.實戰篇-簡單的 tumble window 案例和運行原理
- 先看一個 datastream 窗口案例
- flink sql tumble window 的語義
- tumble window 實際案例
- GeneratedWatermarkGenerator - flink 1.12.1
- BinaryRowDataKeySelector - flink 1.12.1
- AggregateWindowOperator - flink 1.12.1
4.總結與展望篇
先說說結論,以下這些結論已經在上節說過了,此處附上上節文章:
場景問題:flink sql 很適合簡單 ETL,以及基本全部場景下的聚合類指標(本節要介紹的 tumble window 就在聚合類指標的范疇之內)。
語法問題:flink sql 語法其實是和其他 sql 語法基本一致的。基本不會產生語法問題阻礙使用 flink sql。但是本節要介紹的 tumble window 的語法就是略有不同的那部分。下面詳細介紹。
運行問題:查看 flink sql 任務時的一些技巧,以及其中一些可能會碰到的坑:
- 去 flink webui 就能看到這個任務目前在做什么。包括算子名稱都會給直接展示給我們目前哪個算子在干啥事情,在處理啥邏輯。
- sql 的 watermark 類型要設置為 TIMESTAMP(3)。
- 事件時間邏輯中,sql api 和 datastream api 對于數據記錄時間戳存儲邏輯是不一樣的。datastream api:每條記錄的 rowtime 是放在 StreamRecord 中的時間戳字段中的。sql api:時間戳是每次都從數據中進行獲取的。算子中會維護一個下標。可以按照下標從數據中獲取時間戳。
2.目標篇-本文能幫助大家了解 flink sql tumble window 什么?
關于 flink sql tumble window 一般都會有以下問題。本文的目標也是為大家解答這些問題:
場景問題:場景問題就不必多說,datastream 在 tumble window 場景下的應用很多了,分鐘級別聚合等常用場景
語法問題:flink sql 寫 tumble window 任務時是一種與 hive sql 中沒有的語法。下文詳細介紹。
運行問題:使用一條簡單的 tumble window sql 幫大家從 transformation、runtime 幫大家理解 tumble window 的整體運行機制。
理解誤區:既然是 sql 必然要遵循 sql 語義,sql tumble window 聚合是輸入多條,產出一條數據。并不像 datastream 那樣可以在窗口 udf 中做到多對多。
在正式開始聊 tumble window 之前,先看看上節 flink sql 適用場景的結論。讓大家先有 flink sql 的一個整體印象以及結論。
2.1.回顧上節的 flink sql 適用場景的結論
不裝了,我坦白了,flink sql 其實很適合干的活就是 dwd 清洗,dws 聚合。
此處主要針對實時數倉的場景來說。flink sql 能干 dwd 清洗,dws 聚合,基本上實時數倉的大多數場景都能給覆蓋了。
flink sql 牛逼!!!
但是!!!
經過博主使用 flink sql 經驗來看,并不是所有的 dwd,dws 聚合場景都適合 flink sql(截止發文階段來說)!!!
其實這些目前不適合 flink sql 的場景總結下來就是在處理上比 datastream 還是會有一定的損失。
先總結下使用場景:
1. dwd:簡單的清洗、復雜的清洗、維度的擴充、各種 udf 的使用
2. dws:各類聚合
然后分適合的場景和不適合的場景來說,因為只這一篇不能覆蓋所有的內容,所以本文此處先大致給個結論,之后會結合具體的場景詳細描述。
適合的場景:
簡單的 dwd 清洗場景
全場景的 dws 聚合場景
目前不太適合的場景:
復雜的 dwd 清洗場景:舉例比如使用了很多 udf 清洗,尤其是使用很多的 json 類解析清洗
關聯維度場景:舉例比如 datastream 中經常會有攢一批數據批量訪問外部接口的場景,flink sql 目前對于這種場景雖然有 localcache、異步訪問能力,但是依然還是一條一條訪問外部緩存,這樣相比批量訪問還是會有性能差距。
