













理解物體之間潛在關系,MIT新研究讓AI像人一樣「看」世界
人們觀察場景通常是觀察場景中的物體和物體之間的關系。比如我們經常這樣描述一個場景:桌面上有一臺筆記本電腦,筆記本電腦的右邊是一個手機。
但這種觀察方式對深度學習模型來說很難實現,因為這些模型不了解每個對象之間的關系。如果不了解這些關系,功能型機器人就很難完成它們的任務,例如一個廚房機器人將很難執行這樣的命令:「拿起炒鍋左側的水果刀并將其放在砧板上」。
為了解決這個問題,在一篇 NeurIPS 2021 Spotlight 論文中,來自 MIT 的研究者開發了一種可以理解場景中對象之間潛在關系的模型。該模型一次表征一種個體關系,然后結合這些表征來描述整個場景,使得模型能夠從文本描述中生成更準確的圖像。

論文地址:https://arxiv.org/abs/2111.09297
現實生活中人們并不是靠坐標定位物體,而是依賴于物體之間的相對位置關系。這項研究的成果將應用于工業機器人必須執行復雜的多步驟操作任務的情況,例如在倉庫中堆疊物品、組裝電器。此外,該研究還有助于讓機器能夠像人類一樣從環境中學習并與之交互。
每次表征一個關系
該研究提出使用 Energy-Based 模型將個體關系表征和分解為非規一化密度。關系場景描述被表征為關系中的獨立概率分布,每個個體關系指定一個單獨的圖像上的概率分布。這樣的組合方法可以建模多個關系之間的交互。
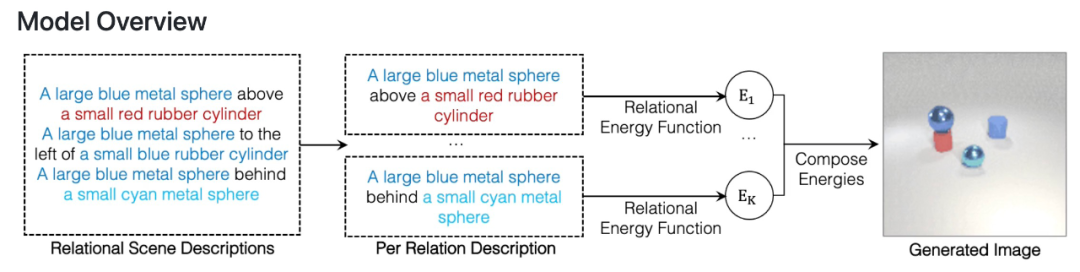
該研究表明所提框架能夠可靠地捕獲和生成帶有多個組合關系的圖像,并且能夠推斷潛在的關系場景描述,并且能夠穩健地理解語義上等效的關系場景描述。
在泛化方面,該方法可以推廣到以前未見過的關系描述上,包括對象和描述來自訓練期間未見過的數據集。這種泛化對于通用人工智能系統適應周圍世界的無限變化至關重要。
以往的一些系統可能會從整體上獲取所有關系,并從描述中一次性生成圖像。然而這些模型不能真正適應添加更多關系的圖像。相比之下,該研究的方法將單獨的、較小的模型組合在一起,能夠對更多的關系進行建模并適應新的關系組合。
此外,該系統還可以反向工作——給定一張圖像,它可以找到與場景中對象之間的關系相匹配的文本描述。該模型還可通過重新排列場景中的對象來編輯圖像,使它們與新的描述相匹配。

研究人員將他們的模型與幾種類似深度學習方法進行了比較,實驗表明在每種情況下,他們的模型都優于基線。
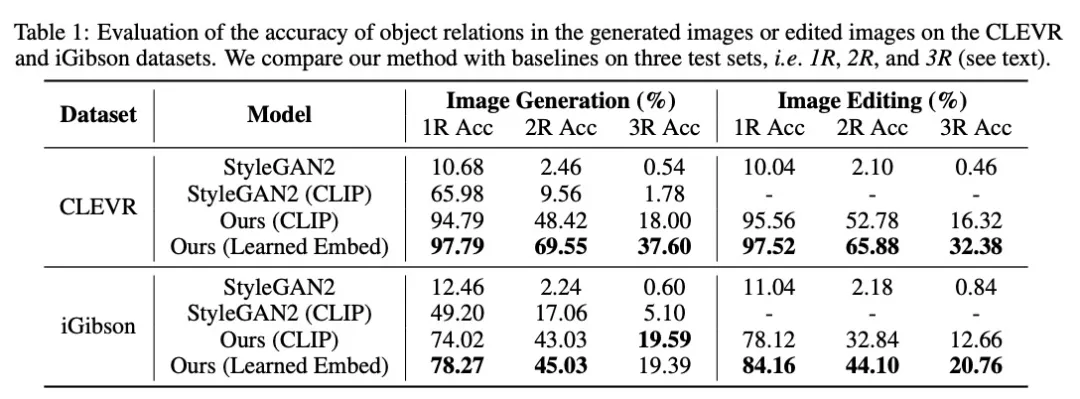
他們還邀請人們評估生成的圖像是否與原始場景描述匹配。在描述包含三個關系的示例中,91% 的參與者認為該模型的性能比以往模型更好。
這些早期結果令人鼓舞,研究人員希望未來該模型能夠在更復雜的真實世界圖像上運行,這需要解決物體遮擋、場景混亂等問題。
他們也期待模型最終能夠整合到機器人系統中,使機器人能夠推斷現實世界中的物體關系,更好地完成交互任務。
感興趣的讀者可以閱讀論文原文了解更多研究細節。





















