













Flink SQL 知其所以然:核心思想之動態表 & 連續查詢!
SQL 動態表 & 連續查詢
hi,大家好,我是老羊,今天給大家帶來一篇關于 Flink SQL 流式計算的核心思想設計文章。
在小伙伴萌看下文之前,先看一下本文整體的思路,跟著博主思路走,會更清晰:
- 先分析一下將 SQL 應用到流處理的思路
- SQL 應用于批處理已經很成熟了,通過對比流批處理在輸入、數據處理、輸出的異同點來分析出將 SQL 應用于流處理的核心要解決的問題點
- 分析如何使用 SQL 動態輸入表 技術來將 輸入數據流 映射到 SQL 中的輸入表
- 分析如何使用 SQL 連續查詢 技術來將 計算邏輯 映射到 SQL 中的運算語義
- 使用 SQL 動態表 & 連續查詢技術 兩種技術方案來將 流式 SQL 實際應用到兩個常見案例中
- 分析 SQL 連續查詢 的兩種類型:更新(Update)查詢 & 追加(Append)查詢
- 分析如何使用 SQL 動態輸出表 技術來將 輸出數據流 映射到 SQL 中的輸出表
博主認為讀完本節你應該掌握:
- SQL 動態輸入表、SQL 動態輸出表
- SQL 連續查詢 的兩種類型分別對應的查詢場景及 SQL 語義
1.SQL 應用于流處理的思路
在流式 SQL 誕生之前,所有的基于 SQL 的數據查詢都是基于批數據的,沒有將 SQL 應用到流數據處理這一說法。
那么如果我們想將 SQL 應用到流處理中,必然要站在巨人的肩膀(批數據處理的流程)上面進行,那么具體的分析思路如下:
- 步驟一:先比較 批處理 與 流處理 的異同之處:如果有相同的部分,那么可以直接復用;不同之處才是我們需要重點克服和關注的。
- 步驟二:摘出 1 中說到的不同之處,分析如果要滿足這個不同之處,目前有哪些技術是類似的
- 步驟三:再從這些類似的技術上進一步發展,以滿足將 SQL 應用于流任務中
博主下文就會根據上述三個步驟來一步一步介紹 動態表 誕生的背景以及這個概念是如何誕生的。
2.流批處理的異同點及將 SQL 應用于流處理核心解決的問題
首先對比一下常見的 批處理 和 流處理 中 數據源(輸入表)、處理邏輯、數據匯(結果表) 的異同點。
- | 輸入表 | 處理邏輯 | 結果表 |
批處理 | 靜態表:輸入數據有限、是有界集合 | 批式計算:每次執行查詢能夠訪問到完整的輸入數據,然后計算,輸出完整的結果數據 | 靜態表:數據有限 |