3.概念篇-先聊聊常見的窗口聚合
窗口聚合大家都在 datastream api 中很熟悉了,目前在實時數據處理的過程中,窗口計算可以說是最重要、最常用的一種計算方式了。
但是在拋出窗口概念之前,博主有幾個關于窗口的小想法說一下。
3.1.窗口竟然拖慢數據產出?
一個小想法。
先拋結論:窗口會拖慢實時數據的產出,是在目前下游分析引擎能力有限的情況下的一種妥協方案。
站在數據開發以及需求方的世界中,當然希望所有的數據都是實時來的,實時處理的,實時產出的,實時展現的。
舉個例子:如果你要滿足一個一分鐘窗口聚合的 pv,uv,或者其他聚合需求。
olap 數據服務引擎 就可以滿足上述的實時來的,實時處理的,實時產出的,實時展現的的場景。flink 消費處理明細數據,產出到 kafka,然后直接導入到 olap 引擎中。查詢時直接用 olap 做聚合。這其中是沒有任何窗口的概念的。但是整個鏈路中,要保障端對端精確一次,要保障大數據量情況下 olap 引擎能夠秒級查詢返回,更何況有一些去重類指標的計算,等等場景。把這些壓力都放在 olap 引擎的壓力是很大的。
因此在 flink 數據計算引擎中就誕生了窗口的概念。我們可以直接在計算引擎中進行窗口聚合計算,然后等到窗口結束之后直接把結果數據產出。這就出現了博主所說的窗口拖慢了實時數據產出的情況。而且窗口在處理不好的情況下可能會導致數據丟失。
關于上述兩種情況的具體優劣選擇,都由大家自行選擇。上述只是引出博主一些想法。
3.2.常用的窗口
目前已知的窗口分為以下四種。
1. Tumble Windows2. Hop Windows3. Cumulate Windows4. Session Windows
這些窗口的具體描述直接見官網,有詳細的說明。此處不贅述。
https://nightlies.apache.org/flink/flink-docs-release-1.13/docs/dev/table/sql/queries/window-agg/
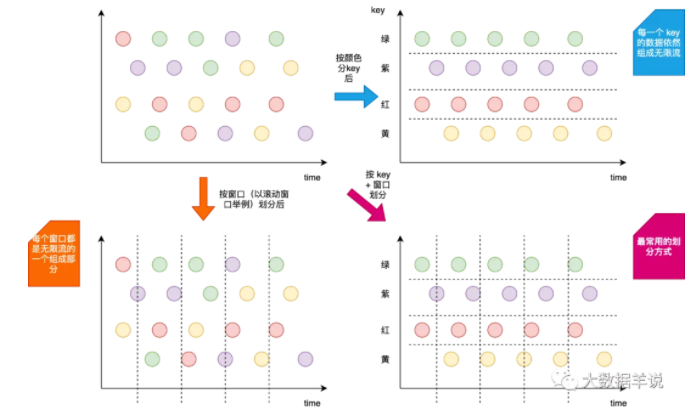
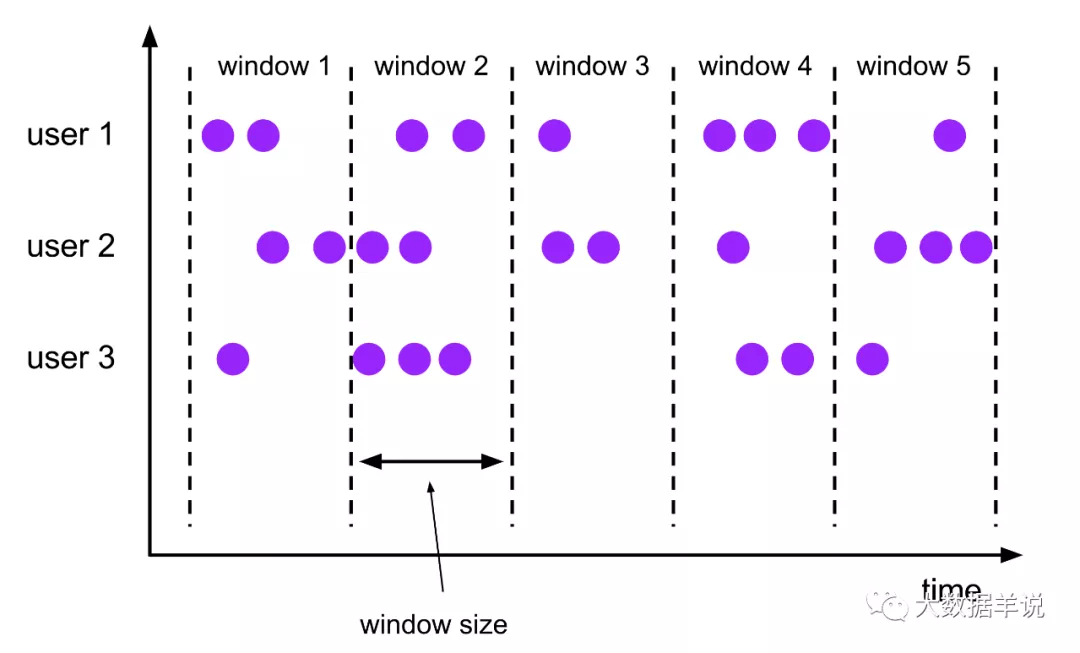
此處介紹下 flink 中常常會涉及到的兩個容易混淆的概念就是:窗口 + key。這里來形象的說明下。
窗口:時間周期上面的劃分。將無限流進行縱向切分,將無限流切分為一個一個的窗口,窗口相當于是無限流中的一段時間內的數據。
key:數據類別上面的劃分。將無限流進行橫向劃分,相同 key 的數據會被劃分到一組中,這個 key 的數據也是一條無限流。
如下圖所示。
4.實戰篇-簡單的 tumble window 案例和運行原理
源碼公眾號后臺回復flink sql tumble window 的奇妙解析之路獲取。
4.1.先看一個 datastream 窗口案例
在介紹 sql tumble window 窗口算子執行案例之前,先看一個 datastream 中的窗口算子案例。其邏輯都是相通的。會對我們了解 sql tumble window 算子有幫助。
我們先看看 datastream 處理邏輯。
以下面這個為例。
- public class _04_TumbleWindowTest {
- public static void main(String[] args) throws Exception {
- StreamExecutionEnvironment env =
- StreamExecutionEnvironment.createLocalEnvironmentWithWebUI(new Configuration());
- env.setParallelism(1);
- env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);
- env.addSource(new UserDefinedSource())
- .assignTimestampsAndWatermarks(new BoundedOutOfOrdernessTimestampExtractor<Tuple4<String, String, Integer, Long>>(Time.seconds(0)) {
