













Flink SQL 知其所以然之流 join 很難嘛???(上)
1.序篇
進入正文。
下面即是文章目錄,也對應到本文的結論,小伙伴可以先看結論快速了解本文能給你帶來什么幫助:
- 背景及應用場景介紹:join 作為離線數倉中最常見的場景,在實時數倉中也必然不可能缺少它,flink sql 提供的豐富的 join 方式(總結 6 種:regular join,維表 join,temporal join,interval join,array 拍平,table function 函數)對我們滿足需求提供了強大的后盾
- 先來一個實戰案例:以一個曝光日志 left join 點擊日志為案例展開,介紹 flink sql join 的解決方案
- flink sql join 的解決方案以及存在問題的介紹:主要介紹 regular join 的在上述案例的運行結果及分析源碼機制,它雖然簡單,但是 left join,right join,full join 會存在著 retract 的問題,所以在使用前,你應該充分了解其運行機制,避免出現數據發重,發多的問題。
- 本文主要介紹 regular join retract 的問題,下節介紹怎么使用 interval join 來避免這種 retract 問題,并滿足第 2 點的實戰案例需求。
2.背景及應用場景介紹
在我們的日常場景中,應用最廣的一種操作必然有 join 的一席之地,例如
計算曝光數據和點擊數據的 CTR,需要通過唯一 id 進行 join 關聯
事實數據關聯維度數據獲取維度,進而計算維度指標
上述場景,在離線數倉應用之廣就不多說了。
那么,實時流之間的關聯要怎么操作呢?
flink sql 為我們提供了四種強大的關聯方式,幫助我們在流式場景中達到流關聯的目的。如下圖官網截圖所示:

join
- regular join:即 left join,right join,full join,inner join
- 維表 lookup join:維表關聯
- temporal join:快照表 join
- interval join:兩條流在一段時間區間之內的 join
- array 炸開:列轉行
- table function join:通過 table function 自定義函數實現 join(類似于列轉行的效果,或者說類似于維表 join 的效果)
在實時數倉中,regular join 以及 interval join,以及兩種 join 的結合使用是最常使用的。所以本文主要介紹這兩種(太長的篇幅大家可能也不想看,所以之后的文章就以簡潔,短為目標)。
3.先來一個實戰案例
先來一個實際案例來看看在具體輸入值的場景下,輸出值應該長啥樣。
場景:即常見的曝光日志流(show_log)通過 log_id 關聯點擊日志流(click_log),將數據的關聯結果進行下發。
來一波輸入數據:
曝光數據:
| log_id | timestamp | show_params |
|---|---|---|
| 1 | 2021-11-01 00:01:03 | show_params |
| 2 | 2021-11-01 00:03:00 | show_params2 |
| 3 | 2021-11-01 00:05:00 | show_params3 |
點擊數據:
| log_id | timestamp | click_params |
|---|---|---|
| 1 | 2021-11-01 00:01:53 | click_params |
| 2 | 2021-11-01 00:02:01 | click_params2 |
預期輸出數據如下:
| log_id | timestamp | show_params | click_params |
|---|---|---|---|
| 1 | 2021-11-01 00:01:00 | show_params | click_params |
| 2 | 2021-11-01 00:01:00 | show_params2 | click_params2 |
| 3 | 2021-11-01 00:02:00 | show_params3 | null |
熟悉離線 hive sql 的同學可能 10s 就寫完上面這個 sql 了,如下 hive sql
- INSERT INTO sink_table
- SELECT
- show_log.log_id as log_id,
- show_log.timestamp as timestamp,
- show_log.show_params as show_params,
- click_log.click_params as click_params
- FROM show_log
- LEFT JOIN click_log ON show_log.log_id = click_log.log_id;
那么我們看看上述需求如果要以 flink sql 實現需要怎么做呢?