流處理 | 動態表:輸入數據無限,數據實時增加,并且源源不斷 | 流式計算:執行時不能夠訪問到完整的輸入數據,每次計算的結果都是一個中間結果 | 動態表:數據無限 |
對比上述流批處理之后,我們得到了要將 SQL 應用于流式任務的三個要解決的核心點:
- SQL 輸入表:分析如何將一個實時的,源源不斷的輸入流數據表示為 SQL 中的輸入表。
- SQL 處理計算:分析將 SQL 查詢邏輯翻譯成什么樣的底層處理技術才能夠實時的處理流式輸入數據,然后產出流式輸出數據。
- SQL 輸出表:分析如何將 SQL 查詢輸出的源源不斷的流數據表示為一個 SQL 中的輸出表。
將上面 3 個點總結一下,也就引出了本節的 動態表 和 連續查詢 兩種技術方案:
- 動態表:源源不斷的輸入、輸出流數據映射到 動態表
- 連續查詢:實時處理輸入數據,產出輸出數據的實時處理技術
3.SQL 流處理的輸入:輸入流映射為 SQL 動態輸入表
動態表。這里的動態其實是相比于批處理的靜態(有界)來說的。
- 靜態表:應用于批處理數據中,靜態表可以理解為是不隨著時間實時進行變化的。一般都是一天、一小時的粒度新生成一個分區。
- 動態表:動態表是隨時間實時進行變化的。是將 SQL 體系中表的概念應用到 Flink 上面的的核心點。
來看一個具體的案例,下圖顯示了點擊事件流(左側)如何轉換為動態表(右側)。當數據源生成更多的點擊事件記錄時,映射出來的動態表也會不斷增長,這就是動態表的概念:
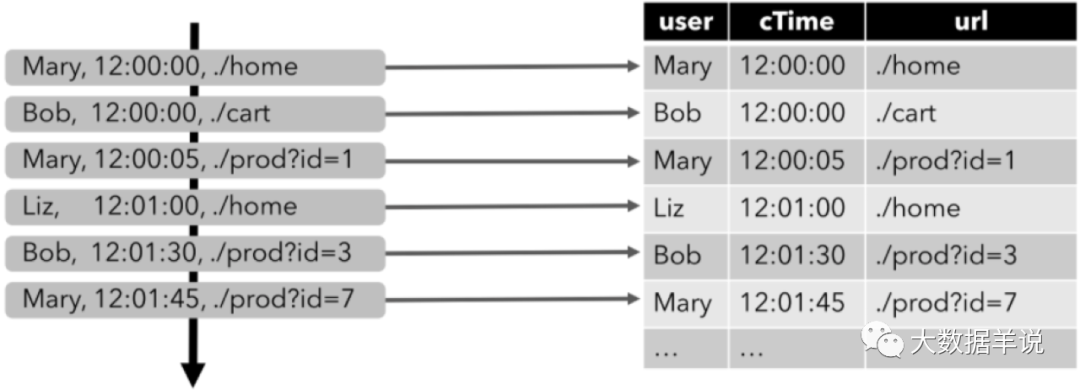
Dynamic Table
4.SQL 流處理的計算:實時處理底層技術 - SQL 連續查詢
連續查詢。
部分高級關系數據庫系統提供了一個稱為物化視圖(Materialized Views) 的特性。
物化視圖其實就是一條 SQL 查詢,就像常規的虛擬視圖 VIEW 一樣。但與虛擬視圖不同的是,物化視圖會緩存查詢的結果,因此在請求訪問視圖時不需要對查詢進行重新計算,可以直接獲取物化視圖的結果,小伙伴萌可以認為物化視圖其實就是把結果緩存了下來。
舉個例子:批處理中,如果以 Hive 天級別的物化視圖來說,其實就是每天等數據源 ready 之后,調度物化視圖的 SQL 執行然后產生新的結果提供服務。那么就可以認為一條表示了輸入、處理、輸出的 SQL 就是一個構建物化視圖的過程。