- @Override
- public long extractTimestamp(Tuple4<String, String, Integer, Long> element) {
- return element.f3;
- }
- })
- .keyBy(new KeySelector<Tuple4<String, String, Integer, Long>, String>() {
- @Override
- public String getKey(Tuple4<String, String, Integer, Long> row) throws Exception {
- return row.f0;
- }
- })
- .window(TumblingEventTimeWindows.of(Time.seconds(10)))
- .sum(2)
- .print();
- env.execute("1.12.1 DataStream TUMBLE WINDOW 案例");
- }
- private static class UserDefinedSource implements SourceFunction<Tuple4<String, String, Integer, Long>> {
- private volatile boolean isCancel;
- @Override
- public void run(SourceContext<Tuple4<String, String, Integer, Long>> sourceContext) throws Exception {
- while (!this.isCancel) {
- sourceContext.collect(Tuple4.of("a", "b", 1, System.currentTimeMillis()));
- Thread.sleep(10L);
- }
- }
- @Override
- public void cancel() {
- this.isCancel = true;
- }
- }
- }
datastream 生產的具體的 transformation 如下圖:
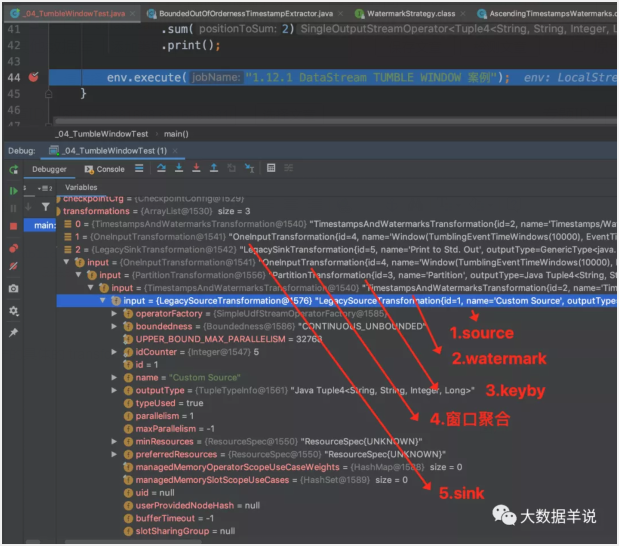
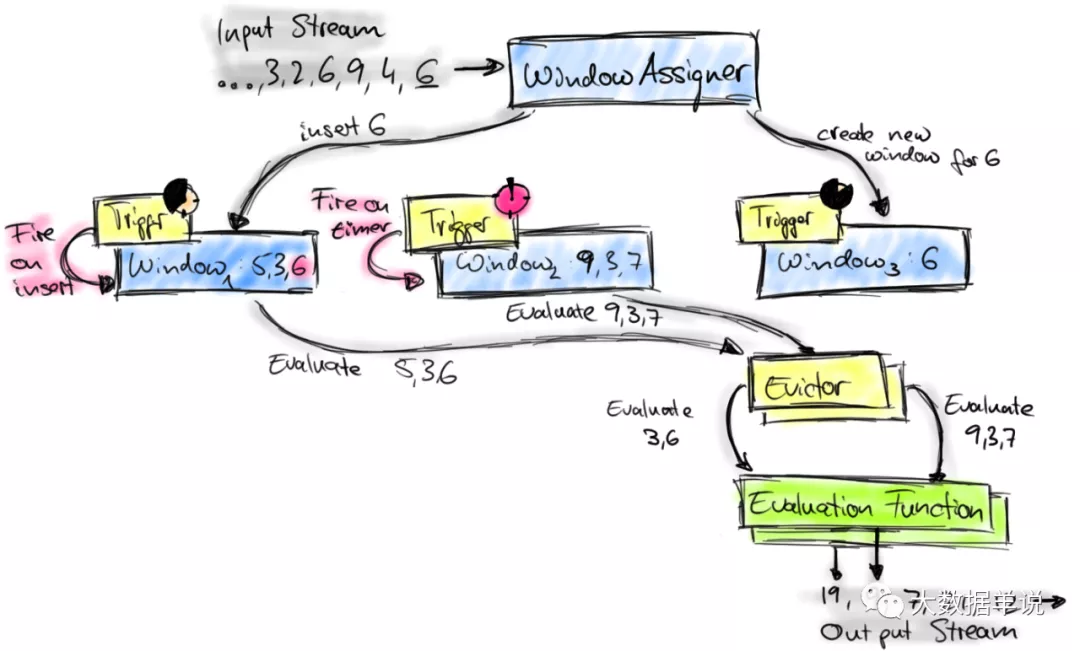
其中我們只關注最重要的 WindowOperator 算子。
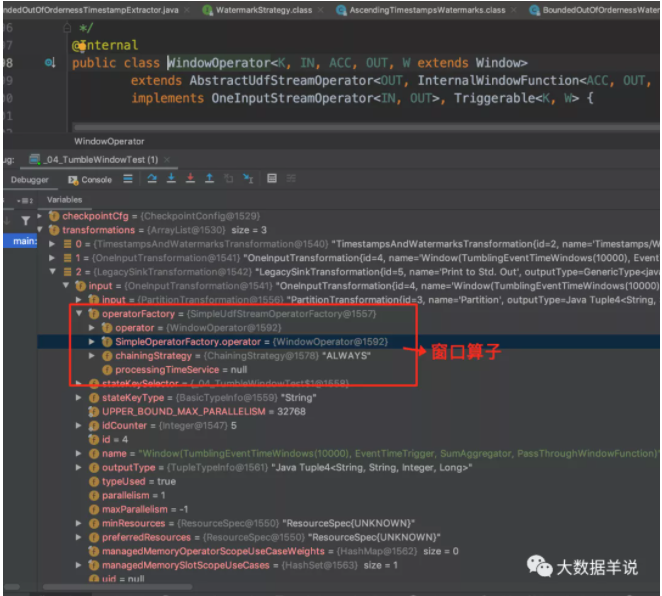
其中 WindowOperator 算子包含的重要屬性如下圖。
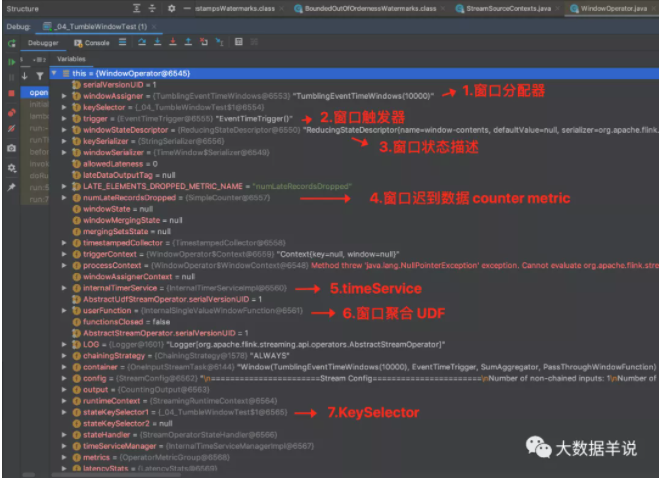
來看看 WindowOperator 的執行邏輯。窗口執行的整體詳細流程可以參考:http://wuchong.me/blog/2016/05/25/flink-internals-window-mechanism/
4.2.flink sql tumble window 的語義
介紹到 tumble window 的語義,總要有對比的去介紹。這里的參照物就是 datastream api。
在 datastream api 中。tumble window 一般用作以下兩種場景。
業務場景:使用 tumble window 很輕松的計算出窗口內的聚合數據。一般是多條輸入數據,窗口結束時一條輸出數據。
優化場景:窗口聚合一批數據然后批量訪問外部存儲擴充維度、或者有一些自定義的處理邏輯。一般是多條輸入數據,窗口結束時多條輸出數據。
但是在 sql api 中。tumble window 是聚合(group by)語義,聚合在 sql 標準中的數據處理邏輯是多條輸入,在窗口觸發時就輸出一條數據的語義。而上面的常常用在 datastream 中的優化場景是多對多的場景。因此和 sql 語義不符合。所以 flink sql tumble window 一般都是用于計算聚合運算值來使用。
4.3.tumble window 實際案例