雖然不 flink sql 提供了 left join 的能力,但是在實際使用時,可能會出現預期之外的問題。下節詳述。
4.flink sql join
4.1.flink sql
還是上面的案例,我們先實際跑一遍看看結果:
- INSERT INTO sink_table
- SELECT
- show_log.log_id as log_id,
- show_log.timestamp as timestamp,
- show_log.show_params as show_params,
- click_log.click_params as click_params
- FROM show_log
- LEFT JOIN click_log ON show_log.log_id = click_log.log_id;
flink web ui 算子圖如下:
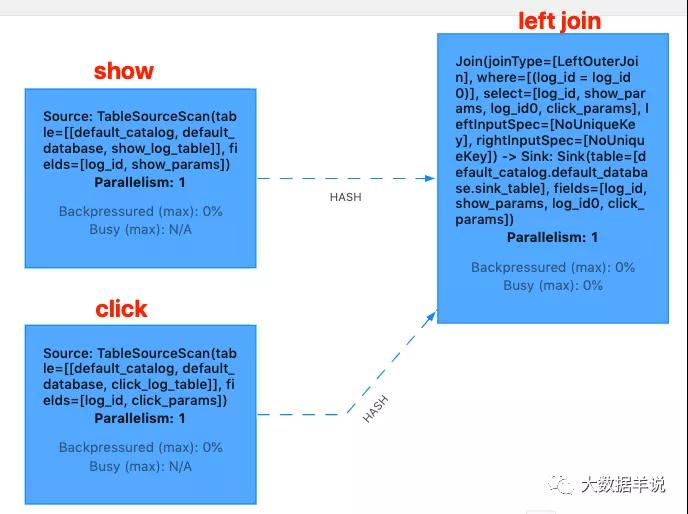
flink web ui
結果如下:
- +[1 | 2021-11-01 00:01:03 | show_params | null]
- -[1 | 2021-11-01 00:01:03 | show_params | null]
- +[1 | 2021-11-01 00:01:03 | show_params | click_params]
- +[2 | 2021-11-01 00:03:00 | show_params | click_params]
- +[3 | 2021-11-01 00:05:00 | show_params | null]
從結果上看,其輸出數據有 +,-,代表其輸出的數據是一個 retract 流的數據。分析原因發現是,由于第一條 show_log 先于 click_log 到達, 所以就先直接發出 +[1 | 2021-11-01 00:01:03 | show_params | null],后面 click_log 到達之后,將上一次未關聯到的 show_log 撤回, 然后將關聯到的 +[1 | 2021-11-01 00:01:03 | show_params | click_params] 下發。
但是 retract 流會導致寫入到 kafka 的數據變多,這是不可被接受的。我們期望的結果應該是一個 append 數據流。
為什么 left join 會出現這種問題呢?那就要從 left join 的原理說起了。
來定位到具體的實現源碼。先看一下 transformations。
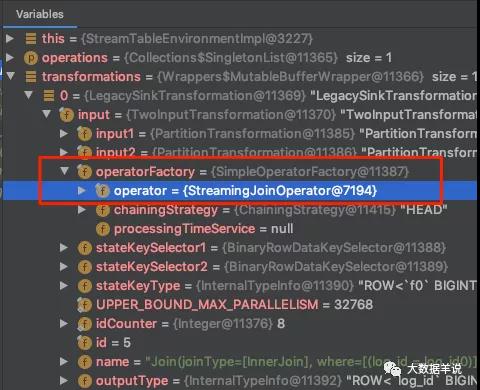
transformations
可以看到 left join 的具體 operator 是 org.apache.flink.table.runtime.operators.join.stream.StreamingJoinOperator。
其核心邏輯就集中在 processElement 方法上面。并且源碼對于 processElement 的處理邏輯有詳細的注釋說明,如下圖所示。
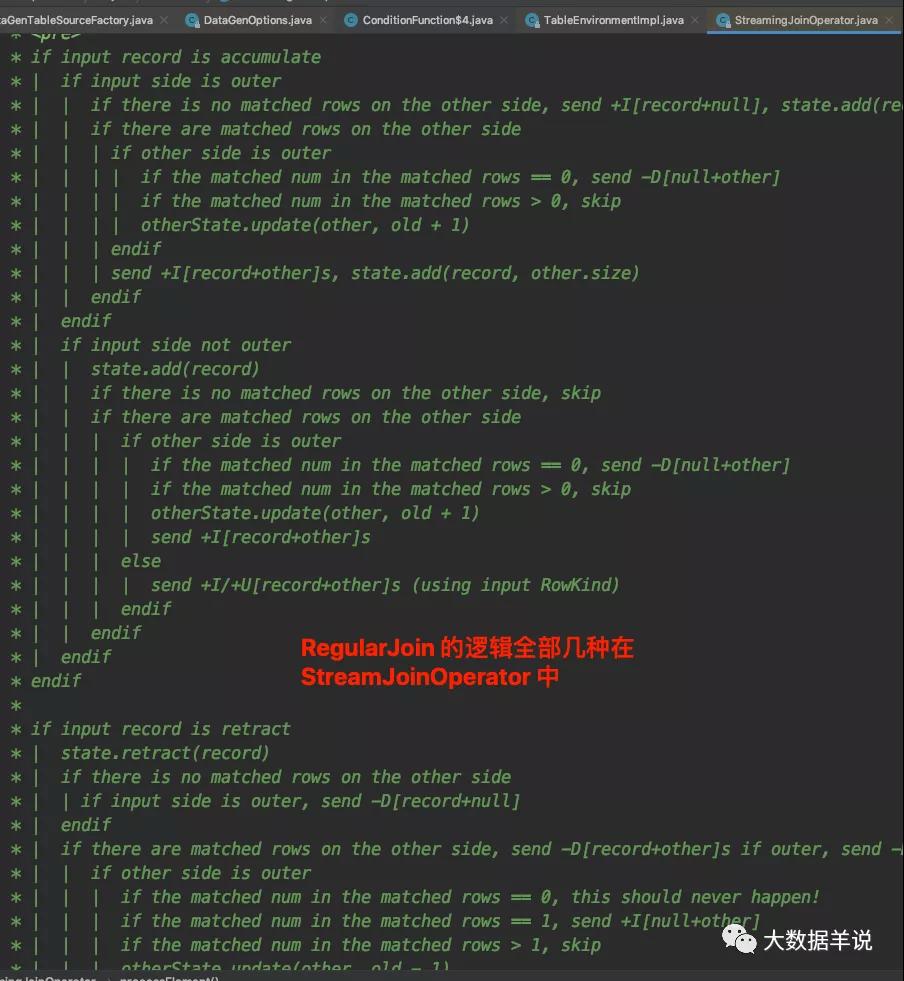
StreamingJoinOperator#processElement
注釋看起來邏輯比較復雜。我們這里按照 left join,inner join,right join,full join 分類給大家解釋一下。
4.2.left join
首先是 left join,以上面的 show_log(左表) left join click_log(右表) 為例:
- 首先如果 join xxx on 中的條件是等式則代表 join 是在相同 key 下進行的,join 的 key 即 show_log.log_id,click_log.log_id,相同 key 的數據會被發送到一個并發中進行處理。如果 join xxx on 中的條件是不等式,則兩個流的 source 算子向 join 算子下發數據是按照 global 的 partition 策略進行下發的,并且 join 算子并發會被設置為 1,所有的數據會被發送到這一個并發中處理。
- 相同 key 下,當 show_log 來一條數據,如果 click_log 有數據:則 show_log 與 click_log 中的所有數據進行遍歷關聯一遍輸出[+(show_log,click_log)]數據,并且把 show_log 保存到左表的狀態中(以供后續 join 使用)。