映射到我們的流任務中,輸入、處理邏輯、輸出這一套流程也是一個物化視圖的概念。相比批處理來說,流處理中,我們的數據源表的數據是源源不斷的。那么從輸入、處理、輸出的整個物化視圖的維護流程也必須是實時的。
因此我們就需要引入一種實時視圖維護(Eager View Maintenance)的技術去做到:一旦更新了物化視圖的數據源表就立即更新視圖的結果,從而保證輸出的結果也是最新的。
這種 實時視圖維護(Eager View Maintenance)的技術就叫做 連續查詢。
注意:
- 連續查詢(Continuous Query) 不斷的消費動態輸入表的的數據,不斷的更新動態結果表的數據。
- 連續查詢(Continuous Query) 的產出的結果 = 批處理模式在輸入表的上執行的相同查詢的結果。相同的 SQL,對應于同一個輸入數據,雖然執行方式不同,但是流處理和批處理的結果是永遠都會相同的。
5.SQL 流處理實際應用:動態表 & 連續查詢技術的兩個實戰案
例總結前兩節,動態表 & 連續查詢 兩項技術在一條流 SQL 中的執行流程總共包含了三個步驟,如下圖及總結所示:

Query
- 第一步:將數據輸入流轉換為 SQL 中的動態輸入表。這里的轉化其實就是指將輸入流映射(綁定)為一個動態輸入表。上圖雖然分開畫了,但是可以理解為一個東西。
- 第二步:在動態輸入表上執行一個連續查詢,然后生成一個新的動態結果表。
- 第三步:生成的動態結果表被轉換回數據輸出流。
我們實際介紹一個案例來看看其運行方式,以上文介紹到的點擊事件流為例,點擊事件流數據的字段如下:
[
user: VARCHAR, // 用戶名
cTime: TIMESTAMP, // 訪問 URL 的時間
url: VARCHAR // 用戶訪問的 URL
]
- 第一步,將輸入數據流映射為一個動態輸入表。以下圖為例,我們將點擊事件流(圖左)轉換為動態表 (圖右)。當點擊數據源源不斷的來到時,動態表的數據也會不斷的增加。
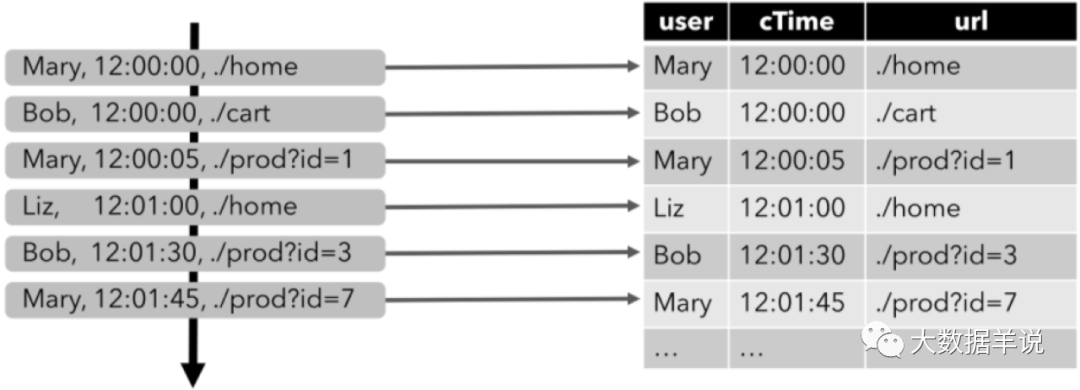
Dynamic Table
- 第二步,在點擊事件流映射的動態輸入表上執行一個連續查詢(Continuous Query),并生成一個新的動態輸出表。
下面介紹兩個查詢的案例:
第一個查詢:一個簡單的 GROUP-BY COUNT 聚合查詢,寫過 SQL 的都不會陌生吧,這種應該都是最基礎,最常用的對數據按照類別分組的方法。
如下圖所示 group by 聚合的常用案例。