滾動窗口的特性就是會將無限流進行縱向劃分成一個一個的窗口,每個窗口都是相同的大小,并且不重疊。
本文主要介紹 flink 1.12 及之前版本的實現。下一篇文章介紹 flink 1.13 的實現。
來,在介紹原理之前,總要先用起來,我們就以下面這個例子展開。
1.(flink 1.12.1)場景:簡單且常見的分維度分鐘級別同時在線用戶數、總銷售額
數據源表:
- CREATE TABLE source_table (
- -- 維度數據
- dim STRING,
- -- 用戶 id
- user_id BIGINT,
- -- 用戶
- price BIGINT,
- -- 事件時間戳
- row_time AS cast(CURRENT_TIMESTAMP as timestamp(3)),
- -- watermark 設置
- WATERMARK FOR row_time AS row_time - INTERVAL '5' SECOND
- ) WITH (
- 'connector' = 'datagen',
- 'rows-per-second' = '10',
- 'fields.dim.length' = '1',
- 'fields.user_id.min' = '1',
- 'fields.user_id.max' = '100000',
- 'fields.price.min' = '1',
- 'fields.price.max' = '100000'
- )
- Notes - 關于 watermark 容易踩得坑:sql 的 watermark 類型必須要設置為 TIMESTAMP(3)。
數據匯表:
- CREATE TABLE sink_table (
- dim STRING,
- pv BIGINT,
- sum_price BIGINT,
- max_price BIGINT,
- min_price BIGINT,
- uv BIGINT,
- window_start bigint
- ) WITH (
- 'connector' = 'print'
- )
數據處理邏輯:
可以看下下面語法,窗口聚合的寫法有專門的 tumble(row_time, interval '1' minute) 寫法,這就是與平常我們寫的 hive sql,mysql 等不一樣的地方。
- insert into sink_table
- select dim,
- sum(bucket_pv) as pv,
- sum(bucket_sum_price) as sum_price,
- max(bucket_max_price) as max_price,
- min(bucket_min_price) as min_price,
- sum(bucket_uv) as uv,
- max(window_start) as window_start
- from (
- select dim,
- count(*) as bucket_pv,
- sum(price) as bucket_sum_price,
- max(price) as bucket_max_price,
- min(price) as bucket_min_price,
- -- 計算 uv 數
- count(distinct user_id) as bucket_uv,
- cast(tumble_start(row_time, interval '1' minute) as bigint) * 1000 as window_start
- from source_table
- group by
- -- 按照用戶 id 進行分桶,防止數據傾斜
- mod(user_id, 1024),
- dim,
- tumble(row_time, interval '1' minute)
- )
- group by dim,
- window_start
2.運行:可以看到,其實在 flink sql 任務中,其會把對應的處理邏輯給寫到算子名稱上面。