- 相同 key 下,當 show_log 來一條數據,如果 click_log 中沒有數據:則 show_log 不會等待,直接輸出[+(show_log,null)]數據,并且把 show_log 保存到左表的狀態中(以供后續 join 使用)。
- 相同 key 下,當 click_log 來一條數據,如果 show_log 有數據:則 click_log 對 show_log 中所有的數據進行遍歷關聯一遍。在輸出數據前,會判斷,如果被關聯的這條 show_log 之前沒有關聯到過 click_log(即往下發過[+(show_log,null)]),則先發一條[-(show_log,null)],后發一條[+(show_log,click_log)] ,代表把之前的那條沒有關聯到 click_log 數據的 show_log 中間結果給撤回,把當前關聯到的最新結果進行下發,并把 click_log 保存到右表的狀態中(以供后續左表進行關聯)。這也就解釋了為什么輸出流是一個 retract 流。
- 相同 key 下,當 click_log 來一條數據,如果 show_log 沒有數據:把 click_log 保存到右表的狀態中(以供后續左表進行關聯)。
4.3.inner join
以上面的 show_log(左表) inner join click_log(右表) 為例:
首先如果 join xxx on 中的條件是等式則代表 join 是在相同 key 下進行的,join 的 key 即 show_log.log_id,click_log.log_id,相同 key 的數據會被發送到一個并發中進行處理。如果 join xxx on 中的條件是不等式,則兩個流的 source 算子向 join 算子下發數據是按照 global 的 partition 策略進行下發的,并且 join 算子并發會被設置為 1,所有的數據會被發送到這一個并發中處理。
相同 key 下,當 show_log 來一條數據,如果 click_log 有數據:則 show_log 與 click_log 中的所有數據進行遍歷關聯一遍輸出[+(show_log,click_log)]數據,并且把 show_log 保存到左表的狀態中(以供后續 join 使用)。
相同 key 下,當 show_log 來一條數據,如果 click_log 中沒有數據:則 show_log 不會輸出數據,會把 show_log 保存到左表的狀態中(以供后續 join 使用)。
相同 key 下,當 click_log 來一條數據,如果 show_log 有數據:則 click_log 與 show_log 中的所有數據進行遍歷關聯一遍輸出[+(show_log,click_log)]數據,并且把 click_log 保存到右表的狀態中(以供后續 join 使用)。
相同 key 下,當 click_log 來一條數據,如果 show_log 沒有數據:則 click_log 不會輸出數據,會把 click_log 保存到右表的狀態中(以供后續 join 使用)。
4.4.right join
right join 和 left join 一樣,只不過順序反了,這里不再贅述。
4.5.full join
以上面的 show_log(左表) full join click_log(右表) 為例:
- 首先如果 join xxx on 中的條件是等式則代表 join 是在相同 key 下進行的,join 的 key 即 show_log.log_id,click_log.log_id,相同 key 的數據會被發送到一個并發中進行處理。如果 join xxx on 中的條件是不等式,則兩個流的 source 算子向 join 算子下發數據是按照 global 的 partition 策略進行下發的,并且 join 算子并發會被設置為 1,所有的數據會被發送到這一個并發中處理。