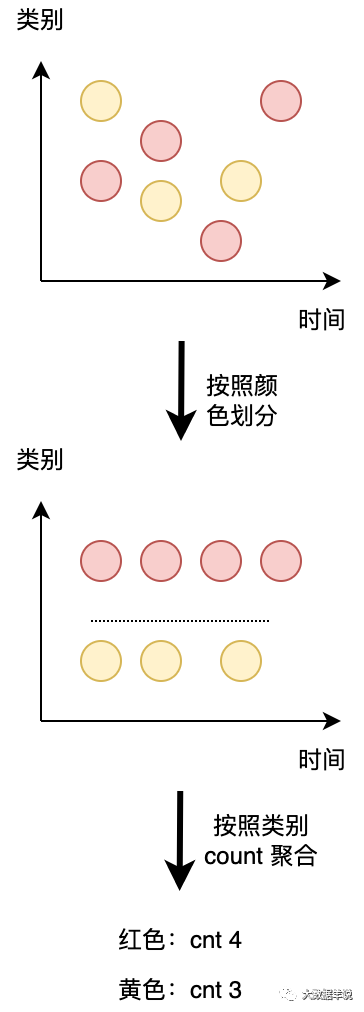
time
那么本案例中呢,是基于 clicks 表中 user 字段對 clicks 表(點擊事件流)進行分組,來統計每一個 user 的訪問的 URL 的數量。下面的圖展示了當 clicks 輸入表來了新數據(即表更新時),連續查詢(Continuous Query) 的計算邏輯。
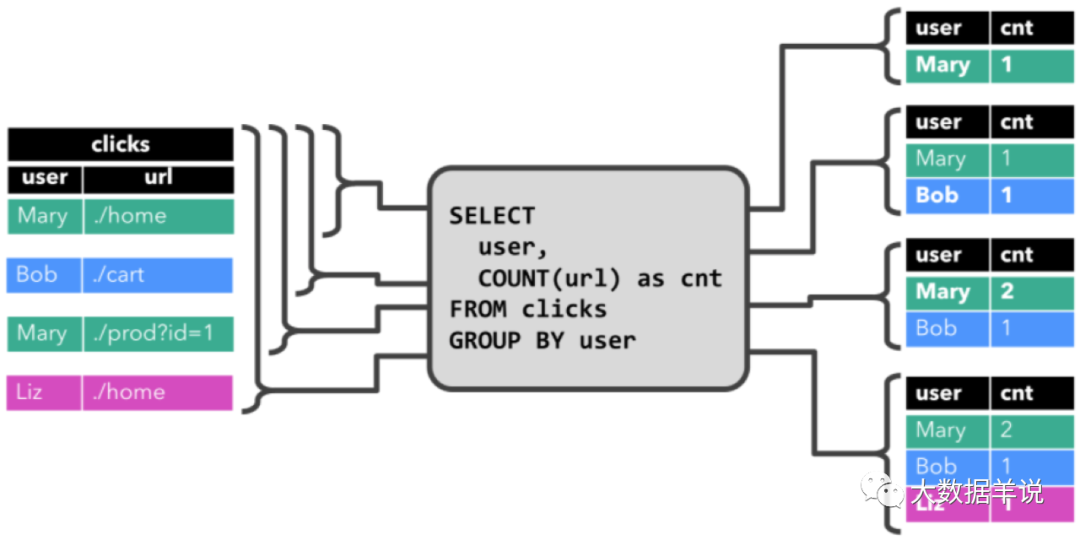
group agg
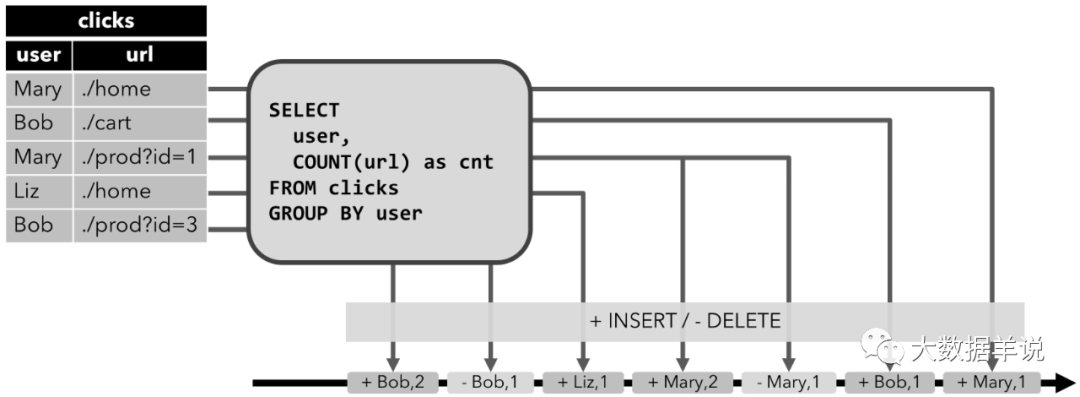
當查詢開始,clicks 表(左側)是空的。
- 當第一行數據被插入到 clicks 表時,連續查詢(Continuous Query)開始計算結果數據。數據源表第一行數據 [Mary,./home] 輸入后,會計算結果 [Mary, 1] 插入(insert)結果表。
- 當第二行 [Bob, ./cart] 插入到 clicks 表時,連續查詢(Continuous Query)會計算結果 [Bob, 1],并插入(insert)到結果表。
- 第三行 [Mary, ./prod?id=1] 輸出時,會計算出[Mary, 2](user 為 Mary 的數據總共來過兩條,所以為 2),并更新(update)結果表,[Mary, 1] 更新成 [Mary, 2]。
- 最后,當第四行數據加入 clicks 表時,查詢將第三行 [Liz, 1] 插入(insert)結果表中。
注意上述特殊標記出來的字體,可以看到連續查詢對于結果的數據輸出方式有兩種:
- 插入(insert)結果表
- 更新(update)結果表
大家對于 插入(insert)結果表 這件事都比較好理解,因為離線數據都只有插入這個概念。
但是 更新(update)結果表 就是離線處理中沒有概念了。這就是連續查詢中中比較重要一個概念。后文會介紹。
接下來介紹第二條查詢語句。
第二條查詢與第一條類似,但是 group by 中除了 user 字段之外,還 group by 了 tumble,其代表開了個滾動窗口(后面會詳細說明滾動窗口的作用),然后計算 url 數量。
group by user,是按照類別(橫向)給數據分組,group by tumble 滾動窗口是按時間粒度(縱向)給數據進行分組。如下圖所示。
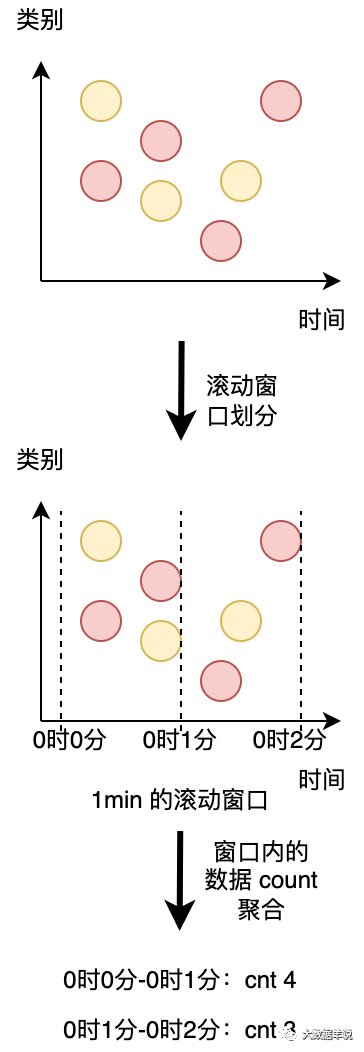
time