- Notes - 觀察 flink sql 技巧 1:這個其實就是我們觀察 flink sql 任務的第一個技巧。如果你想知道你的 flink 任務在干啥,第一反應是去 flink webui 看看這個任務目前在做什么。包括算子名稱都會給直接展示給我們目前哪個算子在干啥事情,在處理啥邏輯
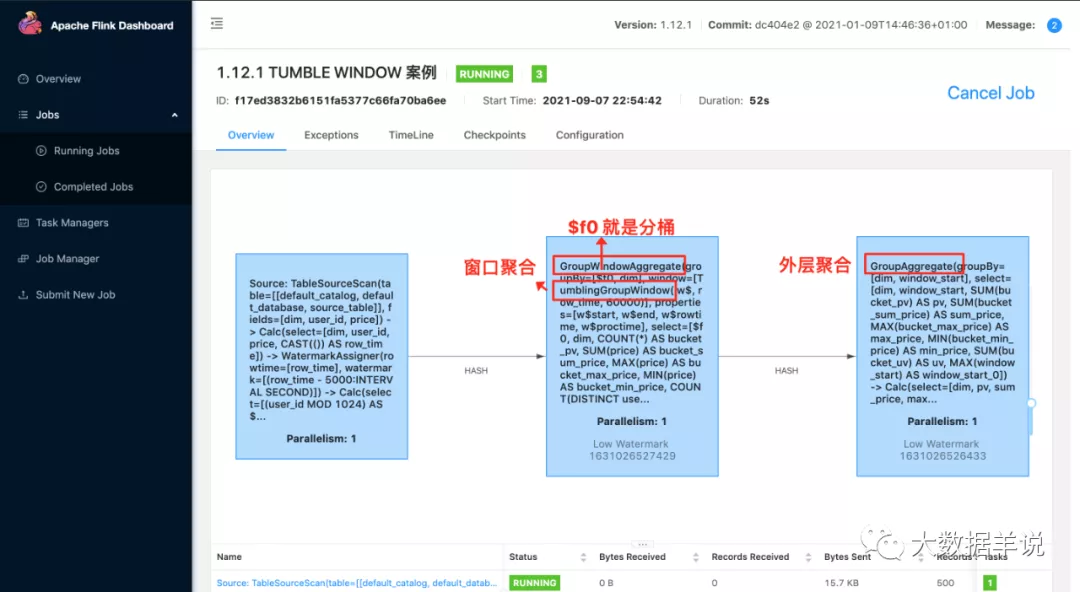
先看一下整個算子圖,如下圖。從左到右總共分為三個算子。
第一個算子就是數據源算子
第二個算子就是分了桶的窗口聚合算子,第一個算子和第二個算子之間 hash 傳輸就是按照 group key 進行 hash 傳輸
第三個算子就是外層進行合桶計算的算子,同樣也是 hash 傳輸,將分桶的數據在一個算子中進行合并計算
來看看每一個算子具體做了什么事情。
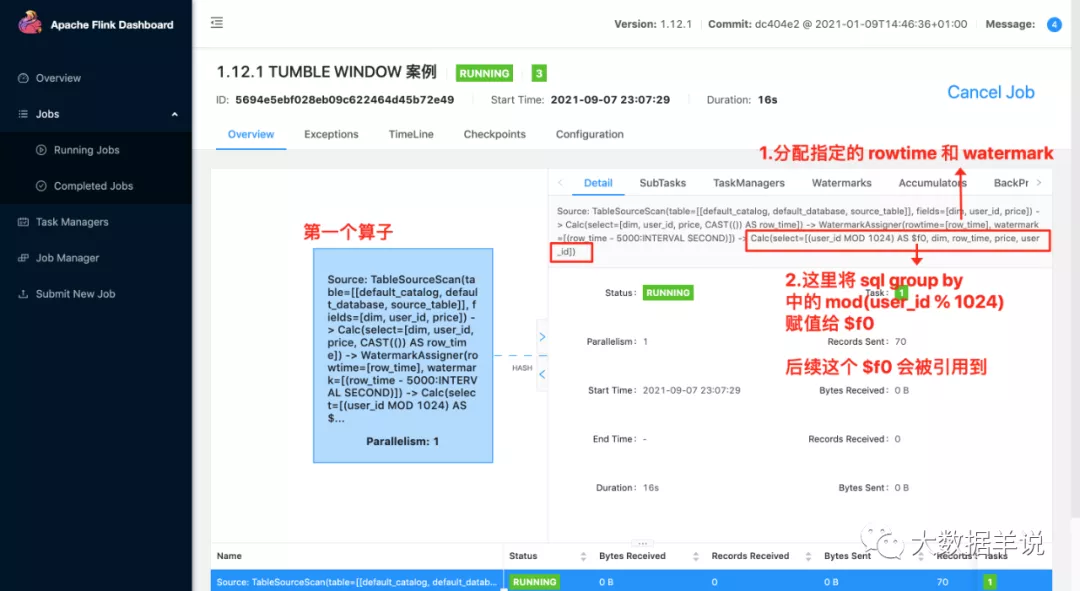
第一個算子:
table scan 讀取數據源
從數據源中獲取對應的字段(包括源表定義的 rowtime)
分配 watermark(按照源表定義的 watermark 分配對應的 watermark)
將一些必要的字段抽取。比如 group by 中的字段。在 hash 時需要使用。
第二個算子:
窗口聚合,計算窗口聚合數據
將數據按照第一層 select 中的數據進行計算以及格式化
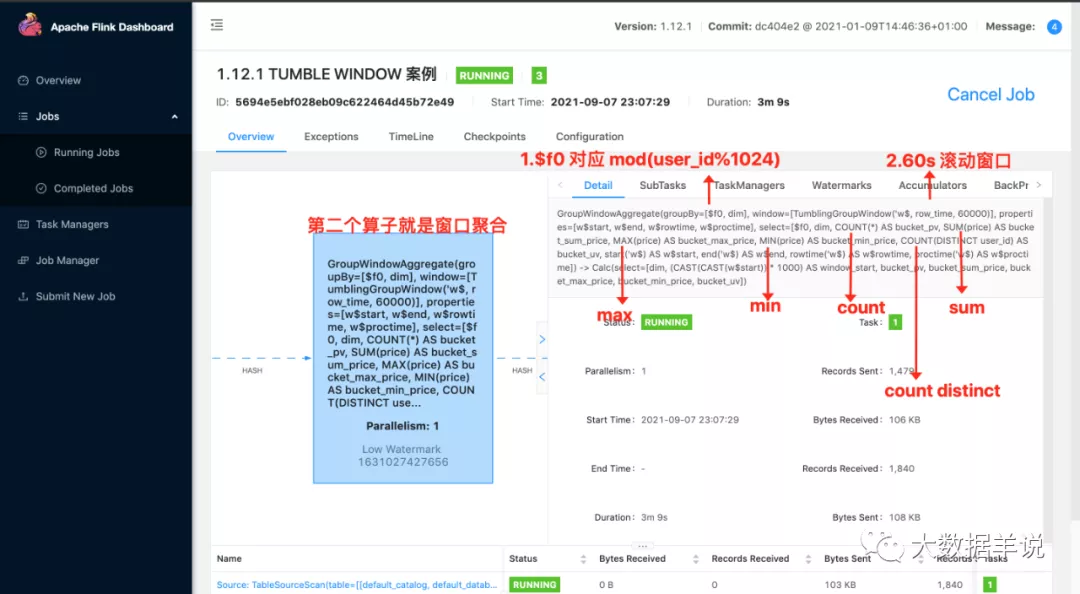
第三個算子:
group 聚合合桶計算
將數據按照第二層 select 中的數據進行計算以及格式化
將數據 sink 寫出
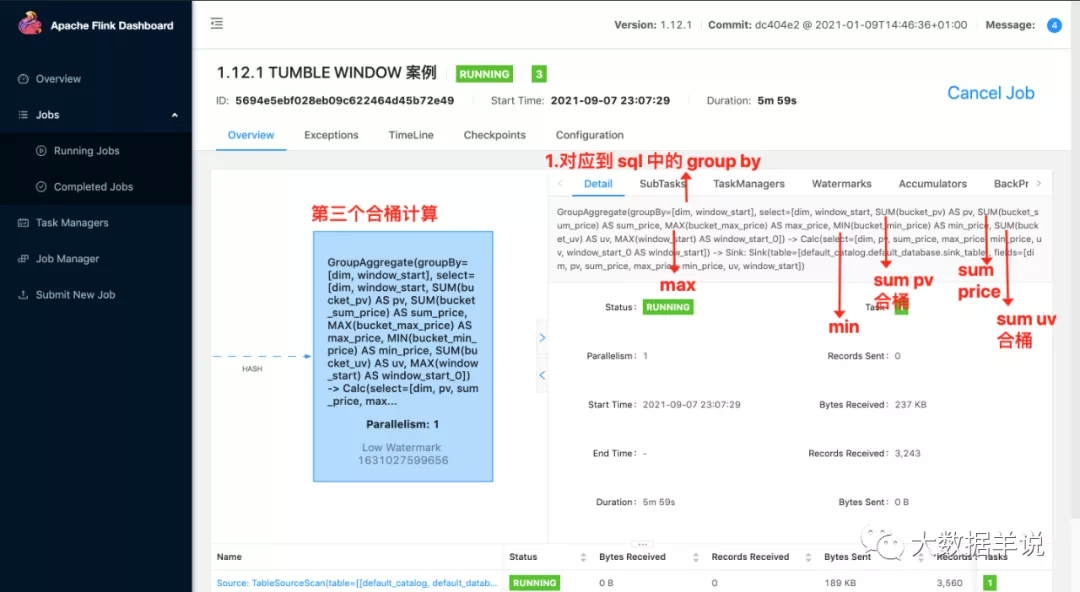
3.(flink 1.12.1)結果:
- +I(9,1,32682,32682,32682,1,1631026440000)
- -U(9,1,32682,32682,32682,1,1631026440000)
- +U(9,2,115351,82669,32682,2,1631026440000)
- +I(2,1,76148,76148,76148,1,1631026440000)
- +I(8,1,79321,79321,79321,1,1631026440000)
- +I(a,1,85792,85792,85792,1,1631026440000)
- +I(0,1,12858,12858,12858,1,1631026440000)
- +I(5,1,36753,36753,36753,1,1631026440000)
- +I(3,1,19218,19218,19218,1,1631026440000)
4.(flink 1.12.1)原理:
關于 sql 開始運行的機制見上一節詳述。
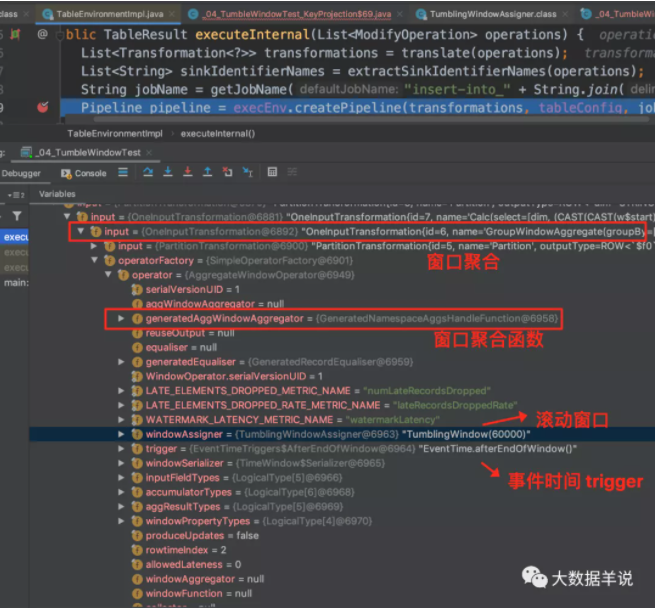
此處只介紹相比前一節新增內容。可以看到上述代碼的具體 transformation 如下圖。
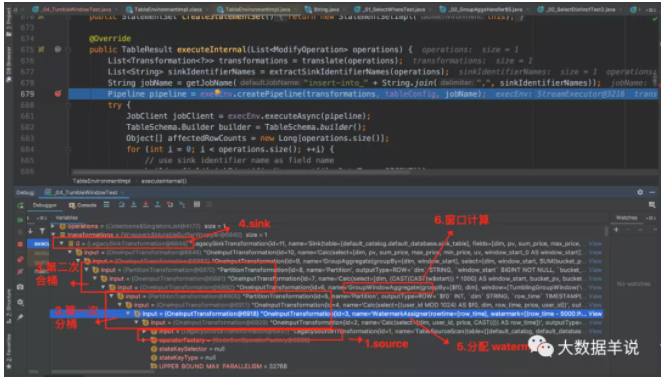
4.4.GeneratedWatermarkGenerator - flink 1.12.1
按照順序,首先看看 watermark 算子。同 datastream 的自定義 watermark 分配策略。
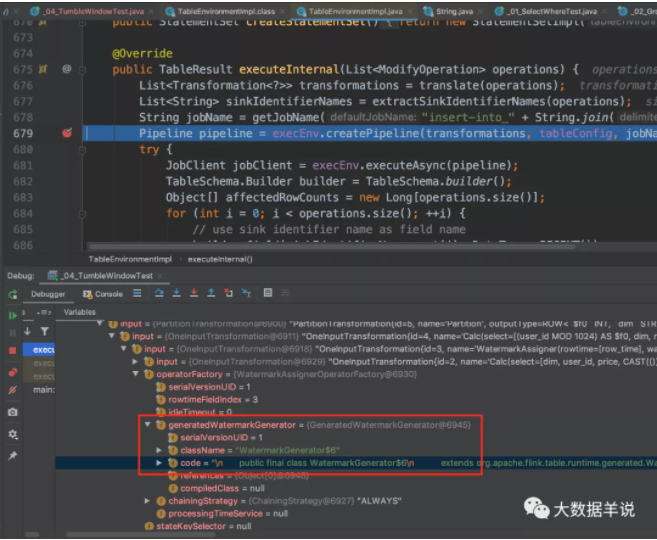
watermark 生成的具體代碼 WatermarkGenerator$6,主要獲取 watermark 的邏輯在 currentWatermark 方法中。如下圖。
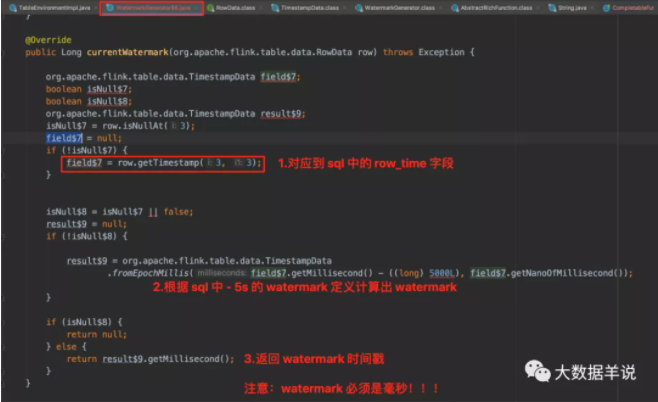
4.5.BinaryRowDataKeySelector - flink 1.12.1
接著就是 group by(同 datastream 中的 keyby)。
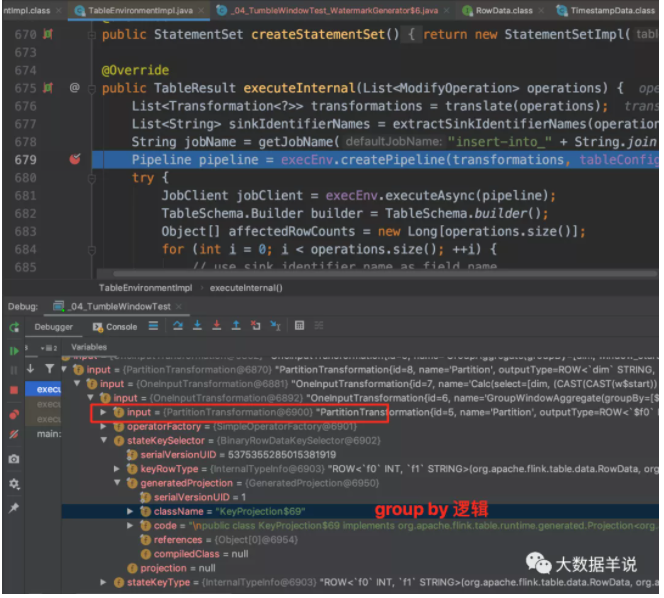
group by key 生成的具體代碼 KeyProjection$19,主要邏輯在 apply 方法中。
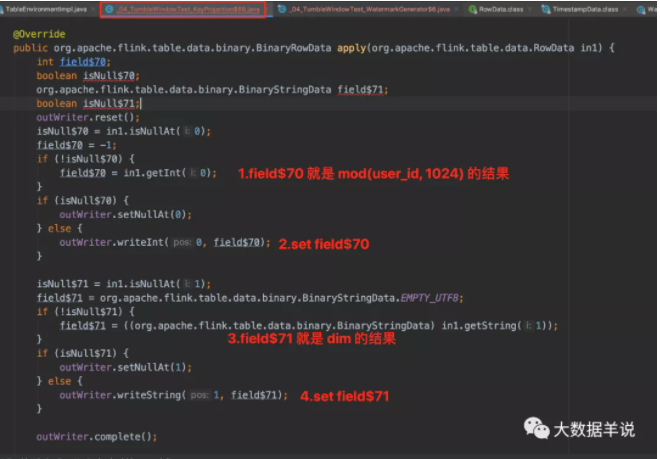
下一個就是窗口聚合算子。
4.6.AggregateWindowOperator - flink 1.12.1
兄弟們!!!兄弟們!!!兄弟們!!!