- 相同 key 下,當 show_log 來一條數據,如果 click_log 有數據:則 show_log 對 click_log 中所有的數據進行遍歷關聯一遍。在輸出數據前,會判斷,如果被關聯的這條 click_log 之前沒有關聯到過 show_log(即往下發過[+(null,click_log)]),則先發一條[-(null,click_log)],后發一條[+(show_log,click_log)] ,代表把之前的那條沒有關聯到 show_log 數據的 click_log 中間結果給撤回,把當前關聯到的最新結果進行下發,并把 show_log 保存到左表的狀態中(以供后續 join 使用)
- 相同 key 下,當 show_log 來一條數據,如果 click_log 中沒有數據:則 show_log 不會等待,直接輸出[+(show_log,null)]數據,并且把 show_log 保存到左表的狀態中(以供后續 join 使用)。
- 相同 key 下,當 click_log 來一條數據,如果 show_log 有數據:則 click_log 對 show_log 中所有的數據進行遍歷關聯一遍。在輸出數據前,會判斷,如果被關聯的這條 show_log 之前沒有關聯到過 click_log(即往下發過[+(show_log,null)]),則先發一條[-(show_log,null)],后發一條[+(show_log,click_log)] ,代表把之前的那條沒有關聯到 click_log 數據的 show_log 中間結果給撤回,把當前關聯到的最新結果進行下發,并把 click_log 保存到右表的狀態中(以供后續 join 使用)
- 相同 key 下,當 click_log 來一條數據,如果 show_log 中沒有數據:則 click_log 不會等待,直接輸出[+(null,click_log)]數據,并且把 click_log 保存到右表的狀態中(以供后續 join 使用)。
4.6.regular join 的總結
總的來說上述四種 join 可以按照以下這么劃分。
inner join 會互相等,直到有數據才下發。
left join,right join,full join 不會互相等,只要來了數據,會嘗試關聯,能關聯到則下發的字段是全的,關聯不到則另一邊的字段為 null。后續數據來了之后,發現之前下發過為沒有關聯到的數據時,就會做回撤,把關聯到的結果進行下發
4.7.怎樣才能解決 retract 導致數據重復下發到 kafka 這個問題呢?
既然 flink sql 在 left join、right join、full join 實現上的原理就是以這種 retract 的方式去實現的,就不能通過這種方式來滿足業務了。
我們來轉變一下思路,上述 join 的特點就是不會相互等,那有沒有一種 join 是可以相互等待的呢。以 left join 的思路為例,左表在關聯不到右表的時候,可以選擇等待一段時間,如果超過這段時間還等不到再下發 (show_log,null),如果等到了就下發(show_log,click_log)。
interval join 閃亮登場。關于 interval join 是如何實現上述場景,及其原理實現,本篇的(下)會詳細介紹,敬請期待。
5.總結與展望
源碼公眾號后臺回復1.13.2 sql join 的奇妙解析之路獲取。
本文主要介紹了 flink sql regular 的在滿足 join 場景時存在的問題,并通過解析其實現說明了運行原理,主要包含下面兩部分:
- 背景及應用場景介紹:join 作為離線數倉中最常見的場景,在實時數倉中也必然不可能缺少它,flink sql 提供的豐富的 join 方式(總結 4 種:regular join,維表 join,temporal join,interval join)對我們滿足需求提供了強大的后盾
- 先來一個實戰案例:以一個曝光日志 left join 點擊日志為案例展開,介紹 flink sql join 的解決方案
- flink sql join 的解決方案以及存在問題的介紹:主要介紹 regular join 的在上述案例的運行結果及分析源碼機制,它雖然簡單,但是 left join,right join,full join 會存在著 retract 的問題,所以在使用前,你應該充分了解其運行機制,避免出現數據發重,發多的問題。
- 本文主要介紹 regular join retract 的問題,下節介紹怎么使用 interval join 來避免這種 retract 問題,并滿足第 2 點的實戰案例需求。