圖形化一解釋就很好理解了,兩種都是對數據進行分組,一個是按照 類別 分組,另一種是按照 時間 分組。
與前面一樣,左邊顯示了輸入表 clicks。查詢每小時持續計算結果并更新結果表。clicks 表有三列,user,cTime,url。其中 cTime 代表數據的時間戳,用于給數據按照時間粒度分組。
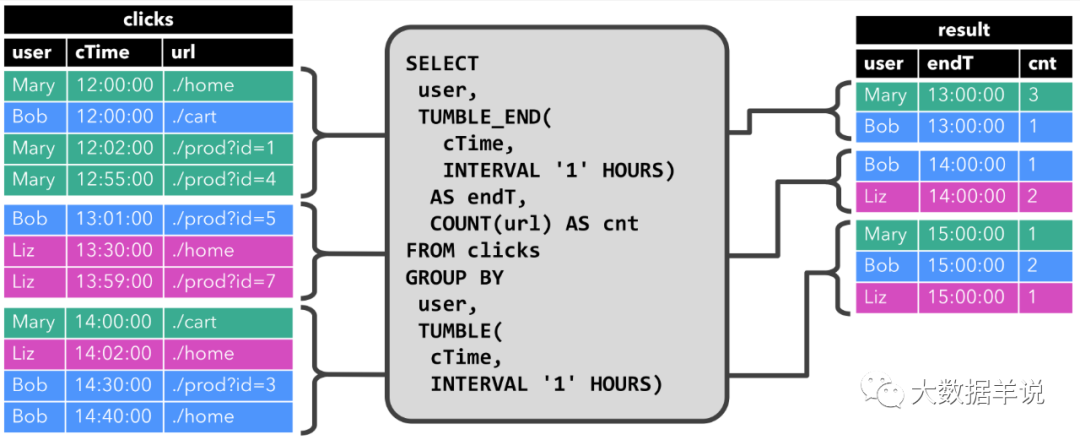
tumble window
我們的滾動窗口的步長為 1 小時,即時間粒度上面的分組為 1 小時。其中時間戳在 12:00:00 - 12:59:59 之間有四條數據。13:00:00 - 13:59:59 有三條數據。14:00:00 - 14:59:59 之間有四條數據。
- 當 12:00:00 - 12:59:59 數據輸入之后,1 小時的窗口,連續查詢(Continuous Query)計算的結果如右圖所示,將 [Mary, 3],[Bob, 1] 插入(insert)結果表。
- 當 13:00:00 - 13:59:59 數據輸入之后,1 小時的窗口,連續查詢(Continuous Query)計算的結果如右圖所示,將 [Bob, 1],[Liz, 2] 插入(insert)結果表。
- 當 14:00:00 - 14:59:59 數據輸入之后,1 小時的窗口,連續查詢(Continuous Query)計算的結果如右圖所示,將 [Mary, 1],[Bob, 2],[Liz, 1] 插入(insert)結果表。
而這個查詢只有 插入(insert)結果表 這個行為。
6.SQL 連續查詢的兩種類型:更新(Update)查詢 & 追加(Append)查詢
雖然前一節的兩個查詢看起來非常相似(都計算分組進行計數聚合),但它們在一個重要方面不同:
- 第一個查詢(group by user),即(Update)查詢:會更新先前輸出的結果,即結果表流數據中包含 INSERT 和 UPDATE 數據。小伙伴萌可以理解為 group by user 這條語句當中,輸入源的數據是一直有的,源源不斷的,同一個 user 的數據之后可能還是會有的,因此可以認為此 SQL 的每次的輸出結果都是一個中間結果, 當同一個 user 下一條數據到來的時候,就要用新結果把上一次的產出中間結果(舊結果)給 UPDATE 了。所以這就是 UPDATE 查詢的由來(其中 INSERT 就是第一條數據到來的時候,沒有之前的中間結果,所以是 INSERT)。