本節的重頭戲來了。sql 窗口聚合算子解析搞起來了。
關于 WatermarkGenerator 和 KeyProjection 沒有什么可以詳細介紹的,都是輸入一條數據,輸出一條數據,邏輯很簡單。
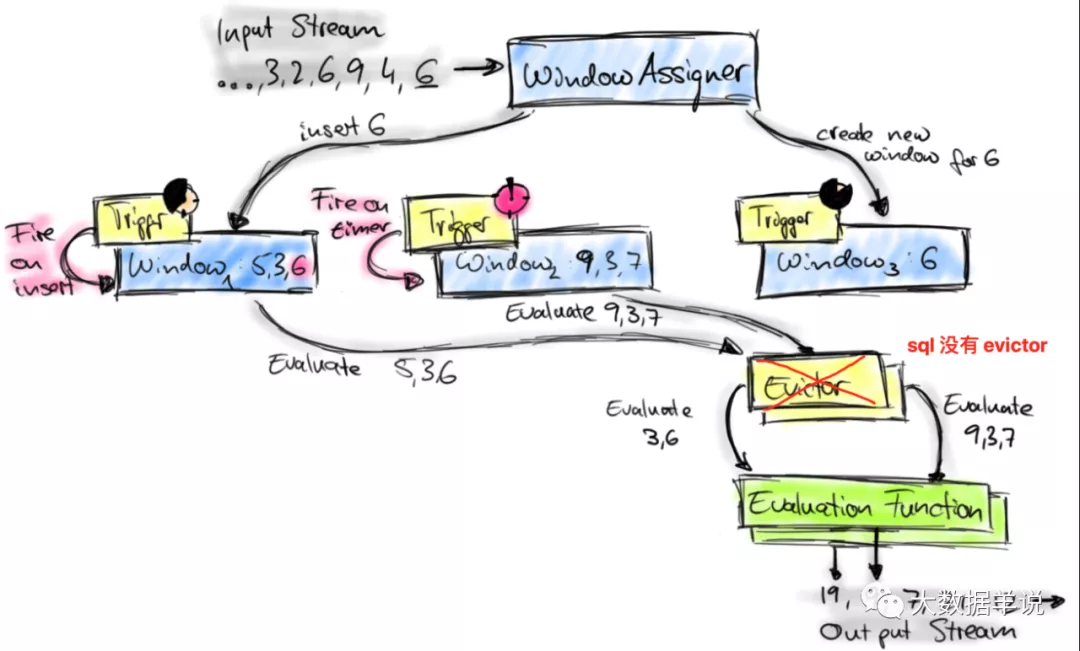
但是窗口聚合算子的計算邏輯相比上面兩個算子復雜很多。窗口算子又承載了窗口聚合的主要邏輯,所以本文重點介紹窗口算子計算的邏輯。
先來看看 sql 窗口整體處理流程。其實與 datastream 處理流程基本一致,但只是少了 Evictor。如下圖所示。
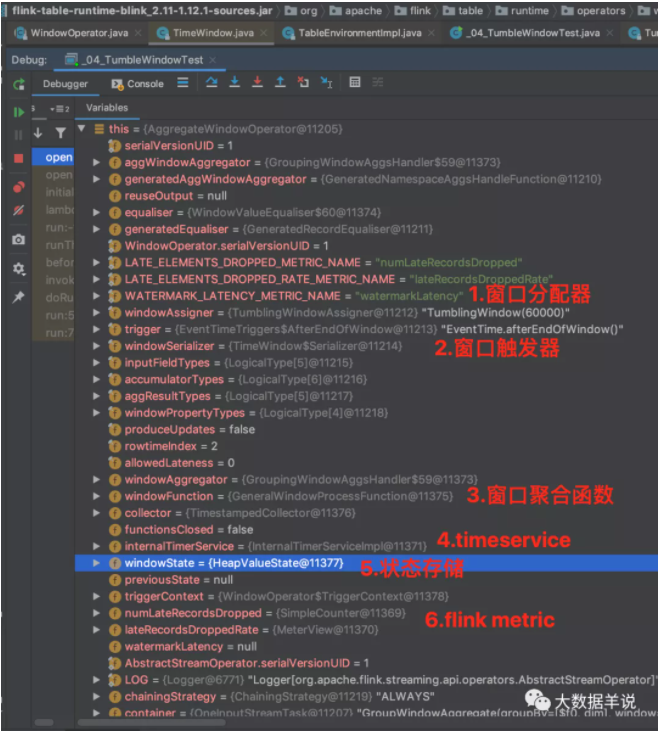
接著來看看上述 sql 生成的窗口聚合算子 AggregateWindowOperator,截圖中屬性也很清晰。
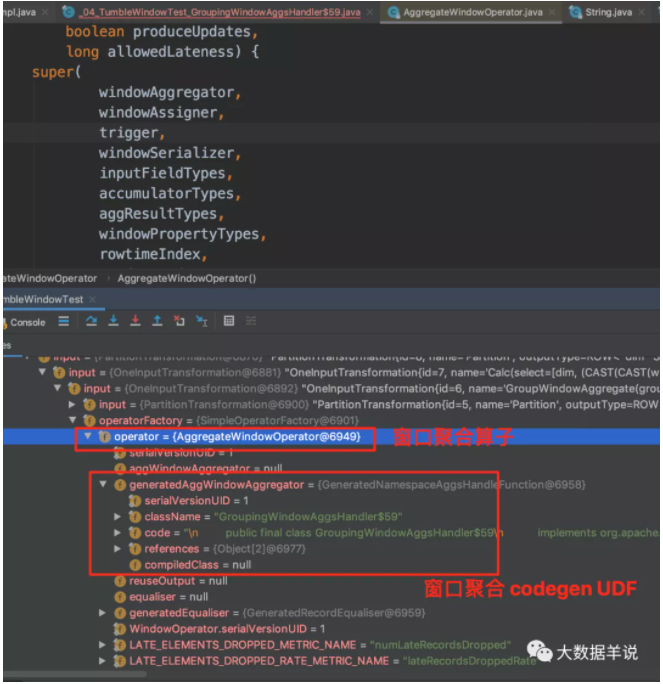
具體生成的窗口聚合代碼 GroupingWindowAggsHandler$59。
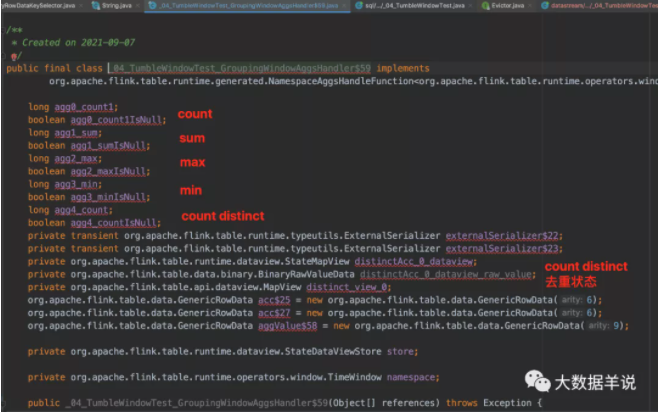
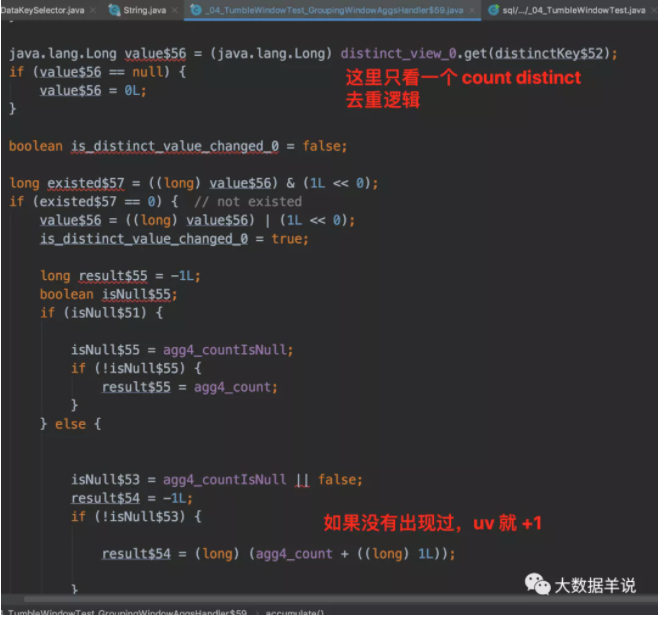
計算邏輯 GroupingWindowAggsHandler$59#accumulate。
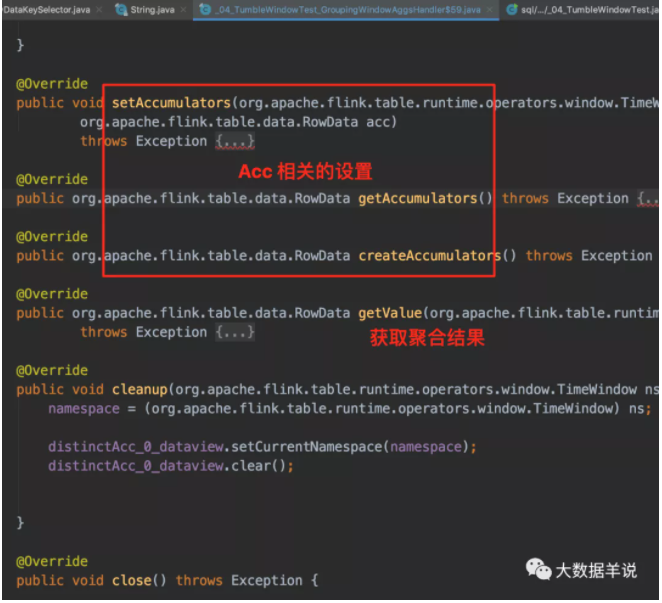
上面那段都是在 flink 客戶端初始化處理的。包括窗口算子的初始化等。
下面這段處理邏輯是在 flink TM 運行時開始執行的,包括窗口算子資源的初始化以及運行邏輯。就到了正式的數據處理環節了。
窗口算子 Task 運行。