- 第二個查詢(group by user, tumble(xxx)),即(Append)查詢:只追加到結果表,即結果表流數據中只包含 INSERT 的數據。小伙伴萌可以理解為雖然 group by user, tumble(xxx) 上游也是一個源源不斷的數據,但是這個查詢本質上是對時間上的劃分,而時間都是越變越大的,當前這個滾動窗口結束之后,后面來的數據的時間都會比這個滾動窗口的結束時間大,都歸屬于之后的窗口了,當前這個滾動窗口的結果數據就不會再改變了,因此這條查詢只有 INSERT 數據,即一個 Append 查詢。
上面是 Flink SQL 連續查詢處理機制上面的兩類查詢方式。我們可以發現連續查詢的處理機制不一樣,產出到結果表中的結果數據也是不一樣的。針對上面兩種結果表的更新方式,Flink SQL 提出了 changelog 表的概念來進行兼容。
changelog 表這個概念其實就和 MySQL binlog 是一樣的。會包含 INSERT、UPDATE、DELETE 三種數據,通過這三種數據的處理來描述實時處理技術對于動態表的變更:
- changelog 表:即第一個查詢的輸出表,輸出結果數據不但會追加,還會發生更新
- changelog insert-only 表:即第二個查詢的輸出表,輸出結果數據只會追加,不會發生更新
7.SQL 流處理的輸出:動態輸出表轉化為輸出數據
可以看到我們的標題都是隨著一個 SQL 的生命周期的。從 輸入流映射為 SQL 動態輸入表、實時處理底層技術 - SQL 連續查詢 到本小節的 SQL 動態輸出表轉化為輸出數據。都是有邏輯關系的。
我們上面介紹到了 連續查詢(Continuous Query) 的輸出結果表是一個 changelog。其可以像普通數據庫表一樣通過 INSERT、UPDATE 和 DELETE 來不斷修改。
它可能是一個只有一行、不斷更新 changelog 表,也可能是一個 insert-only 的 changelog 表,沒有 UPDATE 和 DELETE 修改,或者介于兩者之間的其他表。
在將動態表轉換為流或將其寫入外部系統時,需要對這些不同狀態的數據進行編碼。Flink 的 Table API 和 SQL API 支持三種方式來編碼一個動態表的變化:
- Append-only 流:輸出的結果只有 INSERT 操作的數據。
- Retract 流:
Retract 流包含兩種類型的 message:add messages 和 retract messages 。其將 INSERT 操作編碼為 add message、將 DELETE 操作編碼為 retract message、將 UPDATE 操作編碼為更新先前行的 retract message 和更新(新)行的 add message,從而將動態表轉換為 retract 流。
Retract 流寫入到輸出結果表的數據如下圖所示,有 -,+ 兩種,分別 - 代表撤回舊數據,+ 代表輸出最新的數據。這兩種數據最終都會寫入到輸出的數據引擎中。
如果下游還有任務去消費這條流的話,要注意需要正確處理 -,+ 兩種數據,防止數據計算重復或者錯誤。
retract
- Upsert 流:
Upsert 流包含兩種類型的 message:upsert messages 和 delete messages。轉換為 upsert 流的動態表需要唯一鍵(唯一鍵可以由多個字段組合而成)。其會將 INSERT和 UPDATE 操作編碼為 upsert message,將 DELETE 操作編碼為 delete message。
Upsert 流寫入到輸出結果表的數據如下圖所示,每次輸出的結果都是當前每一個 user 的最新結果數據,不會有 Retract 中的 - 回撤數據。
如果下游還有一個任務去消費這條流的話,消費流的算子需要知道唯一鍵(即 user),以便正確地根據唯一鍵(user)去拿到每一個 user 當前最新的狀態。其與 retract 流的主要區別在于 UPDATE 操作是用單個 message 編碼的,因此效率更高。下圖顯示了將動態表轉換為 upsert 流的過程。
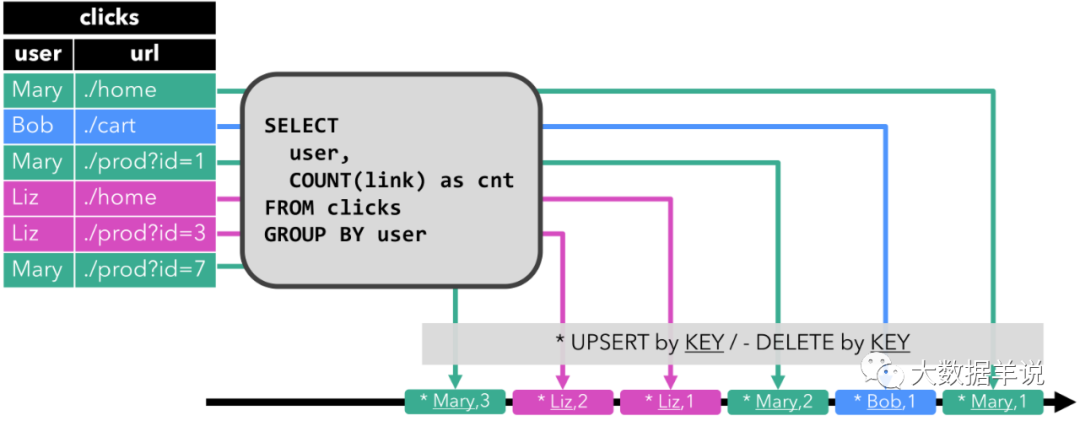
upsert
8.補充知識:SQL 與關系代數
小伙伴萌會問到,關系代數是啥東西?
其實關系代數就是對于數據集(即表)的一系列的 操作(即查詢語句)。常見關系代數有:
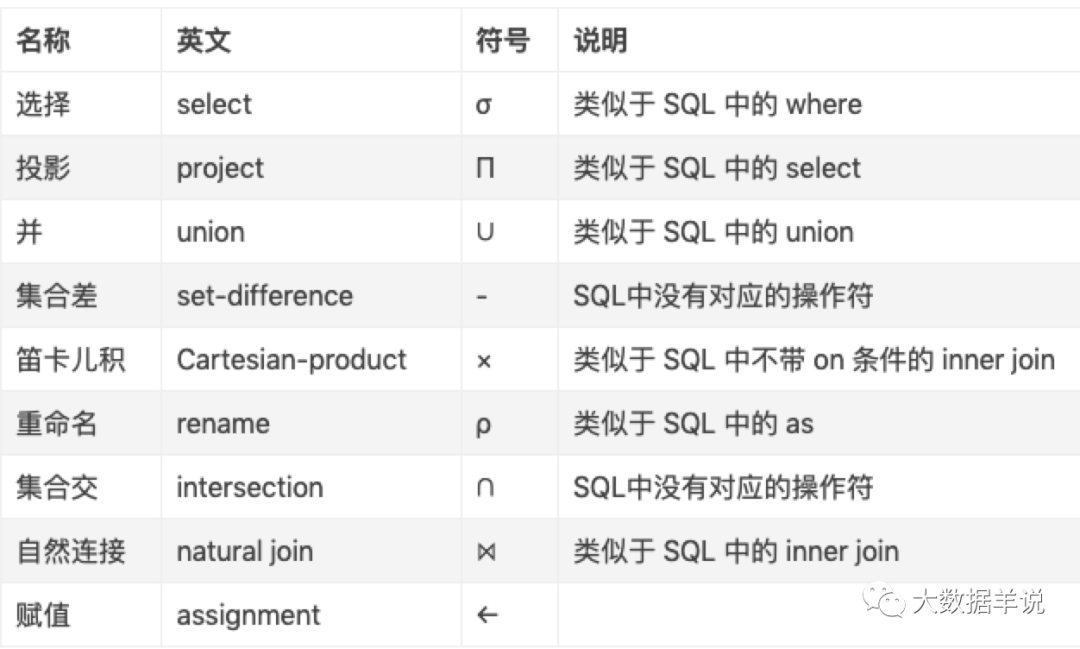
Relational Algebra
那么 SQL 和關系代數是啥關系呢?
SQL 就是能夠表示關系代數一種面向用戶的接口:即用戶能使用 SQL 表達關系代數的處理邏輯,也就是我們可以用 SQL 去在表(數據集)上執行我們的業務邏輯操作(關系代數操作)。






