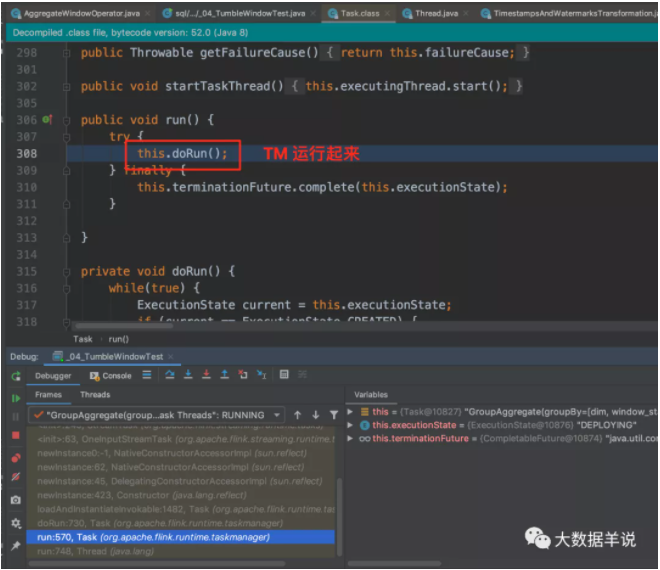
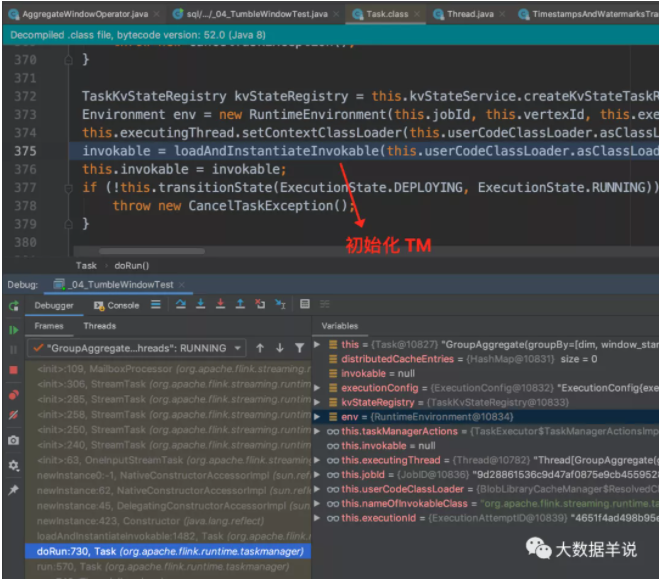
窗口算子 Task 初始化。
StreamTask 整體的處理流程。
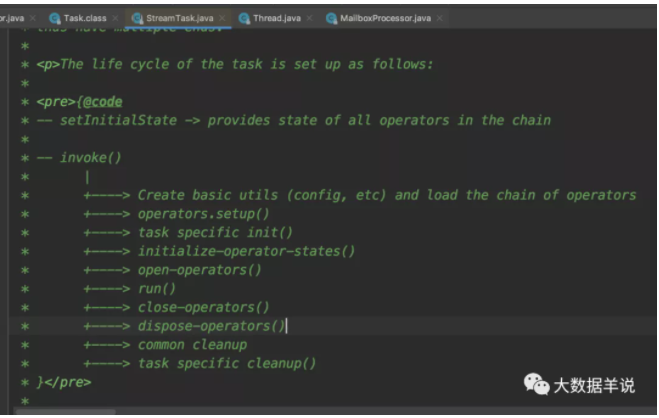
窗口算子 open 初始化。
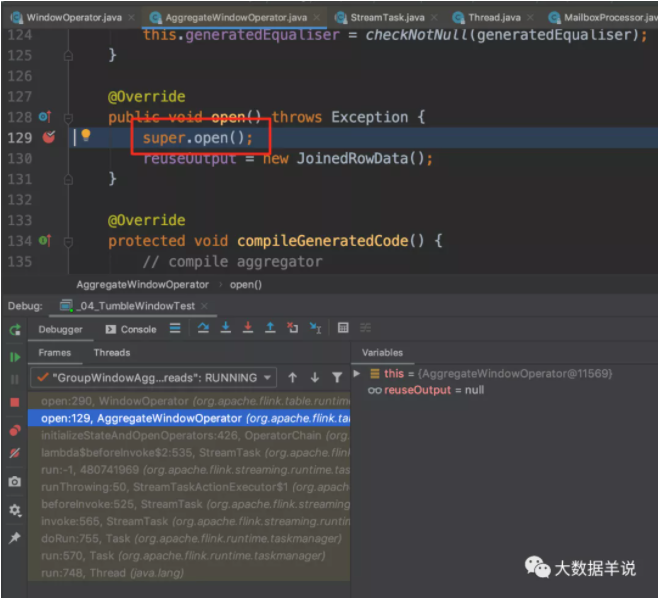
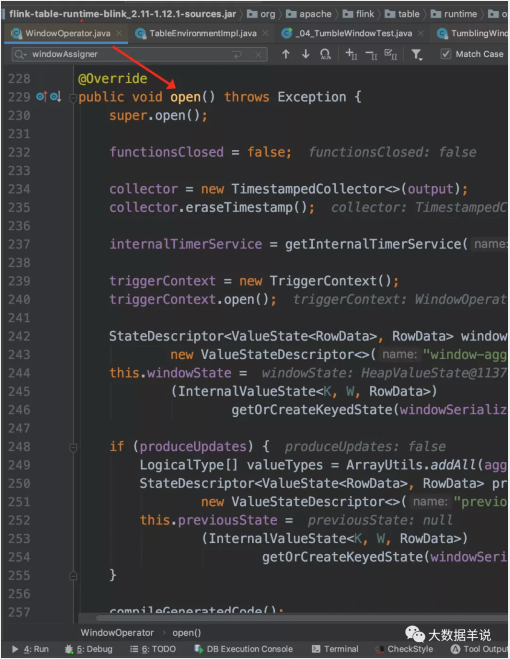
窗口算子 open 初始化后的結果。如下圖,對應的具體組件。
初始化完成之后,開始處理具體數據。
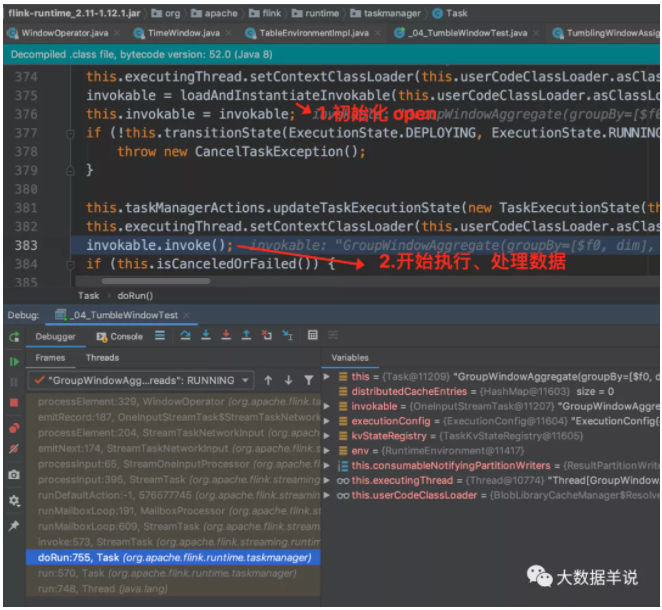
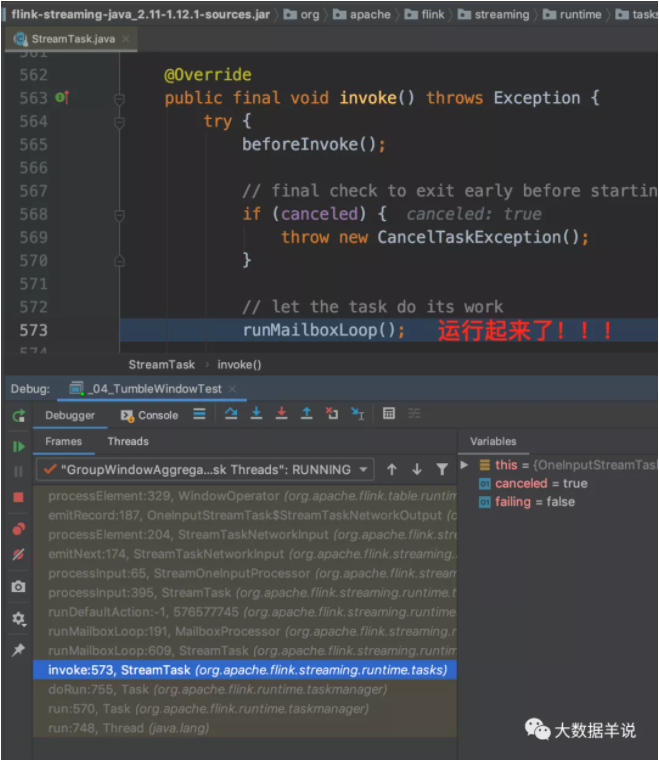
循環 loop,一直 run 啊 run。
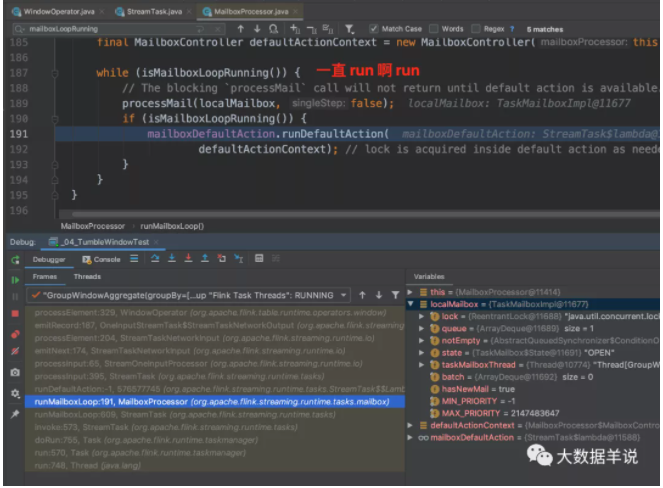
判斷記錄的具體類型,然后執行不同的邏輯。
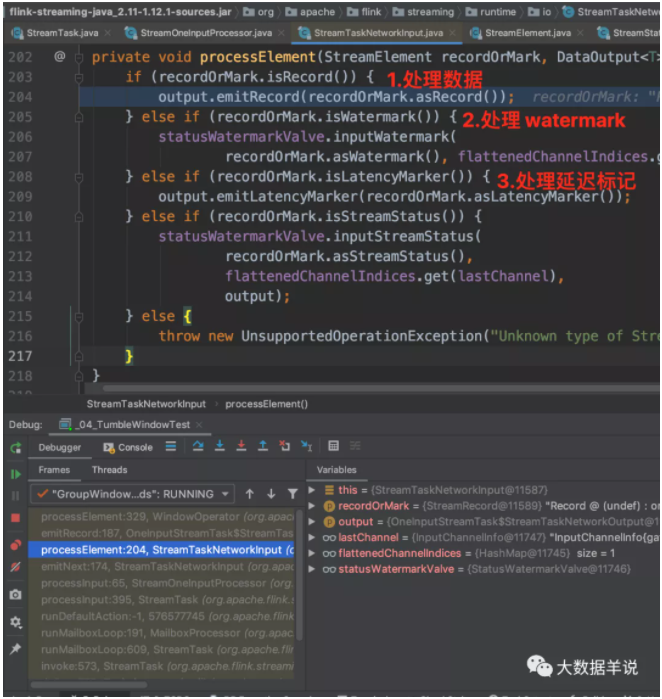
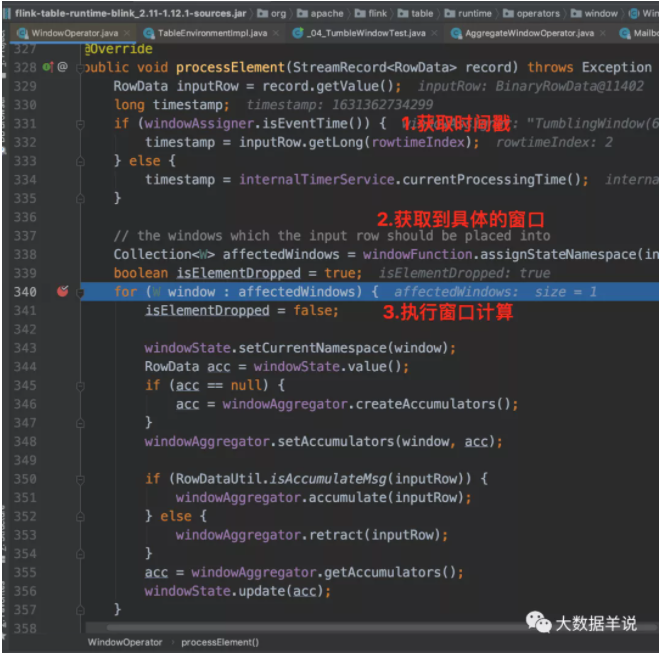
來看看處理一條數據的 processElement 方法邏輯,進行 acc 處理。代碼中的的 windowAggregator 就是之前代碼生成的 GroupingWindowAggsHandler$59。
- Notes:事件時間邏輯中,sql api 和 datastream api 對于數據記錄時間戳存儲邏輯是不一樣的。datastream api:每條記錄的 rowtime 是放在 StreamRecord 中的時間戳字段中的。sql api:時間戳是每次都從數據中進行獲取的。算子中會維護一個下標。可以按照下標從數據中獲取時間戳。
來看看 watermark 到達并且觸發窗口計算時,執行 onEventTime 邏輯。
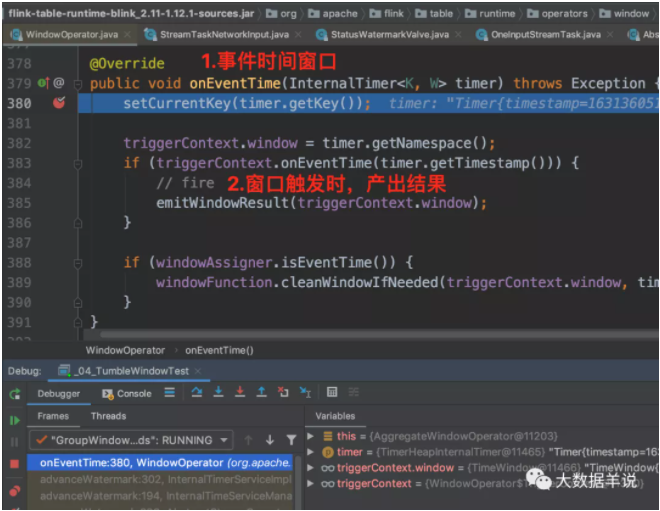
觸發窗口計算時,onEventTime -> emitWindowResult,產出具體數據。
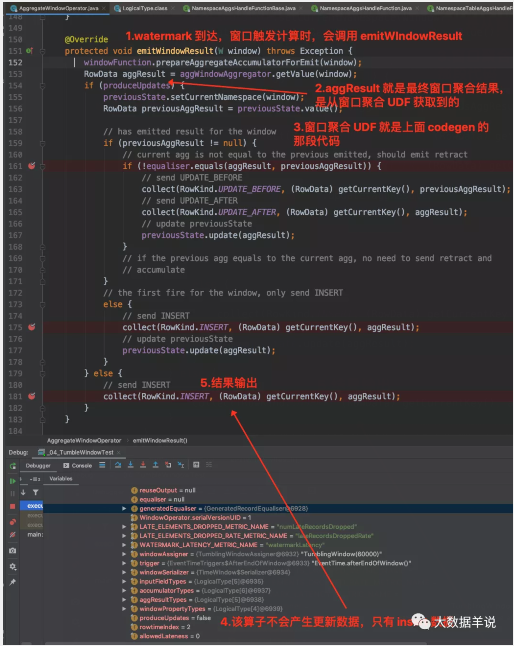
至此整個 sql tumble window 的處理邏輯也就很清楚了。和 datastream 基本上都是一致的。是不是整個邏輯就理清楚了。
5.總結與展望篇
本文主要介紹了 tumble window 聚合類指標的常見場景案例以及其底層運行原理。
而且也介紹了在查看 flink sql 任務時的一些技巧:
去 flink webui 就能看到這個任務目前在做什么。包括算子名稱都會給直接展示給我們目前哪個算子在干啥事情,在處理啥邏輯。
sql 的 watermark 類型要設置為 TIMESTAMP(3)。
事件時間邏輯中,sql api 和 datastream api 對于數據記錄時間戳存儲邏輯是不一樣的。datastream api:每條記錄的 rowtime 是放在 StreamRecord 中的時間戳字段中的。sql api:時間戳是每次都從數據中進行獲取的。算子中會維護一個下標。可以按照下標從數據中獲取時間戳。
本文轉載自微信公眾號「大數據羊說」
























